

说来惭愧,距离蟹棒在简书发表第一篇文章已经时隔两月,蟹棒一直没有要写什么博客的题材,也再一次的让蟹棒为自己肚子里丁点的墨水发愁,蟹棒的写作与思考功力还需修炼,勤奋才能修得正果 !
致谢
蟹棒在简书的第一篇文章是和简友们分享如何搭建自己的个人网站,半个小时撸出自己的个人博客,至此该文章已经收获简友们 2868 次浏览,169 次喜欢,102 个评论,32 个粉丝,蟹棒受宠若惊,也再次感谢简友们的支持与鼓励,谢谢你们给蟹棒的信心和决心,谢谢!
关于
为什么会突然想到写一个这样的博客呢?
之前蟹棒打算独立完成一个音乐播放类的APP,苦于一直没有音乐资源,自己又没有强大的后台数据库来支持,所以就百度谷歌各种音乐平台的API,发现这些API要不就是无法访问,要不就是资源不全,根本无法完成一个完整的流程,所以蟹棒才萌生要自己写一个API的想法,资源我们从网易云音乐的官网爬数据就可以了,当然这种数据源是不合法的,所以简友们可自己用作私人开发,不可以拿来商用哦

因为这次的爬虫是用NodeJS写的,所以希望看这篇文章的简友们要对NodeJS有一定了解,当然你可以在了解完蟹棒的逻辑之后使用其他语言完成
坐稳了没有,蟹棒开车了

哈哈,话不多说,言归正传。
我们先来看看 网易云音乐的主页
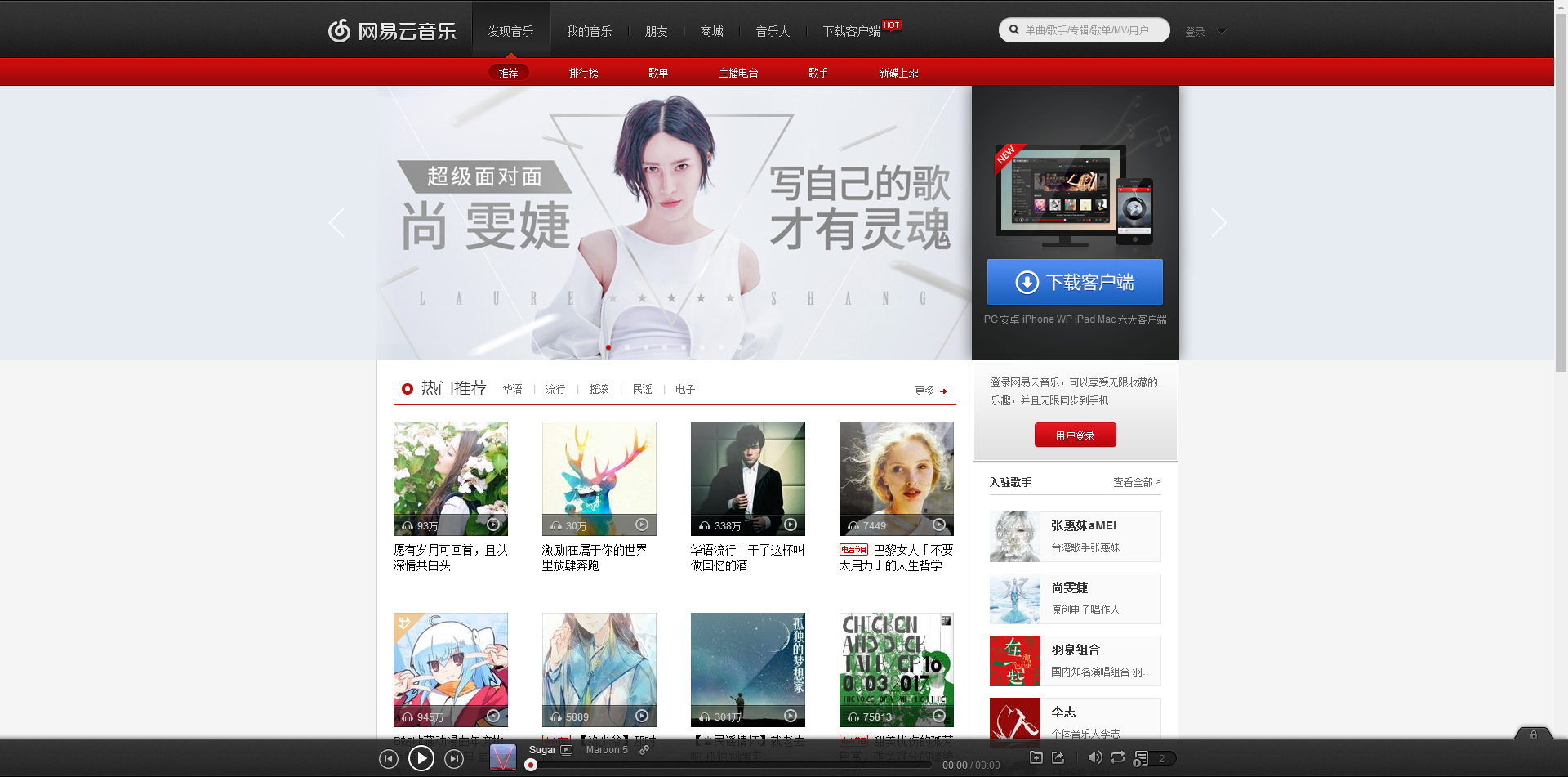
蟹棒的目标先是拿下默认首页里热门推荐的八个歌单,首先我们要新建一个NodeJs项目
// 创建文件夹
mkdir <your project name>
// 初始化NodeJs
npm init
// 完成 npm init 配置选项添加 package.json// 安装需要用到的模块
npm install --save express superagent cheerioexpress 我们用来完成API的路由访问配置,superagent 用来完成对网易云音乐网站页面的访问,cheerio 用来处理数据访问返回的HTML数据,三个模块的 api 大家可以到他们各自的官网扫荡一番
想要爬取网页上的数据,就必须对网页上的HTML结构有一定的了解,而蟹棒研究网易云的主页结构之后,发现页面结构比想象的要复杂一点,不过你只要问问的抓住蟹棒的车把,蟹棒开的很稳
首先访问 网易云音乐的主页,打开调试窗口(F12),点击 Elements 选项,这时候你就可以看到主页的HTML主要结构如下
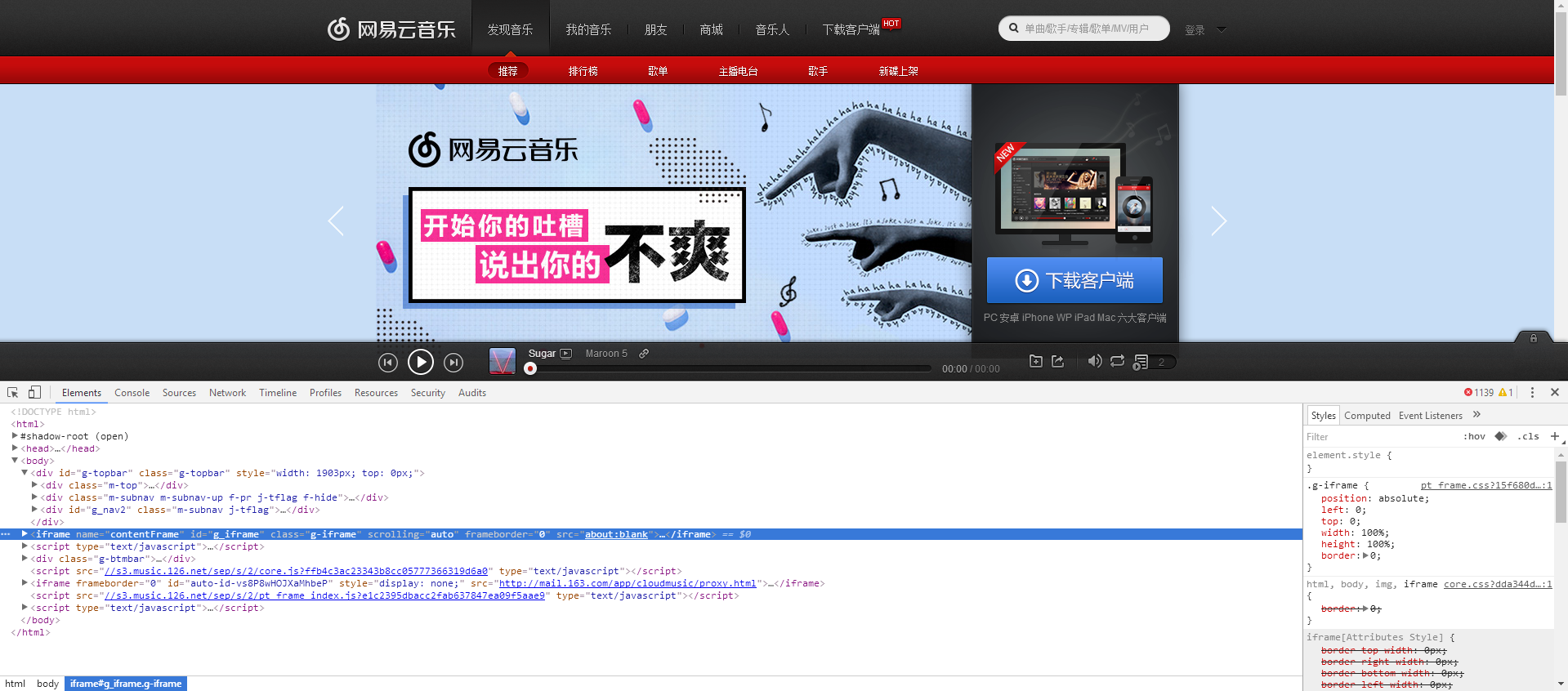
使用快捷键 Ctrl + shift + c 进入 select 模式,这时候我们鼠标移动到页面上任何一个元素上,Element 就会自动定位到元素的代码位置上,按照方法,我们定位第一个歌单的位置
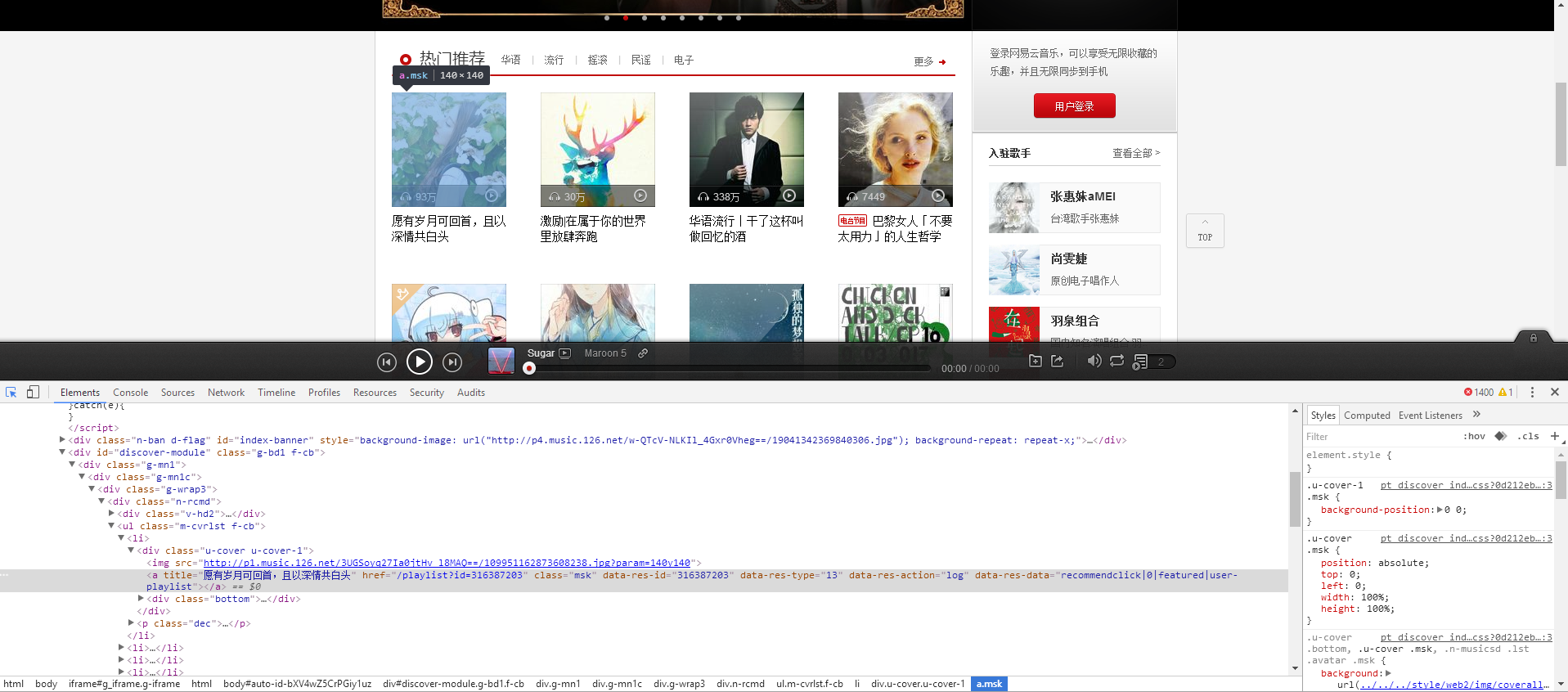
<a title="愿有岁月可回首,且以深情共白头" href="/playlist?id=316387203" class="msk" data-res-id="316387203" data-res-type="13" data-res-action="log" data-res-data="recommendclick|0|featured|user-playlist"></a>不难发现,我们需要的资源这里都可以看到,title 显示的歌单的名称,href 表示它所指向的位置,data-res-id 是歌单id,data-res-type = 13 这个属性表明类型,13 代表什么类型我们不得而知,在这里我们并不关心,data-res-action 与 data-res-data 我们都不知道具体用途,所以我们只拿自己需要的资源
// 定义我们的歌单对象结构
{
id: '歌单ID',
title: '歌单名称',
href: '歌单指向',
type: '类型',
cover: '歌单封面图片'
}我们再来分析怎么从HTML代码中获得想要的八个歌单的信息,从代码中我们观察到在 a 链接外层 存在 一个 li 标签,而 li 的外层正是我们期望见到的 ul 列表标签,我们将 Element 聚焦到 ul 上
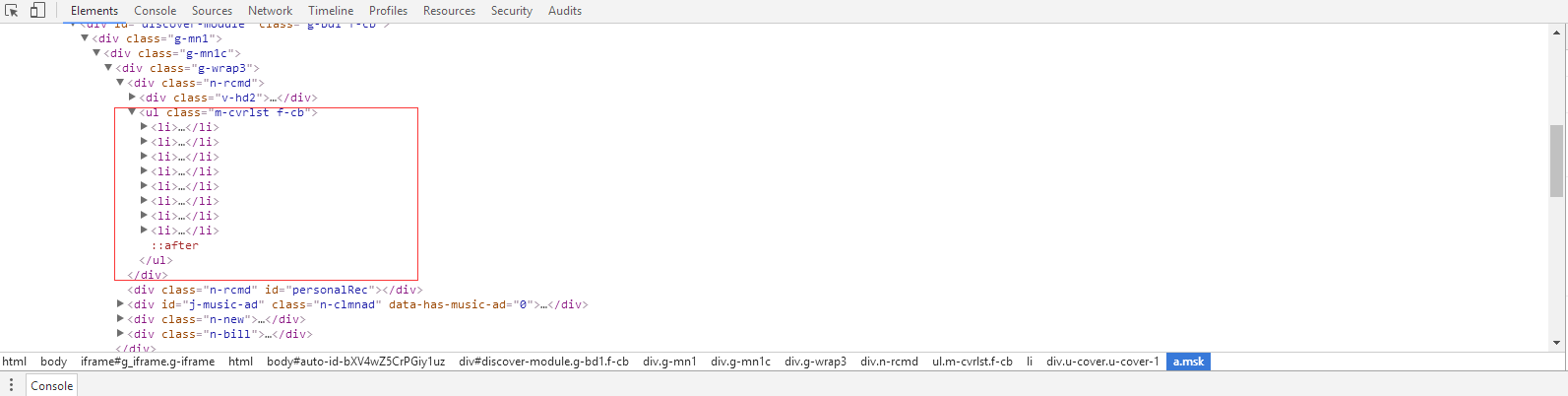
在 ul 中存在八个 li ,感兴趣的简友可以依次打开看一下代码,正是我们上面决定拿到的八个歌单信息,研究完歌单信息在代码中的详细位置,我们来看一下如何在HTML代码中获得这个ul列表,ul 标签存在一个名为 m-cvrlst 的 class , 我们可以点击 Console 选项,输入如下代码
document.getElementsByClassName('m-cvrlst');
结果并不如蟹棒所料,在确定 class 名称没有输错的情况下,我们得到一个空数组,很明显我们在页面中观察到确实存在 class 名为 m-cvrlst 的 ul 元素 ,可以代码并没有获得期望结果,细心的简友此刻已经回去研究代码结构,还没下车的简友们跟着蟹棒司机一起回去研究研究
当我们聚焦到 ul 元素上时,可以在调试窗口最下面看到此元素对应的层级结构,不难发现,在 ul 的父级元素列表中,存在一个 id 为 g_iframe 的 iframe 元素
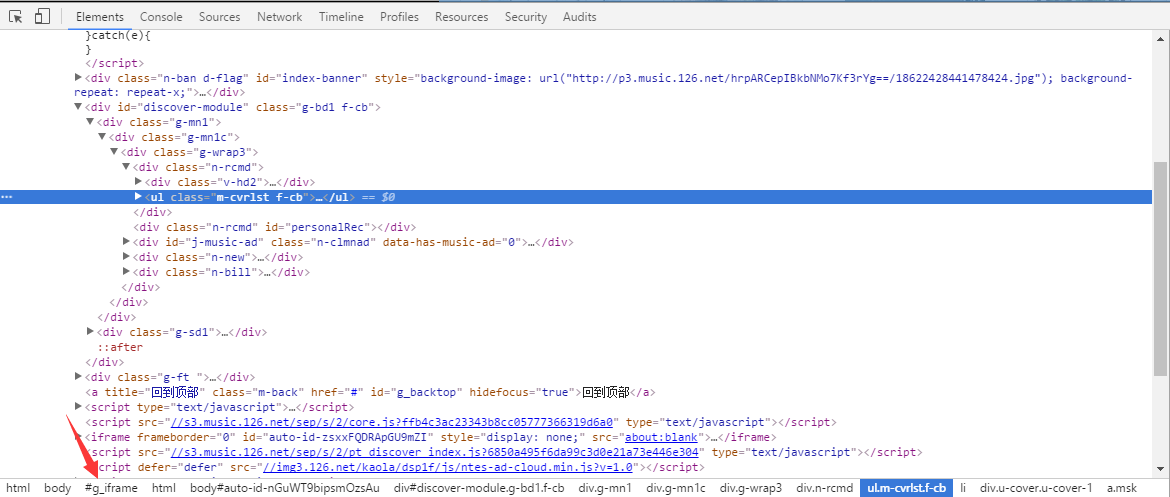
此刻蟹棒车上的年轻司机们都露出了不明觉厉的笑容,我们点击红色箭头指向的位置定位到该 iframe 元素
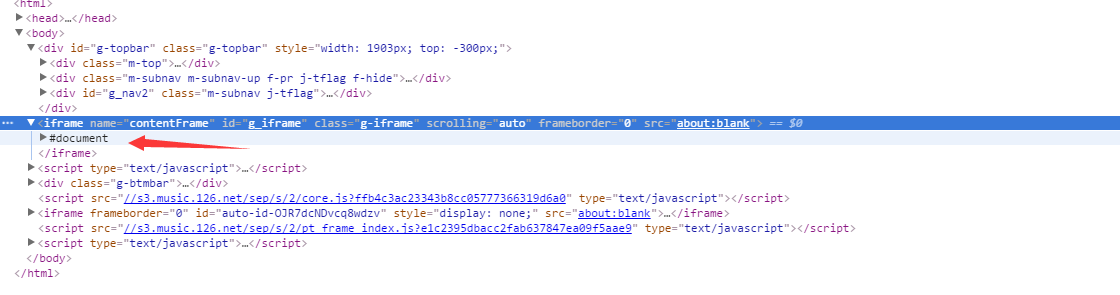
我们会发现 iframe 中也同样存在一个 document 对象,说明此 iframe 加载了一个另外的 url ,了解了原来如此之后,我们继续在 Console 面板中执行如下代码
g_iframe.contentDocument.getElementsByClassName('m-cvrlst');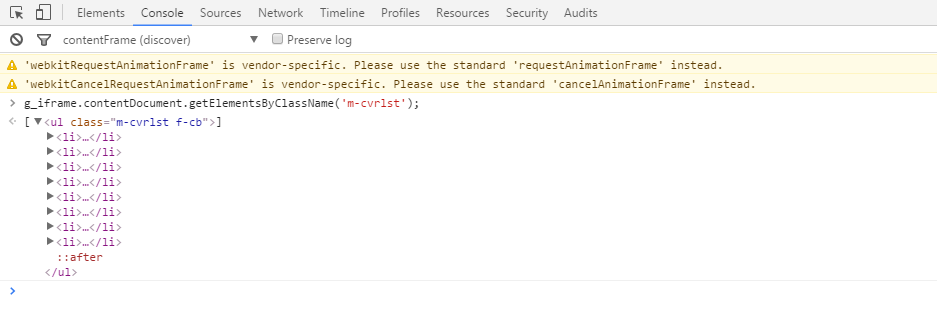
哈哈,这才是我们需要看到的嘛,年轻司机们松了一口气的同时,又在考虑另外一个问题,如何通过代码获得 iframe 里面的 HTML 结构,iframe 加载网页是在当前网页从服务器返回之后再去加载,也就是说 iframe 内嵌网页的加载要晚于当前请求的网页,从上面iframe 的截图我们看到 iframe 的 src 属性指向 about:blank,也就是说 iframe 内部的网页跳转是通过 Js 代码控制,所以 iframe 内嵌网页的加载速度只会比预料的速度更晚,所以我们直接请求 music.163.com 的时候,iframe中的内容还没有加载
光说不练假把式,写几句代码验证一下,该动动我们刚开始建立的 NodeJs 项目了
新建 test.js 文件,写入如下代码
// 加载 express 模块
var app = require('express')();
// 加载 superagent 模块
var request = require('superagent');
// 加载 cheerio 模块
var cheerio = require('cheerio');
// 指定访问路由
app.get('/', function(req, res){
// 请求网易云音乐主页
request.get('http://music.163.com')
.end(function(err, _response){
if (!err) {
// 如果没有发生错误, 获得的html就是网页返回的HTML结构
var html = _response.text;
// cheeio 初始化完成之后与 jQuery 用法相差无几
var $ = cheerio.load(html);
// 打印 iframe
console.log( 'iframe内部结构:' + $('#g_iframe').html() );
res.send('Hello');
} else {
return next(err);
}
});
});
// 监听3000 端口
app.listen(3000, function(){
console.log('Server start!');
}); // cmd 执行如下命令,执行完毕不要关闭控制台窗口
cd <your project name>
node test
// 如果成功输出 "Server start ! ",证明操作正确,其他情况均为错误情况// 浏览器访问,观察控制台输出
localhost:3000
不好意思,车开的快了点,大家稳住,看不懂代码的年轻司机先不需要懂这段代码的意思,只要按照步骤验证我们刚刚的猜想,也就我们在请求网易云音乐主页的时候 iframe 并没有加载,所以我们是没有办法获得iframe里面的内容的,当前打印的iframe内部 dom 结构为空,关于以上代码,蟹棒到了具体写API的时候再具体解释

好了,系好安全带,我们要如何获得 iframe 中的内容呢,我们必须先要摸清楚iframe在页面加载之后去加载了什么网页 url , 当然这个我们不需要去研究源码,Chrome 调试窗口给了我们很方便的工具,打开调试窗口(F12),点击 Sources 选项
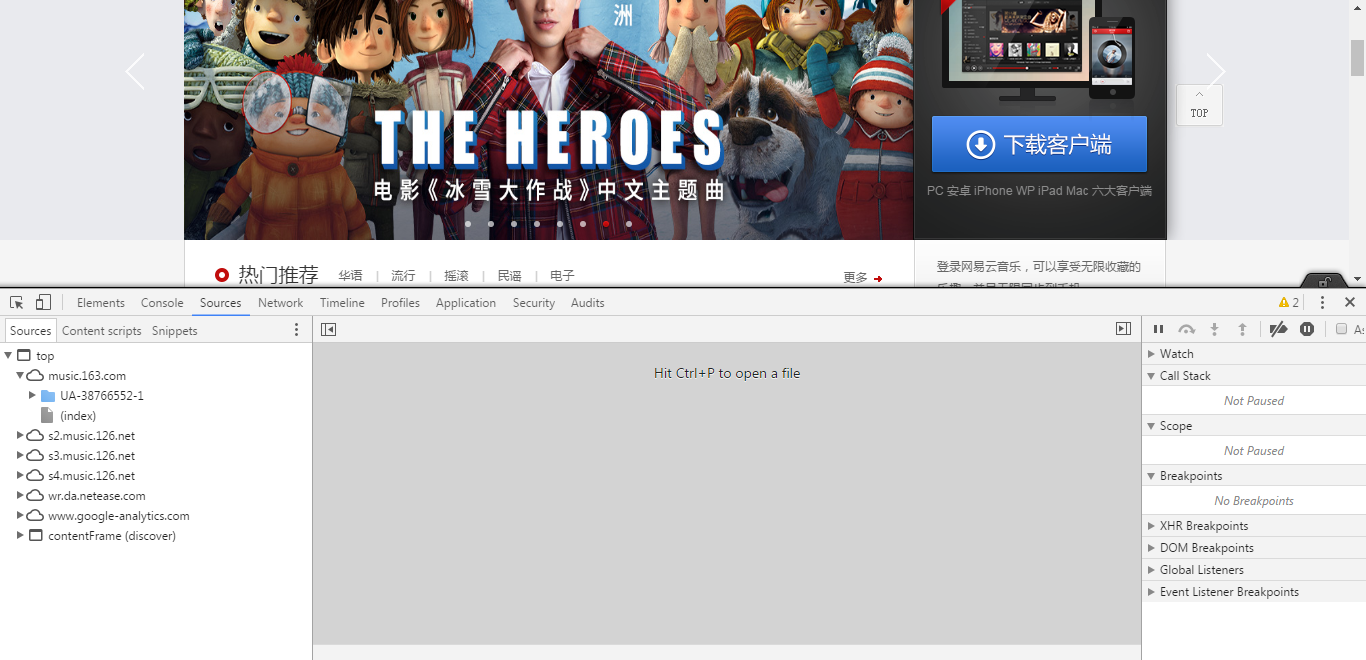
这里会列出当前网页加载的所有资源,我们可以看到在列表的最后一项,存在一个名为 contentFrame 的子节点,点击打开此节点
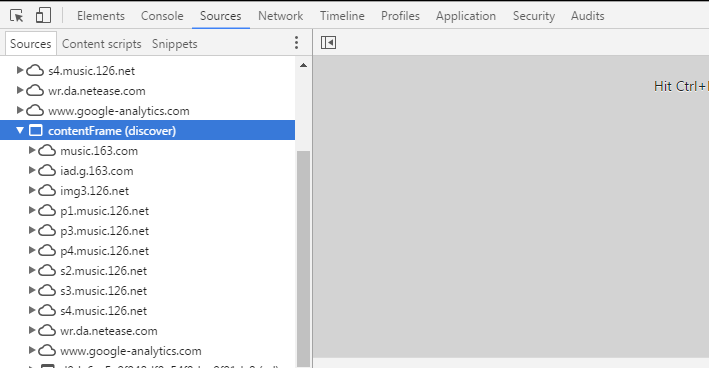
对比上下两张截图,我们发现他们加载的都是同一张页面,但是访问的地址却是不同的,感兴趣的简友可以仔细对比这两张截图中具体加载的内容,现在回到 iframe , 现在我们基本确定,contentFrame 节点中加载的内容正是 iframe 中加载url 指向的网址,我们可以验证一下,打开contentFrame 节点的第一个子节点,在这个节点中存在一个 discover 页面,点击打开
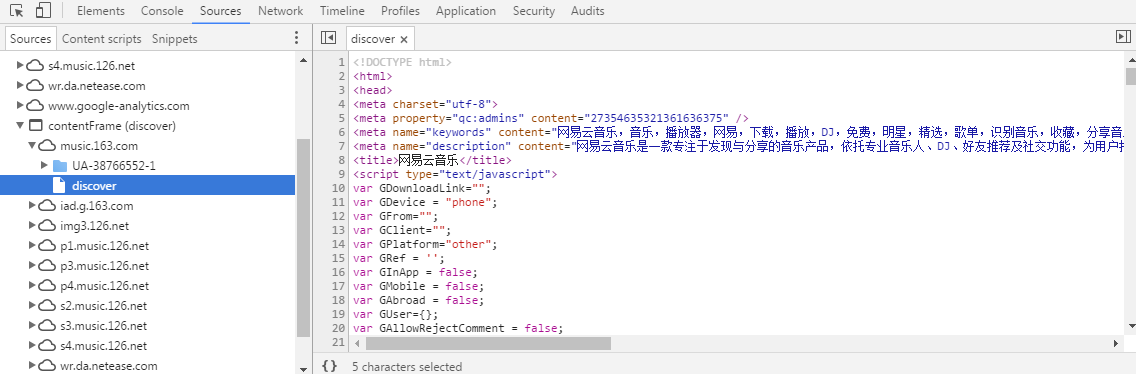
我们看到 discover 页面同样是加载了一个 html 文档,可是这个文档是不是我们需要的文档呢?验证看看,在 discover 中按下快捷键 Ctrl + f , 输入 m-cvrlst , 如果不出意外
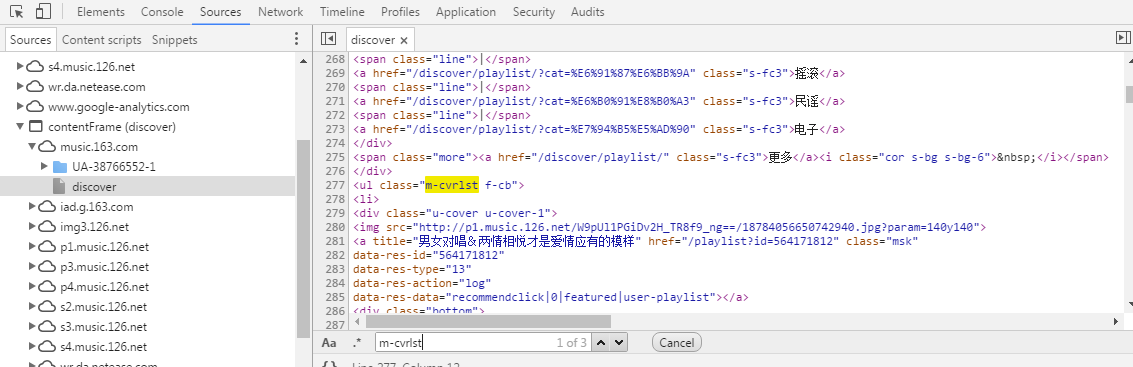
哈哈,这正是我们需要的,怎么知道 discover 页面到底指向哪一个 url 呢,鼠标悬浮到 discover 页面上,就可以看到 music.163.com/discover 的url (因为截图截不到,所以年轻司机们要自己多多观察一下了),Get it !
有了 url ,我们就可以正式写我们的爬虫程序了,在我们的 NodeJs 项目中,新建 index.js
// 初始化 express
var app = require('express')();
/**
* 开启路由
* 第一个参数指定路由地址,当前指向的是 localhost:3000/
* 如果需要其他路由,可以这样定义,比如 需要我们的获取推荐歌单的路由 /recommendLst
* app.get('/recommendLst', function(req, res){});
*/
app.get('/', function(req, res){
// 向请求 localhost:3000/ 的地址返回 Hello World 字符串
res.send('Hello World !');
});
/**
* 开启express服务,监听本机3000端口
* 第二个参数是开启成功后的回调函数
*/
var server = app.listen(3000, function(){
// 如果 express 开启成功,则会执行这个方法
var port = server.address().port;
console.log(`Express app listening at http://localhost:${port}`);
});// 在控制台执行
node index
// 浏览器访问
http://localhost:3000/

恭喜,第一个express Hello world 程序运行成功,具体实现可以参考express官网给出的 Hello world 示例
使用 superagent 访问 discover 页面
到了这里,相信简友对蟹棒的套路已经轻车熟路了,不多说了,上路
我们先用 superagent 访问我们的 localhost:3000 , 如果不出意外,我们获得的正是 localhost:3000/ 返回的 Hello World 字符串
// 初始化 superagent 模块
var request = require('superagent');
app.get('/test', function(req, res){
request.get('http://localhost:3000/')
.end(function(err, _response){
if (!err) {
// 如果获取过程中没有发生错误
var result = '获取到的数据:'+_response.text;
console.log(result);
res.send(result);
} else {
console.log('Get data error !');
}
});
});// 我们在修改服务端代码之后一定要重启服务才会看到效果
node index
// 浏览器访问
http://localhost:3000/test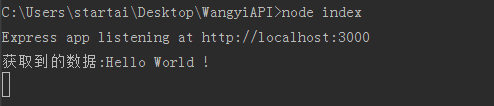

更多有关于 superagent 的 api 在 这里
接下来我们使用 superagent 的 get 函数来访问 discover 页面,我们将开放一个 localhost:3000/recommendLst 的 api 返回推荐列表数据
// express 开放 /recommendLst API
app.get('/recommendLst', function(req, res){
// 使用 superagent 访问 discover 页面
request.get('http://music.163.com/discover')
.end(function(err, _response){
if (!err) {
// 请求成功
var dom = _response.text;
console.log(dom);
res.send('get success');
} else {
console.log('Get data error !');
}
});
});// 重新启动服务
node index
// 浏览器访问
http://localhost:3000/recommendLst如果你的控制台之中打印出如下界面 (截图不完整)
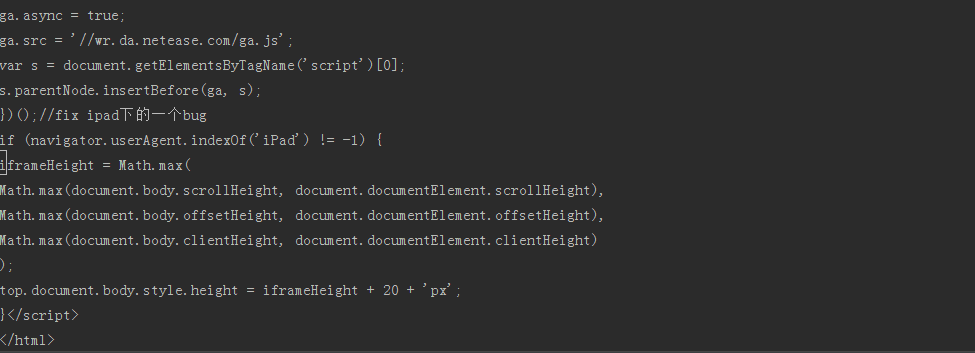
到了这里证明请求 discover 页面成功 !
使用 cheerio 处理返回的 HTML
一脚刹车,蟹棒先休息一会,简友们喘口气喝口水,请站好扶稳,系好安全带,车子将再次启动 .....
先使用 cherrio 来处理一下简单的 html , Look
// 加载 cheerio 模块
var cheerio = require('cheerio');
app.get('/testCheerio', function(req, res){
var $ = cheerio.load('<h1 id="test">这是一段示例文字</h1>');
$('#test').css('color','red');
res.send( $.html() );
});照例
// 重新启动服务
node index
// 浏览器访问
http://localhost:3000/testCheerio运行结果如下

同样,cheerio 的更多api请点击 这里
现在使用 cheerio 来处理 superagent 请求过来的 HTML
// express 开放 /recommendLst API
app.get('/recommendLst', function(req, res){
// 初始化返回对象
var resObj = {
code: 200,
data: []
};
// 使用 superagent 访问 discover 页面
request.get('http://music.163.com/discover')
.end(function(err, _response){
if (!err) {
// 请求成功
var dom = _response.text;
// 使用 cheerio 加载 dom
var $ = cheerio.load(dom);
// 定义我们要返回的数组
var recommendLst = [];
// 获得 .m-cvrlst 的 ul 元素
$('.m-cvrlst').eq(0).find('li').each(function(index, element){
// 获得 a 链接
var cvrLink = $(element).find('.u-cover').find('a');
console.log(cvrLink.html());
// 获得 cover 歌单封面
var cover = $(element).find('.u-cover').find('img').attr('src');
// 组织单个推荐歌单对象结构
var recommendItem = {
id: cvrLink.attr('data-res-id'),
title: cvrLink.attr('title'),
href: 'http://music.163.com' + cvrLink.attr('href'),
type: cvrLink.attr('data-res-type'),
cover: cover
};
// 将单个对象放在数组中
recommendLst.push(recommendItem);
});
// 替换返回对象
resObj.data = recommendLst;
} else {
resObj.code = 404;
console.log('Get data error !');
}
// 响应数据
res.send( resObj );
});
});代码很简单,详细撸完 superagent 和 cheerio 的使用方法的简友们不会被这段代码吓到,至此我们的获取推荐首页的API就已经完成,我们可以看看请求效果,重启服务器,你懂的 !
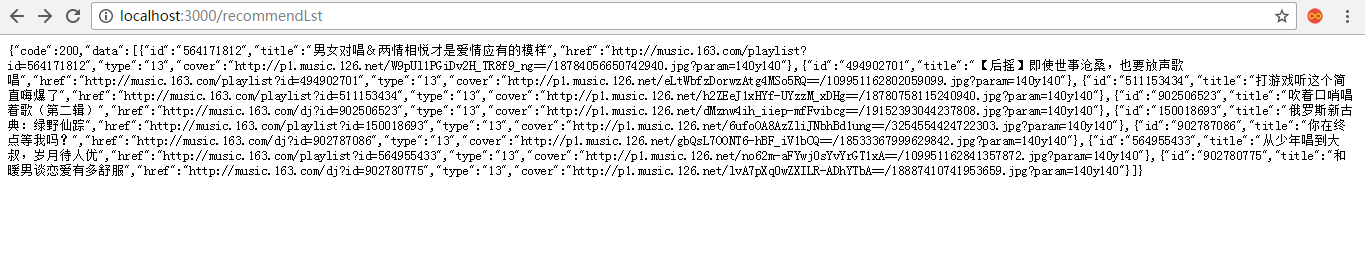
很复杂?不用紧张,蟹棒的车有保险,哈哈,简友们需要 Chrome 扩展程序JSONView (Chrome 应用商店,自备梯子,免费的就用 Lantern,满足简单的需求)
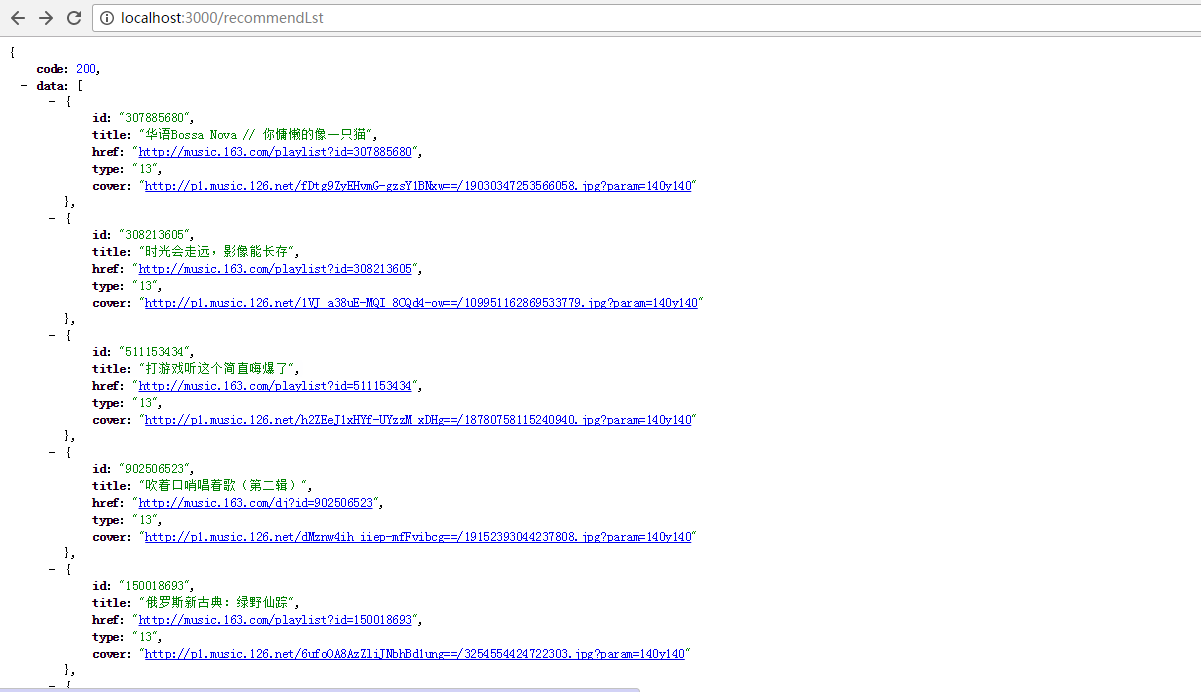
回头看看我们定义过的单个推荐列表的对象结构,这样看是不是很简单明了,我们再来看看访问失败的情况,断掉网络
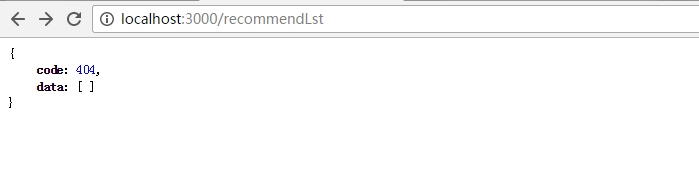
举一反三,根据歌单id获得歌单详细信息
这个就需要我们重新研究dom结构,相信经过上面的过程,简友们对这个已经信心满满了,上车,出发
回到网易云首页,点击任意一个歌单
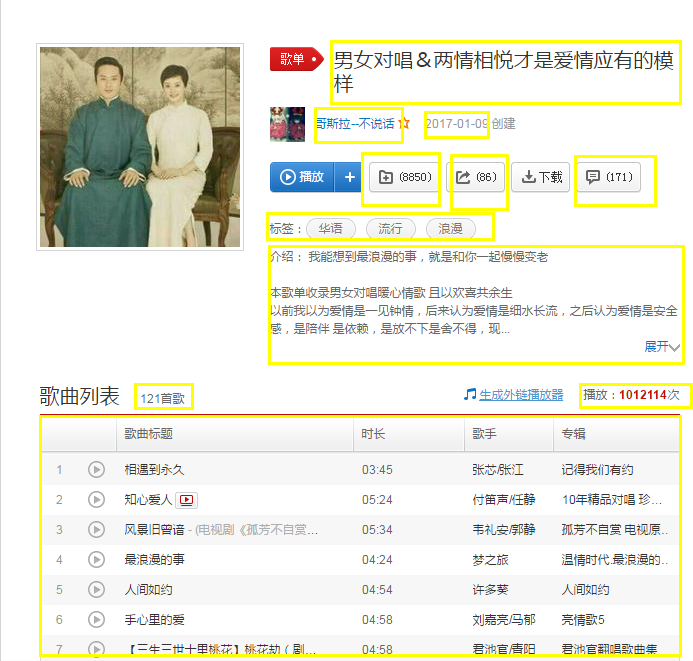
从图中,我们可以分析出,我们需要的资源有上面蟹棒括起来的所有信息,按照这样,我们可以规定一个歌单的详细信息对象结构
{
id: '歌单ID',
title: '歌单名字',
owner: '歌单的拥有人姓名,初级阶段只考虑用户名,不考虑用户详细信息',
create_time: '创建时间',
collection_count: '歌单被收藏数量',
share_count: '歌单被分享数量',
comment_count: '评论数量',
tags: ['标签'],
desc: '歌单描述',
song_count: '歌曲总数量',
play_count: '总播放次数'
}相信简友已经有能力把这些数据一个个扒出来了,我们先来定义API
// 定义根据歌单id获得歌单详细信息的API
app.get('/playlist/:playlistId', function(req, res){
var playlistId = req.params.playlistId;
res.send(playlistId);
});这种API定义方式是 express 的动态参数匹配,/:playlistId 将匹配你输入的动态参数,看看使用方式,不要忘了重启服务器哦

效果很明显,我们将通过这种方式获得需要获取详细信息的歌单ID,具体怎么找元素在哪一个位置,蟹棒就不带着简友们做了,相信简友们看了上面的教程,应该对这个很熟悉了,蟹棒就直接贴源码了,蟹棒友情提醒,注意注释
(Warning....车速正在提升,请站好扶稳,系好安全带.....)
// 定义根据歌单id获得歌单详细信息的API
app.get('/playlist/:playlistId', function(req, res){
// 获得歌单ID
var playlistId = req.params.playlistId;
// 定义返回对象
var resObj = {
code: 200,
data: {}
};
/**
* 使用 superagent 请求
* 在这里我们为什么要请求 http://music.163.com/playlist?id=${playlistId}
* 简友们应该还记得 网易云音乐首页的 iframe
* 应该还记得去打开 调试面板的 Sources 选项卡
* 那么就可以看到在歌单页面 iframe 到底加载了什么 url
*/
request.get(`http://music.163.com/playlist?id=${playlistId}`)
.end(function(err, _response){
if (!err) {
// 定义歌单对象
var playlist = {
id: playlistId
};
// 成功返回 HTML, decodeEntities 指定不把中文字符转为 unicode 字符
// 如果不指定 decodeEntities 为 false , 例如 " 会解析为 "
var $ = cheerio.load(_response.text,{decodeEntities: false});
// 获得歌单 dom
var dom = $('#m-playlist');
// 歌单标题
playlist.title = dom.find('.tit').text();
// 歌单拥有者
playlist.owner = dom.find('.user').find('.name').text();
// 创建时间
playlist.create_time = dom.find('.user').find('.time').text();
// 歌单被收藏数量
playlist.collection_count = dom.find('#content-operation').find('.u-btni-fav').attr('data-count');
// 分享数量
playlist.share_count = dom.find('#content-operation').find('.u-btni-share').attr('data-count');
// 评论数量
playlist.comment_count = dom.find('#content-operation').find('#cnt_comment_count').html();
// 标签
playlist.tags = [];
dom.find('.tags').eq(0).find('.u-tag').each(function(index, element){
playlist.tags.push($(element).text());
});
// 歌单描述
playlist.desc = dom.find('#album-desc-more').html();
// 歌曲总数量
playlist.song_count = dom.find('#playlist-track-count').text();
// 播放总数量
playlist.play_count = dom.find('#play-count').text();
resObj.data = playlist;
} else {
resObj.code = 404 ;
console.log('Get data error!');
}
res.send( resObj );
});
});执行结果(依然是重启服务器,然后浏览器访问)

年轻司机们轻轻摇了摇要昏掉的脑袋冒出一个问题,我们为什么不直接在这个接口中将歌单的所有歌曲也加载进去呢,哈哈,如果简友们认真看过iframe加载成功后的html文件的话,就不会有这个问题了,我们一起看看这一块
打开调试窗口(F12),点击Sources选项卡,点击contentFrame子节点,点击playlist开头的文件,文件结构如下
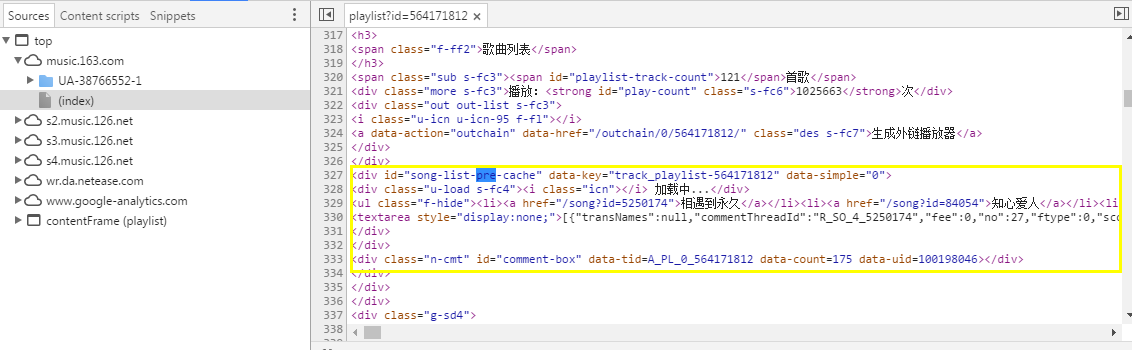
我们能看到在页面已经返回的情况下歌曲的table是没有渲染出来的,在仔细看看页面,刷新的过程中能看到歌曲列表位置出现“加载中..”中的 loading 提示,但是,Look,这是什么

蟹棒把这部分内容Copy出来做了一下 Json解析
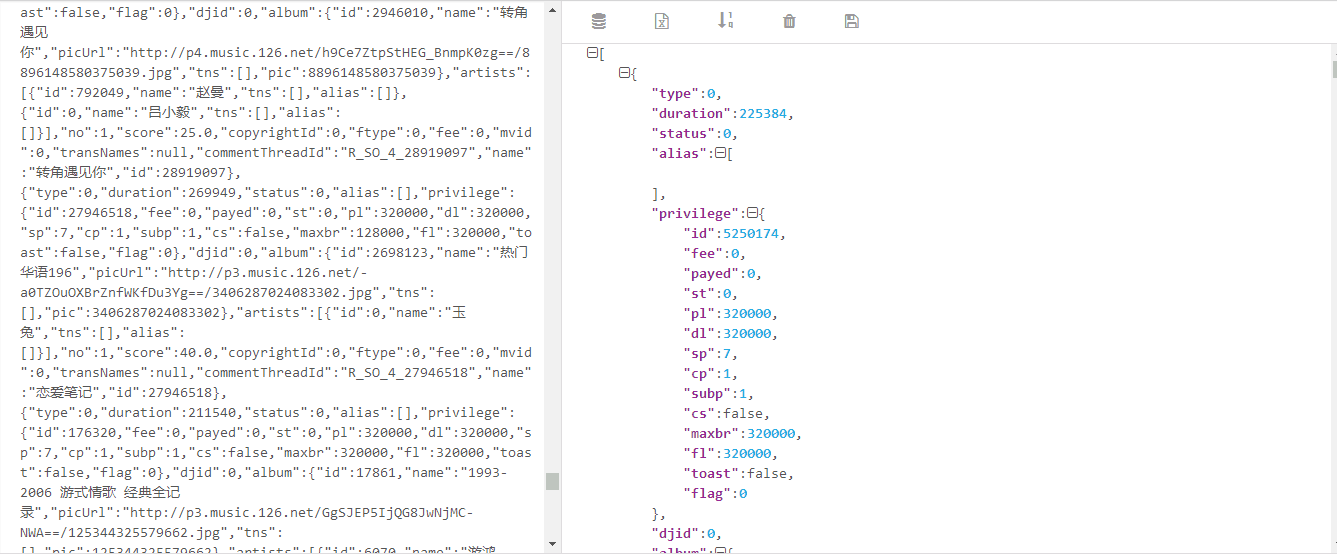
很明显,这正是我们需要的东西,但是这个JSON字符串的长度非常长,如果我们要把它放在请求播放列表详细信息处理的话,会非常耗时,蟹棒大概对该JSON字符串执行了下面几句代码
// 当前操作耗时 1s
var str = JSON.stringify('拷贝过来的字符串');
// 当前操作耗时 1s
console.log(str.length); // 75151
// 当前步骤耗时 2s
var str = JSON.parse(str);再加上我们肯定要对该JSON字符串做相应的逻辑处理,所以速度只会更慢,更好的办法是在播放列表加载完成之后异步加载播放列表中的所有歌曲,而我们要做的仅仅是返回整个JSON字符串,逻辑解析的问题就交给前端Js代码来处理,蟹棒再次贴一段代码
// 定义根据歌单id获得歌单所有歌曲列表的API
app.get('/song_list/:playlistId', function(req, res){
// 获得歌单ID
var playlistId = req.params.playlistId;
// 定义返回对象
var resObj = {
code: 200,
data: []
};
request.get(`http://music.163.com/playlist?id=${playlistId}`)
.end(function(err, _response){
if (!err) {
// 成功返回 HTML
var $ = cheerio.load(_response.text,{decodeEntities: false});
// 获得歌单 dom
var dom = $('#m-playlist');
resObj.data = JSON.parse( dom.find('#song-list-pre-cache').find('textarea').html() );
} else {
resObj.code = 404 ;
console.log('Get data error!');
}
res.send( resObj );
});
});重启服务器,浏览器的访问结果(蟹棒友情提示,如果电脑配置不是很好,请把JSONView扩展程序禁用再浏览网页,否则浏览器可能当机)
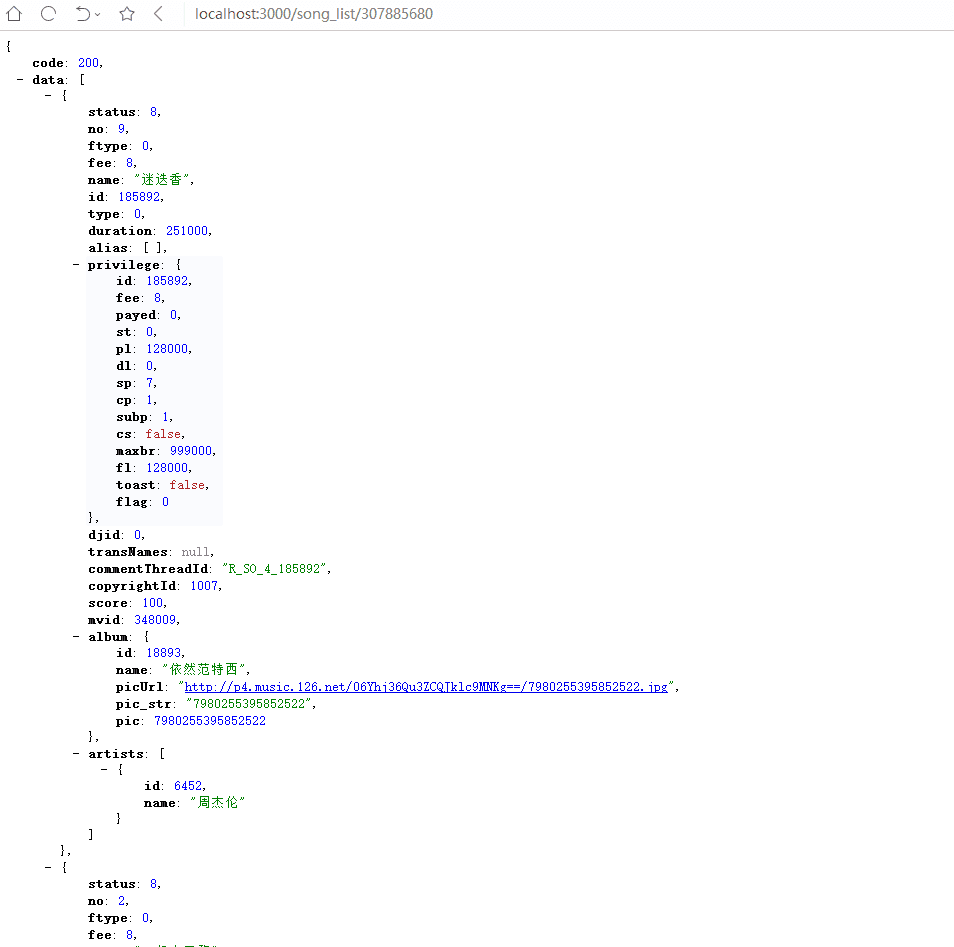
总结
好啦,目的地距离不远,蟹棒的车也开始减速了,简友们能看到这里的,蟹棒感谢你们坐这趟车,也希望蟹棒的文章可以帮到你,我们一起来回顾一下所编写成功的API
- 访问推荐歌单API
http://localhost:3000/recommendLst - 访问歌单详细信息API
http://localhost:3000/playlist/:playlistId - 访问歌单所有歌曲列表的API
http://localhost:3000/song_list/:playlistId
蟹棒用挺长的篇幅不仅细致分析了这三个API的逻辑思路,而且向简友们详细介绍了如何去分析一个网站的dom结构并使用代码来爬取数据,是一篇API教程的同时,又是一片NodeJs爬虫的新手教学(王婆卖瓜,自卖自夸,哈哈,再装一会....),简友们有问题欢迎给蟹棒留言或者私信,蟹棒看到即会回复
源码
源码蟹棒放到了 Github WangyiyunAPI,以后蟹棒会持续更新API,如果对你有帮助,请给蟹棒一个Star,谢谢
本文对你有帮助?欢迎扫码加入前端学习小组微信群:

