

前段时间业务反映某类服务器上更新了 bash 之后,ssh 连上去偶发登陆失败,客户端吐出错误信息如下所示:

图 - 0
该版本 bash 为部门这边所定制,但是实现上与原生版并没有不同,那么这些错误从哪里来?
是 bash 的锅吗
从上面的错误信息可以猜测,异常是 bash 在启动过程中分配内存失败所导致,看起来像是某些情况下该进程错误地进行了大量内存分配,最后导致内存不足,要确认这个事情比较简单,动态内存分配到系统调用这一层上主要就两种方式: brk() 和 mmap(), 所以只要统计一下这两者的调用就可以大概估算出是否有大内存分配了。
bash 是由 sshd 启动的,于是 strace 跟踪了一下 sshd 进程,结果发现异常发生时,bash 分配的内存非常地少,少到有时甚至只有几十字节也会失败,几乎可以断定 bash 在内存使用上没有异常,但在这期间发现一个诡异的现象,Bash 一直只用 brk 在分配小内存,brk() 失败后就直接退出了,一般程序使用的 libc 中的 malloc (或其它类似的 malloc) 会结合 brk 和 mmap 一起使用【0】,不至于 brk 一失败就分配不到内存,顺手查看了下 bash 的源码,发现它确实基于 brk 做了自己的内存管理,并没有使用 malloc 或 mmap。
但那并不是重点,重点是即使是只使用 brk,也不至于只能分配几十字节的内存。
进程的内存布局
进程的内存布局在结构上是有规律的,具体来说对于 linux 系统上的进程,其内存空间一般可以粗略地分为以下几大段【1】,从高内存到低内存排列:
1、内核态内存空间,其大小一般比较固定(可以编译时调整),但 32 位系统和 64 位系统的值不一样。
2、用户态的堆栈,大小不固定,可以用 ulimit -s 进行调整,默认一般为 8M,从高地址向低地址增长。
3、mmap 区域,进程茫茫内存空间里的主要部分,既可以从高地址到低地址延伸(所谓 flexible layout),也可以从低到高延伸(所谓
legacy layout),看进程具体情况【2】【3】。
4、brk 区域,紧邻数据段(甚至贴着),从低位向高位伸展,但它的大小主要取决于 mmap 如何增长,一般来说,即使是 32 位的进程以传统方式延伸,也有差不多 1 GB 的空间(准确地说是 TASK_SIZE/3 - 代码段数据段,参看 arch/x86/include/asm/processor.h 里宏 TASK_UNMAPPED_BASE 的定义)【4】
5、数据段,主要是进程里初始化和未初始化的全局数据总和,当然还有编译器生成一些辅助数据结构等等),大小取决于具体进程,其位置紧贴着代码段。
6、代码段,主要是进程的指令,包括用户代码和编译器生成的辅助代码,其大小取决于具体程序,但起始位置根据 32 位还是 64 位一般固定(-fPIC, -fPIE等除外【5】)。
以上各段(除了代码段数据段)其起始位置根据系统是否起用 randomize_va_space 一般稍有变化,各段之间因此可能有随机大小的间隔,千言万语不如一幅图:

图 - 1
所以现在的问题归结为:为什么目标进程的 brk 的区域突然那么小了,先检查一下 bash 的内存布局:
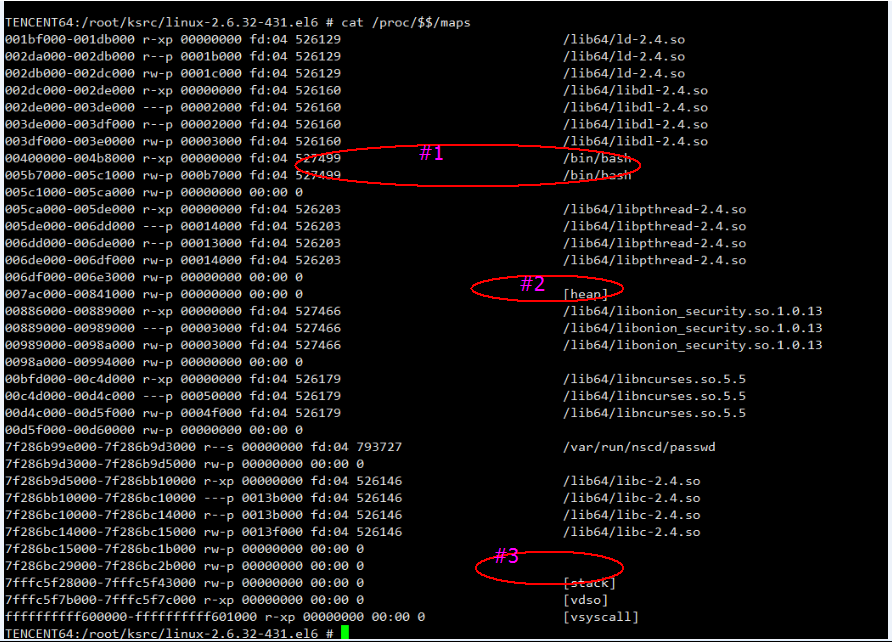
图 - 2
这个进程的内存布局和一般理解上有很大出入,从上往下是低内存到高内存:
#1 处为进程的代码段和数据段,这两个区域一般处于进程内存空间的最低处,但现在在更低处明显有动态库被映射了进来。
#2 处为 brk 的区域,该区域还算紧临着数据段,但是,brk 与代码段之间也被插入了动态库,而且更要命的是,brk 区域向高处伸展的方向上,动态库映射的区域贴的很近,导致 brk 的区域事实上只有很小一个空间(0x886000 - 0x7ac000)。
这并不是我们想要的内存布局,我们想要的应该是长成下面这样的:

图 - 3
看出来不同了没有,两个 bash 进程都是 64 位的,不同在于前者是 sshd 起的进程后者是我手动在终端上起起来的,手动 cat /proc/self/maps 看了下 64 位的 cat 的进程的内存布局也是正常的:

图 - 4
那 sshd 进程呢?
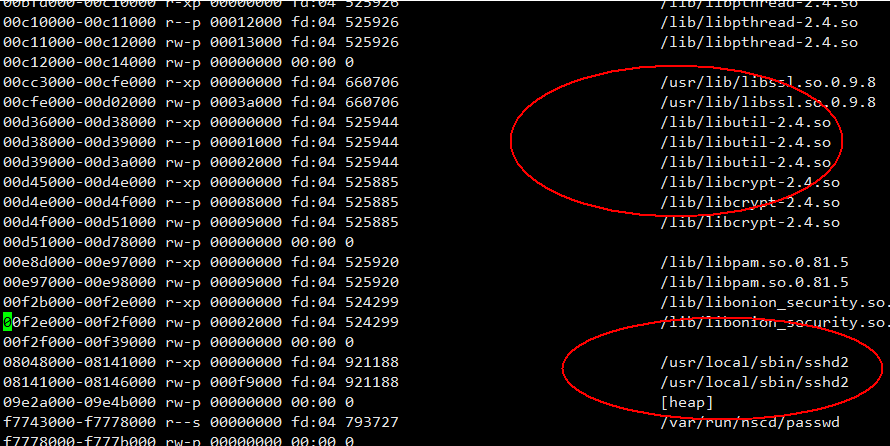
图 - 5
sshd 进程也不正常,而且意外发现 sshd 是 32 位的,于是写了个测试程序:
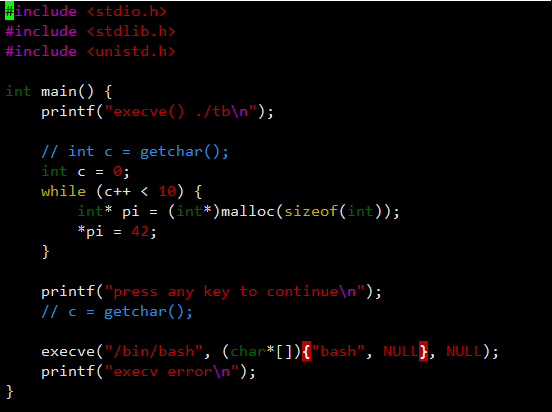
图 - 6
该程序编译为 32 位在目标机器上可以重现问题,而如果编译为 64 位则一切正常,另一个发现是只要是 32 位的进程,它们的内存布局都"不正常"。
操作系统的锅吗?
要搞清楚这个问题得先搞明白进程在内核里启动的流程,对用户态的进程来说,任何进程都是从母进程 fork 出来后再执行 execve, execv 则主要调用对应的加载器(主要是 elf loader)来把代码段、数据段以及动态连接器(ld.so,如果需要)加载进内存空间的各个相应位置,完成之后直接跳到动态连接器的入口(这里先忽略静态链接的程序),其它的动态库都由动态库连接器负责加载,需要注意的是,无论是内核加载 ld.so 还是 ld.so 加载其它动态库,都需要 mmap 的协助,这是用来在内存空间里找位置用的。
现在我们来看看内核出了什么问题,目标系统版本如下,经过咨询系统组的人确认,该系统基于 centos 6.5: vault.centos.org/6.5/centosp…

图 - 7
首先看看 arch/x86/mm/mmap.c: arch_pick_mmap_layout() 这个函数,它的作用是根据进程和当前系统的设置初化 mmap 相关的入口:
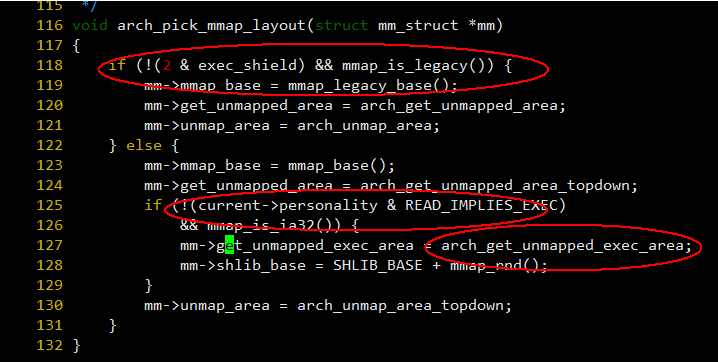
图 - 8
Exec-shield 是一类安全功能的开关,由红帽在很多年前主导搞的对 buffer overflow 攻击的一系列增强,具体可以参看这几个连接 1、2,3, 4,exec shield 在实现和使用上一直有问题,也破坏了有些旧程序的兼容性【6】,因此一直没进主干,只在 redhat 家族 6.x 及其派生系统上使用。
这个功能有一个开关 /proc/sys/kernel/exec-shield,根据链接【6】上的说明,exec-shield 可以设置为 0、1、2、3,分别表示:强制关闭/默认关闭除非可执行程序指定打开/默认打开除非可执行程序指定关闭/强制打开。
mm->get_unmapped_area 是进程需要进行 mmap 时调用的最终函数, arch_get_unmap_area() 用来以传统方式从低位开始搜索合适的位置,arch_get_unmapped_area_topdown() 则以 flexible layout 的方式从高位开始搜索合适的位置,关键点在于 125 ~ 129 行,exec-shield 引进了另一种专门针对 32 位进程的内存分配方式,这种方式指定如果要分配的内存需要可执行权限,那么应该从 mm->shlib_base
这里开始搜索合适的位置,shlib_base 的值为 SHLIB_BASE 加上一个小的随机偏移,而 SHLIB_BASE 的值为【7】:
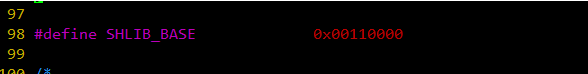
图 - 9
注意到该地址位于 32 位进程的代码段之前(0x8048000),所以这就解释了为什么 32 位的进程,它的动态库被加载到了低位甚至穿插进了 brk 和数据段之间的空隙,本来这个特殊的搜索内存空间的方式是只针对需要可执行权限的内存,但由于 elf 加载器在加载动态库时是分段(PT_LOAD)进行加载【8】,第一个段的位置由 mm->get_unmap_area() 搜索合适的位置分配,后续的段则使用 MAP_FIXED 强制放在了第一个段的后面,所以导致数据段也映射到了低位.【9】
下图 1641 行展示了 mmap 时怎样从 mm 结构里获取 get_area 函数,可以看到,只要 mm->get_unmmapped_exec_area 不为空,且要分配的内存需要可执行权限,就优先使用 mm->get_unmmapped_exec_area 进行搜索。
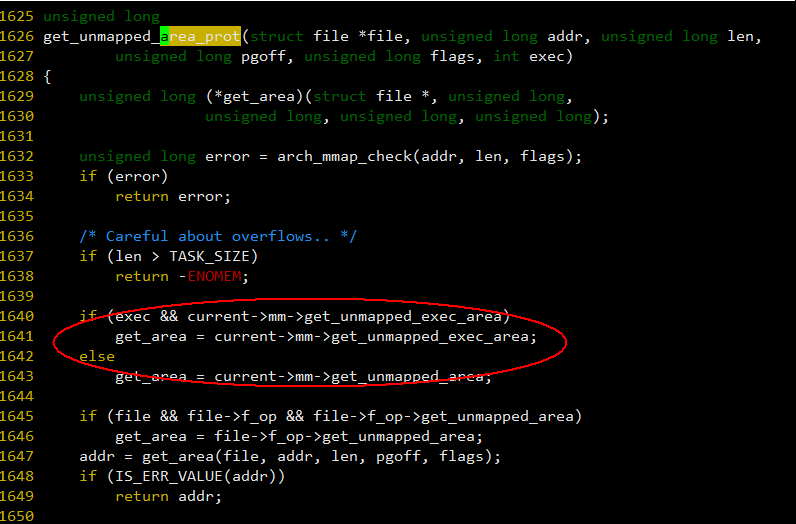
图 - 10
上面这种针对 exec 内存的分配方式实际上很容易引起冲突,redhat 在这里也是打了不少补丁,参看1,2,3。
问题并没有解决
上面的解释说明了为什么 32 位进程的内存布局会异常,但是这里的问题是,为什么用 32 位进程起 64 位进程时,64 位的进程也同样受到了影响。要搞清楚这里的问题,就得看看 fs/binfmt_elf.c: load_elf_binary() 这个函数,它用来在当前进程中加载 elf 格式可执行文件并跳过去执行,此函数被 32 位的 elf 与 64 位 elf 所共用(借助了比较隐蔽的宏),它做的事情总结起来包括如下:
1、读取和解析 elf 文件里包含的各种信息,关键信息如代码段,数据段,动态链接器等。
2、flush_old_exec(): 停止当前进程内的所有线程,清空当前内存空间,重置各种状态等。
3、设置新进程的状态,如分配内存空间,初始化等。
4、加载动态连接器并跳过去执行。
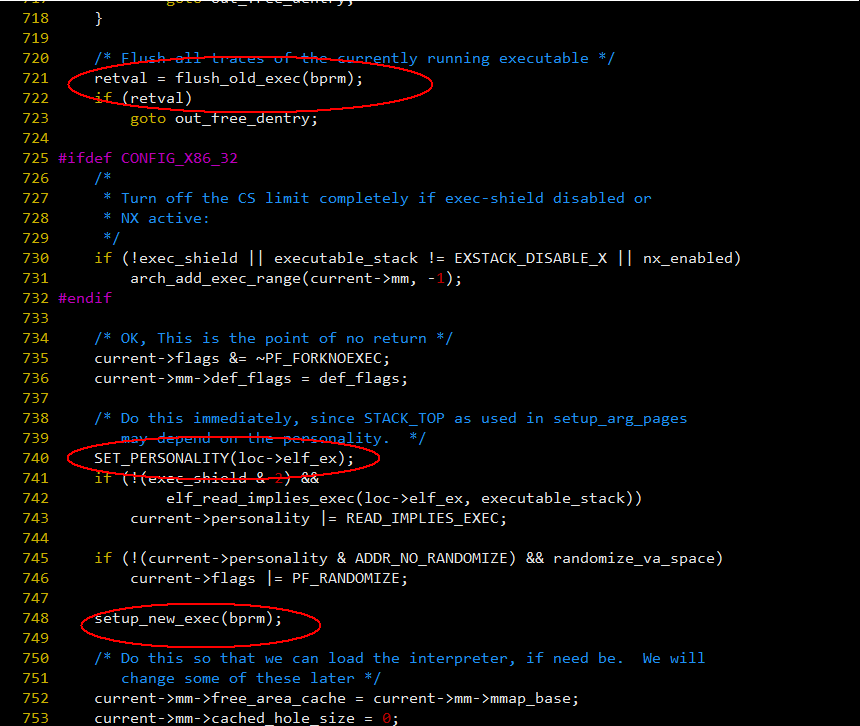
图 - 11
现在回到我们问题,当前进程是 32 位的,在 64 位的系统上执行 32 位的进程需要内核支持,当内核发现 elf 是 32 位的程序时,会在 task 内部置一个标志,这个标志在上图 load_elf_binary() 函数里 740 行调用 SET_PERSONALITY() 才会被清除,所以在 721 行时,当前进程仍认为自己是 32 位的,flush_old_exec() 做了什么事情呢,参看:fs/exec.c: flush_old_exec()
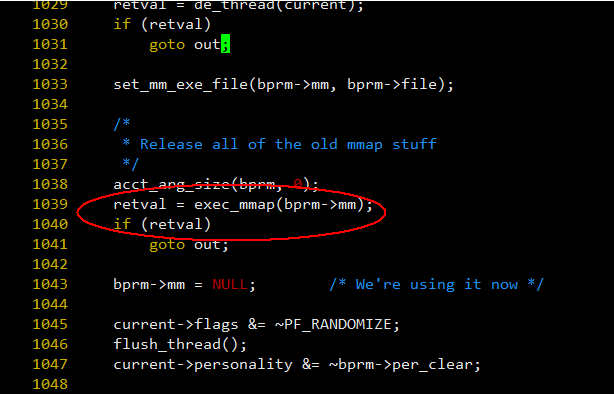
图 - 12
注意其中 1039 行,bprm->mm 表示新的内存空间(旧的还在,但马上就要释放并切换新的),这里需要对新的内存空间进行设置,参看: fs/exec.c: exec_mmap()
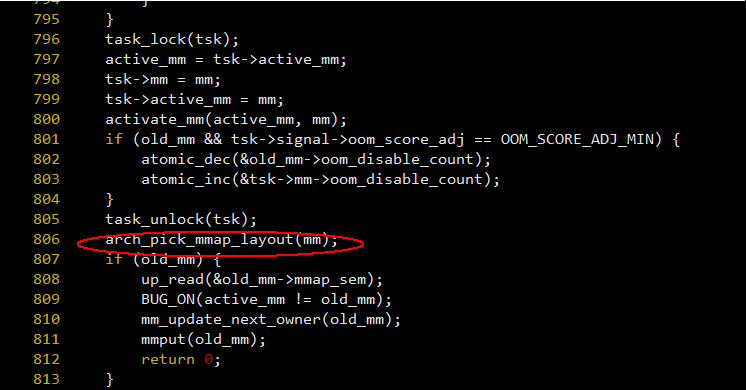
图 - 13
我们可以看到在当前进程还是 32 位的时候,内核对新的内存空间进行了初始化,导致 arch_pick_mmap_layout() 错误地将 arch_get_unmaped_exec_area 赋值给了 bprm->mm->get_unmapped_exec_area 这个成员变量,虽然图-11中 load_elf_binary() 函数在 748 行,32 位的标志被清空之后再次调用 set_up_new_exec() -> arch_get_unmapped_exec_area(),但 arch_get_unmaped_exec_area() 并没有清空 mm->get_unmapped_exec_area 这个变量,导致 execv 后虽然进程是 64 位的,但仍然以 mm->shlib_base 这里作为起始地址搜索内存空间给动态库使用, oops.
解决方案
最直接可靠的做法是在进入 arch_pick_mmap_layout() 时,先把 mm->get_unmapped_exec_area 置为 NULL,但这就要修改内核了,用户态要规避的话有以下方式:
1、设置 ulimit -s unlimited,并设置 exec-shield 为 0 或 1,再起进程,这样一来,因为用户态的栈是无限长的,内核只能以传统的方式来对 32 位进程分配内存,不会掉进 exec-shield 的坑里。
2、把 randomize_va_space
禁掉,但这个做法只是把头埋进了沙子里。
总的来说,上面两种用户态的规避方案基本是哪里疼往哪贴膏药,并非解决问题之道(且有安全隐患),退一步来说,不要用 32 位的进程来起动 64 位进程还相对稳妥点.
参考
【0】en.wikipedia.org/wiki/C_dyna…
【1】access.redhat.com/documentati…
【2】understanding the linux kernel, page 819, flexible memory region layout: books.google.com.hk/books?id=h0…
【3】gist.github.com/CMCDragonka…
【4】lxr.free-electrons.com/source/arch…
【5】 access.redhat.com/blogs/76609…
【6】lwn.net/Articles/31…
【7】lwn.net/Articles/45…
【8】lxr.free-electrons.com/source/fs/b…
【9】lxr.free-electrons.com/source/fs/b…
【10】类似问题: bugzilla.redhat.com/show_bug.cg… bugs.debian.org/cgi-bin/bug…
