

一、 什么是正则表达式
二、为什么要使用正则表达式
正则表达式可以大大简化文本识别工作,现已超出了某种语言或某个系统的局限,成为被人们广为使用的工具。
三、正则表达式简介
1. 正则表达式基本书写符号
| 符号 |
符号 |
示例 |
解释 |
匹配输入 |
| \ |
转义符 |
\* |
符号“*” |
* |
| [ ] |
可接收的字符列表 |
[efgh] |
e、f、g、h中的任意1个字符 |
e、f、g、h |
| [^] |
不接收的字符列表 |
[^abc] |
除a、b、c之外的任意1个字符,包括数字和特殊符号 |
m、q、5、* |
| | |
匹配“|”之前或之后的表达式 |
ab|cd |
ab或者cd |
ab、cd |
| ( ) |
将子表达式分组 |
(abc) |
将字符串abc作为一组 |
abc |
| - |
连字符 |
A-Z |
任意单个大写字母 |
大写字母 |
2.正则表达式限定符
限定符将可选数量的数据添加到正则表达式,下表为常用限定符:
| 符号 |
含义 |
示例 |
示例 |
匹配输入 |
不匹配输入 |
| * |
指定字符重复0次或n次 |
(abc)* |
仅包含任意个abc的字符串,等效于\w* |
abc、abcabcabc |
a、abca |
| + |
指定字符重复1次或n次 |
m+(abc)* |
以至少1个m开头,后接任意个abc的字符串 |
m、mabc、mabcabc |
ma、abc |
| ? | 指定字符重复0次或1次 |
m+abc? |
以至少1个m开头,后接ab或abc的字符串 |
mab、mabc、mmmab、mmabc |
ab、abc、mabcc |
| {n} |
只能输入n个字符 |
[abcd]{3} |
由abcd中字母组成的任意长度为3的字符串 |
abc、dbc、adc |
a、aa、dcbd |
| {n,} |
指定至少 n 个匹配 |
[abcd]{3,} |
由abcd中字母组成的任意长度不小于3的字符串 |
aab、dbc、aaabdc |
a、cd、bb |
| {n,m} |
指定至少 n 个但不多于 m 个匹配 |
[abcd]{3,5} |
由abcd中字母组成的任意长度不小于3,不大于5的字符串 |
abc、abcd、aaaaa、bcdab |
ab、ababab、a |
| ^ |
指定起始字符 |
^[0-9]+[a-z]* |
以至少1个数字开头,后接任意个小写字母的字符串 |
123、6aa、555edf |
abc、aaa、a33 |
| $ |
指定结束字符 |
^[0-9]\-[a-z]+$ |
以1个数字开头后接连字符“–”,并以至少1个小写字母结尾的字符串 |
2-a、3-ddd、5-efg |
33a、8-、7-Ab |
3. 匹配字符集
匹配字符集是预定义的用于正则表达式中的符号集。如果字符串与字符集中的任何一个字符相匹配,它就会找到这个匹配项。
正则表达式中的部分匹配字符集:
| 符号 |
含义 |
示例 |
示例 |
匹配输入 |
不匹配输入 |
| . |
匹配除 \n 以外的任何字符 |
a..b |
以a开头,b结尾,中间包括2个任意字符的长度为4的字符串 |
aaab、aefb、a35b、a#*b |
ab、aaaa、a347b |
| \d |
匹配单个数字字符,相当于[0-9] |
\d{3}(\d)? |
包含3个或4个数字的字符串 |
123、9876 |
123、9876 |
| \D | 匹配单个非数字字符,相当于[^0-9] |
\D(\d)* |
以单个非数字字符开头,后接任意个数字字符串 |
a、A342 | aa、AA78、1234 |
| \w |
匹配单个数字、大小写字母字符,相当于[0-9a-zA-Z] |
\d{3}\w{4} |
以3个数字字符开头的长度为7的数字字母字符串 |
234abcd、12345Pe |
58a、Ra46 |
| \W |
匹配单个非数字、大小写字母字符,相当于[^0-9a-zA-Z] |
\W+\d{2} |
以至少1个非数字字母字符开头,2个数字字符结尾的字符串 |
#29、#?@10 |
23、#?@100 |
4. 分组构造
常用分组构造形式:
| 常用分组构造形式 | 说明 |
| () | 非命名捕获。捕获匹配的子字符串(或非捕获组)。编号为零的第一个捕获是由整个正则表达式模式匹配的文本,其它捕获结果则根据左括号的顺序从1开始自动编号。 |
| (?<name>) | 命名捕获。将匹配的子字符串捕获到一个组名称或编号名称中。用于name的字符串不能包含任何标点符号,并且不能以数字开头。可以使用单引号替代尖括号,例如 (?'name') |
5.字符转义
如果你想查找元字符本身的话,比如你查找.,或者*,就出现了问题:你没办法指定它们,因为它们会被解释成别的意思。这时你就得使用\来取消这些字符的特殊意义。因此,你应该使用\.和\*。当然,要查找\本身,你也得用\\
例如:deerchao\.net匹配deerchao.NET,C:\\Windows匹配C:\Windows。
在Java中的写法: (https://github\\.com/[\\w\\-]) 用"\\."配备"."。
6. 正则表达式举例
◆ 非负整数:“^\d+$ ”
◆ 正整数: “ ^[0-9]*[1-9][0-9]*$”
◆ 非正整数: “ ^((-\d+)|(0+))$”
◆ 整数: “ ^-?\d+$”
◆ 英文字符串:
“ ^[A-Za-z]+$”
◆ 英文字符数字串: “ ^[A-Za-z0-9]+$”
◆ 英数字加下划线串: “^\w+$”
◆ E-mail地址:“^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$”
◆ URL:“^[a-zA-Z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\s*)?$”
四、总结
1、字母:匹配单个字母
(1)A:表示匹配字母A;
(2)\\:匹配转义字符“\”;
(3)\t:匹配转义字符“\t”;
(4)\n:匹配转义字符“\n”;
2、一组字符:任意匹配里面的一个单个字符:
(1)[abc]:表示可能是字母a,可能是字母b或者是字母c;
(2)[^abc]:表示不是字母a,字母b,字母c的任意一个;
(3)[a-zA-Z]:表示全部字母中的任意一个;
(4)[0-9]:表示全部数字的任意一个;
3、边界匹配:在以后编写JavaScript的时候使用正则中要使用到:
(1)^:表示一组正则的开始;
(2)$:表示一组正则的结束;
4、简写表达式:每一位出现的简写标记也只表示一位:
(1)· :表示任意的一位字符;
(2)\d :表示任意的一位数字,等价于“[0-9]”;
(3)\D :表示任意的一位非数字,等价于“[~0-9]”;
(4)\w :表示任意的一位字母、数字、_,等价于“[a-zA-Z0-9_]”;
(5)\w :表示任意的一位非字母、数字、_,等价于“[^a-zA-Z0-9_]”;
(6)\s :表示任意的一位空格,例如:\n、\t等;
(7)\S :表示任意的一位非空格;
5、数量表示:之前所有的正则都只是表示一位,如果要表示多位,则就需要数量表示。
(1)正则表达式?:此正则出现0次或1次;
(2)正则表达式*:此正则出现0次、1次或多次;
(3)正则表达式+:次正则出现1次或多次;
(4)正则表达式{n}:此正则出现正好n次;
(5)正则表达式{n,}:此正则出现n次以上;
(6)正则表达式{n,m}:此正则出现n – m次。
6、逻辑表示:与、或、非
(1)正则表达式A正则表达式B: 表达式A之后紧跟着表达式B;
(2)正则表达式|A正则表达式B: 表示表达式A或者表达式B,二者任选一个出现;
(3)(正则表达式):将多个子表达式合成一个表示,作为一组出现。
五、示例
1.验证是否为数字:是否带小数点、正负都行
String str="234234.88";
String rex="-*\\d+\\.*\\d*";
System.out.println(str.matches(rex));
2.假设我们要在文本文件中搜索美国的社会安全号码。这个号码的格式是999-99-9999。用来匹配它的正则表达式。在正则表达式中,连字符(“-”)有着特殊的意义,它表示一个范围,比如从0到9。因此,匹配社会安全号码中的连字符号时,它的前面要加上一个转义字符“\”。
看看下面那一行正则表达式是对的:
(0-9){3} \-(0-9){2} \- (0-9){4}
[0-9]{3} \-[0-9]{2} \- [0-9]{4}
正确的是:

图:匹配所有123-12-1234形式的社会安全号码
3.假设进行搜索的时候,你希望连字符号可以出现,也可以不出现——即,999-99-9999和999999999都属于正确的格式。这时,你可以在连字符号后面加上一个数量限定符号,如图所示:
看看下面那一行正则表达式是对的:
(0-9){3} \-?(0-9){2} \-? (0-9){4}
[0-9]{3} \-*[0-9]{2} \-* [0-9]{4}
正确的是:

图:匹配所有123-12-1234和123121234形式的社会安全号码
4.美国汽车牌照的一种格式是四个数字加上二个字母。它的正则表达式前面是数字部分“[0-9]{4}”,再加上字母部分“[A-Z]{2}”。图显示了完整的正则表达式。
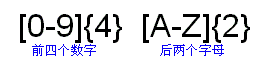
图:匹配典型的美国汽车牌照号码,如8836KV
5."否"符号
"^"符号称为“否”符号。如果用在方括号内,“^”表示不想要匹配的字符。例如,图四的正则表达式匹配所有单词,但以“X”字母开头的单词除外。

图:匹配所有单词,但“X”开头的除外
6.圆括号和空白符号
假设要从格式为“June 26, 1951”的生日日期中提取出月份部分,用来匹配该日期的正则表达式可以如图所示:
看看下面哪一个是正确的:
[a-z]* \s+ [0-9]{1,2},\s* [0-9]{4}
[a-z]+ \s+ [0-9]{1,2},\s* [0-9]{4}
正确的是:

图:匹配所有Moth DD,YYYY格式的日期
“\s”符号是空白符号,匹配所有的空白字符,包括Tab字符。如果字符串正确匹配,接下来如何提取出月份部分呢?只需在月份周围加上一个圆括号创建一个组

图:匹配所有Month DD,YYYY格式的日期,定义月份值为第一个组
六、JAVA正则表达式Pattern和Matcher
java.util.regex是一个用正则表达式所订制的模式来对字符串进行匹配工作的类库包。
1.简介:
java.util.regex是一个用正则表达式所订制的模式来对字符串进行匹配工作的类库包。
它包括两个类:Pattern和Matcher 。
Pattern: 一个Pattern是一个正则表达式经编译后的表现模式。
Matcher:一个Matcher对象是一个状态机器,它依据Pattern对象做为匹配模式对字符串展开匹配检查。
首先一个Pattern实例订制了一个所用语法与PERL的类似的正则表达式经编译后的模式,然后一个Matcher实例在这个给定的Pattern实例的模式控制下进行字符串的匹配工作。
以下我们就分别来看看这两个类:
2.Pattern类:
Pattern的方法如下:
static Pattern compile(String regex)
将给定的正则表达式编译并赋予给Pattern类
static Pattern compile(String regex, int flags)
同上,但增加flag参数的指定,可选的flag参数包括:CASE INSENSITIVE,MULTILINE,DOTALL,UNICODE CASE, CANON EQ
int flags()
返回当前Pattern的匹配flag参数
Matcher matcher(CharSequence input)
生成一个给定命名的Matcher对象
static boolean matches(String regex, CharSequence input)
编译给定的正则表达式并且对输入的字串以该正则表达式为模开展匹配,该方法适合于该正则表达式只会使用一次的情况,也就是只进行一次匹配工作,因为这种情况下并不需要生 成一个Matcher实例。
String pattern()
返回该Patter对象所编译的正则表达式。
String[] split(CharSequence input)
将目标字符串按照Pattern里所包含的正则表达式为模进行分割。
String[] split(CharSequence input, int limit)
作用同上,增加参数limit目的在于要指定分割的段数,如将limi设为2,那么目标字符串将根据正则表达式分为割为两段。
一个正则表达式,也就是一串有特定意义的字符,必须首先要编译成为一个Pattern类的实例,这个Pattern对象将会使用matcher()方法来生成一个Matcher实例,接着便可以使用该 Matcher实例以编译的正则表达式为基础对目标字符串进行匹配工作,多个Matcher是可以共用一个Pattern对象的。
现在我们先来看一个简单的例子,再通过分析它来了解怎样生成一个Pattern对象并且编译一个正则表达式,最后根据这个正则表达式将目标字符串进行分割:
- import java.util.regex.*;
- public class Replacement{
- public static void main(String[] args) throws Exception {
- // 生成一个Pattern,同时编译一个正则表达式
- Pattern p = Pattern.compile("[/]+");
- //用Pattern的split()方法把字符串按"/"分割
- String[] result = p.split(
- "Kevin has seen《LEON》seveal times,because it is a good film."
- +"/ 凯文已经看过《这个杀手不太冷》几次了,因为它是一部"
- +"好电影。/名词:凯文。");
- for (int i=0; i<result.length; i++)
- System.out.println(result[i]);
- }
- }

import java.util.regex.*;
public class Replacement{
public static void main(String[] args) throws Exception {
// 生成一个Pattern,同时编译一个正则表达式
Pattern p = Pattern.compile("[/]+");
//用Pattern的split()方法把字符串按"/"分割
String[] result = p.split(
"Kevin has seen《LEON》seveal times,because it is a good film."
+"/ 凯文已经看过《这个杀手不太冷》几次了,因为它是一部"
+"好电影。/名词:凯文。");
for (int i=0; i<result.length; i++)
System.out.println(result[i]);
}
}输出结果为:
Kevin has seen《LEON》seveal times,because it is a good film.
凯文已经看过《这个杀手不太冷》几次了,因为它是一部好电影。
名词:凯文。
很明显,该程序将字符串按"/"进行了分段。
我们以下再使用 split(CharSequence input, int limit)方法来指定分段的段数,程序改动为:
tring[] result = p.split("Kevin has seen《LEON》seveal times,because it is a good film./ 凯文已经看过《这个杀手不太冷》几次了,因为它是一部好电影。/名词:凯文。",2);
这里面的参数"2"表明将目标语句分为两段。
输出结果则为:
Kevin has seen《LEON》seveal times,because it is a good film.
凯文已经看过《这个杀手不太冷》几次了,因为它是一部好电影。/名词:凯文。
判断是否为非负整数
String s="4";
String reg="\\d*";
System.out.println(s.matches(reg));判断是否为正整数
- String s="10";
- String reg="([1-9]{1})||([1-9]*\\d*)";
- System.out.println(s.matches(reg));
String s="10";
String reg="([1-9]{1})||([1-9]*\\d*)";
System.out.println(s.matches(reg));3.Matcher类:
Matcher方法如下: Matcher appendReplacement(StringBuffer sb, String replacement)
将当前匹配子串替换为指定字符串,并且将替换后的子串以及其之前到上次匹配子串之后的字符串段添加到一个StringBuffer对象里。
StringBuffer appendTail(StringBuffer sb)
将最后一次匹配工作后剩余的字符串添加到一个StringBuffer对象里。
int end()
返回当前匹配的子串的最后一个字符在原目标字符串中的索引位置 。
int end(int group)
返回与匹配模式里指定的组相匹配的子串最后一个字符的位置。
boolean find()
尝试在目标字符串里查找下一个匹配子串。
boolean find(int start)
重设Matcher对象,并且尝试在目标字符串里从指定的位置开始查找下一个匹配的子串。
String group()
返回当前查找而获得的与组匹配的所有子串内容 。
String group(int group)
返回当前查找而获得的与指定的组匹配的子串内容。
int groupCount()
返回当前查找所获得的匹配组的数量。
boolean lookingAt()
检测目标字符串是否以匹配的子串起始。
boolean matches()
尝试对整个目标字符展开匹配检测,也就是只有整个目标字符串完全匹配时才返回真值。
Pattern pattern()
返回该Matcher对象的现有匹配模式,也就是对应的Pattern 对象。
String replaceAll(String replacement)
将目标字符串里与既有模式相匹配的子串全部替换为指定的字符串。
String replaceFirst(String replacement)
将目标字符串里第一个与既有模式相匹配的子串替换为指定的字符串。
Matcher reset()
重设该Matcher对象。
Matcher reset(CharSequence input)
重设该Matcher对象并且指定一个新的目标字符串。
int start()
返回当前查找所获子串的开始字符在原目标字符串中的位置。
int start(int group)
返回当前查找所获得的和指定组匹配的子串的第一个字符在原目标字符串中的位置。
一个Matcher实例是被用来对目标字符串进行基于既有模式(也就是一个给定的Pattern所编译的正则表达式)进行匹配查找的,所有往Matcher的输入都是通过CharSequence接口提供的,这样做的目的在于可以支持对从多元化的数据源所提供的数据进行匹配工作。
我们分别来看看各方法的使用:
★matches()/lookingAt()/find():
一个Matcher对象是由一个Pattern对象调用其matcher()方法而生成的,一旦该Matcher对象生成,它就可以进行三种不同的匹配查找操作:
matches()方法尝试对整个目标字符展开匹配检测,也就是只有整个目标字符串完全匹配时才返回真值。
lookingAt ()方法将检测目标字符串是否以匹配的子串起始。
find()方法尝试在目标字符串里查找下一个匹配子串。
以上三个方法都将返回一个布尔值来表明成功与否。
★replaceAll ()/appendReplacement()/appendTail():
Matcher类同时提供了四个将匹配子串替换成指定字符串的方法:
replaceAll()
replaceFirst()
appendReplacement()
appendTail()
replaceAll()与replaceFirst()的用法都比较简单,请看上面方法的解释。我们主要重点了解一下appendReplacement()和appendTail()方法。
appendReplacement(StringBuffer sb, String replacement) 将当前匹配子串替换为指定字符串,并且将替换后的子串以及其之前到上次匹配子串之后的字符串段添加到一个StringBuffer对象里,而appendTail(StringBuffer sb) 方法则将最后一次匹配工作后剩余的字符串添加到一个StringBuffer对象里。
例如,有字符串fatcatfatcatfat,假设既有正则表达式模式为"cat",第一次匹配后调用appendReplacement(sb,"dog"),那么这时StringBuffer sb的内容为fatdog,也就是fatcat中的cat被替换为dog并且与匹配子串前的内容加到sb里,而第二次匹配后调用appendReplacement(sb,"dog"),那么sb的内容就变为fatdogfatdog,如果最后再调用一次appendTail(sb),那么sb最终的内容将是fatdogfatdogfat。
还是有点模糊?那么我们来看个简单的程序:
//该例将把句子里的"Kelvin"改为"Kevin"
- import java.util.regex.*;
- public class MatcherTest{
- public static void main(String[] args) throws Exception {
- //生成Pattern对象并且编译一个简单的正则表达式"Kelvin"
- Pattern p = Pattern.compile("Kelvin");
- //用Pattern类的matcher()方法生成一个Matcher对象
- Matcher m = p.matcher("Kelvin Li and Kelvin Chan are both working in Kelvin Chen's KelvinSoftShop company");
- StringBuffer sb = new StringBuffer();
- int i=0;
- //使用find()方法查找第一个匹配的对象
- boolean result = m.find();
- //使用循环将句子里所有的kelvin找出并替换再将内容加到sb里
- while(result) {
- i++;
- m.appendReplacement(sb, "Kevin");
- System.out.println("第"+i+"次匹配后sb的内容是:"+sb);
- //继续查找下一个匹配对象
- result = m.find();
- }
- //最后调用appendTail()方法将最后一次匹配后的剩余字符串加到sb里;
- m.appendTail(sb);
- System.out.println("调用m.appendTail(sb)后sb的最终内容是:"+ sb.toString());
- }
- }
import java.util.regex.*;
public class MatcherTest{
public static void main(String[] args) throws Exception {
//生成Pattern对象并且编译一个简单的正则表达式"Kelvin"
Pattern p = Pattern.compile("Kelvin");
//用Pattern类的matcher()方法生成一个Matcher对象
Matcher m = p.matcher("Kelvin Li and Kelvin Chan are both working in Kelvin Chen's KelvinSoftShop company");
StringBuffer sb = new StringBuffer();
int i=0;
//使用find()方法查找第一个匹配的对象
boolean result = m.find();
//使用循环将句子里所有的kelvin找出并替换再将内容加到sb里
while(result) {
i++;
m.appendReplacement(sb, "Kevin");
System.out.println("第"+i+"次匹配后sb的内容是:"+sb);
//继续查找下一个匹配对象
result = m.find();
}
//最后调用appendTail()方法将最后一次匹配后的剩余字符串加到sb里;
m.appendTail(sb);
System.out.println("调用m.appendTail(sb)后sb的最终内容是:"+ sb.toString());
}
} 最终输出结果为:
第1次匹配后sb的内容是:Kevin
第2次匹配后sb的内容是:Kevin Li and Kevin
第3次匹配后sb的内容是:Kevin Li and Kevin Chan are both working in Kevin
第4次匹配后sb的内容是:Kevin Li and Kevin Chan are both working in Kevin Chen's Kevin
调用m.appendTail(sb)后sb的最终内容是:Kevin Li and Kevin Chan are both working in Kevin Chen's KevinSoftShop company。
七、常用的正则表达式
匹配特定数字:
^[1-9]d*$ //匹配正整数
^-[1-9]d*$ //匹配负整数
^-?[1-9]d*$ //匹配整数
^[1-9]d*|0$ //匹配非负整数(正整数 + 0)
^-[1-9]d*|0$ //匹配非正整数(负整数 + 0)
^[1-9]d*.d*|0.d*[1-9]d*$ //匹配正浮点数
^-([1-9]d*.d*|0.d*[1-9]d*)$ //匹配负浮点数
^-?([1-9]d*.d*|0.d*[1-9]d*|0?.0+|0)$ //匹配浮点数
^[1-9]d*.d*|0.d*[1-9]d*|0?.0+|0$ //匹配非负浮点数(正浮点数 + 0)
^(-([1-9]d*.d*|0.d*[1-9]d*))|0?.0+|0$ //匹配非正浮点数(负浮点数 + 0)
评注:处理大量数据时有用,具体应用时注意修正
匹配特定字符串:
^[A-Za-z]+$ //匹配由26个英文字母组成的字符串
^[A-Z]+$ //匹配由26个英文字母的大写组成的字符串
^[a-z]+$ //匹配由26个英文字母的小写组成的字符串
^[A-Za-z0-9]+$ //匹配由数字和26个英文字母组成的字符串
^w+$ //匹配由数字、26个英文字母或者下划线组成的字符串
在使用RegularExpressionValidator验证控件时的验证功能及其验证表达式介绍如下:
只能输入数字:“^[0-9]*$”
只能输入n位的数字:“^d{n}$”
只能输入至少n位数字:“^d{n,}$”
只能输入m-n位的数字:“^d{m,n}$”
只能输入零和非零开头的数字:“^(0|[1-9][0-9]*)$”
只能输入有两位小数的正实数:“^[0-9]+(.[0-9]{2})?$”
只能输入有1-3位小数的正实数:“^[0-9]+(.[0-9]{1,3})?$”
只能输入非零的正整数:“^+?[1-9][0-9]*$”
只能输入非零的负整数:“^-[1-9][0-9]*$”
只能输入长度为3的字符:“^.{3}$”
只能输入由26个英文字母组成的字符串:“^[A-Za-z]+$”
只能输入由26个大写英文字母组成的字符串:“^[A-Z]+$”
只能输入由26个小写英文字母组成的字符串:“^[a-z]+$”
只能输入由数字和26个英文字母组成的字符串:“^[A-Za-z0-9]+$”
只能输入由数字、26个英文字母或者下划线组成的字符串:“^w+$”
验证用户密码:“^[a-zA-Z]w{5,17}$”正确格式为:以字母开头,长度在6-18之间,
只能包含字符、数字和下划线。
验证是否含有^%&’,;=?$”等字符:“[^%&’,;=?$x22]+”
只能输入汉字:“^[u4e00-u9fa5],{0,}$”
验证Email地址:“^w+[-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*$”
验证InternetURL:“^http://([w-]+.)+[w-]+(/[w-./?%&=]*)?$”
验证电话号码:“^((d{3,4})|d{3,4}-)?d{7,8}$”
正确格式为:“XXXX-XXXXXXX”,“XXXX-XXXXXXXX”,“XXX-XXXXXXX”,
“XXX-XXXXXXXX”,“XXXXXXX”,“XXXXXXXX”。
验证身份证号(15位或18位数字):“^d{15}|d{}18$”
验证一年的12个月:“^(0?[1-9]|1[0-2])$”正确格式为:“01”-“09”和“1”“12”
验证一个月的31天:“^((0?[1-9])|((1|2)[0-9])|30|31)$”
正确格式为:“01”“09”和“1”“31”。
匹配中文字符的正则表达式: [u4e00-u9fa5]
匹配双字节字符(包括汉字在内):[^x00-xff]
匹配空行的正则表达式:n[s| ]*r
匹配HTML标记的正则表达式:/< (.*)>.*|< (.*) />/
匹配首尾空格的正则表达式:(^s*)|(s*$)
匹配Email地址的正则表达式:w+([-+.]w+)*@w+([-.]w+)*.w+([-.]w+)*
匹配网址URL的正则表达式:http://([w-]+.)+[w-]+(/[w- ./?%&=]*)?
