

一、聚类
聚类是一种无监督学习,根据样本的内在相似性/距离,将大量未知标记的样本集划分为多个类别,使得同一个类别内的样本相似度较大(距离较小),而不同类别间的样本相似度较小(距离较大)。
划分聚类包含K-Means、K-Means++、Mini Bacth K-Means等。
二、相似性/距离的度量
既然聚类是根据样本之间的内在相似性/距离进行分类的,那相似性/距离的度量有哪些呢?一般来说,相似性越小,距离则越大,二者成反比关系。对于两个样本X,Y,描述它们之间的相似性/距离可有以下几种:
1、闵可夫斯基距离
闵可夫斯基Minkowski距离公式为 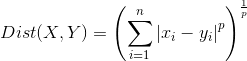 。
。
当 p = 2 时,即为欧氏距离:两个样本点的直线距离;
当 p = 1 时,即为曼哈顿距离:两个样本点的坐标轴距离;
当 p → ∞ 时,即为切比雪夫距离:两个样本点在各个坐标轴上相差距离的最大距离。
2、杰卡德相似系数
杰卡德相似系数为 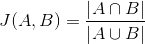 ,即两个样本的特征集合A和B的交集元素在A和B的并集中所占的比例。杰卡德相似系数越大,两个样本的相似性越大。
,即两个样本的特征集合A和B的交集元素在A和B的并集中所占的比例。杰卡德相似系数越大,两个样本的相似性越大。
3、余弦相似度
余弦相似度表示为 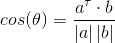 , 其中 a、b为两个样本向量。
, 其中 a、b为两个样本向量。
余弦相似度可看作两个样本在坐标系中的向量表示a和b之间的夹角的余弦值,当夹角为0°时,余弦相似度为1;当夹角为90°时,余弦相似度为0;当夹角为180°时,余弦相似度为-1;
4、皮尔逊相关系数
皮尔逊相关系数的表示为
 。将样本X、Y的特征向量分别看作随机向量,可以得到关于X、Y的均值和方差。
。将样本X、Y的特征向量分别看作随机向量,可以得到关于X、Y的均值和方差。
当皮尔逊相关系数等于-1或1时,X和Y线性相关;等于0时,X和Y两个样本不相关。
从公式的角度看,余弦相似度可以看作 去均值化后的随机向量间的相关系数:
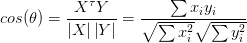
三、K-Means算法
K-Means算法,也成为K-均值算法。算法的基本思路为:
a. 任意选择k个点作为k个类别中心的初始位置
b. 对于每个样本点,根据其对k个类别中心的距离,将该样本点标记为距离某个类别中心最近的那个类别。
c. 对于每个类别中心,将其位置更变为隶属该类别的所有样本点的坐标均值。
d.重复b,c两步,直到类别中心的变化小于某个阈值或者迭代次数达到某个阈值。
1、 K-Means算法缺陷
a. K-Means算法将同一个类别中的所有点作为新的质心,当类别集合中含有异常点时,将导致均值偏离严重。为了减少质心的偏移严重,可改用类别集合中的中位数作为质心。这种聚类方式也叫做K-Mediods聚类或K中值聚类。
b. K-Means算法对初次选取的类别中心敏感的:当k个类别中心的初值太相近时,聚类的效果往往不是很好,容易收敛到局部最优解。
c. K-Means算法需要预先设定类别的数量K,K的选择对聚类的结果起到绝对的作用。
d. K-Means不适合于发现非凸形状的集合或者大小差别很大的集合。
2、轮廓系数
轮廓系数(Silhouette Coefficient),是聚类效果好坏的一种评价方式。
计算步骤为:
a. 计算样本 i 到 同类别中的其他样本的平均距离,记作 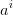 。将 称为样本 i 的集合/簇内不相似度。 越小,说明样本 i 越属于它的类别集合。
。将 称为样本 i 的集合/簇内不相似度。 越小,说明样本 i 越属于它的类别集合。
b. 计算样本 i 到其他的某类别集合 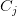 的所有样本的平均距离
的所有样本的平均距离 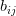 ,
将其称为 样本 i 与 类别集合 的 不相似度。定义样本 i 的类别集合/簇间不相似度为
,
将其称为 样本 i 与 类别集合 的 不相似度。定义样本 i 的类别集合/簇间不相似度为 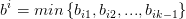 。 越大,说明样本 i 越不属于其他类别集合/簇。
。 越大,说明样本 i 越不属于其他类别集合/簇。
c. 对于样本 i , 其轮廓系数为 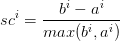 。
。
当 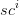 小于0,说明样本
i 与其所在的类别集合的平均距离大于最近的其他簇,表示聚类效果不好;
小于0,说明样本
i 与其所在的类别集合的平均距离大于最近的其他簇,表示聚类效果不好;
当 趋近1时,说明聚类效果比较好;
当 等于0时,说明样本 i 在 两个簇的边界上。
d. 所有样本的轮廓系数的均值称为该聚类结果的轮廓系数,即该聚类结果的一个评价标准。
四、K-Means++算法
因为K-Means算法对初次选取的类别中心敏感,不同的随机种子点得到的聚类结果会有不同。K-Means++算法便是在K-Means的基础上解决了这个问题,并不是一开始就把所有初始点找到,而是一个个地找初始点。
K-Means++的算法思想:
a. 随机挑选一个点作为第一个聚类中心
b. 对于每个样本点,计算与其距离最近的聚类中心的距离 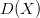 。将所有样本点的 求和,可得到
。将所有样本点的 求和,可得到 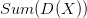 。
。
c. 先取一个能落在Sum(D(x))中的随机值Random,然后用Random -= D(x),直到其<=0,此时的x就是下一个“种子点”,即下一个初始的聚类中心。这种方法也可以看作 以正比与D(x)的概率随机选择一个x作为下一个初始的聚类中心。原则上:D(x)较大的点,被选取作为聚类中心的概率较大
d. 重复b、c两个步骤,直到 k 个聚类中心找到为止。
e. 使用这 k 个初始的聚类中心进行K-Means算法。
五、Mini Bacth K-Means算法
Mini Bacth K-Means算法:使用分批处理(Mini Bacth)的方法对数据点之间的距离进行计算。
当样本点较多时,直接使用K-Means算法进行聚类的话,效率会比较慢,每一轮都有遍历计算所有的样本点到各个聚类中心的距离。
Mini Bacth的好处在于:不必使用所有的样本点进行距离计算、而是从不同类别样本集合中抽取一部分样本来代表各自类别进行计算到各个聚类中心的距离。由于计算样本量的减少,相应的运行时间也会减少,但会带来准确度的降低。
六、sklearn代码示例:
使用sklearn随机生成100000个样本点,分别使用K-Means、K-Means++、Mini Batch K-Means进行聚类。
from sklearn.datasets.samples_generator import make_blobs
import timecenters = [[1, 0], [-1, 0], [0, -1],[0,1],[0,0],[-0.7, -0.7], [-0.7, 0.7], [0.7, -0.7],[0.7,0.7]]
X, labels_true = make_blobs(n_samples=100000, centers=centers, cluster_std=0.18,
random_state=0)import matplotlib.pyplot as plt
fig, axes = plt.subplots(2, 2)axes[0,0].scatter(X[:, 0], X[:, 1],c=labels_true)
axes[0,0].set_xlabel('label_true')<matplotlib.text.Text at 0x8f4b240>
from sklearn.cluster import KMeans
from sklearn.cluster import MiniBatchKMeanst0 = time.time()
y_pred1 = KMeans(init = 'random',n_clusters=9, random_state=8,n_init=1).fit_predict(X)
t_k_means = time.time() - t0axes[0,1].scatter(X[:, 0], X[:, 1], c=y_pred1)
axes[0,1].set_xlabel('k-means time :%f'%t_k_means)<matplotlib.text.Text at 0x8fd6dd8>
y_pred2 = KMeans(init = 'k-means++',n_clusters=9, random_state=9,n_init=1).fit_predict(X)axes[1,0].scatter(X[:, 0], X[:, 1], c=y_pred2)
axes[1,0].set_xlabel('k-means++')<matplotlib.text.Text at 0x908c9e8>
t0 = time.time()
y_pred3 = MiniBatchKMeans(init='random', n_clusters=9, batch_size=900,
n_init=1, max_no_improvement=10).fit_predict(X)
t_batch_means = time.time() - t0axes[1,1].scatter(X[:, 0], X[:, 1], c=y_pred3)
axes[1,1].set_xlabel('batch-k-means time:%f'%t_batch_means)<matplotlib.text.Text at 0x9199588>
plt.subplots_adjust(left=0.2, bottom=0.2, right=0.8, top=0.8,hspace=0.9, wspace=0.9)
plt.show()
