


在使用数据库的正确姿势(一)中,我给大家介绍了数据库应用的第一个层次——数据库的基本使用,下面我将给大家介绍剩下两个层次,分别是
- 面向对象的数据库思维
- 使用分布式数据库
面向对象的数据库思维
What
你可能会问,什么是面向对象的数据库思维?
我对这个概念的了解,源于MVC框架中的M——Model,记得很多年前,我做过MFC的开发,当时,MFC的出现把界面开发变得非常简单:要完成一个项目,你可以不了解操作系统,不了解数据库,只需要专注你的业务逻辑即可——它解决了程序员的痛点,于是程序员写出来的代码变得“又快又好”。
同时,那也是我做过的第一个使用了数据库,却没有调用任何一行SQL语句的项目,要读写数据库,你只需要操作Model中的对象即可。
那次项目后,我再也没有这样使用过数据库,直到最近学rails才让我回想起来,例如,以下两行代码做的是同一件事情(如果你没有见过这种语法,你可以忽略它给你带来的不适,把焦点放在代码的形式上),可以看到,第一行代码是对sql查询语句进行直接调用,而第二行代码就像是在使用一个对象;不知道你对比这两行代码会有什么感受?
sql.execute("select * from group where id=10;")
@group = Group.find(10)对于我来说,这种操作方式不但唤醒了我曾经学习MFC的经验,同时我也想知道其他编程语言有没有类似的方法,不出意料之外,搜索之后发现几乎所有的编程语言,在数据库方面都有类似的代码库,同时业界也给“面向对象的数据库思维”起了个专有的名字——ORM(Object-relational mappers)
ORM是一个自动将关系型数据库中的数据和程序中的对象互相关联,并可以在二者间交换数据的代码库
这张图可以很形象的对这个概念进行解释,左边的是存储在数据库中的记录,右边是Python的对象,而ORM则是两者之间的桥梁:
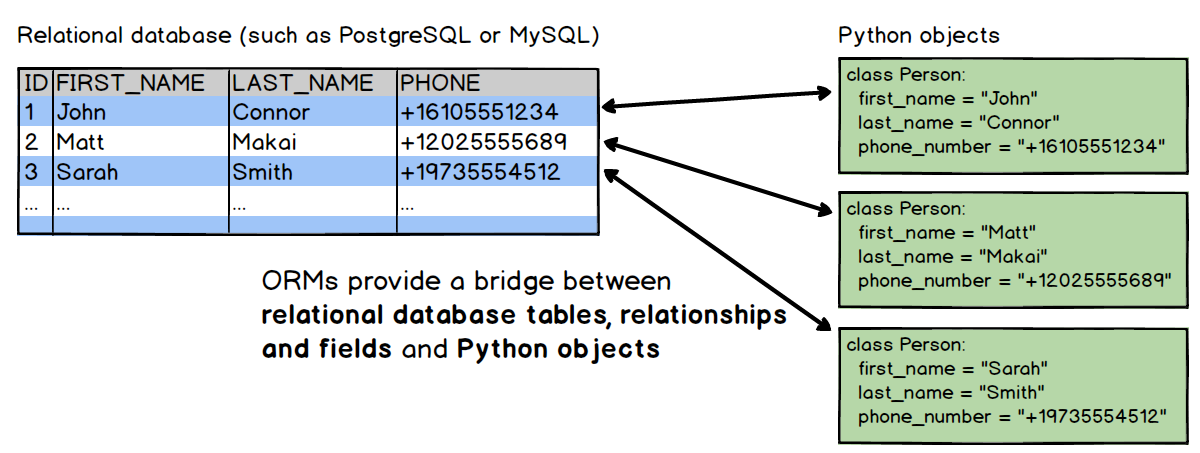
Why
这时你可能又会问了,ORM有什么用呢?难道就只是在敲代码的时候可以少敲几个字符吗?我们为什么要用它呢?
从工程的角度,技术经理为了保证项目能够快速开发,便于维护,一般会说这样的话:让程序员专注于业务逻辑部分,把其他的部分交给框架来完成。
因为把业务逻辑独立于框架范围之外,实现逻辑部分高内聚,及与框架部分的低耦合,可以让项目更为可控。
具体来说,如果你不这样做,你的数据库操作部分的代码可能是这样的,我用伪代码表示如下:
// 第一步、确保与数据库的连接可用,如果不可用,需要重连
if sql.is_connect == False:
sql.connect()
// 第二步、组装sql语句
cmd = "select * from user where userid = %d" % userID
// 第三步、执行sql语句
result = sql.execute(cmd)
// 第四步、解析返回结果
for _r in result:
print _r为了让代码更为简洁,功能更加单一,我们会将这部分代码定义为一个函数(例如findUserByID),可以预见的是,我们每写一个SQL语句,都需要定义一个这样的函数,久而久之,你会发现你已经写了一堆这样的函数,同时这些函数中有很多重复的代码,你想对他们进行抽象,却又发现它们操作的都是不同的数据结构,最终只能无奈的放弃。
如果你只负责开发一个这样的项目,也许你还可以忍,但如果你是一个项目管理者,你有10个项目,每个项目都有一堆这样的数据库代码,你还敢说你的程序有很好的复用性吗?
《程序员修炼之道》里讲了一个破窗理论:
如果一个房子破了一扇窗户而不及时修理好,那么很快这间房子的其他窗户也会被破坏掉。
这个理论适用于项目中的很多方面,例如编码规范、单元测试,以及我们这里所提到的DRY(Don't Repeat Yourself)原则:
如果你的代码中有一处看上去使用了“复制粘贴技术”,那么很快其他地方也会使用“同样的技术”。
所以如果你希望你的团队遵守DRY原则,你可以考虑使用ORM
代码复用能力强,意味着开发效率高,也就意味着你的代码是可控的,例如你可以把数据库的操作都控制在ORM的调用中,以后要对数据库进行扩展,你只需要修改对应的代码即可——这部分代码一般被我们称为Model模块。
除了开发效率和扩展性之外,ORM还有哪些其他的优势呢?让我们考虑下面一种情况,当我需要组装一个SQL语句时,我通常需要从当前的开发语言切换到SQL语言,在切换的过程中,我很可能会突然忘记这条SQL语句怎么写,例如我经常忘记Update的具体语法,于是我便会Google一下,这个动作明显会打断我写代码的思路。这是其一,其二是当你读别人的代码时,到了数据库部分,看到又长又复杂的SQL语句,会不会有一种不顺畅的感觉呢?不管你有没有,反正我是有的。
所以,使用ORM的第二个优势是;它让你的代码保持单一的语法,增强了可读性。
话说回来,和其他框架一样,ORM也有缺点——它会带来性能上的损耗。但我认为在互联网高速发展的今天,在应用没有大到需要你优化它之前,牺牲掉一定的性能来换取工作效率的提升是非常值得的。
所以,你现在知道为什么Rails、Flask之类的框架都使用ORM了吧,即便是这样,很多大流量的项目,仍然会使用这些框架进行开发,例如github网站不就是用的Rails开发的吗,难道他们就不关心性能吗?当然关心,只是因为效率真的是太重要了,因为效率高,所以在流量上来之前,是一定有办法解决掉性能问题的。
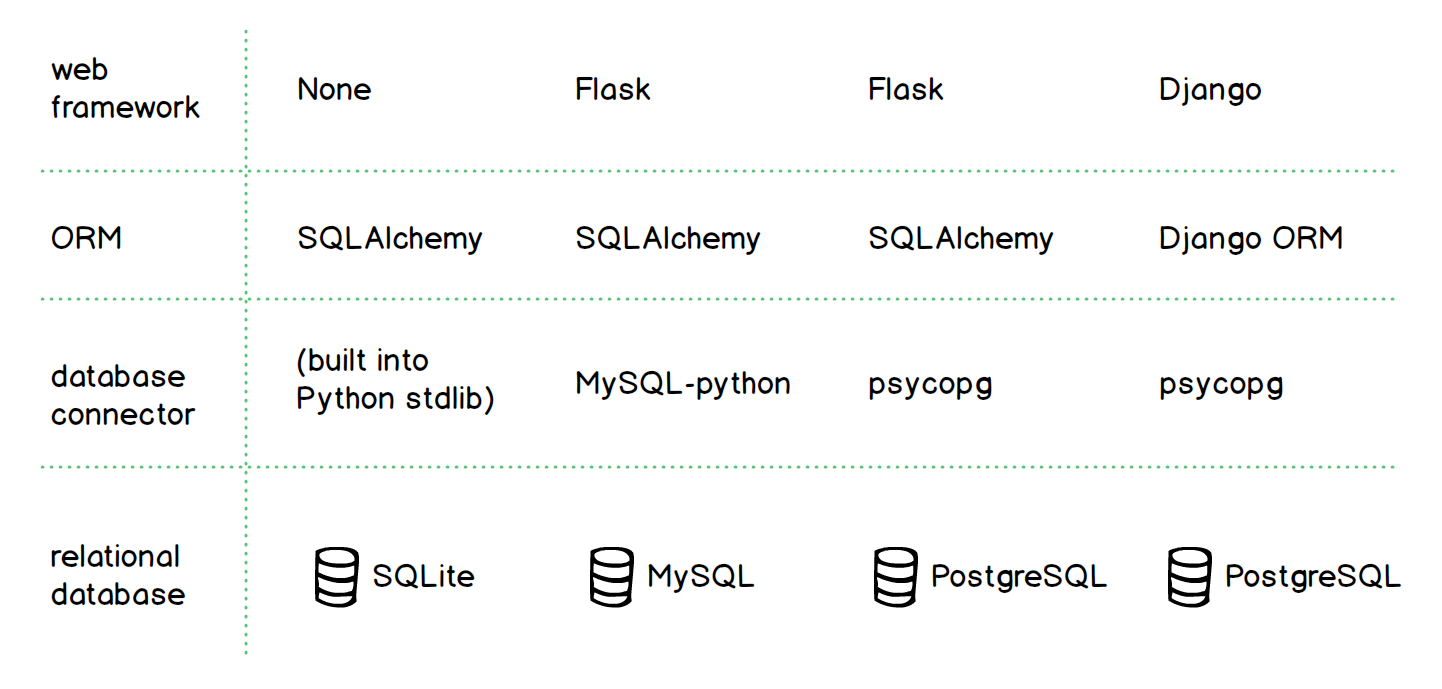
下图是Python框架中,Flask和Django所使用的ORM,可以看到,SQLAlchemy和MySQL-python就是我们之前使用过的代码库。
关于SQLAlchemy,它还有以下几个特点
- 可以自动同步model和元数据,当你在model中增加了一个字段,会自动反应在数据表的元数据中,不过需要借助Alembic插件来完成。
- 与web框架无缝结合:对于每个web请求,会产生一个数据库连接,每个请求被封装到一个transaction中,其中的错误机制也非常完善,可以让你的项目更为健壮
- Eager loading:这个特性会将多个查询语句合并成一条,从而优化性能。例如下面的代码会产生1+n条查询语句,1代表对item表查询1次,n代表循环中对product表的查询次数,这会造成大量的查询而影响性能
for item in order.items: print(item.product.name, item.quantity)session.query(Order).options(joinedload_all('items.product')).get(order_id) - 提供钩子,用户可以重载库中的方法,进而做到定制化开发
- 默认的id字段:对于新创建的表,会默认分配id字段,对于已存在的表,可以使用sqlacodegen工具,将旧表倒入到新表
- 完善的文章:一般开源项目最大的缺点是文档不完善,而该项目的文档介绍了从入门到精通的各个方面。
How
下面我们来看一下ORM的CRUD
-
Create
这里是新增一条记录的部分代码meta, engine = get_meta() session = get_session(engine) User = get_table("user", meta, engine) try: row = User(name="Jerry", age=18) session.add(row) for res in session.query(User).all(): print "add success: name(%s), age(%d)" % (res.name, res.age) session.commit() except Exception as e: session.rollback() finally: session.close()其中,
session代表一个数据库连接,它也是SQLAlchemy中非常重要的概念,对于今后要使用该库的同学,建议阅读一下官方文档get_table("user", meta, engine)表示在指定的数据库中获得一张名为user的数据表。session.add(row)表示增加一行数据,而session.rollback和session.commit分别表示事务的回滚和提交 -
Read
接着我们来看Read的代码query = session.query(User).filter(User.name == 'Jerry') for _row in query.all(): print "query success: name(%s), age(%d)" % (res.name, res.age)query功能非常强大,其中filter相当于SQL语句中的where,更多的条件查询示例可以参考这个链接 -
Update
try: row = session.query(User).filter(User.name == 'Jerry').first() row.age = 19 session.commit() except Exception as e: session.rollback() finally: row = session.query(User).filter(User.name == 'Jerry').first() print "update success: name(%s), age(%d)" %(row.name, row.age)update的写法更为自然,更新操作就是赋值操作,赋值后,接着调用
commit()才会写到数据库中 -
Delete
query = session.query(User).filter(User.name=='Jerry') query.delete() session.commit() query = session.query(User).filter(User.name=='Jerry') print "delete success: %s" % query.all()删除操作也相当简单,操作完毕后,所有
name=='Jerry'的记录将被清空,在这里透露一个小秘密,一般互联网是很少删数据的,即便用户主动删除,可能也只是在记录中做一个“已删除”标记,原因在于:1)删除数据影响性能;2)相对于用户数据来说,硬盘更为廉价
运行后的输出如下:
$ python object_relational_crud.py
add success: name(Jerry), age(18)
query success: name(Jerry), age(18)
update success: name(Jerry), age(19)
delete success: []以上便是ORM的基本使用,其他更多高级用法,比如联表查询、用户自定义查询等,还需要你自己去探索。
分布式数据库应用
最后我将给大家介绍一下数据库使用的第三个层次,使用分布式数据库,那么我们什么时候需要使用分布式数据库呢?如何把数据库调整为分布式呢?且如果调整了分布式之后,我们的程序需要如何修改呢?
其实这几个问题都很简单,当我们的数据量大到一定程度,或者预估我们的产品将来会有千万级别的用户量,那么我们就需要使用分布式数据库,也就是我们常说的对数据库进行分表分库,对于MySQL来说,一张表的极限大概在百万级,所以就很容易预估出上亿级的数据量,只用分100张表即可满足需求。
如果不是在设计过程中就把分表的问题考虑好了,那么我们在分表之后还需要做数据的迁移工作,所以为了减少DBA的负担,最好在设计之初就考虑好:哪些业务需要分表,哪些不需要。
前面两个问题解决之后,我们的程序需要做怎样的调整呢?
一方面:为了保证数据的唯一性,我们需要将同一个用户的数据存储在同一张表中,此时便需要在访问具体的数据之前,先对数据的key进行hash取模操作,假设我们分100张表,hash函数为crc32,则我们可以通过这个公式来计算用户的数据具体存储在哪张表中:
index = crc32(key) % 100另一方面,我们还需要一个动态获取表的方法,还记得刚才提到的get_table函数吗?不记得也没关系,下面我们来看一下这个函数
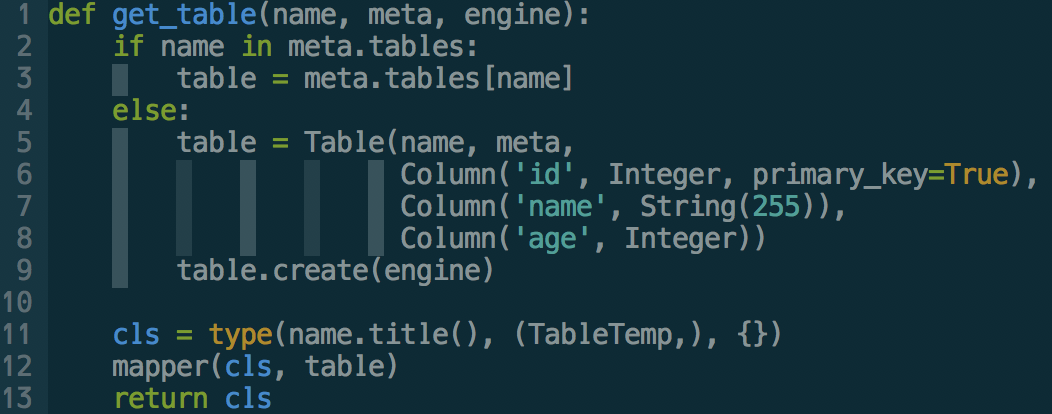
这个函数的功能是,返回一个表名为name的表对象,name为上一步算出来的表名;其次,如果这个表在数据库中不存在,会先创建这张表。
总结上面两个步骤,要让程序能适应于分布式数据库,对于ORM而言,需要先计算数据对应的表名,然后动态获取表对象
所以,使用了ORM之后,切换到分布式数据库,对代码的改动是非常小的。
以上便是分表分库具体的操作思路,你也许会觉得分布式数据库过于简单。实际上并非如此,分布式最难的地方不在这里,而在于ACID,由于篇幅原因,就不在这里展开了,读者有兴趣可以继续深入研究。
下面我们来总结一下,今天我给大家介绍了数据库使用的三个方面,分别是:
- 数据库的基本使用
- 利用面向对象的思维使用数据库
- 在项目中应用分布式数据库
上面演示的代码可以从github下载,大家可以亲自动手体验一下。
参考资料:
pajhome.org.uk/blog/10_rea…
www.fullstackpython.com/object-rela…
github.com/crazyguitar…
