

(这里是最终成品的 GitHub 地址)
(这里是本章会用到的 GitHub 地址)
(知乎的无序列表崩了啊岂可修!!!)
========== 写在前面的话 ==========
最近折腾 RNN 时发现 Tensorflow 居然不支持返回所有的 State 而只支持返回最后一个 State……然后我看了源码之后发现在简单的场景下、这功能挺好实现的……然后我就怒 PR 了一下,不知道 Tensorflow 那边会不会 merge(趴
相关数学理论:
* 数学 · RNN(二)· BPTT 算法(这个不看也并无大碍,毕竟 Tensorflow 会帮你处理所有梯度……)
========== 分割线的说 ==========
LSTMs cell 的实现
由于 Tensorflow 中有相应的 RNN 封装,所以我们只需要把 cell 中的“前向传导算法”实现出来即可(这或多或少地参考了 Tensorflow 的源码):
class LSTMCell(tf.contrib.rnn.BasicRNNCell):
def __call__(self, x, state, scope="LSTM"):
with tf.variable_scope(scope):
# 由于有两种 State,所以要用 split 函数把它们分开
s_old, h_old = tf.split(state, 2, 1)
# 算出各个 Gate 的值
gates = layers.fully_connected(
tf.concat([x, s_old], 1),
num_outputs=4 * self._num_units,
activation_fn=None)
# 用 split 函数把各个 Gate 分开
r1, g1, g2, g3 = tf.split(gates, 4, 1)
# 用激活函数作用于各个 Gate 的值
r1 = tf.nn.sigmoid(r1)
g1 = tf.nn.sigmoid(g1)
g2 = tf.nn.tanh(g2)
g3 = tf.nn.sigmoid(g3)
# 照着公式敲即可 ( σ'ω')σ
h_new = h_old * r1 + g1 * g2
s_new = tf.nn.tanh(h_new) * g3
# 用 concat 函数“打包”两种 State
return s_new, tf.concat([s_new, h_new], 1)
@property
def state_size(self):
# 由于有两种 State,所以 State 大小是 Gate 中隐藏神经元的两倍
return 2 * self._num_units
不过虽说定义 cell 的过程比较平凡,调用它却不是一件特别容易的事,我们会通过解决 Mnist 问题来进行相应的演示
定义数据生成器
为了在实现 RNN 封装时代码显得更简洁,定义一个数据生成器来帮助我们 handle 数据是有必要的:
class MnistGenerator:
def __init__(self, im=None, om=None):
self._im, self._om = im, om
self._cursor = self._indices = None
# DataUtil.get_dataset 的实现这里就不赘述了
# 总之它能返回一个打乱后的迷你 Mnist 数据集
self._x, self._y = DataUtil.get_dataset(
"mnist",
"../../_Data/mnist.txt",
quantized=True, one_hot=True
)
# 将输入 reshape 一下,原因会在后文说明
self._x = self._x.reshape(-1, 28, 28)
# 划分训练集和测试集
self._x_train, self._x_test = self._x[:1800], self._x[1800:]
self._y_train, self._y_test = self._y[:1800], self._y[1800:]
# 重新打乱数据集,相当于“刷新”
def refresh(self):
self._cursor = 0
self._indices = np.random.permutation(len(self._x_train))
def gen(self, batch, test=False):
# 如果 batch 为 0、则返回所有训练集(或测试集)
if batch == 0:
if test:
return self._x_test, self._y_test
return self._x_train, self._y_train
# 否则,生成下一个 Batch
end = min(self._cursor + batch, len(self._x_train))
start, self._cursor = self._cursor, end
if start == end:
self.refresh()
end = batch
start = self._cursor = 0
indices = self._indices[start:end]
return self._x_train[indices], self._y_train[indices]
应该还是挺直观的 ( σ'ω')σ
实现 RNN 的封装
为简洁,我们只针对 Mnist 问题进行灵活性比较差的实现,更灵活、应用场合更全面、广泛的实现可以参见这里(比如 One-to-One、Many-to-Many、State concatenating、Embedding、支持输入序列长度、支持指定使用多少历史信息、支持画出训练曲线之类的)
下面就看看一个最基本的封装框架应该如何搭建吧:
class RNNWrapper:
"""
初始化框架
self._generator:存储数据生成器的属性
self._tfx, self._tfy:Tensorflow 的 placeholder
self._output, self._cell:模型的输出和所用的 cell
self._im, self._om, self._hidden_units:
输入、输出维度和 Gate 中隐藏神经元个数
"""
def __init__(self):
self._generator = None
self._tfx = self._tfy = self._output = None
self._cell = self._im = self._om = self._hidden_units = None
self._sess = tf.Session()
def fit(self, im, om, generator, hidden_units=128, cell=LSTMCell):
self._generator = generator
self._im, self._om, self._hidden_units = im, om, hidden_units
self._tfx = tf.placeholder(tf.float32, shape=[None, None, im])
self._tfy = tf.placeholder(tf.float32, shape=[None, om])
self._cell = cell(self._hidden_units)
# 调用相应函数获得各个 Output
rnn_outputs, _ = tf.nn.dynamic_rnn(
self._cell, self._tfx,
initial_state=self._cell.zero_state(
tf.shape(self._tfx)[0], tf.float32
)
)
# 调用相应方法获得模型输出、损失
self._get_output(rnn_outputs)
# 计算
loss = tf.nn.softmax_cross_entropy_with_logits(
logits=self._output, labels=self._tfy
)
train_step = tf.train.AdamOptimizer(0.01).minimize(loss)
self._sess.run(tf.global_variables_initializer())
# 10 个 epoch
# 每个 epoch 循环训练 29 个 Batch
# 每个 Batch 含 64 个数据
# 注意最后一个 Batch 只剩 1800 - 28 * 64 = 8 个数据
for _ in range(10):
# “刷新”一下数据生成器
self._generator.refresh()
# ceil(1800 /
for __ in range(29):
x_batch, y_batch = self._generator.gen(64)
self._sess.run(
train_step,
{self._tfx: x_batch, self._tfy: y_batch})
self._verbose()
其中,self._get_output 这个方法的实现如下:
def _get_output(self, rnn_outputs):
# 利用最后三个 Output 的信息来生成模型的输出
outputs = tf.reshape(
rnn_outputs[..., -3:, :],
[-1, self._hidden_units * 3]
)
self._output = layers.fully_connected(
outputs, num_outputs=self._om,
activation_fn=tf.nn.sigmoid
)
应该还是挺简洁的 ( σ'ω')σ
使用 RNN 解决计算机视觉问题
由于 RNN 接收的是序列数据,所以我们应该想办法把图像转化为序列。一种自然的做法就是:把每一行像素看成一个输入向量,然后输入序列的长度即为图片的行数。以Mnist为例,我们知道其中每个图片都是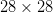 的,那么输入维度和序列长度就都是
的,那么输入维度和序列长度就都是
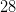 。一般而言,如果某张图片是
。一般而言,如果某张图片是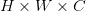 的,亦即:
的,亦即:
- 该图片一共有
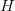 行和
行和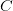 个频道,一般来说
个频道,一般来说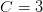 (RGB 通道)、不过我们也不是不可以拿 CNN 的中间结果来喂给 RNN,这样的话就可以很大
(RGB 通道)、不过我们也不是不可以拿 CNN 的中间结果来喂给 RNN,这样的话就可以很大 - 每一行一般视为有
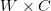 个像素
个像素
那么此时 RNN 的输入维度即为,序列长度即为
在将图像翻译为序列后,剩下要做的无非就是调用上述封装罢了。具体而言:
generator = MnistGenerator()
rnn = RNNWrapper()
rnn.fit(28, 10, generator)
是不是很方便呢 ( σ'ω')σ
对于这个迷你 Mnist 问题而言,我们模型在 GPU 上大概需要 6 秒来完成训练,最终准确率大概在 90% 左右;相比之下,Tflearn 在相同的模型结构、参数、训练强度下,需要 23.5 秒左右才能完成训练,不过它的准确率在 93% 左右……
如果用相同的时间训练的话,我们模型在训练 22.5 秒左右之后能够将准确率稳定在 95% 左右,这说明其表现还是可以的……(Tflearn 可能会记录各种杂七杂八的东西,所以效率相对而言可能就会差一些)
不过调用我们的 RNN 封装的一大问题就是:我们需要花不少时间去定义数据生成器;当然这也不一定是坏处,不过对我这种懒人来说果然还是能够端到端(这里能用“端到端”这个词吧?……)最好
然而由于我太懒所以我不想实现端到端(虽然不难)(喂
希望观众老爷们能够喜欢~
