

作者:Vik Paruchuri
译者:Nick Tang
校对:EarlGrey
出品:PythonTG 翻译组/编程派(微信公众号ID:codingpy)
这是「如何打造数据科学作品集」系列教程的第一篇。如果觉得不错,可以订阅我们第一时间获取最新更新。这个系列的文章都很长,建议先收藏再找时间详细阅读。如果你觉得译文读起来不舒服,可以点此阅读原文,并给我们提些改建建议。
数据科学公司在招聘时越来越看重个人作品集,原因在于作品集是衡量实际能力最好的方式之一。好消息是,你完全掌控着自己的作品集。如果付出一些努力,你就可以打造一套令用人单位印象深刻的高质量作品集。
想要打造高质量作品集,第一步需要搞清楚应该在作品中展现什么能力。公司希望数据科学家具备的能力(也就是他们希望作品集能够展示的能力)包括:
- 沟通能力
- 与他人协作能力
- 技术能力
- 数据推断能力
- 主观能动性
一个好的作品集一般由多个项目构成,每一个项目展示以上 1-2 个能力点。本文是教你怎样打造一个全面的数据科学作品系列的第一篇。我们将介绍怎样打造作品集中的第一个项目,怎样使用数据讲述一个有效的故事。本篇结束时,你将拥有一个展示沟通能力和数据推断能力的数据科学项目。
用数据讲故事
数据科学的本质是沟通。你通过数据得到了一些洞察,然后采用有效的方式将其传播给他人,并向其推销你的解决方案。可见使用数据来讲述一个有效的故事,是数据科学家最重要的技能之一。一个有效的故事可以使你的洞察更有说服力,同时能帮助他人理解你的观点。
数据科学中的故事需要围绕着你发现了什么,怎么发现的,意味着什么进行讲述。举个例子,你发现公司利润去年下降了25%。仅仅阐述这个事实是不够的,你必须说明为什么利润会下降,可以通过什么方式来解决。
用数据讲故事的要点如下:
- 搞清楚并且设置故事的上下文
- 从多个角度进行探索
- 有说服力的形象化展示
- 使用多种数据源
- 叙述的一致性
这里最有效的工具是 Jupyter notebook。如果你对此不是很熟悉,请参考这个教程。Jupyter notebook 允许你交互式的探索数据,支持将结果分享到多个网站,包括 Github 。通过分享,他人可以很好的与你协作,并扩充你的成果。
我们会在文中使用 Jupyter notebook 以及一些 Python 数据科学库,如 Pandas 和 matplotlib。
选择项目主题
创建项目的第一步是决定主题。你需要选择感兴趣且有动力去研究的题目。我们都知道为了做项目而做,还是真的感兴趣去做,这之间有巨大区别。因此这一步值得多花点功夫,确保能够找到真正感兴趣的东西。
寻找题目的一个好办法是浏览不同的数据集,看看有什么有趣的东西。这里推荐一些好的站点:
一般现实中,你拿到的经常不是一个完美的单个数据集。通常需要聚合不同的数据源,或者做大量的数据清理工作。当选题对你来说真的非常有意思,多花点时间去处理数据是非常值得的,同时在这个过程中你也可以炫耀一下技能。
本文我们使用纽约市公立学校的数据,你可以在这里得到它们。
选定题目
能够从一而终的完成项目是非常重要的。因此,限制项目的范围非常关键,这可以让我们清楚地知道我们可以完成它。
本文中,我们着眼于美国高中生的SAT 成绩以及其他统计数据来做数据分析。SAT(Scholastic Aptitude Test) 是美国高中生申请大学前参加的一项考试。大学在作出是否入取决定时会参考考试成绩。这个考试分为三个部分,每部分 800 分,总分 2400 (虽然总分曾改来改去很多次,但在这个数据集里仍是2400)。各高中经常以 SAT 的平均成绩进行排名,SAT 成绩高代表着这个学区的高品质。
有人提出 SAT 对美国的某些种族人群不公平,因此对纽约市的数据进行分析可以帮组我们进一步搞清楚 SAT 考试的公平性。
从这里获得SAT数据及各高中数据。这将是项目的基础,但是我们还需要更多的信息来确保有说服力的分析。
补充数据
一旦找到了好题目,接下来去多找一些有助于这个题目或者能使你更进一步深入研究的数据集。最好提前准备,以便在开始建立项目前拥有尽可能多的数据。通常过少的数据意味着过早的放弃项目。
在这个项目里,某个网站上就有多个相关数据集,包括了生源统计信息以及测试分数等。
这里是所有将使用数据集的链接:
所有的这些数据集是相互关联的,我们可以在分析前先组合他们。
获取背景信息
在深入分析数据之前,调查一些背景信息非常有用。本例中,我们已知一些非常有用的信息:
- 纽约市有五个区,各自是独立的区域。
- 所有学校分布在各个学区里,每个区包含数十个学校。
- 数据集里的学校并非都是高中,因此我们需要做一些数据清理工作。
- 每所有学校都有一个DBN (District Borough Number)唯一编号。
- 通过聚合每个区的数据,我们可以绘制出各个区域之间的差异。
理解数据
为了能够真正理解这些数据的上下文,你要花点时间去探索数据。上面每个链接都有一些关于数据及相关列的描述。我们手里有高中生的 SAT 成绩,以及生源信息等其他数据集。
我们可以执行代码来读取数据。使用 Jupyter notebook 来探索这些数据,下面的代码将:
- 遍历每个下载的数据文件
- 把文件数据读入到Pandas DataFrame
- 将 DataFrame 统一放入一个Python字典
import pandas
import numpy as np
files = ["ap_2010.csv", "class_size.csv", "demographics.csv", "graduation.csv", "hs_directory.csv", "math_test_results.csv", "sat_results.csv"]
data = {}
for f in files:
d = pandas.read_csv("schools/{0}".format(f))
data[f.replace(".csv", "")] = d
数据读入后,我们可以在 DataFrames 上使用 head 方法打印前 5 行数据:
for k,v in data.items():
print("\n" + k + "\n")
print(v.head())

可以发现数据集中的一些明显特征:
- 大多数数据集包含 DBN 列。
- 一些字段对绘图有用,特别是 Location 1,其中包含了坐标信息。
- 一些数据集似乎包含一个学校的多条信息(重复的 DBN ),这意味着我们必须做一些预处理。
统一数据
为了更容易的处理数据,我们需要将所有的单个数据集集中到一个数据集里。这样可以让我们更快的比较数据集之间的列。为了做到这一点,第一步我们需要找到一个统一的公共列。从上面的输出结果来看,你会发现 DBN 出现在大多数的数据集里,看起来可以用作公共列。
如果我们谷歌一下 DBN New York City Schools,会找到这个页面,解释了 DBN 是每一个学校的唯一编号。当我们探索数据集,特别是政府数据集时,为了搞清楚每一个列的意思,做一些调查工作是必不可少的。
现在有个问题,class_size 和 hs_directory 数据集没有发现 DBN 字段。hs_directory 数据集只有 dbn 字段,我们可以通过重命名这个列或者把它拷贝到一个DBN 的新列来解决。而对 class_size 数据集,我们需要采用其他办法来处理。
DBN 列看起来像这样:
data["demographics"]["DBN"].head()
0 01M015
1 01M015
2 01M015
3 01M015
4 01M015
Name: DBN, dtype: object
我们再看一眼 class_size 的前 5 行数据:
data["class_size"].head()

如上图所见,看起来 DBN 实际上是由CSD、 BOROUGH 和 SCHOOL CODE 组合而成。DBN 全称为 District Borough Number 。csd 字段表示 District,BOROUGH 字段表示 borough,再与 SCHOOL CODE 字段一起最终组成DBN。
想洞察数据之间的这种关系并没有什么系统化的方法,只能经过探索和尝试来找到答案。
现在我们知道怎样构建 DBN 了,可以把它添加到 class_size 和 hs_directory 数据集里:
data["class_size"]["DBN"] = data["class_size"].apply(lambda x: "{0:02d}{1}".format(x["CSD"], x["SCHOOL CODE"]), axis=1)
data["hs_directory"]["DBN"] = data["hs_directory"]["dbn"]
添加调查数据
最有趣的数据集之一,应该是学生、父母、老师的问卷调查数据,囊括了对每个学校的安全程度、学术水平等等反馈数据。在组合数据集之前,让我们添加这些调查数据。现实工作中,分析数据的途中你经常会碰到你想要加入的有趣数据。使用Jupyter notebook 这样灵活的工具,可以让你快速添加额外代码,并且重新运行你的分析。
我们将要添加调查数据到我们的 data 字典里,然后再组合所有的数据集。调查数据包含两个文件,一个针对所有学习,一个是针对 75 区的学校。我们需要写一些代码来组合。在下面的代码中,我们将
- 使用 windows-1252 编码读入所有学校的数据。
- 使用 windows-1252 编码读入 75 区学校的数据。
- 添加一个 flag 来数据来自哪个区。
- 使用 DataFrames 的 concat 方法来合并以上数据。
survey1 = pandas.read_csv("schools/survey_all.txt", delimiter="\t", encoding='windows-1252')
survey2 = pandas.read_csv("schools/survey_d75.txt", delimiter="\t", encoding='windows-1252')
survey1["d75"] = False
survey2["d75"] = True
survey = pandas.concat([survey1, survey2], axis=0)
一旦我们完成调查数据的合并,还有一个复杂的事情要处理。为了方便进行比较和找出列直接
关联,我们需要减少数据集中的列数。不幸的是,调查数据里包含太多对我们没有用的列:
survey.head()

我们可以通过查看与调查数据一起下载下来的数据字典文件,来找出我们需要的重要字段去简化列:

这样我们就可以删除 survey 中多余的列:
survey["DBN"] = survey["dbn"]
survey_fields = ["DBN", "rr_s", "rr_t", "rr_p", "N_s", "N_t", "N_p", "saf_p_11", "com_p_11", "eng_p_11", "aca_p_11", "saf_t_11", "com_t_11", "eng_t_10", "aca_t_11", "saf_s_11", "com_s_11", "eng_s_11", "aca_s_11", "saf_tot_11", "com_tot_11", "eng_tot_11", "aca_tot_11",]
survey = survey.loc[:,survey_fields]
data["survey"] = survey
survey.shape
确保你能够理解每个数据集包含什么,相关列是什么,可以为日后分析节省很多的时间和精力。
压缩数据集
再次看一下数据集,我们马上发现一个新的问题:
data["class_size"].head()

class_size 中对应一个高中存在多行数据(及重复的 DBN 和 SCHOOL NAME )。然而 sat_results 里每个高中只有一条数据:
data["sat_results"].head()

为了能够联合数据集,我们需要找到一种方式来保证一个高中对应一行数据。如果不这样做,我们将无法比较 SAT 成绩与班级大小。首先我们需要更好地理解数据,然后做一些聚合。在 class_size 数据集里,GRADE 和 PROGRAM TYPE 字段对于一个学校存在多个值。通过限制一个字段只有一个值,我们可以过滤掉大部分的重复行。在下面的代码中,我们将:
- 仅仅保留 class_size 中GRADE 字段是 09-12 的值。
- 仅仅保留 class_size 中 PROGRAM TYPE 是 GEN ED 的值。
- 按 DBN 进行group,计算每个列的平均值,得到每所学校平均的 class_size 值。
- 重置索引,将 DBN 作为列重新加回。
class_size = data["class_size"]
class_size = class_size[class_size["GRADE "] == "09-12"]
class_size = class_size[class_size["PROGRAM TYPE"] == "GEN ED"]
class_size = class_size.groupby("DBN").agg(np.mean)
class_size.reset_index(inplace=True)
data["class_size"] = class_size
压缩其他数据集
同样,我们需要压缩 demographics 数据集。这个数据集收集了同一个学校多年的数据,因此存在重复数据。我们将仅仅挑选出 schoolyear 字段里为最近年份的,来去除重复的数据:
demographics = data["demographics"]
demographics = demographics[demographics["schoolyear"] == 20112012]
data["demographics"] = demographics
还需要压缩 math_test_results 数据集。这个数据集按 Grade 和 Year 进行分割。我们可以只保留某一年中某个年级的数据:
data["math_test_results"] = data["math_test_results"][data["math_test_results"]["Year"] == 2011]
data["math_test_results"] = data["math_test_results"][data["math_test_results"]["Grade"] == '8']
最后,压缩 graduation 数据集:
data["graduation"] = data["graduation"][data["graduation"]["Cohort"] == "2006"]
data["graduation"] = data["graduation"][data["graduation"]["Demographic"] == "Total Cohort"]
在真正开始项目工作之前,数据的清理和探索是至关重要。拥有一个良好的、一致的数据集会大大加快后续分析工作。
计算变量值
计算变量值对加快分析过程有两个好处,让日后进行比较更快,能够比较原本不能比较的字段。目前我们要做的第一件事情是从 SAT Math Avg. Score、SAT Critical Reading Avg. Score、and SAT Writing Avg. Score 列来计算 SAT 总分。下面的代码:
- 把每个 SAT 成绩中的列从字符串转为数字。
- 合计所有列到 sat_score 列,代表 SAT 总分。
cols = ['SAT Math Avg. Score', 'SAT Critical Reading Avg. Score', 'SAT Writing Avg. Score']
for c in cols:
data["sat_results"][c] = pandas.to_numeric(data["sat_results"][c], errors='coerce')
data['sat_results']['sat_score'] = data['sat_results'][cols[0]] + data['sat_results'][cols[1]] + data['sat_results'][cols[2]]
接下里,我们来解析每个学校的坐标位置,这个可以让我们绘制每所学校的位置。下面的代码:
- 从 Location 1 列解析出经纬度。
- 转换经纬度为数字。
data["hs_directory"]['lat'] = data["hs_directory"]['Location 1'].apply(lambda x: x.split("\n")[-1].replace("(", "").replace(")", "").split(", ")[0])
data["hs_directory"]['lon'] = data["hs_directory"]['Location 1'].apply(lambda x: x.split("\n")[-1].replace("(", "").replace(")", "").split(", ")[1])
for c in ['lat', 'lon']:
data["hs_directory"][c] = pandas.to_numeric(data["hs_directory"][c], errors='coerce')
现在,我们可以重新打印每一个数据集来看看:
for k,v in data.items():
print(k)
print(v.head())
合并数据集
现在我们完成了所有的准备工作,可以使用 DBN 列来将数据集合并在一起了。合并后我们将获得一个有着数百个列的数据集。合并时注意一些数据集存在缺失部分高中的数据。为了不丢失这部分数据,我们需要使用 outer join 来合并数据集。在现实世界里,数据缺失是很常见的。有能力推理和处理缺失数据是作品集中重要的展示部分。
你可以从这里了解不同类型的 join 。
下面的代码中,我们将:
- 遍历 data 字典里的每一项。
- 打印非唯一 DBN 的数量。
- 决定 join 的策略,inner 还是 outer。
- 以 DBN 来 join 所有的数据集,存于 DataFrame full。
flat_data_names = [k for k,v in data.items()]
flat_data = [data[k] for k in flat_data_names]
full = flat_data[0]
for i, f in enumerate(flat_data[1:]):
name = flat_data_names[i+1]
print(name)
print(len(f["DBN"]) - len(f["DBN"].unique()))
join_type = "inner"
if name in ["sat_results", "ap_2010", "graduation"]:
join_type = "outer"
if name not in ["math_test_results"]:
full = full.merge(f, on="DBN", how=join_type)
full.shape
sat_results
0
demographics
0
graduation
0
hs_directory
0
ap_2010
1
survey
0
class_size
0
(396, 174)
添加值
现在我们有了 DataFrame full, 几乎包含所有我们需要信息的。但是,仍然有部分字段的数据是缺失的。例如我们想将 AP 考试的结果与 SAT 成绩关联到一起的话,我们需要将列转化为数字,然后填入所有缺失的数值:
cols = ['AP Test Takers ', 'Total Exams Taken', 'Number of Exams with scores 3 4 or 5']
for col in cols:
full[col] = pandas.to_numeric(full[col], errors='coerce')
full[cols] = full[cols].fillna(value=0)
接着,我们计算 school_dist 列,得到学校的区号。之后我们将使用这个数据按区去匹配学区,绘制学校的的统计数据。
full["school_dist"] = full["DBN"].apply(lambda x: x[:2])
最后我们用所有列的平均值,来填写 full 中其他的缺失值:
full = full.fillna(full.mean())
计算关联性
计算列之间的关联性,是探索数据集和检查列相关度的好方法。这个方法可以告诉你哪个列与你感兴趣的列有紧密关系。我们可以使用 Pandas DataFrames 提供的 corr 方法来计算得分。得分越接近 0,表示越没有相关性。越接近 1,则正相关性越强,越接近 -1,则负相关性越强:
从上面的数据我们洞察到一些需要进一步研究的东西:
- 总录取人数与 sat_score 有很强的相关性。这有点令我们惊讶,在我们的认知中,越小的学校,应该越注重于学生教育,分数应该更高才对。
- 女性百分比(female_per)与 SAT 成绩成正比,男性比例(male_per) 则相反。
- 调查反馈数据与 SAT 成绩没有什么相关性。
- SAT 成绩中有显著的种族不平等性(white_per, asian_per, black_per, hispanic_per)。
- ell_percent 与 SAT 成绩有强烈的负相关性。
以上每一项都是一个潜在的探索方向,都可以使用数据来叙述一个故事。
设定上下文
在我们深入数据之前,要为自己以及读者设定一个上下文。使用可探索的图表或者地图是一个好的方式。在本例中,我们按学校位置绘制出地图,这可以帮组我们理解即将探索的问题。
下面的代码:
- 设立地图中心为纽约市
- 为每所学校添加一个标记
- 显示地图
import folium
from folium import plugins
schools_map = folium.Map(location=[full['lat'].mean(), full['lon'].mean()], zoom_start=10)
marker_cluster = folium.MarkerCluster().add_to(schools_map)
for name, row in full.iterrows():
folium.Marker([row["lat"], row["lon"]], popup="{0}: {1}".format(row["DBN"], row["school_name"])).add_to(marker_cluster)
schools_map.save('schools.html')
schools_map

这幅地图很有帮助,但很难看出哪个地区的学校最多。因此,我们制作一副热力图:
schools_heatmap = folium.Map(location=[full['lat'].mean(), full['lon'].mean()], zoom_start=10)
schools_heatmap.add_children(plugins.HeatMap([[row["lat"], row["lon"]] for name, row in full.iterrows()]))
schools_heatmap.save("heatmap.html")
schools_heatmap

学区地图绘制
热力图对于绘制梯度差异很方便,但是我们希望使用更加结构化的方式,来绘制城市中不同学校 SAT 成绩的区别。学区是一个很好的可视化选择,因为每个学期的管理各异。纽约市有数十个学期,每个学区就是一个小的地理范围。
我们可以根据学期计算 SAT 成绩,然后将其绘制到地图上。在下面的代码中,我们将:
- 根据学区对 full 进行分组
- 计算每个学区的行均值
- 删除 school_dist 字段中的前导 0 ,方便与地理区域数据进行匹配
district_data = full.groupby("school_dist").agg(np.mean)
district_data.reset_index(inplace=True)
district_data["school_dist"] = district_data["school_dist"].apply(lambda x: str(int(x)))
现在我们可以绘制每个学区的平均 SAT 成绩了。为此,我们读取 GeoJSON 格式的数据,获取每个学区的形状,然后通过 school_dist 列将 SAT 成绩与学区形状关联在一起,最后绘制出想要的图形:
def show_district_map(col):
geo_path = 'schools/districts.geojson'
districts = folium.Map(location=[full['lat'].mean(), full['lon'].mean()], zoom_start=10)
districts.geo_json(
geo_path=geo_path,
data=district_data,
columns=['school_dist', col],
key_on='feature.properties.school_dist',
fill_color='YlGn',
fill_opacity=0.7,
line_opacity=0.2,
)
districts.save("districts.html")
return districts
show_district_map("sat_score")

入学率与 SAT 成绩
绘制完每个学员的位置,并按学区绘制出 SAT 成绩之后,我们就设定了分析的上下文。阅读我们分析报告的人将能更好地理解数据集背后的上下文。接来下,我们进行此前提到的分析。第一个是学校的学生数量与 SAT 成绩之间的关系。
可以使用散点图,来比较学校的入学率和 SAT 成绩。
%matplotlib inline
full.plot.scatter(x='total_enrollment', y='sat_score')

我们发现,左下方有大量的数据点聚集,表示低入学率低 SAT 成绩。除此之外,SAT 成绩和总入学率之间似乎只有一点正相关。将相关性绘制出来可以发现意想不到的规律。
我们可以获取低入学率、低 SAT 成绩的学校名称,进行进一步的探索。
full[(full["total_enrollment"] < 1000) & (full["sat_score"] < 1000)]["School Name"]

谷歌搜索结果显示,这些学校中大多数是针对正在学习英语的学生,因此入学率也低。这一结果告诉我们,并不是说总入学率与 SAT 成绩相关,而是学校中的学生是否以英语为第二外语。
英语学生与 SAT 成绩
既然我们知道了一个学习中英语学生的比例与较低的 SAT 成绩相关,可以进一步作探索。ell_percent 列是每个学校中英语学生的比例。我们绘制一副散点图来分析二者之间的关系。
full.plot.scatter(x='ell_percent', y='sat_score')

看上去有一些学校的英语学生比例很高,同时平均 SAT 成绩却很低。我们可以从学区层面对此进行调查,弄清每个学区中英语学生的比例,然后检查是否与根据学区绘制的 SAT 成绩图相匹配。
show_district_map("ell_percent")

从中可以看出,英语学生比例低的学区,SAT 成绩一般比较高,反之亦然。
调查分数与 SAT 成绩
我们可以合理地假设,学生、家长和老师调查的结果与 SAT 成绩与较大的相关性。成绩预期高的学校一般 SAT 成绩也高。为了验证该假设,我们结合 SAT 成绩和各种调查结果进行绘图:
full.corr()["sat_score"][["rr_s", "rr_t", "rr_p", "N_s", "N_t", "N_p", "saf_tot_11", "com_tot_11", "aca_tot_11", "eng_tot_11"]].plot.bar()

令人意外的是,相关性最高的两个因素是 N_p 和 N_s,即参与调查的家长和学生的数量。二者与总入学率之间均呈强相关性,因此可能会受到 ell_learners 的影响。相关性强的其他指标是 saf_t_11 。这是学生、家长和老师对学校安全性的评价。一所学校越安全,学生更容易安心在其中学习。但是沟通、成绩预期等其他因素与 SAT 成绩之间没有任何相关性。这或许说明纽约市在调查时的问题设计不妥,或者是调查因子就不正确(如果他们的目标是提高 SAT 成绩的话)。
种族和 SAT 成绩
还有一个分析角度,就是种族和 SAT 成绩。二者之间有很大的相关性,可视化后将有助于理解背后的原因:
full.corr()["sat_score"][["white_per", "asian_per", "black_per", "hispanic_per"]].plot.bar()
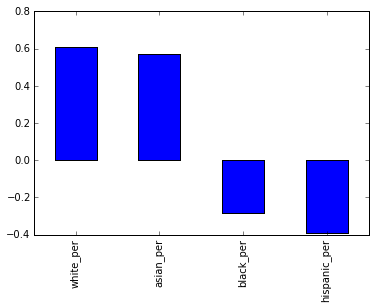
结果显示,白人和亚洲学生的比例越高,SAT 成绩就越高,而黑人和拉美裔学生比例越高,SAT 成绩就越低。对于拉美裔学生来说,原因可能是近来移民的数量较大,其中多为英语学生。我们可以按地区绘制拉美裔的比例,来验证相关性。
show_district_map("hispanic_per")

拉美裔比例似乎和英语学生比例之间有一定相关性,但是要确定的话则需要做深入的分析和研究。
性别差别与 SAT 成绩
最后一个分析角度是性别与SAT 成绩。我们注意到女性比例更高的学校有更高的 SAT 成绩。我们可以用一个柱状图来呈现:
full.corr()["sat_score"][["male_per", "female_per"]].plot.bar()

为了挖掘更多信息,我们以 female_per 和 sat_score 列为轴绘制散点图:
full.plot.scatter(x='female_per', y='sat_score')
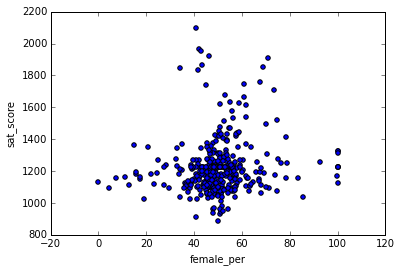
在图中,我们发现了一些拥有高比例女性和高 SAT 分数的学校。可以这样获取这些学校的名字:
full[(full["female_per"] > 65) & (full["sat_score"] > 1400)]["School Name"]

谷歌搜索显示,这些学校属于表演艺术的精英学校。所以可以同时解释这些学校有较高的女性占比以及较高的 SAT 分数。
AP 成绩
目前为止,我们已经考虑了生源方面的分析角度。另一个方向是研究学生参加 AP 考试与SAT 成绩的关系。二者之间应该是相关的,学习成绩好的学生,SAT 成绩也应更高。
full["ap_avg"] = full["AP Test Takers "] / full["total_enrollment"]
full.plot.scatter(x='ap_avg', y='sat_score')
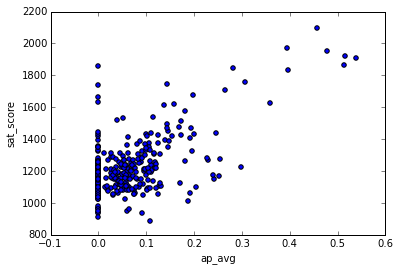
看起来二者之间确实是正相关。右上方的学校很有趣,他们的 SAT 成绩很高,学生参加 AP 考试的比例也很高。
full[(full["ap_avg"] > .3) & (full["sat_score"] > 1700)]["School Name"]

谷歌搜索显示,它们大多数属于需要考试才能入学的名牌学校。所以这些学校有高的 AP 考试比例也是理所当然的。
故事总结
数据科学的世界里,故事绝不会完全结束。把你的分析分享给其他人,别人可以就任何感兴趣的方向进一步扩充和塑造你的分析。比如本文中就有很多你可以继续进行挖掘的方向。
入门用数据来讲故事最好的方式,就是尝试扩充或者复制其他人的分析。如果你决定这么做,非常欢迎你扩展本文的分析,来看看你还会有什么发现。如果你这么做了,请在下面留言。
下一步
如果你已经学到这里了,代表你已经理解如何用数据讲故事和怎样打造你的数据科学作品集。一旦你完成了你的数据科学项目,请将它传到 Github,这样别人就可以与你协作了。
首发地址:打造数据科学作品集:用数据讲故事
