

WordCountTopology
“源码走读系列”从代码层面分析了storm的具体实现,接下来通过具体的实例来说明storm的使用。因为目前storm已经正式迁移到Apache,文章系列也由twitter storm转为apache storm.
WordCountTopology 使用storm来统计文件中的每个单词的出现次数。
通过该例子来说明tuple发送时的几个要素
- source component 发送源
- destination component 接收者
- stream 消息通道
- tuple 消息本身
本文涉及到的开发环境搭建可以参考前面的两篇博文。
awk实现
其实对文件中的单词进行统计是Linux下一个很常见的任务,用awk就可以轻松的解决(如果文件不是太大的话),下面是进行word counting的awk脚本,将其保存为名为wordcount.awk文件。
wordcount.awk
{
for (i = 1; i<=NF; i++)
freq[$i]++
}
END{
for (word in freq)
printf "%s\t%d\n",word,freq[word]
}运行该脚本,对文件中的单词进行统计
gawk -f wordcount.awk filename原始版本
从github上复制内容
git clone https://github.com/nathanmarz/storm-starter.git编译运行
lein deps
lein compile
java -cp $(lein classpath) WordCountTopologymain函数
main函数的主要内容
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new RandomSentenceSpout(), 5);
builder.setBolt("split", new SplitSentence(), 8).shuffleGrouping("spout");
builder.setBolt("count", new WordCount(), 12).fieldsGrouping("split", new Fields("word"));注意:grouping操作的时候,如果没有显示指定stream id,则使用的是default stream. 如shuffleGrouping("spout")表示从名为spout的component中接收从default stream发送过来的tuple.
改进版本
在原始版本中,spout不停的向split bolt随机发送句子,Count bolt统计每个单词出现的次数。
那么能不能让Spout在读取完文件之后,通知下游的bolt显示最柊的统计结果呢?
要想达到上述的改进目标,采用如上图所示的结构即可。改变的地方如下,
- 在Spout中添加一个SUCCESS_STREAM
- 添加只有一个运行实例的statistics bolt
- 当spout读取完文件内容之后,通过SUCCESS_STREAM告诉statistics bolt,文件已经处理完毕,可以打印当前的统计结果
RandomSentenceSpout.java
declareOutputFields
添加SUCCESS_STREAM
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
declarer.declareStream("SUCCESS_STREAM",new Fields("word"));
}nextTuple
使用SUCCESS_STREAM通知下游,文件处理完毕
@Override
public void nextTuple() {
Utils.sleep(100);
String[] sentences = new String[]{ "the cow jumped over the moon", "an apple a day keeps the doctor away",
"four score and seven years ago", "snow white and the seven dwarfs", "i am at two with nature" };
if ( count == sentences.length )
{
System.out.println(count+" try to emit tuple by success_stream");
_collector.emit("SUCCESS_STREAM",new Values(sentences[0]));
count++;
}else if ( count < sentences.length ){
_collector.emit(new Values(sentences[count]));
count++;
}
}WordCountTopology.java
添加静态类WordCount2
public static class WordCount2 extends BaseBasicBolt {
Map<String, Integer> counts = new HashMap<String, Integer>();
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
if ( tuple.getSourceStreamId() == "SUCCESS_STREAM" ) {
System.out.println("prepare to print the statistics");
for (String key : counts.keySet()) {
System.out.println(key+"\t"+counts.get(key));
}
System.out.println("finish printing");
}else {
String word = tuple.getString(0);
Integer count = counts.get(word);
if (count == null)
count = 0;
count++;
counts.put(word, count);
}
}
main函数
将spout的并行数由5改为1
builder.setSpout("spout", new RandomSentenceSpout(), 1);在原有的Topology中添加WordCount2 Bolt
builder.setBolt("count2", new WordCount2(), 1).globalGrouping("count").globalGrouping("spout","SUCCESS_STREAM");WordCount2 Bolt会接收从Count Bolt通过default stream发送的tuple,同时接收Spout通过SUCCESS_STREAM发送的tuple,也就是说wordcount2会接收从两个stream来的数据。
编译
编译修改后的源文件
cd $STROM_STARTER
lein compile storm.starter 可能会出现以下异常信息,该异常可以忽略。
Exception in thread "main" java.io.FileNotFoundException: Could not locate storm/starter/WordCountTopology__init.class or storm/starter/WordCountTopology.clj on classpath:运行
在local模式下运行修改后的WordCountTopology
java -cp $(lein classpath) storm.starter.WordCountTopology如果一切正常,日志如下所示,线程的名字可能会有所不同。
moon 1
score 1
cow 1
doctor 1
over 1
nature 1
snow 1
four 1
keeps 1
with 1
a 1
white 1
dwarfs 1
at 1
the 4
and 2
i 1
two 1
away 1
seven 2
apple 1
am 1
an 1
jumped 1
day 1
years 1
ago 1
结果验证
可以将WordCountTopology的运行结果和awk脚本的运行结果相比对,结果应该是一致的。
小技巧
- awk脚本的执行结果存为一个文件result1.log, WordCountTopology的输出中单词统计部分存为result2.log
- 用vim打开result1.log,进行sorting,保存结果;用vim打开result2.log,进行sorting,保存。
- 然后用vimdiff来进行比较 vimdiff result1.log result2.log
BasicDRPCTopology
本文通过BasicDRPCTopology的实例来分析DRPCTopology在提交的时候, Topology中究竟含有哪些内容?
BasicDRPCTopology
main函数
DRPC 分布式远程调用(这个说法有意思,远程调用本来就是分布的,何须再加个D, <头文字D>看多了, :)
public static void main(String[] args) throws Exception {
LinearDRPCTopologyBuilder builder = new LinearDRPCTopologyBuilder("exclamation");
builder.addBolt(new ExclaimBolt(), 3);
Config conf = new Config();
if (args == null || args.length == 0) {
LocalDRPC drpc = new LocalDRPC();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("drpc-demo", conf, builder.createLocalTopology(drpc));
for (String word : new String[]{ "hello", "goodbye" }) {
System.out.println("Result for \"" + word + "\": " + drpc.execute("exclamation", word));
}
cluster.shutdown();
drpc.shutdown();
}
else {
conf.setNumWorkers(3);
StormSubmitter.submitTopology(args[0], conf, builder.createRemoteTopology());
}
}
问题: 上面的代码中只是添加了一个bolt,并没有设定Spout. 我们知道一个topology中最起码得有一个Spout,那么这里的Spout又隐身于何处呢?
关键的地方就在builder.createLocalTopology, 调用关系如下
- LinearDRPCTopologyBuilder::createLocalTopology
- LinearDRPCTopologyBuilder:: createTopology()
- LinearDRPCTopologyBuilder:: createTopology(new DRPCSpout(_function))
- LinearDRPCTopologyBuilder:: createTopology()
原来DRPCTopology中使用的Spout是DRPCSpout.
LinearDRPCTopology::createTopology
既然代码已经读到此处,何不再进一步看看createTopology的实现.
简要说明一下该段代码的处理逻辑:
- 设置DRPCSpout
- 以bolt为入参,创建CoordinatedBolt
- 添加JoinResult Bolt
- 添加ReturnResult Bolt: ReturnResultBolt连接到DRPCServer,并返回结果
private StormTopology createTopology(DRPCSpout spout) {
final String SPOUT_ID = "spout";
final String PREPARE_ID = "prepare-request";
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(SPOUT_ID, spout);
builder.setBolt(PREPARE_ID, new PrepareRequest())
.noneGrouping(SPOUT_ID);
int i=0;
for(; i<_components.size();i++) {
Component component = _components.get(i);
Map<String, SourceArgs> source = new HashMap<String, SourceArgs>();
if (i==1) {
source.put(boltId(i-1), SourceArgs.single());
} else if (i>=2) {
source.put(boltId(i-1), SourceArgs.all());
}
IdStreamSpec idSpec = null;
if(i==_components.size()-1 && component.bolt instanceof FinishedCallback) {
idSpec = IdStreamSpec.makeDetectSpec(PREPARE_ID, PrepareRequest.ID_STREAM);
}
BoltDeclarer declarer = builder.setBolt(
boltId(i),
new CoordinatedBolt(component.bolt, source, idSpec),
component.parallelism);
for(Map conf: component.componentConfs) {
declarer.addConfigurations(conf);
}
if(idSpec!=null) {
declarer.fieldsGrouping(idSpec.getGlobalStreamId().get_componentId(), PrepareRequest.ID_STREAM, new Fields("request"));
}
if(i==0 && component.declarations.isEmpty()) {
declarer.noneGrouping(PREPARE_ID, PrepareRequest.ARGS_STREAM);
} else {
String prevId;
if(i==0) {
prevId = PREPARE_ID;
} else {
prevId = boltId(i-1);
}
for(InputDeclaration declaration: component.declarations) {
declaration.declare(prevId, declarer);
}
}
if(i>0) {
declarer.directGrouping(boltId(i-1), Constants.COORDINATED_STREAM_ID);
}
}
IRichBolt lastBolt = _components.get(_components.size()-1).bolt;
OutputFieldsGetter getter = new OutputFieldsGetter();
lastBolt.declareOutputFields(getter);
Map<String, StreamInfo> streams = getter.getFieldsDeclaration();
if(streams.size()!=1) {
throw new RuntimeException("Must declare exactly one stream from last bolt in LinearDRPCTopology");
}
String outputStream = streams.keySet().iterator().next();
List<String> fields = streams.get(outputStream).get_output_fields();
if(fields.size()!=2) {
throw new RuntimeException("Output stream of last component in LinearDRPCTopology must contain exactly two fields. The first should be the request id, and the second should be the result.");
}
builder.setBolt(boltId(i), new JoinResult(PREPARE_ID))
.fieldsGrouping(boltId(i-1), outputStream, new Fields(fields.get(0)))
.fieldsGrouping(PREPARE_ID, PrepareRequest.RETURN_STREAM, new Fields("request"));
i++;
builder.setBolt(boltId(i), new ReturnResults())
.noneGrouping(boltId(i-1));
return builder.createTopology();
}
Bolt
处理逻辑: 在接收到的每一个单词后面添加'!'.
public static class ExclaimBolt extends BaseBasicBolt {
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
String input = tuple.getString(1);
collector.emit(new Values(tuple.getValue(0), input + "!"));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "result"));
}
}运行
java -cp $(lein classpath) storm.starter.BasicDRPCTopologyTridentWordCount
介绍TridentTopology的使用,重点分析newDRPCStream和stateQuery的实现机理。
使用TridentTopology进行数据处理的时候,经常会使用State来保存一些状态,这些保存起来的State通过stateQuery来进行查询。问题恰恰在这里产生,即对state进行更新的Stream和尔后进行stateQuery的Stream并非同一个,那么它们之间是如何关联起来的呢。
在TridentTopology中,有一些Processor可能会同处于一个Bolt中,这些Processor形成一个processing chain, 那么Tuple又是如何在这些Processor之间进行传递的呢。
TridentWordCount
编译和运行
lein compile storm.starter.trident.TridentWordCount
java -cp $(lein classpath) storm.starter.trident.TridentWordCount main函数
public static void main(String[] args) throws Exception {
Config conf = new Config();
conf.setMaxSpoutPending(20);
if (args.length == 0) {
LocalDRPC drpc = new LocalDRPC();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("wordCounter", conf, buildTopology(drpc));
for (int i = 0; i < 100; i++) {
System.out.println("DRPC RESULT: " + drpc.execute("words", "cat the dog jumped"));
Thread.sleep(1000);
}
}
else {
conf.setNumWorkers(3);
StormSubmitter.submitTopology(args[0], conf, buildTopology(null));
}
} buildTopology
public static StormTopology buildTopology(LocalDRPC drpc) {
FixedBatchSpout spout = new FixedBatchSpout(new Fields("sentence"), 3, new Values("the cow jumped over the moon"),
new Values("the man went to the store and bought some candy"), new Values("four score and seven years ago"),
new Values("how many apples can you eat"), new Values("to be or not to be the person"));
spout.setCycle(true);
TridentTopology topology = new TridentTopology();
TridentState wordCounts = topology.newStream("spout1", spout).parallelismHint(16).each(new Fields("sentence"),
new Split(), new Fields("word")).groupBy(new Fields("word")).persistentAggregate(new MemoryMapState.Factory(),
new Count(), new Fields("count")).parallelismHint(16);
topology.newDRPCStream("words", drpc).each(new Fields("args"), new Split(), new Fields("word")).groupBy(new Fields(
"word")).stateQuery(wordCounts, new Fields("word"), new MapGet(), new Fields("count")).each(new Fields("count"),
new FilterNull()).aggregate(new Fields("count"), new Sum(), new Fields("sum"));
return topology.build();
} 示意图
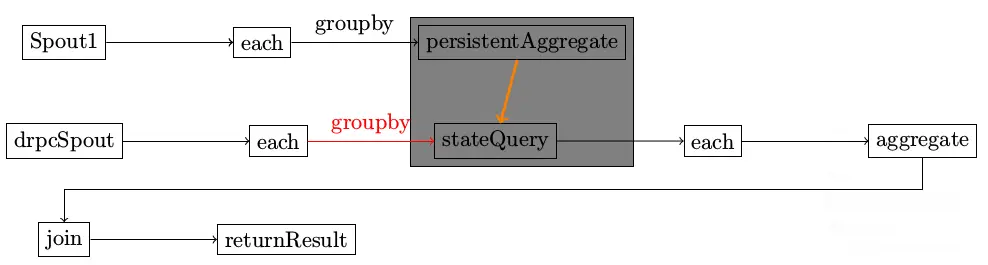
在整个topology中,有两个不同的spout。
运行结果该如何理解
此图有好几个问题
- PartitionPersistProcessor和StateQueryProcessor同处于一个bolt,该bolt为SubtopologyBolt
- SubtopologyBolt有来自多个不同Stream的输入,根据不同的Streamid找到对应的InitialReceiver
- drpcspout在执行的时候,是一直不停的emit消息到SubtopologyBolt,还是发送完一次消息就停止发送
不同的tuple,其sourcestream不一样,根据SourceStream,找到对应的InitialReceiver
Map<String, InitialReceiver> _roots = new HashMap();
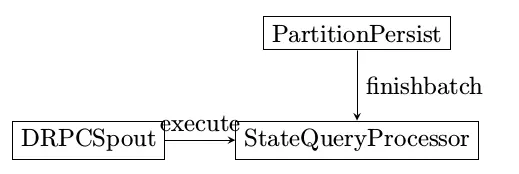
状态更新
进行状态更新的Processor名为PartitionPersistProcessor
execute
记录哪些tuple需要进行状态更新
finishBatch
状态真正更新是发生在finishBatch阶段
persistentAggregate
PartitionPersistProcessor
- SubtopologyBolt::execute
- PartitionPersistProcessor::finishBatch
- _updater::updateState
- Snapshottable::update
- _updater::updateState
- PartitionPersistProcessor::finishBatch
当状态更新的时候,状态查询是否会发生?
状态查询
进行状态查询的Processor名为StateQueryProcessor
execute
finishBatch
查询的时候,首先调用batchRetrieive来获得最新的状态更新结果,再对每个最新的结果使用_function来进行处理。
调用层次
- SubtopologyBolt::finishBatch
- StateQueryProcessor::finishBatch
- _function.batchRetrieve
- _function.execute 将处理过的结果发送给下一跳进行处理
- StateQueryProcessor::finishBatch
消息的传递
TridentTuple
如何决定bolt内部的哪个processor来处理接收到的消息,这个是根据不同的Stream来判断InitialReceiver完成。
当SubtopologyBolt接收到最原始的tuple时,根据streamid找到InitialReceiver后,InitialReceiver在receive函数中作的第一件事情就是根据tuple来创建一个tridenttuple,tridenttuple会被处在同一个SubtopologyBolt中的processor一一处理,处理的结果是保存在tridenttuple和processorcontext中。
ProcessorContext
ProcessorContext记录两个重要的信息,即当前的batchId和batchState.
public class ProcessorContext {
public Object batchId;
public Object[] state;
public ProcessorContext(Object batchId, Object[] state) {
this.batchId = batchId;
this.state = state;
}
}TridentCollector
tridentcollector在emit的时候将消息由各个TupleReceiver进行处理。目前仅有BridgeReceiver实现了该接口。
BridgeReceiver负责将消息发送给另外的Bolt进行处理。这里说的“另外的Bolt”是指Vanilla Topology中的Bolt.
