


weibo_terminator 微博终结者爬虫基本上准备就绪:
这次我们更新了以下功能:
- 增加了延时策略,每次爬取10个页面,暂停五分钟,这样依旧不能百分百保证账号不被ban,但是我们还有策略!!
- 现在我们同时使用十几个账号同时开爬了,weibo_scraper 会在一个账号被禁止之后自动切换到下一个账号!!
- 不需要设置cookies!!!重要的事情说三遍,我们不需要在手动设置cookies了,只需要在accounts.py里面设置相应的账号,WT自动获取cookies,后面也可以设置更新,或者删掉cookies缓存手动更新;
如果你认为只有这些你就图样图森破了,三木檀木子拿衣服。更重要的更新在于:
- id不仅仅限于数字id了,一些明星大v的字母id照样爬,我们这次更新默认的id就是angelababy的微博,她的id为:
realangelababy; - 作者完善了从微博内容对话格式提取聊天pair对的脚本, 对话的准确率在 99% 左右(consider copyright issue, we will open source it later);
- 作者提交了分门别类的近800万用户id的list,全网开爬(Consider weibo official limitations, we can't distributed all list, just for sample, join our contributor team we will give every contributor single and unique part of id_file.);
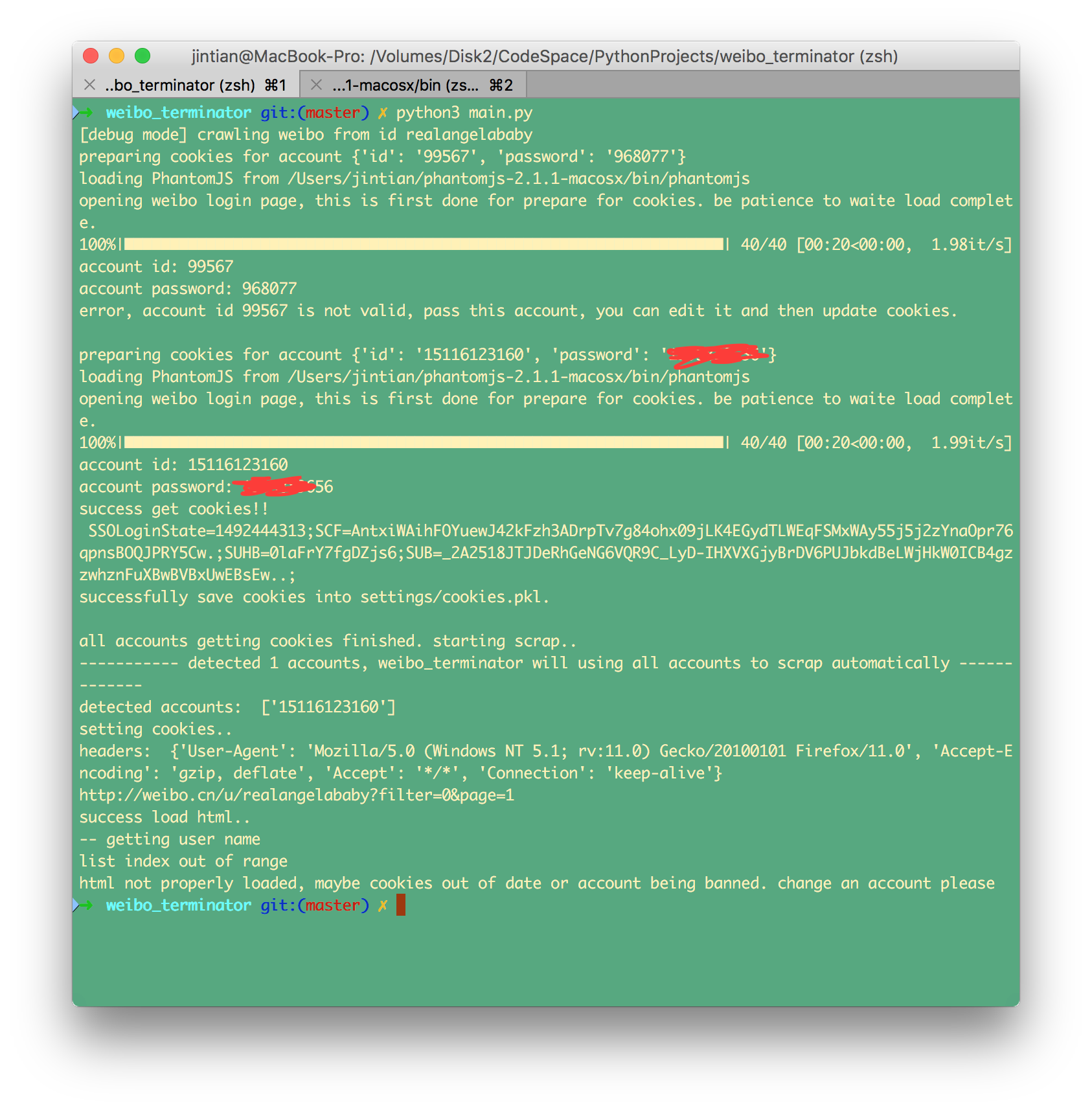
- 作者新增了断点续爬功能,这次更新我们的爬虫会记住上一次爬取到了哪个地方,第二次会直接从上一次中断的地方开始爬取,直到爬完整个微博,所以当你的cookies被ban了以后,直接换小号继续爬即可;
- 所有工作将在半个月之内完成,构建的语料仅限于contributor使用,欢迎大家为WT贡献进来。
为了基于庞大的微博网络,我们发起终结者计划,群策群力爬取微博中文计划语料,这次更新的repo中一个 weibo_id.list 文件,这里面有分门别类的近800万用户的id。 不要问我怎么来的,接下来我们分配给每个contributor一定区间段的id,对全部微博进行爬取,然后把结果上传到我们内部的百度云网盘,所有数据只有所有的contributor以及 weibo_terminator authors可以获取。 最后声明以下,本项目参考了一些类似项目,但是本项目实现的功能,考虑的问题复杂度不是以上这些项目能比拟,我们实现的都是最新的网页API和Python3,很多其他项目都是基于scrapy构建的,本项目根本使用任何类似的爬虫库,
不是别的原因,拿那些库构建的项目缺乏灵活性,我们不太喜欢。希望大家理解。
最后依旧欢迎大家submit issue,我们永远开源,维护更新!!
Contribution tips:
- Clone this repo:
git clone https://github.com/jinfagang/weibo_terminater.git; - Install PhantomJS to enable weibo_terminator auto get cookies, from here get it and set your unzip path to
settings/config.py, follow the instruction there; - Set your multi account, inside
settings/accounts.py, you can using multi account now, terminator will automatically dispatch them; - Run
python3 main.py -i realangelababy, scrap single user, setsettings/id_filefor multi user scrap; - Contact project administrator via wechat
jintianiloveu, if you want contribute, administrator will hand out you and id_file which is unique in our project; - All data will saved into
./weibo_detail, with different id separately. - Collect data to project administrator.
- When all the work finished, administrator will distribute all data as one single file to all contributors. Using it under
WT & TIANEYE COPYRIGHT.
Research & Discuss Group
We fund several group for our project:
QQ
AI智能自然语言处理: 476464663
Tensorflow智能聊天Bot: 621970965
GitHub深度学习开源交流: 263018023
Wechat
add administrator `jintianiloveu` to be added in.
Tutorial
这是第一次commit丢失的部分,使用帮助:
# -h see helps
python3 main.py -h
# -i specific an single id or id_file path(with every id as a line.)
python3 main.py -i 167385960
python3 main.py -i ./id_file
# -f specific filter mode, if 0, all weibo are all original, if 1, contains repost one, default is 0
python3 main.py -i 16758795 -f 0
# -d specific debug mode for testing, be aware debug mode only support one single id.
python3 main.py -i 178600077 -d 1
That's all, simple and easy.

About cookies
The cookies still maybe banned, if our scraper continues get information from weibo, that is exactly we have to get this job done under people's strength, no one can build such a big corpora under one single power. If your cookies out of date or being banned, we strongly recommended using another weibo account which can be your friends or anyone else, and continue scrap, one thing you have to remind is that our weibo_terminator can remember scrap progress and it will scrap from where it stopped last time. :)
微博终结者爬虫
关于聊天对话系统我后面会开源一个项目,这个repo目的是基于微博构建一个高质量的对话语料,本项目将继续更进开发,大家快star!!永远开源!
这个项目致力于对抗微博的反爬虫机制,集合众人的力量把微博成千上万的微博评论语料爬取下来并制作成一个开源的高质量中文对话语料,推动中文对话系统的研发。 本系统现已实现:
- 爬取指定id用户的微博数,关注数,粉丝数,所有微博内容以及所有微博对应的评论;
- 作者考虑到制作对话系统的可行性以及微博语料的难处理性,爬取过程中,所有微博会保存为可提取的形式,具体可以参照爬取结果保存样例;
- 本项目不依赖于任何第三方爬取框架,但手动实现了一个多线程库,当爬取多用户时会开启上百条线程工作,爬取速度在每小时百万级别;
- 本项目最终目的是为了充分利用庞大的微博平台构建一个开源高质量的中文对话系统(据作者所知,很多公司对自己的数据视如珍宝,鄙之);
- 除此之外,本项目还可以用于指定用户评论分析,比如爬取罗永浩的微博可以分析他第二年锤子手机的销量(牛逼把)
希望更多童鞋们contribute进来,还有很多工作要做,欢迎提交PR!
为人工智能而生
中文语料一直以来备受诟病,没有机构或者组织去建立一些公开的数据集,反观国外,英文语料相当丰富,而且已经做的非常精准。
微博语料作者认为是覆盖最广,最活跃最新鲜的语料,使用之构建对话系统不说模型是否精准,但新鲜的词汇量是肯定有的。
爬取结果

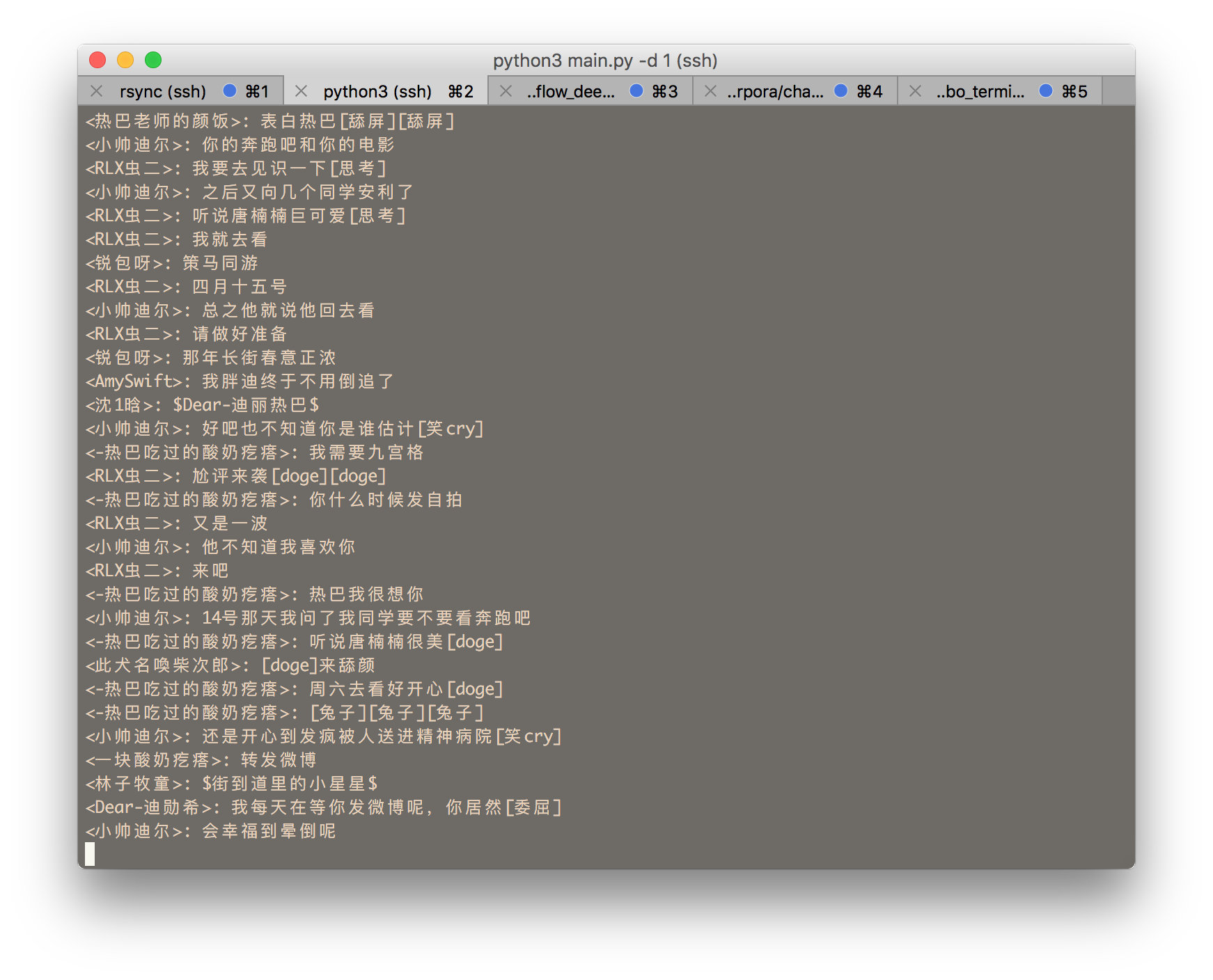
指定用户的微博和评论形式如下:
E
4月15日#傲娇与偏见# 超前点映,跟我一起去抢光它 [太开心] 傲娇与偏见 8.8元超前点映 顺便预告一下,本周四(13号)下
午我会微博直播送福利,不见不散哦[坏笑] 电影傲娇与偏见的秒拍视频 <200b><200b><200b>
E
F
<哈哈哈哈哈哈狗->: 还唱吗[doge]
<緑麓>: 绿麓!
<哈哈哈哈哈哈狗->: [doge][doge]
<至诚dliraba>: 哈哈哈哈哈哈哈
<五只热巴肩上扛>: 大哥已经唱完了[哆啦A梦吃惊]
<哈哈哈哈哈哈狗->: 大哥[哆啦A梦吃惊]
<独爱Dear>: 10:49坐等我迪的直播[喵喵][喵喵][喵喵]
<四只热巴肩上扛>: 对不起[可怜]我不赶
<四只热巴肩上扛>: 哈狗[哆啦A梦花心][哆啦A梦花心]
<至诚dliraba>: 哈狗来了 哈哈哈
<四只热巴肩上扛>: [摊手]绿林鹿去哪里了!!!!
<哈哈哈哈哈哈狗->: 阿健[哆啦A梦花心]
<至诚dliraba>: 然而你还要赶我出去[喵喵]
<四只热巴肩上扛>: 我也很绝望
<至诚dliraba>: 只剩翻墙而来的我了
<四只热巴肩上扛>: [摊手]我能怎么办
<四只热巴肩上扛>: [摊手]一首歌唱到一半被掐断是一个歌手的耻辱[摊手]
<至诚dliraba>: 下一首
<四只热巴肩上扛>: 最害怕就是黑屋[摊手]
<至诚dliraba>: 我脑海一直是 跨过傲娇与偏见 永恒的信念
F
说明:
- E E 表示微博内容的开头和结果
- F F表示所有评论的开头和结尾
- 每条评论中 <> 是发起评论的用户id, ? 中是at用户的id
Future Work
现在爬取的语料是最原始版本,大家对于语料的用途可以从这里开始,可以用来做话题评论机器人,但作者后面将继续开发后期处理程序,把微博raw data变成对话形式,并开源。 当然也欢迎有兴趣的童鞋们给我提交PR,选取一个最佳方案,推动本项目的进展。
Contact
对于项目有任何疑问的可以联系我 wechat: jintianiloveu, 也欢迎提issue
Copyright
(c) 2017 Jin Fagang & Tianmu Inc. & weibo_terminator authors LICENSE Apache 2.0
