

简介
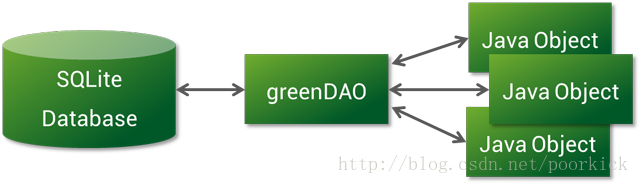
greenDAO是一个开源的Android ORM,使SQLite数据库的开发再次变得有趣。 它减轻了开发人员处理底层的数据库需求,同时节省开发时间。 SQLite是一个很不错的关系型数据库。 尽管如此,编写SQL和解析查询结果仍然是相当乏味和耗时的任务。 greenDAO通过将Java对象映射到数据库表(称为ORM,“对象/关系映射”)来解决这些问题。 这样,您可以使用简单的面向对象的API来存储,更新,删除和查询Java对象。
特性
- 最高性能(可能是Android中最快的ORM); 我们的benchmarks 也是开源的
- 涵盖关系和连接且易用的强大API
- 最小的内存开销
- 迷你开源库(<100KB),降低工程构建时间同时避免65k方法限制
- 数据库加密:greenDAO支持SQLCipher以保证用户的数据安全
- 强大的社区:超过5000 GitHub星星表明我们拥有一个强大而活跃的社区
开始使用
入门
本教程将引导你完成一个简单的greenDAO示例项目DaoExample。 克隆代码并运行它,或者直接在GitHub上查看文件。
DaoExample是一个简单地用来记笔记的Android应用程序。 你可以通过键入一些文本来添加新笔记,并通过点击现有笔记删除笔记。
1. Note实体和DAO类
一起看下代码:在src文件夹中,你会发现一个实体类Note.java。 它被持久化到数据库并包含Note的所有数据,如id,注释文本和创建日期。
@Entity(indexes = {
@Index(value = "text, date DESC", unique = true)
})
public class Note {
@Id
private Long id;
@NotNull
private String text;
private Date date;
...通常,实体是在数据库中持久化的类(例如,一个对象的一行)。 实体包含映射到数据库列的属性。
现在开始编译工程,例如在Android Studio中使用“Build> Make project”。 这将触发greenDAO来生成DAO类,例如NoteDao.java,这将帮助我们向数据库添加笔记。
2. 插入和删除笔记
要学习如何添加一些笔记,请看一下NoteActivity类。 首先,我们必须为我们的Note类准备一个DAO对象,我们在onCreate()中做:
// get the note DAO
DaoSession daoSession = ((App) getApplication()).getDaoSession();
noteDao = daoSession.getNoteDao();当用户单击添加按钮时,将调用addNote()方法。 在这里,我们创建一个新的Note对象,并将其传递给DAO insert()方法,以将其插入到数据库中:
Note note = new Note(null, noteText, comment, new Date());
noteDao.insert(note);
Log.d("DaoExample", "Inserted new note, ID: " + note.getId());注意,我们在创建笔记的时候没有传递id。 在这种情况下,数据库决定note id。 DAO负责在从插入操作返回之前自动设置新的ID(请参阅日志语句)。
删除笔记也很简单,参见NoteClickListener:
noteDao.deleteByKey(id);你可以探索NoteDao的其他方法,比如loadAll()和update()。
3. 设置数据库
你已经看到了DAO,但是如何初始化greenDAO和底层数据库呢? 通常你需要init一个DaoSession,它通常在整个应用程序中的Application类中执行一次:
DevOpenHelper helper = new DevOpenHelper(this, "notes-db");
Database db = helper.getWritableDb();
daoSession = new DaoMaster(db).newSession();使用生成的DaoMaster类提供的帮助器类DevOpenHelper创建数据库。 它是DaoMaster中的OpenHelper类的一个实现,它为你创建所有数据库。 再也不需要编写“CREATE TABLE”语句。
然后Activity和Fragment可以调用getDaoSession()来访问所有实体DAO,和我们之前在插入和删除的时候一样。
4. 扩展和添加实体
为了扩展我们的笔记或创建新实体,你只需修改或创建Java类,并以相同的方式注解它们。 然后重新编译项目。
有关详细信息,请参阅建模实体。(这个下面已经翻译出来)
介绍
greenDAO是Android的对象/关系映射(ORM)工具。 它为关系数据库SQLite提供了一个面向对象的接口。像greenDAO一类的ORM工具为你做很多重复性的任务,提供简单的数据接口。
1. Gradle插件和DAO代码生成
为了在你的Android项目中使用greenDAO,你需要添加greenDAO Gradle插件并添加greenDAO库:
buildscript {
repositories {
mavenCentral()
}
dependencies {
classpath 'org.greenrobot:greendao-gradle-plugin:3.2.1'
}
}
apply plugin: 'com.android.application'
apply plugin: 'org.greenrobot.greendao'
dependencies {
compile 'org.greenrobot:greendao:3.2.0'
}然后进行实体建模也就是创建实体,并编译项目,例如在Android Studio中使用“Build> Make Project”。
2. 核心类
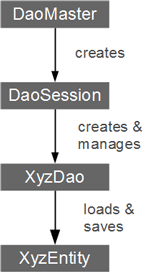
一旦项目构建完毕,你就可以在Android项目中开始使用greenDAO了。
以下核心类是greenDAO的基本接口:
DaoMaster:使用greenDAO的切入点。 DaoMaster保存数据库对象(SQLiteDatabase)并管理特定模式的DAO类(而不是对象)。 它有静态方法来创建表或删除它们。 它的内部类OpenHelper和DevOpenHelper都是SQLiteOpenHelper的实现,用来在SQLite数据库中创建模式。
DaoSession:管理特定模式的所有可用DAO对象,你可以使用其中一个的getter方法获取DAO对象。 DaoSession还为实体提供了一些通用的持久性方法,如插入,加载,更新,刷新和删除。 最后,DaoSession对象也跟踪identity scope。 有关更多详细信息,请查看会话文档
DAO:数据访问对象(DAO),用于实体的持久化和查询。 对于每个实体,greenDAO会生成一个DAO。 它比DaoSession拥有更多的持久化方法,例如:count,loadAll和insertInTx。
实体:可持久化对象。 通常,实体是使用标准Java属性(如POJO或JavaBean)表示数据库行的对象。
3. 核心初始化
最后,以下代码示例说明了初始化数据库和核心greenDAO类的第一步
//做一次,例如在你的Application类中
helper = new DaoMaster.DevOpenHelper(this,“notes-db”,null);
db = helper.getWritableDatabase();
daoMaster = new DaoMaster(db);
daoSession = daoMaster.newSession();
//在您的活动/片段中执行此操作以获取DAO
noteDao = daoSession.getNoteDao();该示例假设存在一个Note实体。 有了它的DAO(noteDao对象),我们可以调用这个特定实体的持久化操作。
实体建模
要在项目中使用greenDAO,您需要创建一个表示应用程序中持久数据的实体模型。 然后,基于此模型,greenDAO为DAO类生成Java代码。
模型本身是使用带有注解的Java类定义的。
要使用旧式生成器创建模式,请参阅生成器。
下侧的图示描述了greenDAO所基于的元模型。
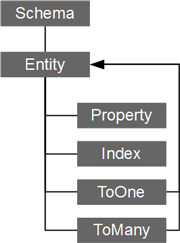
1. 模式
无需任何其他配置就可以开始使用greenDAO Gradle插件。但是,至少应该像下面这样设置下模式版本:
// In the build.gradle file of your app project:
android {
...
}
greendao {
schemaVersion 2
}此外,greendao配置元素支持一系列配置选项:
- schemaVersion:数据库模式的当前版本。 这由* OpenHelpers类用于在模式版本之间迁移。 如果更改实体/数据库模式,则必须增加此值。 默认值为1。
- daoPackage:生成的DAO,DaoMaster和DaoSession的包名称。 默认为源实体的包名称。
- targetGenDir:生成的源码应存储在的位置。 默认为生成目录(build / generated / source / greendao)中生成的源文件夹。
- generateTests:设置为true以自动生成单元测试。
- targetGenDirTests:生成的单元测试应存储在的基本目录。 默认为src / androidTest / java。
2. 实体和注解
greenDAO 3使用注解来定义模式和实体。 这里有一个简单的例子:
@Entity
public class User {
@Id
private Long id;
private String name;
@Transient
private int tempUsageCount; // not persisted
// getters and setters for id and user ...
}@Entity注解将Java类User转换为数据库支持的实体。 这也将指示greenDAO生成必要的代码(例如DAO)。
注意:仅支持Java类。 如果你喜欢另一种语言,如Kotlin,你的实体类仍然必须是Java。
5. @Entity 注解
正如在上面的示例中看到的,@Entity注解将Java类标记为greenDAO的持久化的实体。
虽然通常没有任何额外的参数,在使用@Entity的时候你仍然可以配置一些细节:
@Entity(
// If you have more than one schema, you can tell greenDAO
// to which schema an entity belongs (pick any string as a name).
schema = "myschema",
// Flag to make an entity "active": Active entities have update,
// delete, and refresh methods.
active = true,
// Specifies the name of the table in the database.
// By default, the name is based on the entities class name.
nameInDb = "AWESOME_USERS",
// Define indexes spanning multiple columns here.
indexes = {
@Index(value = "name DESC", unique = true)
},
// Flag if the DAO should create the database table (default is true).
// Set this to false, if you have multiple entities mapping to one table,
// or the table creation is done outside of greenDAO.
createInDb = false,
// Whether an all properties constructor should be generated.
// A no-args constructor is always required.
generateConstructors = true,
// Whether getters and setters for properties should be generated if missing.
generateGettersSetters = true
)
public class User {
...
}注意,当使用Gradle插件时,目前不支持多个模式。 暂时,继续使用你的生成器项目。
5. 基本属性
@Entity
public class User {
@Id(autoincrement = true)
private Long id;
@Property(nameInDb = "USERNAME")
private String name;
@NotNull
private int repos;
@Transient
private int tempUsageCount;
...
}@Id注解选择long / Long属性作为实体ID。 在数据库术语中,它是主键。 参数autoincrement是一个标志,使ID值不断增加(不重用旧值)。
@Property允许你定义一个当前属性映射到的数据库列的非默认名称。 如果为空,greenDAO将以SQL-ish方式使用字段名(大写字母,下划线代替驼峰,例如customName将成为CUSTOM_NAME)。 注意:当前只能使用内联常量来指定列名称。
@NotNull使属性在数据库端为“NOT NULL”列。 通常,使用@NotNull标记原始类型(long,int,short,byte),同时使用封装类(Long,Integer,Short,Byte)可以使用空值。
@Transient标记要从持久性中排除的属性。 将它们用于临时状态等。或者,也可以使用Java中的transient关键字。
6. 主键限制
目前,实体必须具有long或Long属性作为其主键。 这是Android和SQLite的推荐做法。
要解决此问题,请将你的键属性定义为其他属性,但为其创建唯一索引:
@Id
private Long id;
@Index(unique = true)
private String key;7. 属性索引
在属性中使用@Index可为相应的数据库列创建数据库索引。 使用以下参数自定义:
name:如果你不喜欢greenDAO为索引生成的默认名称,你可以在这里指定你的名字。
unique:向索引添加UNIQUE约束,强制所有值是唯一的。
@Entity
public class User {
@Id private Long id;
@Index(unique = true)
private String name;
}@Unique向数据库列添加UNIQUE约束。 注意,SQLite也隐式地为它创建一个索引。
@Entity
public class User {
@Id private Long id;
@Unique private String name;
}8. 默认值
greenDAO尝试使用合理的默认值,以便开发人员每个都一一配置。
例如,数据库侧的表和列名称派生自实体和属性名称。 而不是在Java中使用的骆驼案例样式,默认数据库名称使用大写,使用下划线分隔单词。
例如,名为creationDate的属性将成为数据库列CREATION_DATE
9. 关系
要了解如何添加一对一和多对多关系,请参阅关系(下面已经翻译)
10. 触发生成
一旦实体模式就位,你就可以通过在IDE中使用“Make project”来触发代码生成过程。 或者直接执行greendao Gradle任务。
如果在更改实体类之后遇到错误,请尝试重新生成项目,以确保清除旧生成的类。
11. 修改生成的代码
greenDAO 3中的实体类由开发人员创建和编辑。 然而,在代码生成过程中,greenDAO可能会增加实体的源代码。
greenDAO将为它创建的方法和字段添加一个@Generated注解,以通知开发人员并防止任何代码丢失。 在大多数情况下,你不必关心使用@Generated注解的代码。
作为预防措施,greenDAO不会覆盖现有代码,并且如果手动更改生成的代码会引发错误:
Error:Execution failed for task ':app:greendao'.
> Constructor (see ExampleEntity:21) has been changed after generation.
Please either mark it with @Keep annotation instead of @Generated to keep it untouched,
or use @Generated (without hash) to allow to replace it.正如错误消息所暗示的,通常有两种方法来解决此问题:
- 将更改还原为使用@Generated注解的代码。 或者,你也可以完全删除更改的构造函数或方法。 它们将与下一个版本重新生成。
- 使用@Keep注解替换@Generated注解。 这将告诉greenDAO永远不要触摸带注解的代码。 请记住,你的更改可能会中断实体和其他greenDAO之间的约定。 此外,未来的greenDAO版本可能期望生成的方法中有不同的代码。 所以,要谨慎!。同时采用单元测试的方法来避免麻烦是个不错的选择。
12. 保留部分
不再支持旧版本的greenDAO中使用的KEEP。
但是,如果Gradle插件检测到KEEP FIELDS部分,它将自动使用@Transient注释字段。 之后,可能会删除周围的KEEP FIELDS注释。
会话和会话的identity scope
(生成的)DaoSession类是greenDAO的中心接口之一。 DaoSession提供开发人员访问基本实体操作和相较于DAO的更完整的操作集合。 此外,会话还管理实体的identity scope。
1. DaoMaster and DaoSession
如“入门”部分所述,你需要创建一个DaoMaster以获取DaoSession:
daoMaster = new DaoMaster(db);
daoSession = daoMaster.newSession();请注意,数据库连接属于DaoMaster部分,因此多个会话指的是同一个数据库连接。 因此,我们可以相当快地创建新会话。 但是,每个会话得分配存储空间,特别是实体的会话“缓存”。
2. Identity scope 和会话缓存
如果有两个查询返回相同的数据库对象,则使用多少个Java对象:一个或两个? 它完全取决于Identity scope。
greenDAO中的默认值(行为是可配置的)是多个查询返回对同一Java对象的引用。 例如,从ID为42的USER表中加载User对象会为这两个查询返回相同的Java对象。
这种方式的副作用是某种实体“缓存”。 如果实体对象在内存中仍然存在(greenDAO在这里使用弱引用),则不会再次构造该实体。 此外,greenDAO不执行数据库查询以更新实体值。 相反,对象从会话高速缓存“立即”返回,这个速度是相当快的。
3. 清除identity scope
要清除整个会话的identity scope,以便不返回“缓存”对象:
daoSession.clear();清除单个DAO的identity scope:
noteDao = daoSession.getNoteDao();
noteDao.detachAll();4. 概念
本文档页面当前信息有限。 请参考Hibernate会话以掌握会话和identiry scope的完整概念。
查询和查询构建器
查询返回符合特定条件的实体。 在greenDAO中,你可以使用原始SQL来制定查询,或者使用QueryBuilder API,相对而言后者会更容易。
此外,查询支持懒加载结果,当在大结果集上操作时,可以节省内存和性能。
1. 查询构建器
编写SQL可能很困难,并且容易出现错误,这些错误仅在运行时被察觉。 QueryBuilder类允许你为没有SQL的实体构建自定义查询,并帮助在编译时检测错误。
简单条件示例:查询所有名为“Joe”的用户,按姓氏排序:
List<User> joes = userDao.queryBuilder()
.where(Properties.FirstName.eq("Joe"))
.orderAsc(Properties.LastName)
.list();嵌套条件示例:获取1970年10月或之后出生的名为“Joe”的用户。
假设我们有一个用户的生日作为年,月和日的单独属性。 然后,我们可以用更正式的方式表示条件:名字是“Joe”AND(出生年份大于1970年或(出生年份是1970年,出生年份等于或大于10))( 10月,10月)。
QueryBuilder<User> qb = userDao.queryBuilder();
qb.where(Properties.FirstName.eq("Joe"),
qb.or(Properties.YearOfBirth.gt(1970),
qb.and(Properties.YearOfBirth.eq(1970), Properties.MonthOfBirth.ge(10))));
List<User> youngJoes = qb.list();2. 限制,偏移和分页
有时候,你只需要一个查询结果的子集,例如在用户界面中显示的前10个元素。 当拥有大量实体时,这是非常有用的(节省资源的),并且你也不能使用“where”语句来限制结果。 QueryBuilder 有定义限制和偏移的方法:
limit(int):限制查询返回的结果数。
offset(int):结合limit(int)设置查询结果的偏移量。 将跳过第一个偏移结果,并且结果的总数将受limit(int)限制。 你不能使用offset无限制(int)。
3. 使用自定义类型作为参数
通常,greenDAO以透明方式映射查询中使用的类型。 例如,boolean被映射到INTEGER,具有0或1个值,并且Date被映射到(long)INTEGER值。
自定义类型是一个例外:在构建查询时,总是必须使用数据库值类型。 例如,如果使用转换器将枚举类型映射到int值,则应在查询中使用int值。
4. 查询和LazyList
Query类表示可以多次执行的查询。当你使用QueryBuilder中的一个方法来获取结果(如list())时,执行过程中QueryBuilder 内部会使用Query 类。如果要多次运行同一个查询,应该在QueryBuilder 上调用build()来创建查询而并非执行它。
greenDAO支持唯一结果(0或1个结果)和结果列表。如果你想在Query (或QueryBuilder )上有唯一的结果调用unique(),这将为你提供单个结果或者在没有找到匹配的实体时返回null。如果你的用例禁止null作为结果,调用uniqueOrThrow()将保证返回一个非空的实体(否则会抛出一个DaoException)。
如果希望多个实体作为查询结果,请使用以下方法之一:
- list()所有实体都加载到内存中。结果通常是一个简单的ArrayList。最方便使用。
- listLazy()实体按需加载到内存中。一旦列表中的元素第一次被访问,它将被加载并缓存以备将来使用。使用完后必须关闭。
- listLazyUncached()一个“虚拟”实体列表:对列表元素的任何访问都导致从数据库加载其数据。使用完后必须关闭。
- listIterator()让我们通过按需加载数据(lazily)来遍历结果。数据未缓存。使用完后必须关闭。
方法listLazy(),listLazyUncached()和listIterator()使用greenDAO的LazyList类。要按需加载数据,它保存对数据库游标的引用。这就是为什么你必须确保关闭惰性列表和迭代器(通常在try / finally块)。
来自listLazy()的缓存延迟列表和listIterator()中的惰性迭代器在访问或遍历所有元素后自动关闭游标。如果列表处理过早停止,开发者需要自己调用close()进行处理
5. 多次执行查询
使用QueryBuilder构建查询后,这个Query对象是可以被重复使用的。 这比总是创建新的Query对象更高效。 如果查询参数不更改,你可以继续调用列表/唯一结果等方法进行查询操作。
但是,参数是可以被更改的:通过调用setParameter方法来更改参数。 当前,通过基于零的参数索引来寻址各个参数。 索引基于我们传入到QueryBuilder的顺序。 例如:
// fetch users with Joe as a first name born in 1970
Query<User> query = userDao.queryBuilder().where(
Properties.FirstName.eq("Joe"), Properties.YearOfBirth.eq(1970)
).build();
List<User> joesOf1970 = query.list();
// using the same Query object, we can change the parameters
// to search for Marias born in 1977 later:
query.setParameter(0, "Maria");
query.setParameter(1, 1977);
List<User> mariasOf1977 = query.list();6. 在多线程中执行查询
如果在多个线程中使用查询,则必须调用forCurrentThread()获取当前线程的Query实例。 Query实例绑定到构建查询的那个线程。
你可以安全地设置Query对象的参数,不涉及到其他线程。 如果一个线程尝试修改查询参数或执行已经绑定到另一个线程的查询绑,系统将抛出异常。 用这种方式,你就不再需要synchronized语句了。 实际上,你应该避免锁定,因为如果并发事务使用相同的Query对象,这可能导致死锁。
*每次调用forCurrentThread()时,查询参数将会被设置成使用构建器构建查询时的参数。
7. 原始查询
如果QueryBuilder不能满足你的需求,有两种方法来执行原始SQL并返回实体对象。 第一种,首选的方法是使用QueryBuilder和WhereCondition.StringCondition。 这样,你可以将任何SQL片段作为WHERE子句传递给查询构建器。
以下代码是一个理论示例,说明如何运行子选择(使用连接将是更好的解决方案):
Query<User> query = userDao.queryBuilder().where(
new StringCondition("_ID IN " +
"(SELECT USER_ID FROM USER_MESSAGE WHERE READ_FLAG = 0)")
).build();第二种方法不使用QueryBuilder, 而是使用queryRaw或queryRawCreate方法。 它们允许您传递一个原始SQL字符串,它附加在SELECT和实体列之后。 这样,你可以有任何WHERE和ORDER BY子句来选择实体。 可以使用别名T来引用实体表。
以下示例显示如何创建一个查询,该查询使用连接检索名为“admin”的组的用户(同样,greenDAO本身支持连接,这只是为了演示):
Query<User> query = userDao.queryRawCreate(
", GROUP G WHERE G.NAME=? AND T.GROUP_ID=G._ID", "admin"
);注意:可以使用生成的常量引用表和列名称。 这是建议避免打字错误,因为编译器将检查名称。 在实体的DAO中,你将发现TABLENAME包含数据库表的名称,以及一个内部类属性,其中包含所有属性的常量(字段columnName)。
8. 删除查询
批量删除不会删除单个实体,但是所有实体都符合一些条件。 要执行批量删除,请创建一个QueryBuilder,调用其buildDelete()方法,并执行返回的DeleteQuery。
***API的这一部分可以在将来改变,例如可以添加方便的方法。
请注意,批量删除目前不影响identity scope中的实体,例如,如果已删除的实体先前已缓存,并通过其ID(加载方法)进行访问,则可以“复活”。 请考虑立即清除身份范围,如果这可能会导致你的用例的问题。*
9. 疑难解答查询
您的查询不返回预期结果? 在QueryBuilder上启用SQL和参数记录有两个静态标志:
QueryBuilder.LOG_SQL = true;
QueryBuilder.LOG_VALUES = true;当调用其中一个构建方法时,它们将记录生成的SQL命令和传递的值,并将它们与实际所需的值进行比较。 此外,它可能有助于将生成的SQL复制到一些SQLite数据库浏览器,并看看它如何执行。
查询构建器连接表
1. 连接
非普通查询通常需要几个实体类型(表)的数据。 在SQL世界中,可以通过使用连接条件“连接”两个或多个表来实现。
让我们考虑一个实体User,它与Address实体具有一对多的关系。 然后,我们要查询居住在“Sesame Street”上的用户:我们必须使用用户ID与User实体加入Address实体,并在Address实体上定义WHERE条件:
QueryBuilder<User> queryBuilder = userDao.queryBuilder();
queryBuilder.join(Address.class, AddressDao.Properties.userId)
.where(AddressDao.Properties.Street.eq("Sesame Street"));
List<User> users = queryBuilder.list();连接需要目标实体类作为每个实体的参数和连接属性。 在示例中,只定义Address实体的join属性,因为默认使用主键属性。 换句话说,查询导致用户具有UserId等于User实体ID并且还具有特定街道的Address实体。
2. 查询构建器连接API
由于可以在使用主键属性时省略join属性,因此QueryBuilder中提供了三种重载的连接方法:
/**
* Expands the query to another entity type by using a JOIN.
* The primary key property of the primary entity for
* this QueryBuilder is used to match the given destinationProperty.
*/
public <J> Join<T, J> join(Class<J> destinationEntityClass, Property destinationProperty)
/**
* Expands the query to another entity type by using a JOIN.
* The given sourceProperty is used to match the primary
* key property of the given destinationEntity.
*/
public <J> Join<T, J> join(Property sourceProperty, Class<J> destinationEntityClass)
/**
* Expands the query to another entity type by using a JOIN.
* The given sourceProperty is used to match the given
* destinationProperty of the given destinationEntity.
*/
public <J> Join<T, J> join(Property sourceProperty, Class<J> destinationEntityClass,
Property destinationProperty)3. 链式连接
此外,greenDAO允许跨多个表连接。 在这里,使用另一个连接和目标实体定义连接。 在这种情况下,第一连接的目的实体变为第二联接的起始实体。
用于链接连接的QueryBuilder API如下所示:
/**
* Expands the query to another entity type by using a JOIN.
* The given sourceJoin's property is used to match the
* given destinationProperty of the given destinationEntity.
* Note that destination entity of the given join is used
* as the source for the new join to add. In this way,
* it is possible to compose complex "join of joins" across
* several entities if required.
*/
public <J> Join<T, J> join(Join<?, T> sourceJoin, Property sourceProperty,
Class<J> destinationEntityClass, Property destinationProperty)让我们看看另一个有三个实体的例子:城市,国家和大陆。 如果我们要查询欧洲所有人口至少100万的所有城市,它将如下所示:
QueryBuilder<City> qb = cityDao.queryBuilder().where(Properties.Population.ge(1000000));
Join country = qb.join(Properties.CountryId, Country.class);
Join continent = qb.join(country, CountryDao.Properties.ContinentId,
Continent.class, ContinentDao.Properties.Id);
continent.where(ContinentDao.Properties.Name.eq("Europe"));
List<City> bigEuropeanCities = qb.list();4. 自连接/树示例
连接也可以与引用单个实体的关系一起使用。 例如,我们想找到所有的人,他的祖父的名字是“林肯”。 让我们假设我们有一个具有指向同一个实体的fatherId属性的Person实体。 然后,查询构建如下:
QueryBuilder<Person> qb = personDao.queryBuilder();
Join father = qb.join(Person.class, Properties.FatherId);
Join grandfather = qb.join(father, Properties.FatherId, Person.class, Properties.Id);
grandfather.where(Properties.Name.eq("Lincoln"));
List<Person> lincolnDescendants = qb.list();如您所见,连接是构建跨多个实体类型或关系的查询的强大工具。
实体之间的关系(一对多)
1. 关系
数据库表可以使用1:1,1:N或N:M关系彼此相关。 如果你刚接触数据库关系,你需要在我们讨论ORM之前快速的恶补一下。 这里有一些关于数据库关系的网络链接。
第一篇
第二篇
第三篇
在greenDAO中,实体使用一对一或一对多关系。 例如,如果要在greenDAO中建模1:n关系,则将具有一对一关系和一对多关系。 但是,请注意,一对一和一对多关系不会彼此连接,因此你必须更新两者。
2. 构建一对一关系
@ToOne注解定义与另一个实体(一个实体对象)的关系。 将其应用于包含其他实体对象的属性。
在内部,greenDAO需要一个指向由joinProperty参数指定的目标实体的ID的附加属性。 如果此参数不存在,则会自动创建一个附加列来保存这个信息。
@Entity
public class Order {
@Id private Long id;
private long customerId;
@ToOne(joinProperty = "customerId")
private Customer customer;
}
@Entity
public class Customer {
@Id private Long id;
}一对一关系的getter方法(在此示例中为getCustomer())在其第一次调用时延迟解析目标实体。 后续调用将立即返回先前解析的对象。
注意,如果更改外键属性(这里为customerId),下一次对getter(getCustomer())的调用将解析实体以获取更新的ID。
另外,如果设置了一个新实体(setCustomer()),外键属性(customerId)也将被更新。
Customer customerA = user.getCustomer();
// change the customer id
user.setCustomerId(customerIdB);
// or set a customer with a different id
user.setCustomer(customerB);
customerB = user.getCustomer();
assert(customerA.getId() != customerB.getId());注意:要热加载一对一关系,请使用实体DAO类的loadDeep()和queryDeep()。 这将解析与单个数据库查询具有所有一对一关系的实体。 如果你总是访问相关实体,这将有助于性能的提高。
2. 构建一对多关系
@ToMany定义与一组其他实体(多个实体对象)的关系。 将此应用于表示目标实体列表的属性。 引用的实体必须有一个或多个属性指向拥有@ToMany的实体。
有三种可能性来指定关系映射,只使用其中一个即可:
- referencedJoinProperty参数:指定目标实体中指向此实体标识的“外键”属性的名称。
@Entity
public class Customer {
@Id private Long id;
@ToMany(referencedJoinProperty = "customerId")
@OrderBy("date ASC")
private List<Order> orders;
}
@Entity
public class Order {
@Id private Long id;
private Date date;
private long customerId;
}- joinProperties参数:对于更复杂的关系,你可以指定一列@JoinProperty注解。 每个@JoinProperty需要原始实体中的源属性和目标实体中的引用属性。
@Entity
public class Customer {
@Id private Long id;
@Unique private String tag;
@ToMany(joinProperties = {
@JoinProperty(name = "tag", referencedName = "customerTag")
})
@OrderBy("date ASC")
private List<Site> orders;
}
@Entity
public class Order {
@Id private Long id;
private Date date;
@NotNull private String customerTag;
}- @JoinEntity:如果你正在执行涉及另一个连接实体/表的N:M(多对多)关系,请在属性上放置此附加注解。
@Entity
public class Product {
@Id private Long id;
@ToMany
@JoinEntity(
entity = JoinProductsWithOrders.class,
sourceProperty = "productId",
targetProperty = "orderId"
)
private List<Order> ordersWithThisProduct;
}
@Entity
public class JoinProductsWithOrders {
@Id private Long id;
private Long productId;
private Long orderId;
}
@Entity
public class Order {
@Id private Long id;
}一旦运行,插件将生成一个getter来解析被引用实体的列表。 例如在前两种情况下:
// return all orders where customerId == customer.getId()
List<Order> orders = customer.getOrders();3. 解析和更新对多关系
多对多关系在第一个请求上解析比较慢,然后将List对象缓存在实体中。 因此,后续采用get方法调用将不会查询数据库。
更新多对多关系需要一些额外的工作。 因为缓存了一对多列表,所以当将相关实体添加到数据库时,它们不会更新。 以下代码说明了这种行为:
// get the current list of orders for a customer
List<Order> orders1 = customer.getOrders();
// insert a new order for this customer
Order order = new Order();
order.setCustomerId(customer.getId());
daoSession.insert(order);
// get the list of orders again
List<Order> orders2 = customer.getOrders();
// the (cached) list of orders was not updated
// orders1 has the same size as orders2
assert(orders1.size() == orders2.size);
// orders1 is the same object as orders2
assert(orders1.equals(orders2));因此,要添加新的相关实体,请将它们手动添加到源实体的多对多列表中,如下:
// get the to-many list before inserting the new entity
// otherwise the new entity might be in the list twice
List<Order> orders = customer.getOrders();
// create the new entity
Order newOrder = ...
// set the foreign key property
newOrder.setCustomerId(customer.getId());
// persist the new entity
daoSession.insert(newOrder);
// add it to the to-many list
orders.add(newOrder);同样,你可以删除相关实体,如下:
List<Order> orders = customer.getOrders();
// remove one of the orders from the database
daoSession.delete(someOrder);
// manually remove it from the to-many list
orders.remove(someOrder);添加,更新或删除许多相关实体时,可以使用重置方法清除缓存的列表。 然后下一个get将重新查询相关实体:
// clear any cached list of related orders
customer.resetOrders();
List<Order> orders = customer.getOrders();4. 双向1:N关系
有时你想在两个方向上建立1:N关系。 在greenDAO中,你必须添加一对一和一对多关系才能实现此目的。
以下示例显示了客户和订单实体的完整建模,我们之前用作示例。 这次,我们使用customerId属性创建两个关系:
@Entity
public class Customer {
@Id private Long id;
@ToMany(referencedJoinProperty = "customerId")
@OrderBy("date ASC")
private List<Order> orders;
}
@Entity
public class Order {
@Id private Long id;
private Date date;
private long customerId;
@ToOne(joinProperty = "customerId")
private Customer customer;
}让我们假设我们有一个订单实体。 使用这两种关系,我们可以得到客户和客户所做的所有订单:
List<Order> allOrdersOfCustomer = order.getCustomer().getOrders();5. 示例:建模树关系
您可以通过使用指向自身的一对一和多对一关系建模实体来建模树关系:
@Entity
public class TreeNode {
@Id private Long id;
private Long parentId;
@ToOne(joinProperty = "parentId")
private TreeNode parent;
@ToMany(referencedJoinProperty = "parentId")
private List<TreeNode> children;
}生成的实体允许您导航其父级和子级:
TreeNode parent = entity.getParent();
List<TreeNode> children = entity.getChildren();6. 更多示例
查看DaoExample项目以获取完整的Android应用示例。
此外,DaoTestEntityAnnotation项目附带了几个关系测试。 其中,除了其他示例和测试项目之外,可以用作进一步的示例。
自定义类型:将类和枚举映射到数据库值
自定义类型允许实体具有任何类型的属性。 默认情况下,greenDAO支持以下类型
boolean, Boolean
int, Integer
short, Short
long, Long
float, Float
double, Double
byte, Byte
byte[]
String
Date1. 转换注解和属性转换器
要添加对自定义类型的支持,可以使用@Convert注释将它们映射到其中一种受支持的类型。 同时你还需要提供PropertyConverter实现。
例如,你可以使用自定义Color类在实体中定义颜色,并将其映射到整数。 或者你可以将流行的org.joda.time.DateTime从Joda Time映射到Long。
这是将枚举映射到整数的示例:
@Entity
public class User {
@Id
private Long id;
@Convert(converter = RoleConverter.class, columnType = Integer.class)
private Role role;
public enum Role {
DEFAULT(0), AUTHOR(1), ADMIN(2);
final int id;
Role(int id) {
this.id = id;
}
}
public static class RoleConverter implements PropertyConverter<Role, Integer> {
@Override
public Role convertToEntityProperty(Integer databaseValue) {
if (databaseValue == null) {
return null;
}
for (Role role : Role.values()) {
if (role.id == databaseValue) {
return role;
}
}
return Role.DEFAULT;
}
@Override
public Integer convertToDatabaseValue(Role entityProperty) {
return entityProperty == null ? null : entityProperty.id;
}
}
}注意:如果你在实体类中定义自定义类型或转换器,它们必须是静态的。
不要忘记正确处理空值 - 通常,如果输入为null,则应返回null。
转换器的数据库类型意义上不是SQLite类型,而是由greenDAO提供的原始Java类型。 建议使用易于转换的基本类型(int,long,byte数组,String,…)。
注意:为了获得最佳性能,greenDAO将为所有转换使用单个转换器实例。 确保转换器除了无参数默认构造函数之外没有任何其他构造函数。 另外,使它线程安全,因为它可能在多个实体上并发调用。
2. 如何正确转换枚举
枚举在像实体这样的数据对象中使很常用的。 当持久化枚举时,有下面几个不错的方法:
- 不要持久化枚举的序号或名称:两者都不稳定,并且很有可能下次编辑枚举定义的时候就变化了。
- 使用stable ids:在你的枚举中定义一个保证稳定的自定义属性(整数或字符串)。 使用它来进行持久性映射。
- 未知值:定义一个UNKNOWN枚举值。 它可以用于处理空值或未知值。 这将允许你处理像旧的枚举值被删除而不会崩溃您的应用程序的情况。
3. 自定义类型在查询中的处理
QueryBuilder不知道自定义类型。 您必须对查询使用原语类型(例如在WHERE参数中)。 还要注意,在数据库中完成的操作总是引用原始类型,例如在ORDER BY子句中。
数据库加密
greenDAO支持加密的数据库来保护敏感数据。
虽然较新版本的Android支持文件系统加密,但Android本身并不为数据库文件提供加密。 因此,如果攻击者获得对数据库文件的访问(例如通过利用安全缺陷或欺骗有根的设备的用户),攻击者可以访问该数据库内的所有数据。 使用受密码保护的加密数据库增加了额外的安全层。 它防止攻击者简单地打开数据库文件。
1. 使用自定义SQLite构建
因为Android不支持加密数据库,所以你需要在APK中捆绑SQLite的自定义构建。 这些定制构建包括CPU相关和本地代码。 所以你的APK大小将增加几个MByte。 因此,你应该只使用加密,如果你真的需要它。
2. 设置数据库加密
greenDAO直接支持带有绑定的SQLCipher。 SQLCipher是使用256位AES加密的SQLite的自定义构建。
2.1 添加SQLCipher依赖关系
请参阅SQLCipher for Android,了解如何向项目添加SQLCipher。
2.2 数据库初始化
确保使用DaoMaster中提供的OpenHelper的子类来创建数据库实例。 例如简单的DevOpenHelper,也在DaoMaster中提供。
然后,在创建数据库实例时,只需调用.getEncryptedWritableDb()而不是.getWritableDb()。 最后,像往常一样将数据库传递给DaoMaster:
DevOpenHelper helper = new DevOpenHelper(this, "notes-db-encrypted.db");
Database db = helper.getEncryptedWritableDb("<your-secret-password>");
daoSession = new DaoMaster(db).newSession();
DevOpenHelper helper = new DevOpenHelper(this, "notes-db-encrypted.db");
Database db = helper.getEncryptedWritableDb("<your-secret-password>");
daoSession = new DaoMaster(db).newSession();3. 数据库抽象
greenDAO对所有数据库交互使用一个小型的抽象层,因此支持标准和非标准的SQLite实现:
- Android的标准android.database.sqlite.SQLiteDatabase
- SQLCipher的net.sqlcipher.database.SQLiteDatabase
- 任何SQLite兼容的数据库,它可以实现
org.greenrobot.greendao.database.Database(例如SQLite的自定义构建)
这使您能够轻松地从标准数据库切换到加密数据库,因为在针对DaoSession和单个DAO时,代码将是相同的。
3.1 使用Robolectric进行单元测试
数据库抽象允许用Robolectric进行单元测试。 即使你的应用程序使用加密的数据库,你的测试也可以使用未加密的数据库。
Robolectric实现标准的SQLite API,没有办法加载自定义SQLite构建(Android二进制)。 因此,对于你的测试,在创建数据库实例时使用.getWritableDb()而不是.getEncryptedWritableDb()(见上文)。
3.2 SQLCipher的已知问题
SQLCipher是SQLite的自定义构建。 它的Android API与Android系统API有点分歧。 这里是我们注意到的问题(与greenDAO无关):
- 抛出的异常不是类型android.database.SQLException(请参阅SQLcipher问题223)
- SQLCipher比最近的SQLiteDatabase实现锁定更多。 这不仅降低了并发性,而且增加了死锁的机会。
- 从SQLCipher 3.5.0开始,缺少Android归类(如LOCALIZED)
写在最后
个人翻译,用于后面查阅,若有不当请担待~
原文链接:
greenrobot.org/greendao/
