

我们的世界不应该只有“胡萝卜”

进入正题之前容我先扯点别的。
最近突然想到了一个驴子和胡萝卜不得不说的故事。说是一个人坐在驴子背上,用一根长杆绑着一根胡萝卜,然后把胡萝卜悬到驴子的面前,驴子以为只要向前走一步就可以吃到胡萝卜,于是不停地向前走,可是它始终无法吃到这根萝卜。
一千个读者就有一千个哈姆雷特,当然不同的人对这个故事也会有不同的理解。比如我们为了生活拼命地工作,却永远达不到财务自由,我们是不是也像一只忙碌的“驴子”呢?
所以,我们的世界不应该只有“胡萝卜”。
不识庐山真面目,只缘身在此山中。有时候跳出来,用“上帝视角”来看看这个我们存在的世界,说不定会有不一样的发现。生活如此,学习也是如此。
数据结构和算法与Java集合框架
接下来我们再来看一个故事。本故事纯属虚构,如有雷同,纯属你抄我。
时间:2017/01/11
地点:A公司办公室
人物:小明——一个工作一年的Android小菜鸟;B大大——A公司Android开发负责人,Android高级开发工程师
起因:小明想到A公司工作,由B大大对他进行面试。
经过:B大大说,小明啊,你刚毕业一年,算法应该还不错,咱们先来一个简单的吧。有一个迷宫,由n行m列的单元格组成,每一个单元格要么是空地要么是障碍物,障碍物是不能穿过的。任取两个不是障碍物并且不相同的点p和q,怎么找到p到q的最短路径呢?
小明支支吾吾,边挠头边说,那个B大大,我上学的时候贪玩没有好好学数据结构和算法,毕业后工作中也基本没有用到过,所有不怎么会了。。。
B大大露出一副安慰的表情,说,恩,可以理解。那咱们问点工作中常用的吧。
小明顿时来了精神,一顿小鸡啄米似的点头。
B大大说,那你先说说你工作中接触到的数据结构吧。
小明张口就来,数组、ArrayList、Map。
B大大又等了一会,看小明实在没有了下文,又继续问道,那你了解Java集合框架的设计思路吗?
小明说,设计思路?为什么要了解,没时间啊,老夫写代码就是一把梭!复制、粘贴,拿起键盘就是干!效率刚刚的。
B大大心里一万只羊驼飞奔而过,嘴角抖了抖,说,那个小明,咱们今天的面试就先到这吧,有结果了我再让Hr通知你好吧。
然后,然后就没有然后了。
虽然这个故事是虚构的,但是不难找出来现实版的小明求职记。那么从这个故事我们可以反思一些什么呢?
首先个人认为数据结构和算法、设计模式这些属于内功,俗话说练拳不练功,到老一场空,有了这些内功我们才能更好的去使用各种招式,否则只是徒有其形罢了。要知道一个花架子是没有多少战斗力的。
其次,了解了源码里的设计思路,用起来才能更得心应手,同时也能提高自己的设计能力。而且就像开篇说的,我们要善于从宏观的角度去看一些事情,这样才能看到更多,收获更多。当然成长为高级工程师,迎娶白富美,走向人生巅峰不是梦啦。
数据结构和算法
这里我不打算再过多的重复数据结构和算法的定义、算法的时空复杂度这些问题,只过一下各个数据结构的特性。因为算法对数据结构的通用操作类似,基本都包括插入、查找、删除、遍历和排序等,所以我们重点关注下这些操作上的性能。
- 数组:优点是插入块,如果知道下标,可以非常快的存取。缺点是查找慢,删除慢,大小固定。
- 有序数组:优点是比无序数组查找快。缺点是插入和删除慢,大小固定。
- 栈:提供后进先出方式的存取。缺点是存取其他项很慢。
- 队列:提供先进先出方式的存取。缺点是存取其他项很慢。
- 链表:优点是插入快,删除快。缺点是查找慢。
- 二叉树:优点是查找、插入、删除都快(如果树保持平衡)。缺点是删除算法复杂。
- 红-黑树:优点是查找、插入、删除都快,树总是平衡的。缺点是算法复杂。
- 2-3-4树:优点是查找、插入、删除都快,树总是平衡的,类似的树对磁盘存储有用。缺点是算法复杂。
- 哈希表:优点是如果关键字已知,则存取极快,插入快。缺点是删除慢,如果不知道关键字则存取很慢,对存储空间使用不充分。
- 堆:优点是插入、删除快,对最大数据项的存取很快。缺点是对其他数据项存取慢。
- 图:对现实世界建模。有些算法慢且复杂。
Java中集合框架的总体设计
良好的设计总是相似的。它使用一个好用的接口来封装一个特定的功能,它有效的使用CPU与内存,等等。
我们常用的数据结构有线性表、栈、队列等线性结构,还有集合以及哈希表,所以我们只讨论这几种结构的设计。
在分析Java集合框架的设计思路之前,我们先来认真思考一个问题,如果让你去设计Java的集合框架,你会怎么做?
小明的做法
如果是小明来设计的话,我猜他会选择一种简单粗暴的方式,分别去写几个类来实现线性表、栈、队列、集合以及哈希表。好,那么问题来了。
- 假如用户想自定义一个用自己方式实现的线性表,那么他该如何操作?
- 假如开始用户使用了无序的线性表,然后因为某个需求要改成有序的,那么用户需不需要进行很大改动呢?
- 假如小明要对已有的Api进行升级,要加入无序线性表的另一种更高性能的实现,他需要改动多少东西?
其实把三个问题总结一下无非就是维护和扩展成本的问题。
我们的思路
首先我们先来参考一下其他功能的设计思路,比如Android中的View类族和Context类族。我们分析一下他们的代码的结构层次。
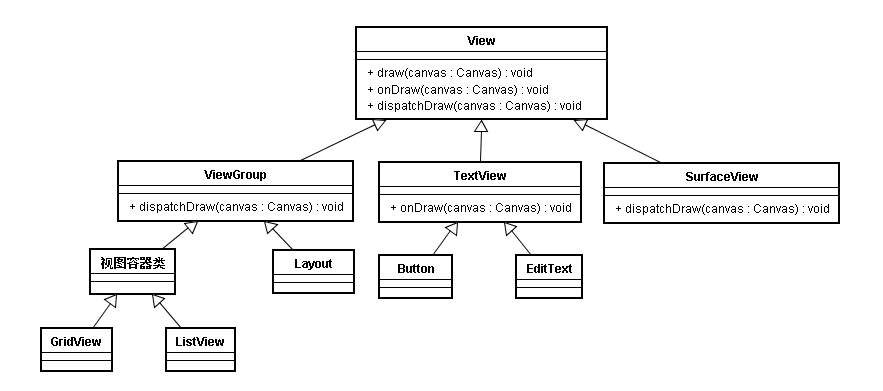
View类族的类图如下
Context类族的类图如下
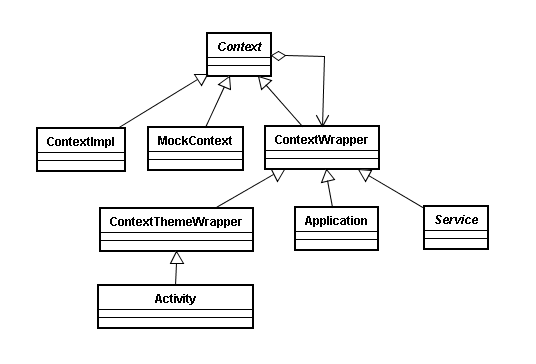
我们来分下一下这两个模块设计上相似的地方
- 整体的代码结构都像一棵树,有一个唯一的根节点,这个根节点封装了这个类族的公有特性
- 有一层抽象类或者类似抽象类作用的类,它们实现了通用的方法。方便用户扩展自己的业务。
- 有具体的实现,用户可以直接使用这些具体实现。
这些相似的地方其实可以归纳为三个结构层次
- 一个高度抽象的根节点接口,可以再抽象出一组带有具体操作的接口来实现我们的根节点
- 一组抽象类,实现带有具体操作接口的部分方法,方便用户快速扩展自己的业务。
- 具体的实现,方便用户直接调用。
这个套路在Android源码中是很常见的,这样做的好处也显而易见,比较易于维护和扩展。
源码的实现思路
然后我们来看看是不是像我们说的那样,Java的集合框架也是这种套路呢?
我们来看下集合框架的类图
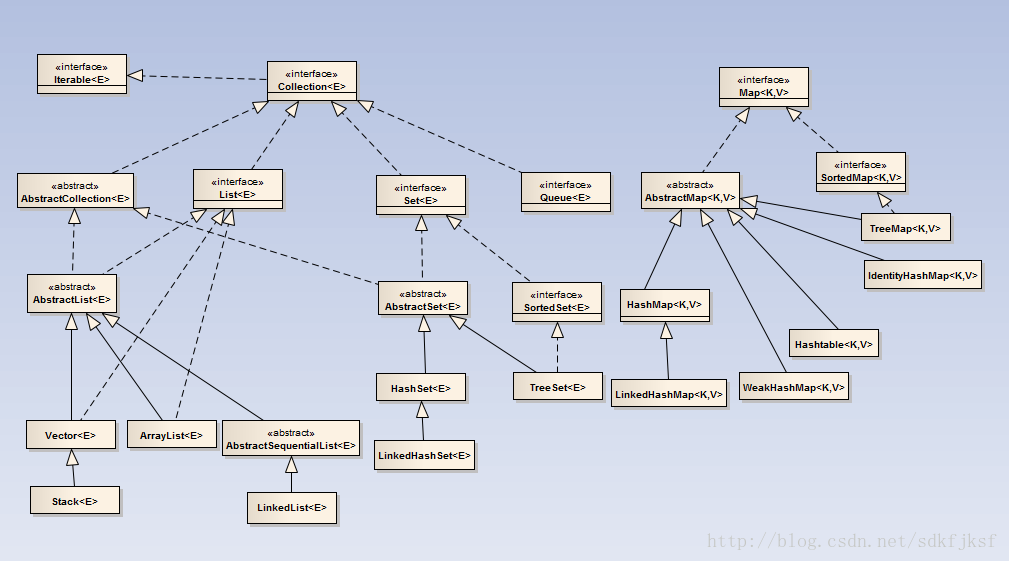
这张图是我从网上找的,不过不影响我们的分析。如果有侵权,请告诉我,我会删除。
从这张图我们可以很清晰的看出来,套路一模一样有没有。
首先由于Map和Collection的相似点很少,所以这两部分的根节点是分开的。
我们拿Collection这部分来说,首先定义了一组接口。Collection是List、Set等集合高度抽象出来的接口,它包含了这些集合的基本操作,它主要又分为:List、Set和Queue,分别对应线性表、集合、队列,实现对应的接口,则有了对应数据结构的特性。这是第一个结构层次。
然后又定义了一组抽象类,我们拿AbstractCollection类来说,先看下注释
/**
* This class provides a skeletal implementation of the <tt>Collection</tt>
* interface, to minimize the effort required to implement this interface. <p>
*/
这个类实现了Collection接口的骨架,用户继承这个类可以用最小化的时间来实现一个集合。
其他的抽象类也都是各个数据结构的骨架,用户可以自定义自己的集合。
最后第三个层次就是具体的实现类了,比如我们常用的ArrayList、LinkedList等等。比如LinkedList实现了List和Queue接口,那么它既有队列先进先出的特性,又有List可以通过位置访问元素的特性。
源码的具体实现
Collection部分
Collection是List、Set等集合高度抽象出来的接口,它包含了这些集合的基本操作,它主要又分为两大部分:List和Set。
Collection接口
/**
* The root interface in the <i>collection hierarchy</i>. A collection
* represents a group of objects, known as its <i>elements</i>. Some
* collections allow duplicate elements and others do not. Some are ordered
* and others unordered. The JDK does not provide any <i>direct</i>
* implementations of this interface: it provides implementations of more
* specific subinterfaces like <tt>Set</tt> and <tt>List</tt>. This interface
* is typically used to pass collections around and manipulate them where
* maximum generality is desired.
*/
集合层次结构的根。一个集合包含一组元素对象。有一些集合允许重复元素,有一些不允许;有一些集合元素是有序的有一些不是。
定义的方法:
- int size()
- boolean isEmpty()
- boolean contains(Object o)
- Iterator iterator()
- Object[] toArray()
- T[] toArray(T[] a)
- boolean add(E e)
- boolean remove(Object o)
- boolean containsAll(Collection c)
- boolean addAll(Collection c)
- boolean removeAll(Collection c)
- boolean retainAll(Collection c)
- void clear()
Iterator接口
迭代器接口,用于遍历集合。
- boolean hasNext()
- E next()
- default void remove()
- default void forEachRemaining(Consumer action)
AbstractCollection抽象类
/**
* This class provides a skeletal implementation of the <tt>Collection</tt>
* interface, to minimize the effort required to implement this interface. <p>
*
* To implement an unmodifiable collection, the programmer needs only to
* extend this class and provide implementations for the <tt>iterator</tt> and
* <tt>size</tt> methods. (The iterator returned by the <tt>iterator</tt>
* method must implement <tt>hasNext</tt> and <tt>next</tt>.)<p>
*
* To implement a modifiable collection, the programmer must additionally
* override this class's <tt>add</tt> method (which otherwise throws an
* <tt>UnsupportedOperationException</tt>), and the iterator returned by the
* <tt>iterator</tt> method must additionally implement its <tt>remove</tt>
* method.<p>
*
* The programmer should generally provide a void (no argument) and
* <tt>Collection</tt> constructor, as per the recommendation in the
* <tt>Collection</tt> interface specification.<p>
*
* The documentation for each non-abstract method in this class describes its
* implementation in detail. Each of these methods may be overridden if
* the collection being implemented admits a more efficient implementation.<p>
*/
这个类实现了Collection接口的骨架,用户继承这个类可以用最小化的时间来实现一个集合。
如果我们需要实现一个简单的集合,只需要重写iterator()、int size()和add(E o)方法。同时这个集合的特性取决于我们的实现方式。
List接口
线性表(List):零个或多个数据元素的有限序列。
/**
* An ordered collection (also known as a <i>sequence</i>). The user of this
* interface has precise control over where in the list each element is
* inserted. The user can access elements by their integer index (position in
* the list), and search for elements in the list.<p>
*/
一个有序的集合,用户可以通过这个接口精确的控制在哪里插入元素。用户可以通过元素的int下标来拿到元素和查找List中的元素。可以有重复元素。
List接口的扩展方法:
- add(int index, E element)
- addAll(int index, Collection c)
- E get(int index)
- int indexOf(Object o)
- int lastIndexOf(Object o)
- ListIterator listIterator()
- ListIterator listIterator(int index)
- E remove(int index)
- default void replaceAll(UnaryOperator operator)
- E set(int index, E element)
- default void sort(Comparator c)
ListIterator接口
/**
* An iterator for lists that allows the programmer
* to traverse the list in either direction, modify
* the list during iteration, and obtain the iterator's
* current position in the list. A {@code ListIterator}
* has no current element; its <I>cursor position</I> always
* lies between the element that would be returned by a call
* to {@code previous()} and the element that would be
* returned by a call to {@code next()}.
*/
一个为List设计的迭代器,允许用户从任意方向遍历List,在遍历的过程中修改List,并且获得迭代器的当前位置。
ListIterator的扩展方法:
- boolean hasPrevious()
- E previous()
- int nextIndex()
- int previousIndex()
- void set(E e)
- void add(E e)
Set接口
集合(Set):是标记着具有某些相关联或相互依赖的一系列离散数据。
/**
* A collection that contains no duplicate elements. More formally, sets
* contain no pair of elements <code>e1</code> and <code>e2</code> such that
* <code>e1.equals(e2)</code>, and at most one null element. As implied by
* its name, this interface models the mathematical <i>set</i> abstraction.
*/
一个不包含重复元素的集合。所谓不重复是指不能有两个元素e1.equals(e2),并且至多包含一个null元素。
Set接口只包含继承自Collection的方法,并增加了重复的元素被禁止约束性。
集还增加了对equals和hashCode操作的行为更强的契约,允许Set集合实例进行有意义的比较,即使他们的实现类型不同。
Queue
队列(Queue):是只允许在一端进行插入操作,而在另一端进行删除操作的线性表。
/**
* A collection designed for holding elements prior to processing.
* Besides basic {@link java.util.Collection Collection} operations,
* queues provide additional insertion, extraction, and inspection
* operations. Each of these methods exists in two forms: one throws
* an exception if the operation fails, the other returns a special
* value (either {@code null} or {@code false}, depending on the
* operation). The latter form of the insert operation is designed
* specifically for use with capacity-restricted {@code Queue}
* implementations; in most implementations, insert operations cannot
* fail.
*/
队列的接口,提供了Collection之外的插入、提取和检索操作。这三种操作都有两种形式,一种失败之后会抛出异常,另一种会返回特定的值(null或者false)。

Map部分
Map是一个映射接口,其中的每个元素都是一个key-value键值对。
Map接口
散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f(key)。
对应关系f称为散列函数,又称为哈希(Hash)函数。
采用散列技术将记录存储在一块连续的存储空间中,这块连续的存储空间称为散列表或哈希表(Hash table)。
/**
* An object that maps keys to values. A map cannot contain duplicate keys;
* each key can map to at most one value.
*/
一个匹配key和value的对象。
包含的主要方法:
- int size()
- boolean isEmpty()
- boolean containsKey(Object key)
- boolean containsValue(Object value)
- V get(Object key)
- V put(K key, V value)
- V remove(Object key)
- putAll(Map m)
- clear()
- Set keySet()
- Collection values()
- entrySet()
- boolean equals(Object o)
- int hashCode()
Map接口中包含一个Entry接口,这是对Map一个条目的封装即一个键值对。可以通过它操作条目的键值。
AbstractMap
实现Map接口的骨架,减小用户创建自定义Map的成本。
如果你想创建一个自己的可以修改的Map,比如重写V put(K key, V value)和V remove(Object key)方法以及实现entrySet().iterator()。
SortedMap接口
/**
* A {@link Map} that further provides a <em>total ordering</em> on its keys.
* The map is ordered according to the {@linkplain Comparable natural
* ordering} of its keys, or by a {@link Comparator} typically
* provided at sorted map creation time. This order is reflected when
* iterating over the sorted map's collection views (returned by the
* {@code entrySet}, {@code keySet} and {@code values} methods).
* Several additional operations are provided to take advantage of the
* ordering. (This interface is the map analogue of {@link SortedSet}.)
*/
提供了进一步对Map的key进行排序的操作。
扩展的方法:
- Comparator comparator()
- K firstKey()
- K lastKey()
- SortedMap headMap(K toKey)
- SortedMap subMap(K fromKey, K toKey)
- SortedMap tailMap(K fromKey)
