

2月1日,一个让千千万万的运维人无法忘怀的日子,我们在初五迎财神的时候,大洋彼岸的Gitlab.com运维工程师却和恶魔撞上,这个恶魔就是运维人熟知的sudo rm -rf。
Gitlab是大家很熟悉的开源Git代码托管工具,国内公司大多使用社区版自行搭建私有化的内部代码托管平台。Gitlab.com本身也提供在线代码托管和持续集成的云服务,类似Github+Travis CI的结合体。2016年Gitlab完成的B轮融资金额达2000万美元。
好消息是:Gitlab 数据库终于在北京时间 2月2日 0:14 恢复成功(18:14 UTC 02/01)。
坏消息是:丢失了6小时的生产数据!(between 17:20 UTC and 23:25 UTC 01/31,影响内容为项目、用户、问题、合并请求等存储在数据库中的信息,代码和wiki存储是单独存储在文件系统中,不受影响。)
官方表示这是无法接受的,并将运用 5 why’s of why 来深入剖析并避免再犯。
值得被尊敬的是,Gitlab 官方直播了本次恢复过程,回放地址如下:
https://www.youtube.com/watch?v=nc0hPGerSd4本次故障及恢复的极简回顾
-
Gitlab 被攻击,连锁反应导致PostgreSQL复制出现问题;
-
极度疲劳的运维操作人员A做了一个误操作:本来应该在出问题的数据库服务器执行 rm -rf / ,结果在正常的数据库服务器上执行(2秒钟后他回过神来,但300GB的数据已然只剩下4.5GB);
-
万幸的事,故障发生前,做了一次手工的LVM快照,否则只能恢复到24小时前了。。。
以下为本次故障处理的全过程,由高效运维社区金牌编辑@龙井编译自故障官方地址:
https://about.gitlab.com/2017/02/01/gitlab-dot-com-database-incident/此次事件影响的是下图中的PostgreSQL(影响内容为项目、用户、问题、合并请求等存储在数据库中的信息,代码和wiki存储是单独存储在文件系统中,不受影响。
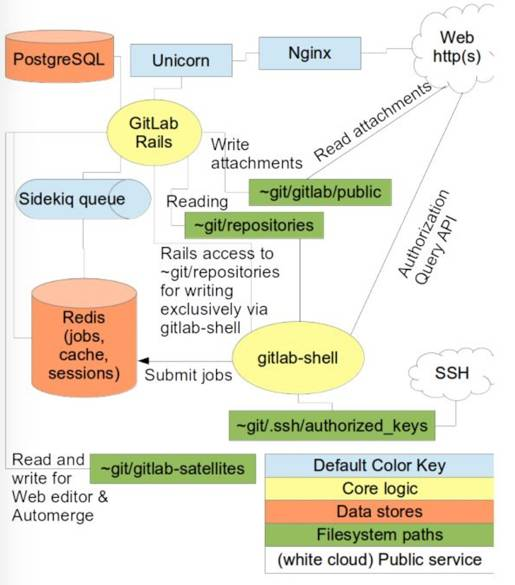
第一阶段
2017/01/31 18:00 UTC,我们发现垃圾邮件发送者通过创建snippet(笔者:snippet是Gitlab中的代码片断,Gitlab可以将代码文件的片断共享给其他人查看和协作)造成数据库的不稳定。我们立即开始分析问题原因和考虑解决办法。
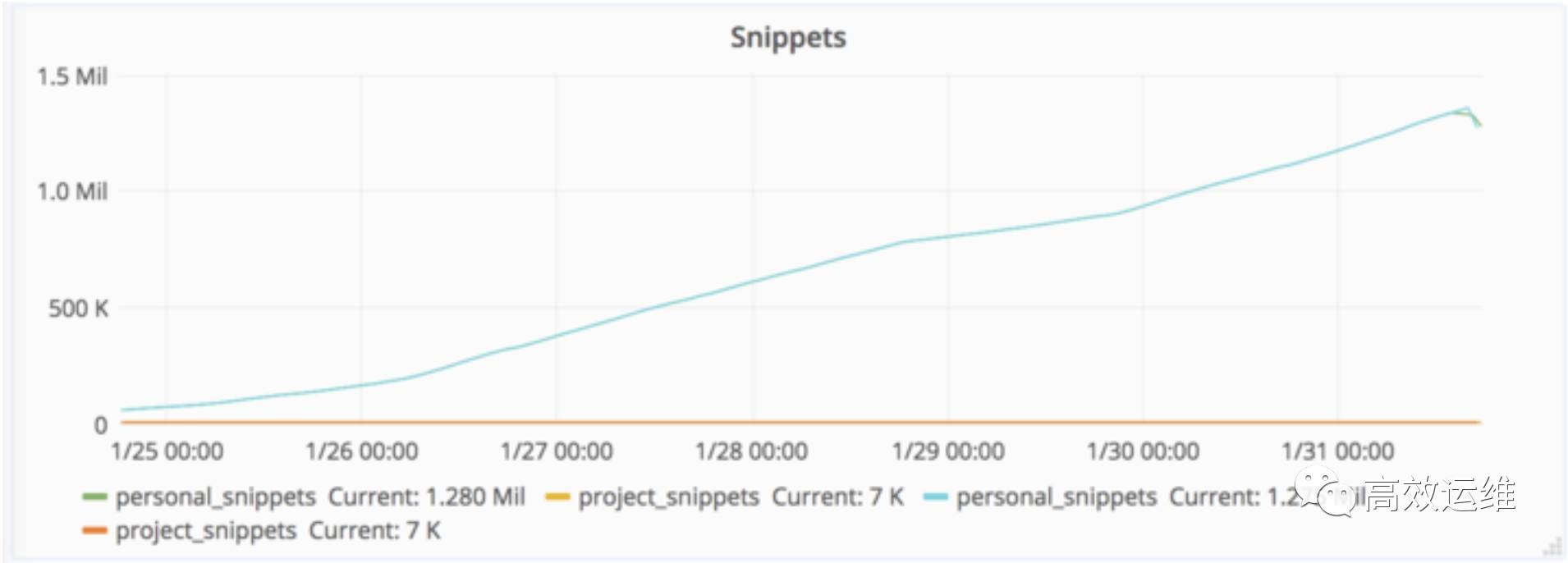
2017/01/31 21:00 UTC,事件引发数据库无法执行写操作,造成宕机。
采取的措施:
-
我们屏蔽了垃圾邮件发送者的IP地址;
-
我们移除了一个用户,不允许该用户以某种CDN的形式使用仓库。因为有47000个IP地址使用这个账户登录(引发数据库高负载);
-
我们移除了通过创建snippets发送垃圾邮件的用户。
第二阶段
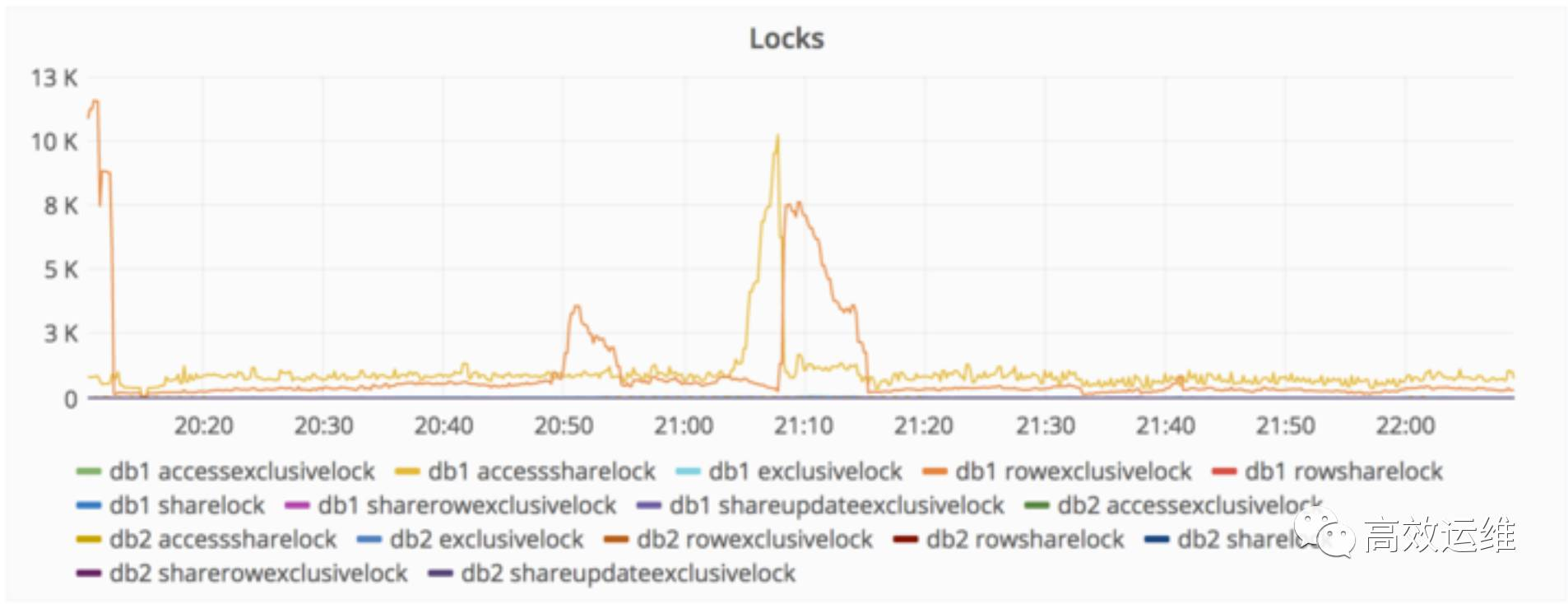
2017/01/31 22:00 UTC,我们收到消息,数据库复制严重滞后。原因是从数据库有一个高峰写操作没有及时处理。
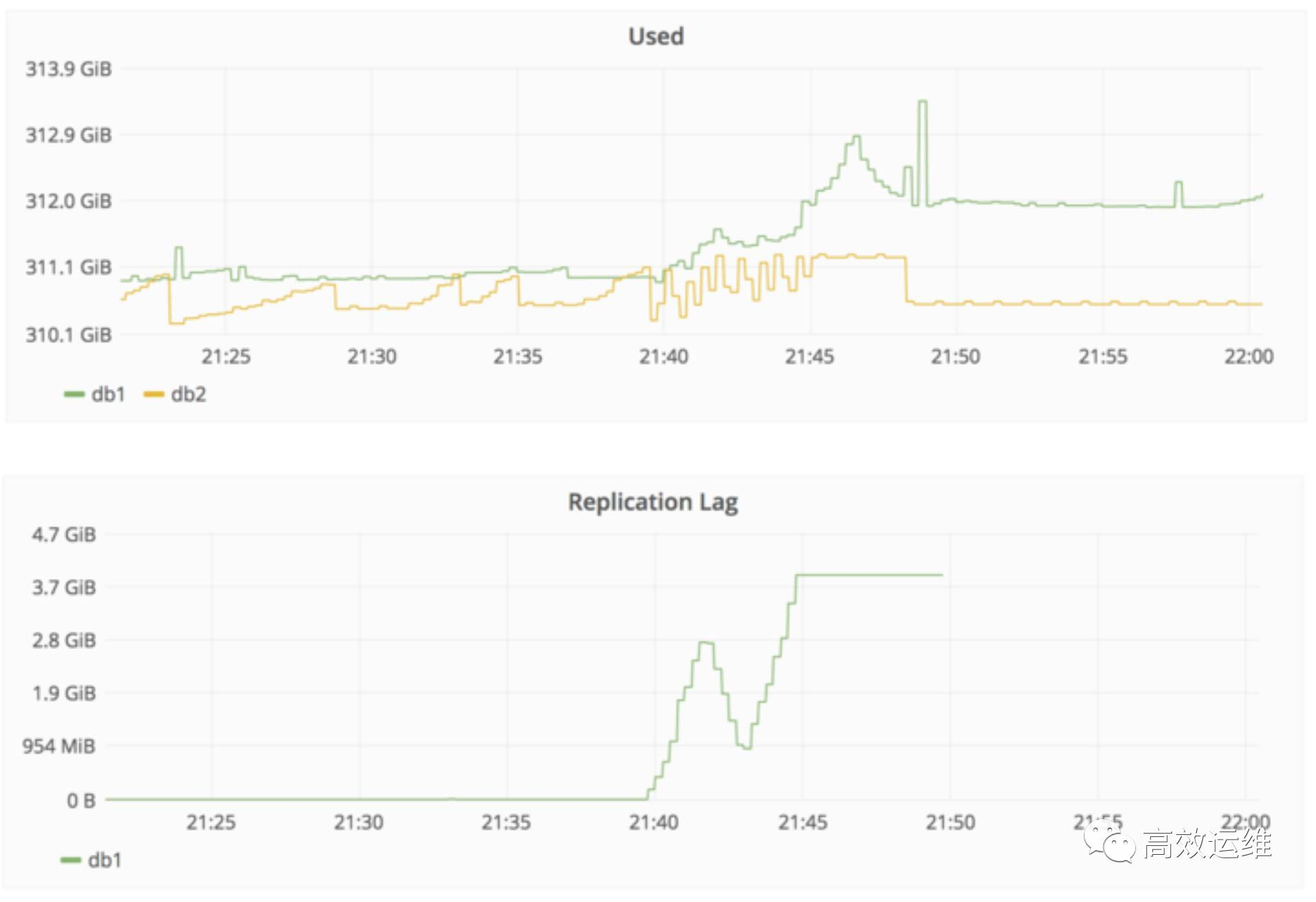
采取的措施:
-
试图修复db2,它滞后大概4GB数据;
-
db2.cluster 拒绝复制,擦除/var/opt/gitlab/postgresql/data目录,以便进行干净的复制;
-
db2.cluster 拒绝连接db1,提示max_wal_senders太低。这项参数是为了限制WAL(复制)客户端的数量;
-
运维工程师A调整了db1的max_wal_senders为32.重启了PostgreSQL;
-
PostgreSQL提示信号太多被打开,启动失败;
-
运维工程师A将max_connections从8000调整到了2000。PostgreSQL重新启动(虽然8000已经使用了近一年);
-
db2.cluster依然拒绝复制,但是已经不提示连接信息,而是死在那儿了;
-
这个时候大家都很沮丧,晚上的早些时候运维工程师A明确提出他要下班了,因为已经很晚了。但是因为复制问题突然放大,不得不继续。
第三阶段
2017/01/31 23:00,运维工程师A认为造成pg_basebackup拒绝工作的可能原因是PostgreSQL数据目录存在(虽然目录是空的)。他觉得删除目录是管用的。
一两秒之后,他突然意识到,他在正常的db1.cluster.gitlab.com执行了删除数据库目录的命令,而不是有问题的db2.cluster.gitlab.com(天了噜)。
2017/01/31 23:27,运维工程师A停止了删除操作,但是一切都为时晚矣。原本300GB的数据只剩下4.5GB。
我们只好将Gitlab.com暂时关闭,并在Twitter上公布:
我们正在进行数据库紧急维护 ...
— GitLab.com Status(@gitlabstatus)2017年1月31日
遇到的问题
-
LVM快照默认24小时执行一次,运维工程师A碰巧服务中断的6小时前手动执行过一次。因为他负责数据负载均衡。
-
日常备份也是24小时执行一次,然而运维工程师A并没有找到日常备份存储位置。根据运维工程师B的说法,日常备份并没有生效,因为生产数据只有几个字节大小。
笔者:这里的日常备份应该指的是Gitlab官方提供的gitlab-rake gitlab:backup:create。使用crontab,每天只需一次,会将数据库、代码库、文件打包备份。
-
运维工程师C:看起来pg_dump也失败了,运维运行的是PostgreSQL 9.2二进制代码,而不是9.6二进制代码。
之所以会出现这种情况,是因为Gitlab omnibus(Gitlab提供omnibus和源码安装两种方式)只在data/PG_VERSION文件被设成9.6时使用Pg 9.6,但是在worker节点上,该文件不存在。所以默认情况下运行9.2,悄然失效。因此没有SQL dumps。
Fog gem(Ruby on Rails的包)可能清除掉了早些时候的备份。
-
Azure上只对NFS服务器启用了磁盘快照,没有在DB服务器启用磁盘快照
-
往预发布环境同步数据的同步程序一旦同步会自动删除webhooks(笔者:Gitlab提供webhook以支持调用、事件触发等功能),除非我们可以在过去的24小时内的常规备份中找回这些数据,否则webhooks将会丢失。
-
复制过程很脆弱,容易出错,需要依靠一些手工编写的shell脚本,而且没有完备的文档说明。
-
往S3的备份显然也没有成功。
-
这就是说,我们的5级备份/复制技术没有毛用,我们最终只能恢复6小时以前的备份数据(笔者:这还是上帝可怜运维工程师A,给的一次偶然机会,如果他没有手工进行一次LVM快照,只能恢复24小时以前的)
-
pg_basebackup只能等待主数据库以初始化复制过程。根据另一位生产环境工程师的说法,这需要花10分钟。这引发我们思考流程一定是在某处卡住了。使用跟踪程序没能提供有用的信息。
恢复
我们正在使用预发布环境的数据库备份恢复数据。
我们不小心删除了生产数据,可能不得不从备份中恢复。Google Doc中提供了直播说明 t.co/EVRbHzYlk8
— GitLab.com Status(@gitlabstatus)2017年2月1日
-
2017/02/01 00:36 - 备份 db1.staging.gitlab.com 的数据
-
2017/02/01 00:55 - 挂载db1.staging.gitlab.com 到 db1.cluster.gitlab.com
-
从预发布环境的 /var/opt/gitlab/postgresql/data/复制数据到生产环境的/var/opt/gitlab/postgresql/data/
-
2017/02/01 01:05 - nfs-share01 服务器被征用为临时存储,路径为/var/opt/gitlab/db-meltdown
-
2017/02/01 01:18 - 复制剩下的生产数据, 包括 pg_xlog 打包为20170131-db-meltodwn-backup.tar.gz
下图显示删除以及之后复制数据需要的时间:
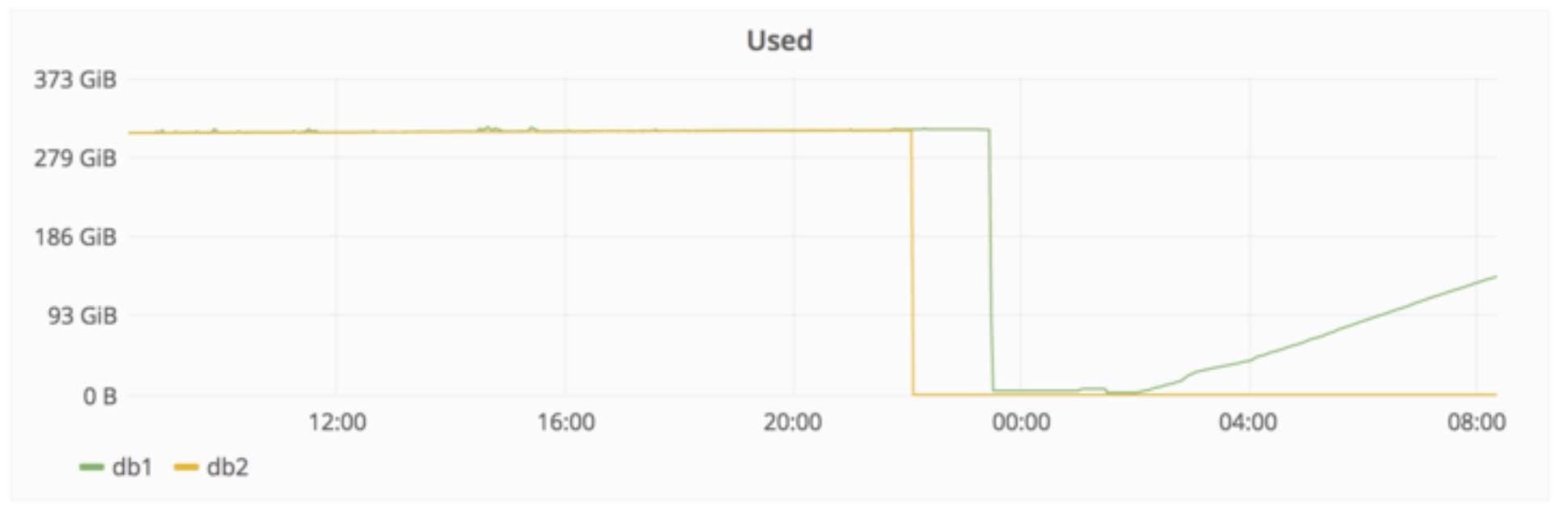
到北京时间 2月2日凌晨时,Gitlab.com的工程师还在YouTube上直播问题修复过程,回答网友的问题。受限于磁盘读写速度,恢复过程非常慢,在直播过程中也在寻求大家的帮助,提供加速办法。
以上就是Gitlab.com公布的问题修复过程介绍。
我想今天一定有很多外国程序猿们被迫放假了,因为他们无法下载和上传代码、也无法进行持续集成验证,更别提部署上线了。五级备份都失败,网友们纷纷表示应该将2月1日定为“世界备份日”以纪念此次事件和警示后人。
这次事件给我们的警示:
-
不要疲劳驾驶,喝酒不上机,上机不喝酒,尤其别动数据库;
-
建议要对rm命令设置alias,常见做法是设置别名为mv到指定目录;
-
备份和恢复验证同在,定期从备份数据进行恢复演练,既验证备份数据是否完整有效,也验证恢复方案是否靠谱;
-
践行DevOps的无指责文化,尤其是在做事故分析时。事故分析重在定位原因,制定改进措施;
-
在处理事故时,一定要考虑处理措施是否会引发连锁故障,重要操作三思而行;
-
应急预案还是要做的,此次事故响应和修复周期非常长,备用硬件不给力,且丢失数据,对用户而言是难以接受的;
-
千万不要在改进措施中增加线上操作的领导审批环节,不仅于事无补,还会影响效率;
听听运维小伙伴们的声音:

在直播过程中,Gitlab 工作人员明确表示不会开除这位员工。
那么,您怎么看?请投出您宝贵的一票!
 很抱歉,请在手机微信登录投票
很抱歉,请在手机微信登录投票
Gitlab 误操作的工程师,应该被开除么(单选)
-
不应该,应该推行免责文化
-
应该,影响太大了
-
容朕想想
2017年貌似各种不太平。即将于4月21日-22日举行的GOPS2017深圳站,将开设故障及如何避免的深度讨论专场,并将发布《运维三十六计》,让低级错误不再重现,让别人的经验成为您的财富:
关于本次大故障,更多专业分析,请参见@德哥文章(点击阅读原文链接)。
您有些什么话不吐不快?你觉得应该开除与否的理由是什么?敬请文末留言。
