

日志是分析线上问题的重要手段,通常我们会把日志输出到控制台或者本地文件中,排查问题时通过根据关键字搜索本地日志,但越来越多的公司,项目开发中采用分布式的架构,日志会记录到多个服务器或者文件中,分析问题时可能需要查看多个日志文件才能定位问题,如果相关项目不是一个团队维护时沟通成本更是直线上升。把各个系统的日志聚合并通过关键字链接一个事务处理请求,是分析分布式系统问题的有效的方式。
ELK(elasticsearch+logstash+kibana)是目前比较常用的日志分析系统,包括日志收集(logstash),日志存储搜索(elasticsearch),展示查询(kibana),我们使用ELK作为日志的存储分析系统并通过为每个请求分配requestId链接相关日志。ELK具体结构如下图所示:
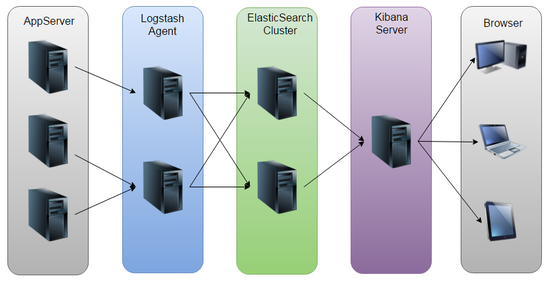
1、安装logstash
logstash需要依赖jdk,安装logstash之前先安装java环境。
下载JDK:
在oracle的官方网站下载,http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
根据操作系统的版本下载对应的JDK安装包,本次实验下载的是jdk-8u101-linux-x64.tar.gz
上传文件到服务器并执行:
# mkdir /usr/local/java
# tar -zxf jdk-8u45-linux-x64.tar.gz -C /usr/local/java/
配置java环境
export JAVA_HOME=/usr/local/java/jdk1.8.0_45
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$CLASSPATH
执行java -version命令,打印出java版本信息表示JDK配置成功。

下载logstash:
wget https://download.elastic.co/logstash/logstash/logstash-2.4.0.tar.gz
tar -xzvf logstash-2.4.0.tar.gz
进入安装目录: cd #{dir}/logstash-2.4.0
创建logstash测试配置文件:
vim test.conf
编辑内容如下:
input {
stdin { }
}
output {
stdout {
codec => rubydebug {}
}
}
运行logstash测试:
bin/logstash -f test.conf
显示

证明logstash已经启动了,
输入hello world
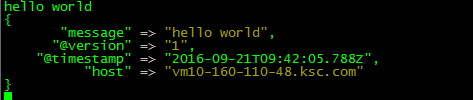
因为我们配置内容为,控制台输出日志内容,所以显示以上格式即为成功。
2、安装elasticsearch
下载安装包:
wget https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/tar/elasticsearch/2.4.0/elasticsearch-2.4.0.tar.gz
解压并配置:
tar -xzvf elasticsearch-2.4.0.tar.gz
cd #{dir}/elasticsearch-2.4.0
vim config/elasticsearch.yml
修改:
path.data: /data/es #数据路径
path.logs: /data/logs/es #日志路径
network.host: 本机地址 #服务器地址
http.port: 9200 #端口
配置执行用户和目录:
groupadd elsearch
useradd elsearch -g elsearch -p elasticsearch
chown -R elsearch:elsearch elasticsearch-2.4.0
mkdir /data/es
mkdir /data/logs/es
chown -R elsearch:elsearch /data/es
chown -R elsearch:elsearch /data/logs/es
启动elasticsearch:
su elsearch
bin/elasticsearch
通过浏览器访问:
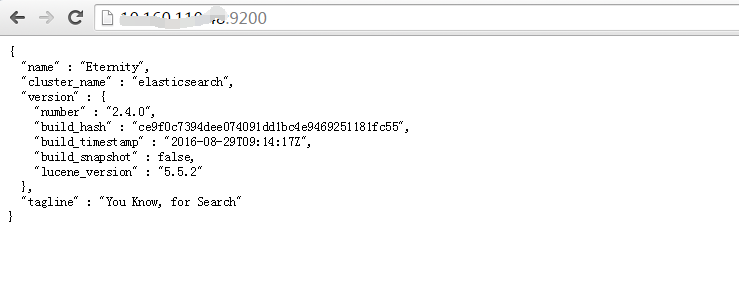
安装成功.
集成logstash和elasticsearch,修改Logstash配置为:
input {
stdin { }
}
output {
elasticsearch {
hosts => "elasticsearchIP:9200"
index => "logstash-test"
}
stdout {
codec => rubydebug {}
}
}
再次启动logstash,并输入任意文字:“hello elasticsearch”

通过elasticsearch搜索到了刚才输入的文字,集成成功。
但是通过elasticsearch的原生接口查询和展示都不够便捷直观,下面我们配置一下更方便的查询分析工具kibana。
3、安装kibana
下载安装包:
wget https://download.elastic.co/kibana/kibana/kibana-4.6.1-linux-x86_64.tar.gz
解压kibana,并进入解压后的目录
打开config/kibana.yml,修改如下内容
#启动端口 因为端口受限 所以变更了默认端口
server.port: 8601
#启动服务的ip
server.host: “本机ip”
#elasticsearch地址
elasticsearch.url: “http://elasticsearchIP:9200”
启动程序:
bin/kibana
访问配置的ip:port,在discover中搜索刚才输入的字符,内容非常美观的展示了出来。
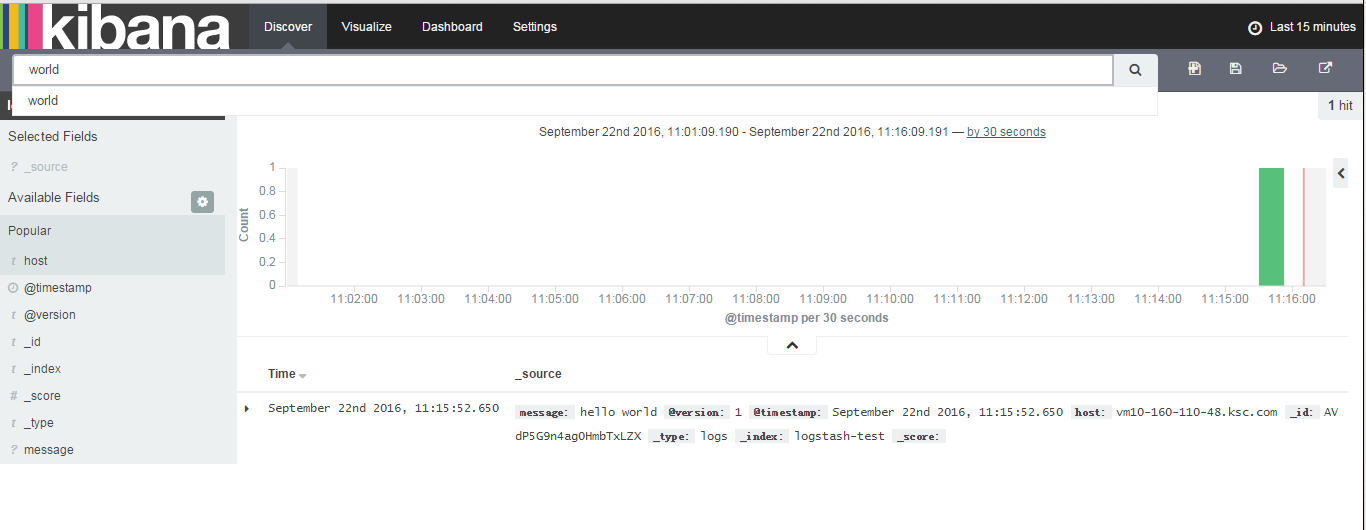
到这里我们的elk环境已经配置完成了,我们把已java web项目试验日志在elk中的使用。
4、创建web工程
一个普通的maven java web工程,为了测试分布式系统日志的连续性,我们让这个项目自调用n次,并部署2个项目,相互调用,关键代码如下:
@RequestMapping("http_client")
@Controller
public class HttpClientTestController {
@Autowired
private HttpClientTestBo httpClientTestBo;
@RequestMapping(method = RequestMethod.POST)
@ResponseBody
public BaseResult doPost(@RequestBody HttpClientTestResult result) {
HttpClientTestResult testPost = httpClientTestBo.testPost(result);
return testPost;
}
}
@Service
public class HttpClientTestBo {
private static Logger logger = LoggerFactory.getLogger(HttpClientTestBo.class);
@Value("${test_http_client_url}")
private String testHttpClientUrl;
public HttpClientTestResult testPost(HttpClientTestResult result) {
logger.info(JSONObject.toJSONString(result));
result.setCount(result.getCount() + 1);
if (result.getCount() <= 3) {
Map<String, String> headerMap = new HashMap<String, String>();
String requestId = RequestIdUtil.requestIdThreadLocal.get();
headerMap.put(RequestIdUtil.REQUEST_ID_KEY, requestId);
Map<String, String> paramMap = new HashMap<String, String>();
paramMap.put("status", result.getStatus() + "");
paramMap.put("errorCode", result.getErrorCode());
paramMap.put("message", result.getMessage());
paramMap.put("count", result.getCount() + "");
String resultString = JsonHttpClientUtil.post(testHttpClientUrl, headerMap, paramMap, "UTF-8");
logger.info(resultString);
}
logger.info(JSONObject.toJSONString(result));
return result;
}
}
为了表示调用的链接性我们在web.xml中配置requestId的filter,用于创建requestId:
requestIdFilter
com.virxue.baseweb.utils.RequestIdFilter
requestIdFilter
/*
public class RequestIdFilter implements Filter {
private static final Logger logger = LoggerFactory.getLogger(RequestIdFilter.class);
/* (non-Javadoc)
* @see javax.servlet.Filter#init(javax.servlet.FilterConfig)
*/
public void init(FilterConfig filterConfig) throws ServletException {
logger.info("RequestIdFilter init");
}
/* (non-Javadoc)
* @see javax.servlet.Filter#doFilter(javax.servlet.ServletRequest, javax.servlet.ServletResponse, javax.servlet.FilterChain)
*/
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException,
ServletException {
String requestId = RequestIdUtil.getRequestId((HttpServletRequest) request);
MDC.put("requestId", requestId);
chain.doFilter(request, response);
RequestIdUtil.requestIdThreadLocal.remove();
MDC.remove("requestId");
}
/* (non-Javadoc)
* @see javax.servlet.Filter#destroy()
*/
public void destroy() {
}
}
public class RequestIdUtil {
public static final String REQUEST_ID_KEY = "requestId";
public static ThreadLocal<String> requestIdThreadLocal = new ThreadLocal<String>();
private static final Logger logger = LoggerFactory.getLogger(RequestIdUtil.class);
/**
* 获取requestId
* @Title getRequestId
* @Description TODO
* @return
*
* @author sunhaojie 3113751575@qq.com
* @date 2016年8月31日 上午7:58:28
*/
public static String getRequestId(HttpServletRequest request) {
String requestId = null;
String parameterRequestId = request.getParameter(REQUEST_ID_KEY);
String headerRequestId = request.getHeader(REQUEST_ID_KEY);
if (parameterRequestId == null && headerRequestId == null) {
logger.info("request parameter 和header 都没有requestId入参");
requestId = UUID.randomUUID().toString();
} else {
requestId = parameterRequestId != null ? parameterRequestId : headerRequestId;
}
requestIdThreadLocal.set(requestId);
return requestId;
}
}
我们使使用了Logback作为日志输出的插件,并且使用它的MDC类,可以无侵入的在任何地方输出requestId,具体的配置如下:
UTF-8
${log_base}/java-base-web.log
${log_base}/java-base-web-%d{yyyy-MM-dd}-%i.log
10
200MB
%d^|^%X{requestId}^|^%-5level^|^%logger{36}%M^|^%msg%n
这里的日志格式使用了“^|^”做为分隔符,方便logstash进行切分。在测试服务器部署2个web项目,并且修改日志输出位置,并修改url调用链接使项目相互调用。
5、修改logstash读取项目输出日志:
新增stdin.conf,内容如下:
input {
file {
path => ["/data/logs/java-base-web1/java-base-web.log", "/data/logs/java-base-web2/java-base-web.log"]
type => "logs"
start_position => "beginning"
codec => multiline {
pattern => "^\[\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}"
negate => true
what => "next"
}
}
}
filter{
mutate{
split=>["message","^|^"]
add_field => {
"messageJson" => "{datetime:%{[message][0]}, requestId:%{[message][1]},level:%{[message][2]}, class:%{[message][3]}, content:%{[message][4]}}"
}
remove_field => ["message"]
}
}
output {
elasticsearch {
hosts => "10.160.110.48:9200"
index => "logstash-${type}"
}
stdout {
codec => rubydebug {}
}
}
其中path为日志文件地址;codec => multiline为处理Exception日志,使换行的异常内容和异常头分割在同一个日志中;filter为日志内容切分,把日志内容做为json格式,方便查询分析;
测试一下:
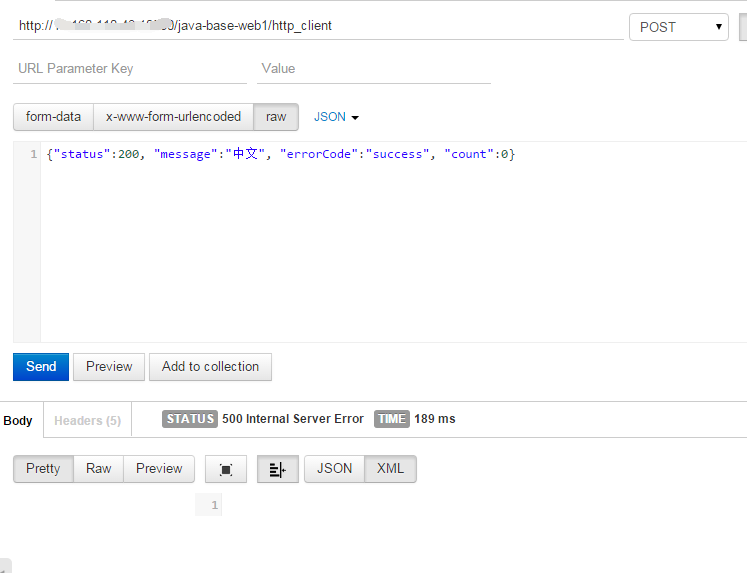
使用POSTMan模拟调用,提示服务器端异常:
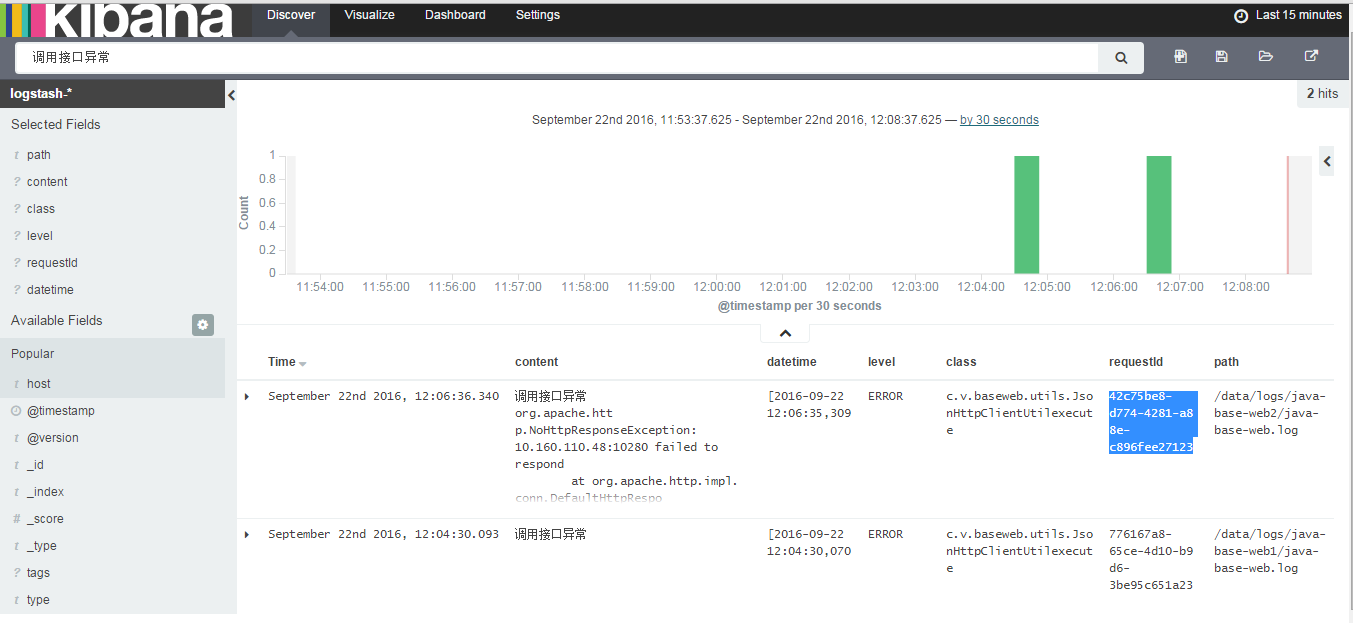
通过界面搜索”调用接口异常”,共两条数据。
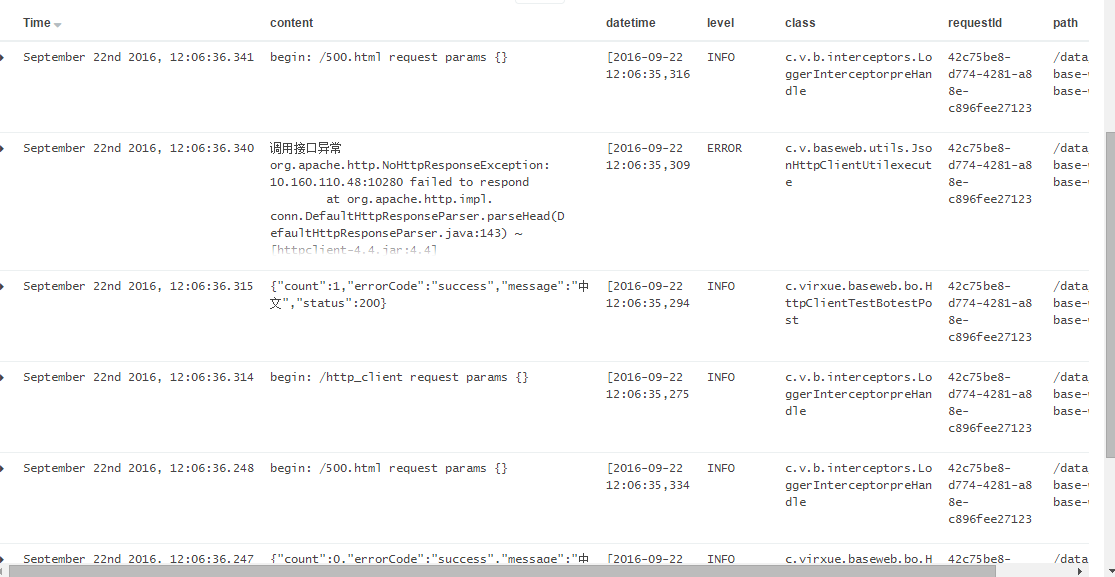
使用其中一条数据的requestId搜索,展示出了请求再系统中和系统间的执行过程,方便了我们排查错误。
到这里我们实验了使用elk配置日志分析,其中很多细节需要更好的处理,欢迎更多的同学交流学习。
转载请注明:孙豪杰的博客 » ELK(elasticsearch+logstash+kibana)实现Java分布式系统日志分析架构
