

在Solr 5.X以后,无论你是在Windos下还是在Linux下搭建Solr、Solr Cloud的都是极其简单的,因为Solr提供了很多快速搭建脚本并且都包括sh、bat两种版本。
环境
- OS:Linux
- JDK:1.7
- Solr:5.5.3
本文以Solr 5 的最后一个发行版5.5.3作为Solr的版本,因为6.X官方建议的JDK版本是Java 8,下载地址:apache.fayea.com/lucene/solr…
快速搭建
//1.下载
$ wget http://apache.fayea.com/lucene/solr/5.5.3/solr-5.5.3.tgz
//2.将它移动到你想要的目录下,操作省略。
//3.解压
$ tar -zxvf solr-5.5.3.tgz
//4.进入solr-5.5.3目录下执行下面命令$ ./bin/solr start
Waiting up to 30 seconds to see Solr running on port 8983 [/] Started Solr server on port 8983 (pid=24120). Happy searching!
//只需这4步,一个单节点的Solr Server就搭建完成了,端口默认为8983,快去访问它吧!./bin/solr 这个脚本非常重要,是官方提供操作Solr的入口脚本,通常我们启动单点的Solr Server只会涉及三个命令,start、stop、status,使用start命令启动时可以通过-s 指定solr home目录,-p 指定端口;使用stop命令关闭时可以使用-p指定要关闭的服务的端口,使用-all关闭所有服务;使用status来查看服务的状态。
下面链接是官方文档对该脚本的说明,最好花几分钟快速浏览一遍。
cwiki.apache.org/confluence/…
提示:使用./bin/solr 启动的Solr使用内嵌的Servlet容器 Jetty,这也是官方建议的,同时这也和Spring Boot的理念相契合,应用本来就是易于使用的,内嵌容器也将是未来Java Web 应用的趋势。笔者在学习Solr的过程中也翻阅过一些博文,大部分还是使用Tomcat来搭建Solr,笔者对此感到困惑,不过你依然可以使用Tomcat,不过搭建就没有这么简便了~

HTML UI
顺利启动后~访问http://your_server_ip:8983/solr 便可进入Solr 的管理界面,点我查看官方用户界面介绍
更进一步
搭建完成后,我们需要通过Core Admin 来创建一个Core,就是上篇文章所说的那个Core,你可以把它理解为在数据库服务器上创建了一个新的数据库,虽然并不是那么恰当。
Add Core
通常在点击Add Core的时候会报错,因为Solr 在solr-home目录并找不到相应的配置文件,因为我们启动的时候并没有指定solr-home目录,也并没有添加相应的配置文件。
现在我们需要停掉该服务,增加solr-home目录,并添加配置文件后,重新启动它。
//1.先停止先前启动的服务(如果你不使用-p或-all的话默认关闭的就是端口为8983的服务)
$ ./bin/solr stop //2.创建solr-home目录(目录,名字随意~)
$ cd ~$ mkdir solr-home
//3.复制solr.xml配置文件
$ cp solr-5.5.3/server/solr/solr.xml ./solr-home/
//4.复制一份core配置文件
$ cp -rf solr-5.5.3/server/solr/configsets/data_driven_schema_configs/ ./solr-home/
//5.修改core配置文件夹名称(这里使用test-core,稍后创建的core要与之匹配)
$ mv ./solr-home/data_driven_schema_configs/ ./solr-home/test-core
//6.指定solr-home,并启动Solr Server
$ cd ./solr-5.5.3
$ .bin/solr start -s ~/solr-home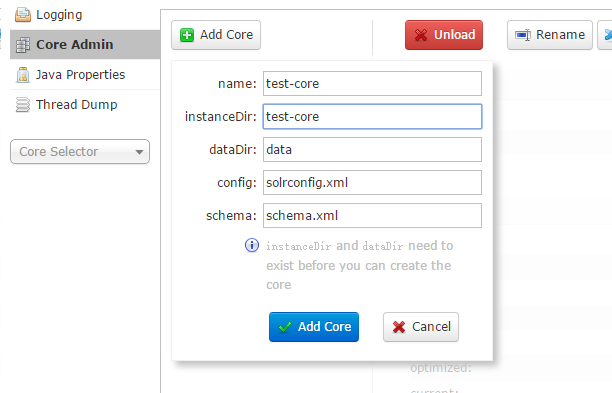
Add Core
这时,输入name、instanceDir后就可以创建一个Core了,成功后通过下面的Core Selector便可进入该Core,就像进入数据库服务器,选择DB一样~

Execute Query
点击查询便可进行查询操作,不过现在应该没有索引文档,所以结果为空~
现在我们可以添加一些索引,在添加索引之前,我们要创建一些字段,就像数据库创建一张表需要添加Column一样,添加之前我们看看Solr 已经为我们创建了什么字段,看下图。

Document Field
这些字段统一由managed-schema文件来管理、配置(Solr 5 以前叫schema.xml),它位于solr-home/test-core/conf目录下,通过编辑它便可进行配置,官方字段类型介绍,非官方比较好的讲解。
我们可以尝试添加一个文档到索引,就以下面JSON(当然也可以是其他格式)为例。
{'id':'1','author':'李恒名','title':'使用Solr为应用提供搜索服务(2)搭建&配置'}
Add Document
再次查询,便可查询到该文档~

Paste_Image.png
此时有必要简略的说一下查询语法了
使用分词器
如果没有使用分词器的话,我们要查询标题内包含“服务”这个关键词的文档的话,通常需要这样写title:服务*,类似于SQL TITLE LIKE '%服务%',这样显而易见会降低性能。如果可以把“使用Solr为应用提供搜索服务(2)搭建&配置”,拆分为“使用”、“Solr”、“应用”、“提供”等等这样的词汇再进行索引的话,那么我们使用title:服务*便可快速索引到该文档,要达到该目的,我们需要为Solr添加分词器,这里我们使用IKAnalyzer作为我们中文分词器的选择,下面是步骤。
- 下载JAR包,下载地址(IKAnalyzer2012FF_u2只有该版本在Solr 5.5.3下可以正常工作)。
- 想办法将JAR包放入/home/solr/solr-5.5.3/server/solr-webapp/webapp/WEB-INF/lib下(相信你可以做到)。
- 编辑managed-schema, 在标签内添加分词fieldType,并使用它,参考下面代码片段
//配置分词器fieldType //将type改为分词器类型 - 重启SOLR

使用中文分词器
至此,单节点Solr 的搭建和配置就到此为止了,由于Solr 提供的是HTTP REST接口,所以我们可以很容易的通过GET请求 访问API 获得JSON/XML响应来使用Solr提供的索引服务。
下篇文章:Solr Cloud
我只是官方文档的搬运工,如果你要使用Solr 强烈建议阅读官方文档,写的非常完善,传送门。
