

因为毕业后想从事数据挖掘相关的职业,但对该行业的需求不太了解,网上资料太多查看花时间且抓不住重点,所以爬取了拉勾网上 900 多条相关的岗位共计 30 万字的职位描述的数据进行了相关的分析。分析结果主要想回答下面两个问题:
1、目前数据挖掘岗位的现状 ?
2、如果要从事数据挖掘行业,需要具备哪些技能 ?
分析时间:2017 年 2 月
工具:RStudio, Number, R (爬取和分析使用的都是 R )
代码和爬取数据:github.com/edvardHua/J…
数据挖掘岗位现状
分两块描述,第一块是基本的统计数据,包括数据挖掘在那个城市需求最旺盛,对应聘人员的学历要求,行业的分布和公司的财务状况。第二块围绕着薪酬做相关性的分析,主要是工作资历与薪酬之间的关系,以及行业与薪酬之间的关系。
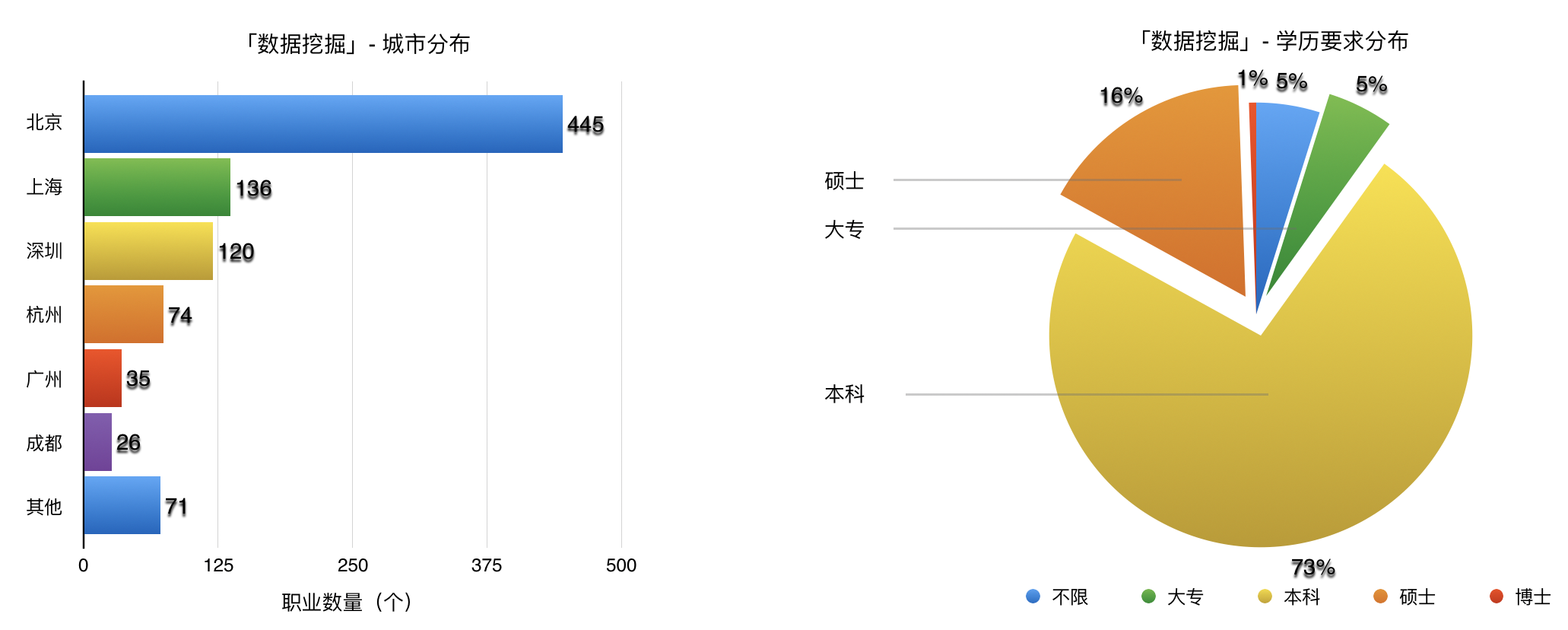
首先可以看到大部分数据挖掘岗位都分布在北京,上海,深圳和杭州,北京该岗位需求相当旺盛,差不多占据了一半的职位数量。从左边的饼图可以看出,大部分数据挖掘岗位对应聘者的学历要求为至少是本科以上。
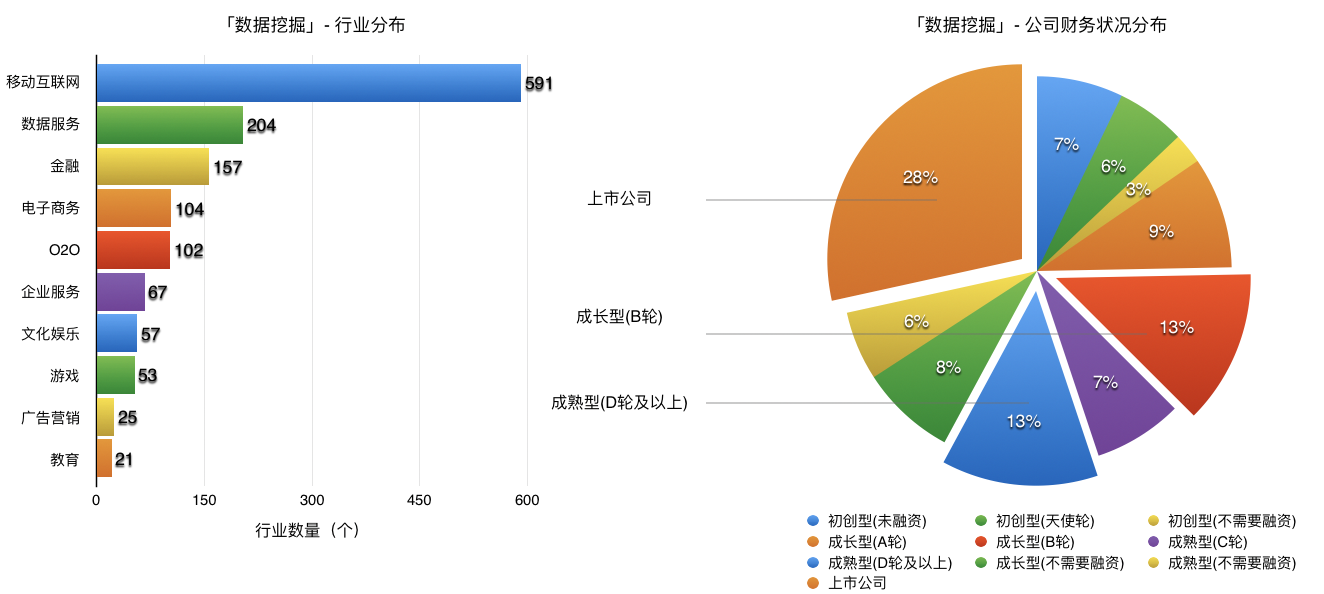
左边的条形图显示大部分的数据挖掘岗位都分布在移动互联网领域,另外,右边的饼图可以看出,上市公司和成长型 B 轮及 D 轮以上的公司对数据挖掘岗位的需求最大。
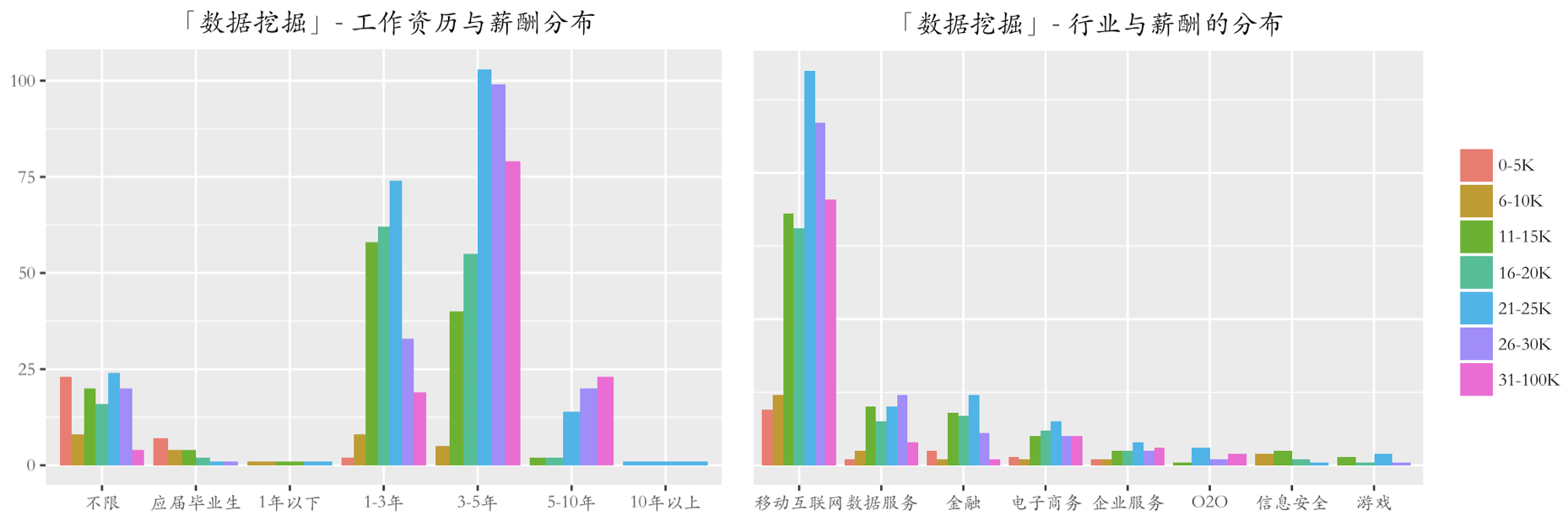
从左边这张图可以看出,对于有 1-3 年经验的应聘者,企业的普遍工资在 16-20 K 左右的水平,而对于 3-5 年工作经验的应聘者,则普遍的工资在 21-25 K,另外有意思的是,许多职位对工作经验没有要求,但是也愿意给出不错的薪酬。从右边的图可以看出,移动互联网领域职位数量多且工资相对较高,若想找份高薪的工作,在移动互联网行业做数据挖掘是个不错的选择。
从事数据挖掘行业,需要具备哪些技能组合
将爬取到的全部职位描述汇总在一起后,总共有差不多 30 万字的职位描述。这里首先使用 jiebaR 中文分词库对文本进行分析和挖掘。在挖掘之前,首先需要简历自己的词料库,我使用的词料库是从网上搜查得到,感兴趣可点击此处查询。
首先使用 jiebaR 库对 30 万字的职业描述进行关键字(TF_IDF 算法)提取,结果如下:
"数据挖掘" "算法" "数据" "经验" "熟悉" "机器学习" "优先"
关键字高度概括了企业对应聘者的需求,拿这些词造句的话,应该可以理解为:
「我们需要找一位熟悉数据结构和机器挖掘算法的人。另外,具备经验者优先。」
随后,再根据自己收集的语料库进行词频统计,做成云图,结果如下:
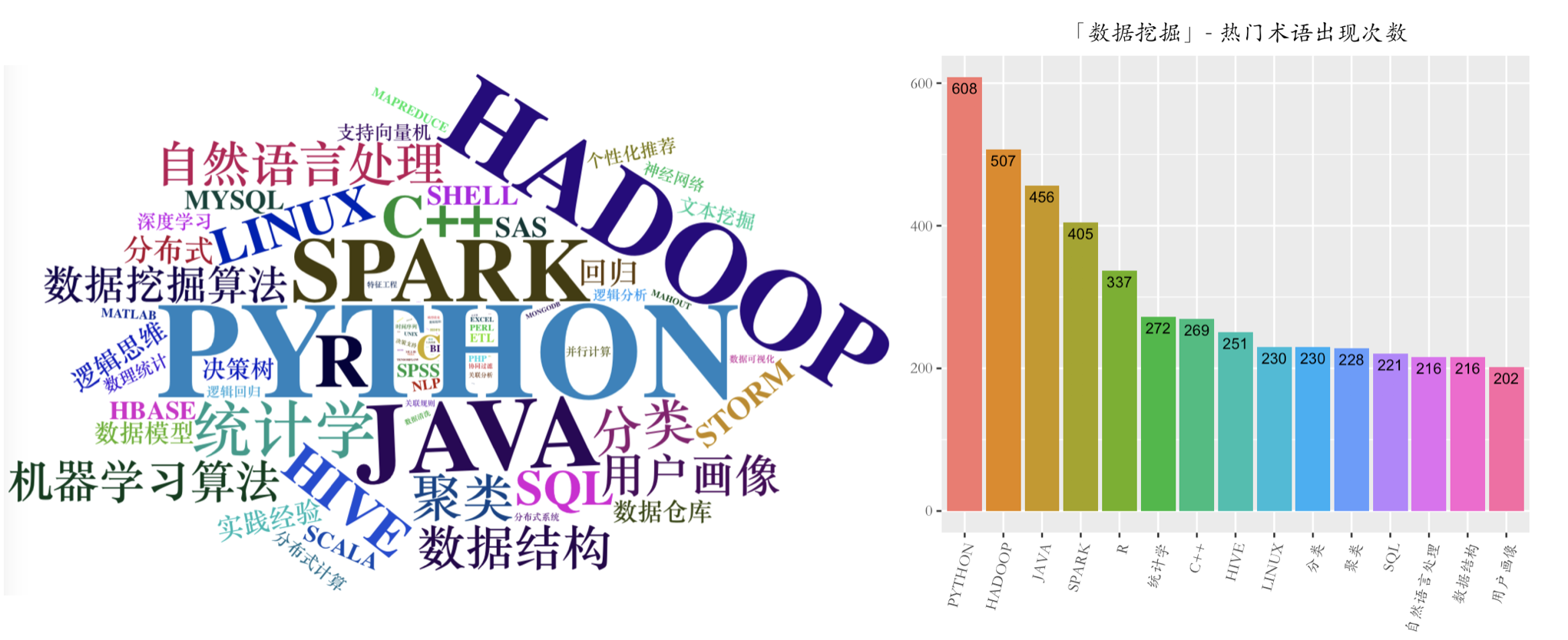
从词云和术语出现次数可以看出,想要从事数据挖掘,除了要熟悉基本的编程语言和框架外( Python,Hadoop,Java,Spark,R ),还需要具备一定的数学知识,尤其是统计学。
代码结构
地址:github.com/edvardHua/J…
使用到的 R 包:ggplot2, jiebaR, wordcloud2
代码结构:
├── data
│ ├── position-\ 1:63 拉勾网的原始数据,为 json 格式
├── cache
│ ├── position_after_cleaning.csv 预处理后的数据,直接读取既可使用
│ ├── ...
├── corpus
│ ├── collected.dict.utf8 数据挖掘领域相关的语料库
│ ├── ...
├── graphs
│ ├── ...
├── src
│ ├── curl.R 爬虫
│ ├── clean.R 数据清洗
│ ├── func.R 公共函数
│ └── statistics.R 统计结果可视化
│ ├── mining.R 关键字提取和词频统计
└── tests
└── test.R