

背景
业务接入了elk日志系统,考虑到能自定义日志格式和Mapping,没有使用logstash来抓取日志,而选择用本地RabbitMQ队列+Node的Elasticsearch模块来自己写日志,写日志的具体逻辑如下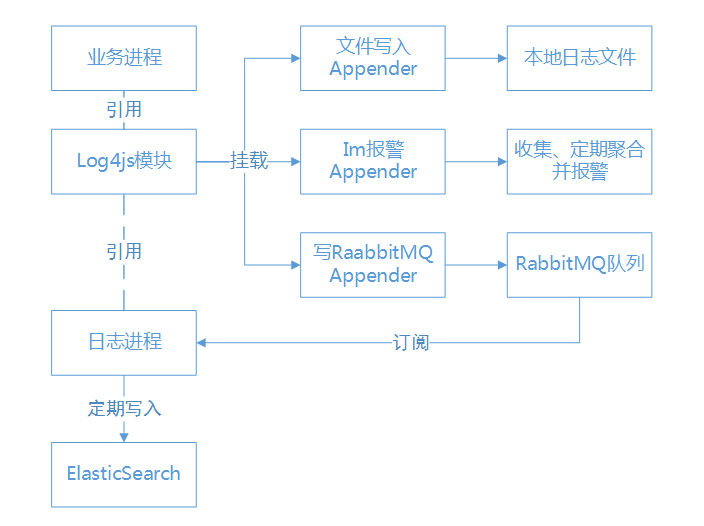
问题就出在这张图上。
bug描述
在正式环境下这个日志写入进程会经常“挂”掉,因为有另一个进程定时检查RabbitMQ队列的消息量,所以会及时发现队列的消息堆积并发出报警,这个时候到RabbitMQ的管理界面上会看到日志进程断连了(日志队列的订阅者数量为0),RabbitMQ的日志也显示客户端心跳超时断连。正常来说连接断开会触发amqplib模块connection的close或者error之类的事件,而后进程会打印错误然后退出(PM2会自动重启),但从PM2上观察,日志进程却还在运行,也没有输出错误,然后在几十分钟后结束进程。
找不到问题就加日志检查咯,由于是实时性要求不高的日志写入进程,所以随意重启调试也没关系。我在定期写入Elastic的函数(每秒执行1次)里加了调试打印,发现神奇的一幕:每逢整10分钟或20分钟,日志打印就会停止,从raabitmq管理界面上就看到进程断开了。从这里能推出两点:
- 一定跟定时任务有关
- 定时任务不再执行,最大的可能性是有严重耗时的同步操作阻塞了javascript主线程,这个也能解释为什么没有触发断开连接的事件,实际上是触发了,但事件还在Node的事件队列里等待异步处理
但之后就没头绪了,因为我的代码里根本没有每10分钟触发一次的定时任务,也没有复杂到能够卡住几十分钟的同步cpu运算,我开始怀疑是系统其他定时任务的原因影响,但并没有找到线索。
进一步检查
说来惭愧,以前碰到bug基本上都是靠加log来追踪调试的,基本都能解决,但碰到这个连log都不打印的情况,加log都没用了,这个时候就要搬出Node的性能分析工具,先运行
node --prof index.js
收集性能日志,一直运行到进程卡住挂起再停止,Node会在运行文件夹生成一个“isolate-0xnnnnnnnnnnnn-v8.log”文件,然后用它来生成简化的性能报告
node --prof-process isolate-0xnnnnnnnnnnnn-v8.log > processed.txt
报告显示了代码中各个部分占用CPU时间的情况,检查“processed.txt”之后问题一目了然:
[JavaScript]:ticks total nonlib name687497 75.5% 75.9% LazyCompile: *findMiddleSnake /xxx/node_modules/.1.0.1@mdiff/lib/index.js:43:3659471 6.5% 6.6% Stub: StringCompareStub3137 0.3% 0.3% Stub: CEntryStub {1}1545 0.2% 0.2% Stub: CEntryStub1080 0.1% 0.1% Stub: LoadICStub
看到mdiff这个模块还真是出乎意料,它用于流程图上“IM报警Appender”(代码)的聚合日志功能,简单来说就是计算两条输出日志的相似度,比较接近的日志可以统计条数再输出,避免被同样内容的日志刷屏。
原理比较暴力,就是计算出最大相同子串(就是LCS算法,使用mdiff模块提供的函数来处理),计算子串长度占原串长度的百分比(相似度)再进行聚合。那么这个计算LCS的操作会占用很长的CPU时间吗?
mdiff的文档上给出了使用算法的论文地址,出于种种原因我们就不细究到具体算法了_(:3 」∠ )_,简单看了一下算法时间复杂度:O(ND),在最坏条件下D=2N,也就是O(2N2)。而外层的统计聚合
(代码),在最坏的情况下会调用mdiff的LCS算法M2(M:日志条数)次,也就是说最差的算法复杂度是O(2N2M2),这可是十分可怕的……
再结合实际情况:一次批量写入最多512条日志,每秒写1次,日志进程向ElasticSearch写入日志经常会返回类似这样的错误:
version conflict, current version [13] is different than the one provided [12]
而返回的错误我都会完整地打印log出来,以供IM报警(参见流程图),于是产生了大量非常非常长的错误log。这些log每隔5分钟会做一次统计聚合,于是产生了严重耗时的同步操作,导致所有异步回调都被阻塞,包括各个定时器和event订阅。
解决方案
- 减少计算量
限制参与计算的日志长度和日志量,因为是用来聚合做IM报警的,本身就不需要完整显示出来,过长的日志可以直接截断。 - 减少错误出现次数
Elastic会返回“version conflict”这个错误主要是因为存在多个进程同时写入一个文档的情况,官方也提供了retry_on_conflict这个参数来解决问题,在bulk操作中它的名字是_retry_on_conflict,用于指定返回错误前的重试次数,理论上来说调大它就会减少出现版本错误的概率
做了上述处理之后,问题被修复
总结
- 对不熟悉的事物保持敬畏,多翻文档多尝试
- 对自己的代码保持猜疑,注意考虑边界条件和兜底
- 善用工具能节省无谓的时间
