

前言
最近项目要用到Picasso,所以就看了一下Picasso里面的源码,发现里面的内存缓存主要用的LruCache这个类,就去看了一下它的相关的东西,还是挺有收获的。
正文
我一般看类源码喜欢以构造方法作为突破口,然后从它暴露出来的我们使用的最多的那些方法切入,一点一点的把它捋清除,这次基本上也是这个思路。
构造方法
/**
* @param maxSize for caches that do not override {@link #sizeOf}, this is
* the maximum number of entries in the cache. For all other caches,
* this is the maximum sum of the sizes of the entries in this cache.
*/
public LruCache(int maxSize) {
if (maxSize <= 0)="" {="" throw="" new="" illegalargumentexception("maxsize="" );="" }="" this.maxsize="maxSize;" this.map="new" linkedhashmap(0, 0.75f, true);
} 从这个构造方法,我们至少可以得到以下两点信息:
- LruCache所占的内存大小是可以自定义的。
- LruCache的底层是通过LinkedHashMap实现数据缓存的。
看到LinkedHashMap的这个构造方法,我感觉挺奇怪的,因为以前从来没有用过这个构造方法,于是我就进入LinkedHashMap类看了看这个构造有何奇特之处:
/**
* Constructs a new {@code LinkedHashMap} instance with the specified
* capacity, load factor and a flag specifying the ordering behavior.
*
* @param initialCapacity
* the initial capacity of this hash map.
* @param loadFactor
* the initial load factor.
* @param accessOrder
* {@code true} if the ordering should be done based on the last
* access (from least-recently accessed to most-recently
* accessed), and {@code false} if the ordering should be the
* order in which the entries were inserted.
* @throws IllegalArgumentException
* when the capacity is less than zero or the load factor is
* less or equal to zero.
*/
public LinkedHashMap(
int initialCapacity, float loadFactor, boolean accessOrder) {
super(initialCapacity, loadFactor);
init();
this.accessOrder = accessOrder;
} 第一个参数是LinkedHashMap的初始化大小,这个很正常,没问题。第二个参数是loadFactor,一个float值,而且LruCache传进来的是0.75f,3/4,这么怪异的数字。我的好奇心被提起来了。可以看到,initialCapacity和loadFactor这两个参数是传进了super方法,好的,我们继续进去父类看,点住super然后control+左键:
/**
* Constructs a new {@code HashMap} instance with the specified capacity and
* load factor.
*
* @param capacity
* the initial capacity of this hash map.
* @param loadFactor
* the initial load factor.
* @throws IllegalArgumentException
* when the capacity is less than zero or the load factor is
* less or equal to zero or NaN.
*/
public HashMap(int capacity, float loadFactor) {
this(capacity);
if (loadFactor <= 0="" ||="" float.isnan(loadfactor))="" {="" throw="" new="" illegalargumentexception("load="" factor:="" "="" +="" loadfactor);="" }="" <="" code="">我们看到capacity被传到另外一个构造方法了,而loadFactor,除了做了一下是否合法的判断之外,竟然,完全没有用到!!! 写这个类的程序员GG还非常善意留下了一个note:这个接口忽略了loadFactor,它默认是用的3/4,这样精简了代码而且通常能够使它表现的更好。一脸懵逼0.0。
我又搜索了一下本类中有没有其他的可以修改loadFactor的地方,终究是没有找到,只找到了一处用它的地方:
private void writeObject(ObjectOutputStream stream) throws IOException {
ObjectOutputStream.PutField fields = stream.putFields();
fields.put("loadFactor", DEFAULT_LOAD_FACTOR);
stream.writeFields();
stream.writeInt(table.length);
stream.writeInt(size);
for (Entry e : entrySet()) {
stream.writeObject(e.getKey());
stream.writeObject(e.getValue());
}
} 在用ObjectOutputStream写入数据的时候,它设置了一个叫做loadFactor的键,其值是一个叫做DEFAULT_LOAD_FACTOR的东西,我看了一下,它是这样定义的:
/**
* The default load factor. Note that this implementation ignores the
* load factor, but cannot do away with it entirely because it's
* mentioned in the API.
*
* Note that this constant has no impact on the behavior of the program,
* but it is emitted as part of the serialized form. The load factor of
* .75 is hardwired into the program, which uses cheap shifts in place of
* expensive division.
*/
static final float DEFAULT_LOAD_FACTOR = .75F; 第一段的注释还是说了这个接口忽略了loadFactor,但是API里面有,所以不能完全的把这个东西封闭起来,第二段呢则是在说这个东西硬编码成了0.75f,提升了性能。然而,看这个loadFactor看了这么久,我们仍然连它是干嘛的都不知道,而且在源码里似乎已经找不到头绪了。没关系,还有最后一招——看官方文档 ! 作为一名Android开发者,我首先上了Android Developer官网,查看HashMap的描述,结果大失所望——并没有相关的任何信息,只是不痛不痒的介绍了一下HashMap的排序以及它的线程不安全。然后我又上了Oracle官网,去查看相关描述,果然找到了:
The load factor is a measure of how full the hash table is allowed to get before its capacity is automatically increased. When the number of entries in the hash table exceeds the product of the load factor and the current capacity, the hash table is rehashed (that is, internal data structures are rebuilt) so that the hash table has approximately twice the number of buckets.
As a general rule, the default load factor (.75) offers a good tradeoff between time and space costs. Higher values decrease the space overhead but increase the lookup cost (reflected in most of the operations of the HashMap class, including get and put). The expected number of entries in the map and its load factor should be taken into account when setting its initial capacity, so as to minimize the number of rehash operations. If the initial capacity is greater than the maximum number of entries divided by the load factor, no rehash operations will ever occur.
文档里面说的很清楚,loadFactor是当哈希表的容量自动增大时允许获得多满的哈希表的一种衡量(此处表述好像有点不清楚)。而一般来说,默认的loadFactor是0.75f,这是设计者在时间和空间的开销上权衡之后得到的最合适的值,如果增大这个值,那么就会使得空间开销变小,但是在时间上的开销将会增大,变小则以此类推。(然而为什么这个值是0.75f我就不知道了,也没有找到相关的资料,甚至不知道这个值是无数的例子总结出来的还是通过某种途径计算出来的,如果有知道的读者还望不吝赐教)
结合官方对于loadFactor的描述以及LinkedHashMap构造方法里面的note,我们基本上可以判定,那个构造方法里面之所以出现传参数传进去了loadFactor然而并没有对它做任何处理这种情况,是由于版本迭代的问题——一开始有那个构造方法的原因是程序员可以根据他的需要自定义loadFactor值,后来官方通过某种途径发现0.75f是最合适的值,在这个值下通常能达到最优的结果,所以就在构造方法里面把对于loadFactor处理的部分删掉了,并且留下了note——有些人会问,为什么不直接把那个构造方法上删掉或者修改一下传参?并不可以,因为也许有一些程序员是在项目里面调用了这个构造方法的,如果擅自修改那么可能会引起非常严重的后果。
ok,LinkedHashMap构造方法的第二个参数的问题基本上说的差不多了,接下来看看第三个参数:accessOrder。显然,这个方法是用来控制排序的。如果其为true,那么LinkedHashMap就是按照最常访问排序,为false则是按照插入时间排序。那么LinkedHashMap是怎么实现最常访问排序的呢?我找了一下这个类里面有关accessOrder的地方,发现其用途都是这样的:
if (accessOrder)
makeTail((LinkedEntry) e);那么很显然,makeTail()方法就是实现最常访问排序的方法了。makeTail()方法是这样写的:
private void makeTail(LinkedEntry e) {
e.prv.nxt = e.nxt;
e.nxt.prv = e.prv;
LinkedEntry header = this.header;
LinkedEntry oldTail = header.prv;
e.nxt = header;
e.prv = oldTail;
oldTail.nxt = header.prv = e;
modCount++;
} LinkedHashMap是一个双向循环链表,这段代码第一步就是将传进去的e节点先剥离出来,然后将其放到剥离之后的链表的尾巴上:
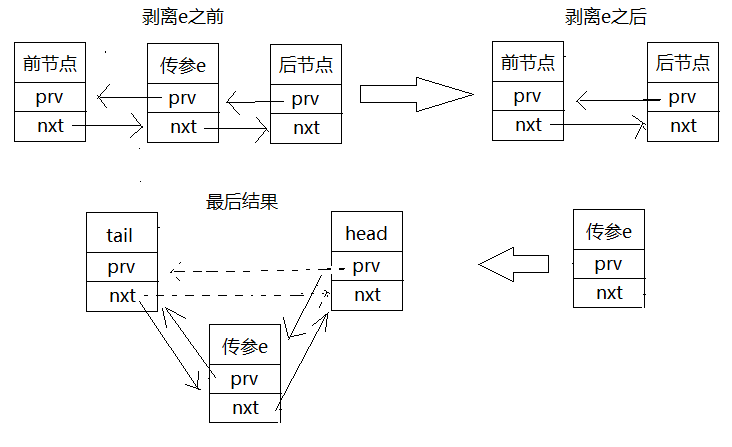
宾果,这样的话LinkedHashMap就在用户进行put或者get操作的时候将用户所操作的那个键值对放到链表的尾巴上,然后最不常使用的那个键值对就是header.nxt,也就是头节点的下一个节点。
到这里LruCache的构造方法就已经剖析的清清楚楚了,接下来看使用的最频繁的get()和put()方法。
get()
/**
* Returns the value for {@code key} if it exists in the cache or can be
* created by {@code #create}. If a value was returned, it is moved to the
* head of the queue. This returns null if a value is not cached and cannot
* be created.
*/
public final V get(K key) {
if (key == null) {
throw new NullPointerException("key == null");
}
V mapValue;
synchronized (this) {
mapValue = map.get(key);
if (mapValue != null) {
hitCount++;
return mapValue;
}
missCount++;
}
V createdValue = create(key);
if (createdValue == null) {
return null;
}
synchronized (this) {
createCount++;
mapValue = map.put(key, createdValue);
if (mapValue != null) {
map.put(key, mapValue);
} else {
size += safeSizeOf(key, createdValue);
}
}
if (mapValue != null) {
entryRemoved(false, key, createdValue, mapValue);
return mapValue;
} else {
trimToSize(maxSize);
return createdValue;
}
} 一开始是判断key的合法性,很正常。接下来就是一个同步块,在里面进行获取key对应的值的操作——因为LinkedHashMap是线程不安全的,如果不在同步块里面进行获得值的操作的话有可能会出现无法预知的后果。注意,在执行完 map.get(key) 语句之后,LinkedHashMap中传入的key对应的键值对就已经处于双向链表的尾端,即最常使用的位置了。
如果key对应的value为null,那么将会调用create()方法。这个方法默认返回的是null,也就意味着如果不主动重写这个方法的话LruCache是不会帮你自动创建key对应的键值的。
接下来的一个同步块里面做的事情是,如果用户重写了create()方法的话,那么就对create()生成的东西进行存储。中间还涉及了一个获取key此时对应的键值是否为null的判断,如果不为null的话就抛弃create()生成的值,而使用此时key对应的值——因为create()方法没有在同步块中,有可能当create()了一个key的值之后这个key对应的值已经并不是null了(有可能此时key已经被put了值进去)。其实我个人觉得在大部分情况下create()方法以及其后面的这一段代码能够得到应用的情况是非常少的,毕竟通常的做法是发现key对应的值是null然后就发起网络请求获取key对应的值,然后将其put到LinkedHashMap里面去,而不会去重写create()方法,在key对应null的时候生成一个值。
第二个同步块里面在成功放入create的mapValue之后进行了一个trimToSize()的操作,很显然,这是在控制LinkedHashMap的大小,剔除最不常使用的变量,它的具体写法是这样的:
/**
* Remove the eldest entries until the total of remaining entries is at or
* below the requested size.
*
* @param maxSize the maximum size of the cache before returning. May be -1
* to evict even 0-sized elements.
*/
public void trimToSize(int maxSize) {
while (true) {
K key;
V value;
synchronized (this) {
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(getClass().getName()
+ ".sizeOf() is reporting inconsistent results!");
}
if (size <= maxsize)="" {="" break;="" }="" map.entry toEvict = map.eldest();
if (toEvict == null) {
break;
}
key = toEvict.getKey();
value = toEvict.getValue();
map.remove(key);
size -= safeSizeOf(key, value);
evictionCount++;
}
entryRemoved(true, key, value, null);
}
} 这里有一个很有意思的地方。首先外层的while循环是理所当然的,必须要不停地剔除最不常使用的变量直到LruCache缓存的大小小于预定的maxSize。在同步块里面首先进行了一次合法性判定,如果size < 0或者明明map是空的然而size != 0的话就抛出一个异常。接下来如果size <= maxsize就return,表示大小已经合格。那么怪异的地方来了,接下来一个if判断。Map.Entry toEvict = map.eldest(),即toEvict 是map里面最不常使用的值,我们来点进去map.eldest()看一下:
/**
* Returns the eldest entry in the map, or {@code null} if the map is empty.
* @hide
*/
public Entry eldest() {
LinkedEntry eldest = header.nxt;
return eldest != header ? eldest : null;
} 确实,返回的是map里面最不常使用的值,如果map为空的话那么返回的就是null。我们再回到trimToSize()方法看刚才那个if判断。如果if判断成立,那么可以判断map为空——因为toEvict == null。我们现在来总结一下在这个方法里面到目前为止得到的结论:
- size >= 0
- !(map.isEmpty() && size != 0)
- size > maxSize
- map.isEmpty == true
从这些结论里面, 我们可以很容易的得出另一个结论:maxSize < 0。那么问题就来了,进入那个if判断就意味着maxSize < 0,而只要出现这个情况,显然是非法的,那么为什么设计这个类的作者在这里只是简单的break了而不是抛出一个异常告诉用户此处有误?匪夷所思。
想了一会儿,我觉得之所以作者没有在这里抛出一个异常是因为代码根本没有可能进入这个if判断。因为刚刚推理得到的结论 maxSize < 0 其实也是进入这个判断的条件,但是 maxSize 根本不会出现小于0的情况——所有能设置 maxSize 的地方都对其合法性做了判断,如果它小于0的话早就抛出异常了。那么这里这个if判断为什么会出现呢?唯一的解释就是作者有代码洁癖,如果这里不加一个对于null的判断的话,后面会在用到toEvict出现一个黄色警告,所以作者习惯性的做了个判断。
put()
先贴上源码:
/**
* Caches {@code value} for {@code key}. The value is moved to the head of
* the queue.
*
* @return the previous value mapped by {@code key}.
*/
public final V put(K key, V value) {
if (key == null || value == null) {
throw new NullPointerException("key == null || value == null");
}
V previous;
synchronized (this) {
putCount++;
size += safeSizeOf(key, value);
previous = map.put(key, value);
if (previous != null) {
size -= safeSizeOf(key, previous);
}
}
if (previous != null) {
entryRemoved(false, key, previous, value);
}
trimToSize(maxSize);
return previous;
} 分析了前面的那些东西之后,再来看这个put()方法就很简单了,里面的逻辑还有涉及的方法都很清晰,就不多说了。
结语
看到最后,发现这原来不是Picasso的那个LruCache,是官方的那个LruCache…
然后我又去看了Picasso的那个LruCache,发现竟然感觉比官方那个看起来还要好看一点…
