

实习期间一直在用golang,今天想写篇博客,聊聊我对golang的一些思考,以及分析下groupcache的实现;
在没接触golang之前,在我的印象里,服务器开发就是常见的nginx多进程,memcache多线程,redis单线程;后来,golang这种多协程,一个连接对应一个协程的模式深深吸引了我,相比进程,线程,协程粒度相对较小,协程切换代价与进程和线程相比是非常小的,因此一个连接对应一个协程才得以行得通;
golang很适合写服务,首先是语言层面支持高并发,其次是对http和rpc接口封装,用户在写c/s架构服务器时,既可以用基于http的rest api接口实现客户端和服务器端的通信,同时还可以用rpc实现客户端和服务器端的通信,而且支持多种数据格式传输,例如xml,json,gob等等;最后就是部署简单,生成可执行文件,直接运行;
学习golang,首先是学习基础语法,这个网上有很多教程,有一本《Go语言编程》很适合入门;其次就需要学习go语言层面底层的一些东西,例如协程切换,socket编程原理以及gc等等;这是非常有必要的,因为了解这些,对golang的使用会更加得心应手;例如golang网络编程,是怎么通知某个描述符有事件到达的?协程一开始阻塞在read调用中,当有数据达到之后,是怎么被唤醒的?等;我推荐两本gitbook,一个适合入门,一个适合深入:
在了解基础于语法以及一些底层原理之后,我觉得可以看看golang自带的框架,写的非常棒,很适合学习,特别是http和rpc,因为学习这两个框架可以了解到一次http请求是如何实现的,以及一次rpc过程是怎么实现的;当然还有一些第三方开源框架也写得很好;
ok,下面就来看看缓存库groupcache是怎么实现的。
groupcache存储的是kv结构,同是memcache作者出品,官方github上说明如下:
groupcache is a caching and cache-filling library, intended as a replacement for memcached in many cases.
也就是说groupcache是一个kv缓存,用于在某些方面替代memcache,但是我在学习了这个框架之后,我发现这个框架的适用场景并不多,因为groupcache只能get,不能update和delete,也不能设置过期时间,只能通过lru淘汰最近最少访问的数据;有些数据如果长时间不更改,那么可以用groupcache作为缓存;groupcache已经在dl.Google.com、Blogger、Google Code、Google Fiber、Google生产监视系统等项目中投入使用。
但是groupcache还是有它的优点的,groupcache既是服务器,也是客户端,当在本地groupcache缓存中没有查找的数据时,通过一致性哈希,查找到该key所对应的peer服务器,在通过http协议,从该peer服务器上获取所需要的数据;还有一点就是当多个客户端同时访问memcache中不存在的键时,会导致多个客户端从mysql获取数据并同时插入memcache中,而在相同情况下,groupcache只会有一个客户端从mysql获取数据,其他客户端阻塞,直到第一个客户端获取到数据之后,再返回给多个客户端;
groupcache是一个缓存库,也就是说不是一个完整的软件,需要自己实现main函数。可以自己写个测试程序,跑跑groupcache,我看了有些博客是直接引用Playing With Groupcache这篇博客的测试程序,这个测试程序,客户端和groupcache通过rpc进行通信,而groupcache peer之间通过http协议进行通信;这是比较好的做法,因为如果客户端与服务器通信和groupcache之间通信采用的是同一个端口,那么在并发量上去的时候,会严重影响性能;下图是这个测试程序的架构图:
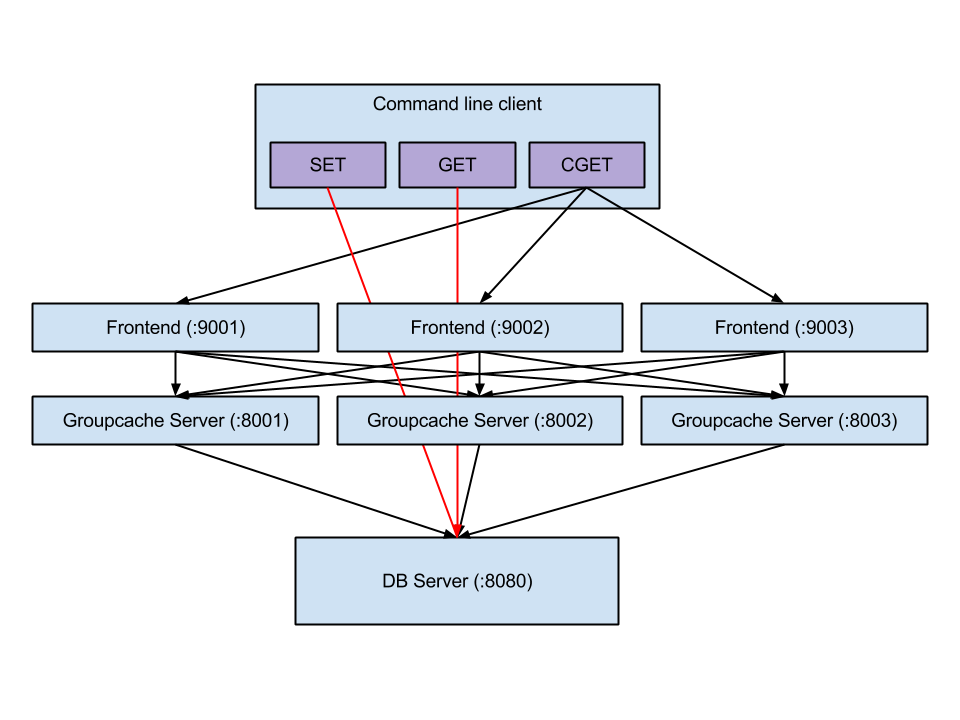
这个原理就是如果客户端用的是set或get命令时,这时直接操作的是数据源(数据库或文件),如果调用的是cget命令,则从groupcache中查找数据;
groupcache内部实现了lru和一致性哈希,我觉得大家可以看看,学习golang是如何实现lru和一致性哈希。下面简单分析groupcache Get函数的实现以及peer之间的通信;
groupcache Get函数实现
当客户端连上groupcache时,能做的只有get获取数据,如果本地有所需要的数据,则直接返回,如果没有,则通过一致性哈希函数判断这个key所对应的peer,然后通过http从这个peer上获取数据;如果这个peer上有需要的数据,则通过http回复给之前的那个groupcache;groupcache收到之后,保存在本地hotCache中,并返回给客户端;如果peer上也没有所需要的数据,则groupcache从数据源(数据库或者文件)获取数据,并将数据保存在本地mainCache,并返回给客户端;
func (g *Group) Get(ctx Context, key string, dest Sink) error {
g.peersOnce.Do(g.initPeers)
g.Stats.Gets.Add(1)
if dest == nil {
return errors.New("groupcache: nil dest Sink")
value, cacheHit := g.lookupCache(key)
if cacheHit {
g.Stats.CacheHits.Add(1)
return setSinkView(dest, value)
destPopulated := false
value, destPopulated, err := g.load(ctx, key, dest)
if err != nil {
return err
if destPopulated {
return nil
return setSinkView(dest, value)这个Get函数很简单,先检查本地cache是否存在,存在即返回,不存在则向peer获取,接下来看下load函数是如何实现的;
func (g *Group) load(ctx Context, key string, dest Sink) (value ByteView, destPopulated bool, err error) {
g.Stats.Loads.Add(1)
viewi, err := g.loadGroup.Do(key, func() (interface{}, error) {
if value, cacheHit := g.lookupCache(key); cacheHit {
g.Stats.CacheHits.Add(1)
return value, nil
g.Stats.LoadsDeduped.Add(1)
var value ByteView
var err error
if peer, ok := g.peers.PickPeer(key); ok {
value, err = g.getFromPeer(ctx, peer, key)
if err == nil {
g.Stats.PeerLoads.Add(1)
return value, nil
g.Stats.PeerErrors.Add(1)
value, err = g.getLocally(ctx, key, dest)
if err != nil {
g.Stats.LocalLoadErrs.Add(1)
return nil, err
g.Stats.LocalLoads.Add(1)
destPopulated = true
g.populateCache(key, value, &g.mainCache)
return value, nil
if err == nil {
value = viewi.(ByteView)
return这个load函数先是从peer获取数据,如果peer没有数据,则直接从数据源(数据库或文件)获取数据;ok,先看下groupcache是如何从数据源获取数据,然后再分析下如果从peer中获取数据;
func (g *Group) getLocally(ctx Context, key string, dest Sink) (ByteView, error) {
err := g.getter.Get(ctx, key, dest)
if err != nil {
return ByteView{}, err
return dest.view()getLocallly函数主要是利用NewGroup创建Group时传进去的Getter,在调用这个Getter的Get函数从数据源获取数据。
func NewGroup(name string, cacheBytes int64, getter Getter) *Group {
return newGroup(name, cacheBytes, getter, nil)也就是说当groupcache以及peer不存在所需数据时,用户可以自己定义从哪获取数据以及如何获取数据,即定义Getter的实例即可;
从peer获取数据
当本地groupcache中不存在数据时,会先从peer处获取数据,我们来看下getFromPeer函数实现
func (g *Group) getFromPeer(ctx Context, peer ProtoGetter, key string) (ByteView, error) {
req := &pb.GetRequest{
Group: &g.name,
Key: &key,
res := &pb.GetResponse{}
err := peer.Get(ctx, req, res)
if err != nil {
return ByteView{}, err
value := ByteView{b: res.Value}
if rand.Intn(10) == 0 {
g.populateCache(key, value, &g.hotCache)
return value, nil这个ProtoGetter是个接口,httpGetter结构体实现了这个接口,而上述传进getFromPeer函数的peer就是httpGetter,因此,我们可以来看下httpGet这个结构体的Get函数
func (h *httpGetter) Get(context Context, in *pb.GetRequest, out *pb.GetResponse) error {
u := fmt.Sprintf(
"%v%v/%v",
h.baseURL,
url.QueryEscape(in.GetGroup()),
url.QueryEscape(in.GetKey()),
req, err := http.NewRequest("GET", u, nil)
if err != nil {
return err
tr := http.DefaultTransport
if h.transport != nil {
tr = h.transport(context)
res, err := tr.RoundTrip(req)
if err != nil {
return err
defer res.Body.Close()
if res.StatusCode != http.StatusOK {
return fmt.Errorf("server returned: %v", res.Status)
b := bufferPool.Get().(*bytes.Buffer)
b.Reset()
defer bufferPool.Put(b)
_, err = io.Copy(b, res.Body)
if err != nil {
return fmt.Errorf("reading response body: %v", err)
err = proto.Unmarshal(b.Bytes(), out)
if err != nil {
return fmt.Errorf("decoding response body: %v", err)
return nil这个函数首先向peer发起一个http请求,然后将请求得到的封装在out *pb.GetResponse,返回给getFromPeer,并最终返回给客户端;
这篇文章主要是聊聊我对学习golang的一些看法,以及分析下groupcache的实现原理,分析的不是很细,主要是对这个框架进行了分析,对groupcache有了整体的认识之后,再去看细节部分,会简单很多。
这几天再看sqlmock开源框架,这个主要作用就是,在单元测试时用来模拟数据库操作;主要原理就是实现一个驱动程序。在看这个sqlmock过程中,首先必须把database/sql以及go-sql-driver看懂,知道这两个是如何一起运作的,这样才能了解sqlmock的实现;过几天再把database/sql以及go-sql-driver的实现原理发出来。
