

背景
在 Web 后端开发过程中,经常需要确认一个远程网络文件是否存在,或者查看文件的大小。
如果直接将文件下载下来,当然可以在本地计算文件大小,但是未免要消耗大量时间和带宽资源。
有没有办法只获取文件大小,但又不用去下载呢?
答案是:可以。
HTTP 协议
在 http response 报文中,主要分为两大块:
- 响应头部
response header - 响应内容
response body
以浏览器请求一张图片为例:
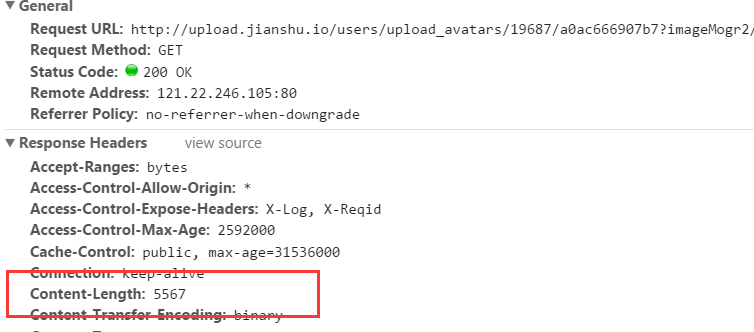
可以看到,响应头包含一个内容长度的字段:
Content-Length:5567所以,只要获取到 http 响应头,就可以知道网络文件的大小了。
在 http 协议中专门定义了 HEAD 请求方法,告知服务器只返回响应头信息,不用返回响应内容。
请求示例:
curl -v -I 'http://upload.jianshu.io/users/upload_avatars/19687/a0ac666907b7?imageMogr2/auto-orient/strip|imageView2/1/w/240/h/240'请求过程和响应:
> HEAD /users/upload_avatars/19687/a0ac666907b7?imageMogr2/auto-orient/strip|imageView2/1/w/240/h/240 HTTP/1.1
> User-Agent: curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.13.1.0 zlib/1.2.3 libidn/1.18 libssh2/1.2.2
> Host: upload.jianshu.io
> Accept: */*
>
< HTTP/1.1 200 OK
< Date: Tue, 23 May 2017 12:21:54 GMT
< Server: openresty
< Content-Type: image/jpeg
< Content-Length: 5567
< Accept-Ranges: bytesPHP
令人欣喜的是,php 已经内置了获取网络资源响应头的方法了:
get_headers();执行命令:
php -r "print_r(get_headers('http://upload.jianshu.io/users/upload_avatars/19687/a0ac666907b7?imageMogr2/auto-orient/strip|imageView2/1/w/240/h/240'));"打印结果:
Array
(
[0] => HTTP/1.1 200 OK
[1] => Date: Tue, 23 May 2017 13:35:38 GMT
[2] => Server: openresty
[3] => Content-Type: image/jpeg
[4] => Content-Length: 5567
[5] => Accept-Ranges: bytes
)问题
看起来 php 中 get_headers 方法很好的执行了 http 协议,只获取了 header 信息。
但是,Nginx日志却显示 get_headers 方法用的是 GET 方法,并不是 HEAD:
127.0.0.1 - - [23/May/2017:21:51:22 +0800] GET /test.html HTTP/1.0 "200" ......事实上,在使用 get_headers之前,你得手动指定用 HEAD 方法:
<?php
// By default get_headers uses a GET request to fetch the headers. If you want to send a HEAD request instead, you can do so using a stream context:
stream_context_set_default(
array(
'http' => array(
'method' => 'HEAD'
)
)
);
$headers = get_headers('http://example.com/test.html');Nginx 日志:
127.0.0.1 - - [23/May/2017:21:51:22 +0800] HEAD /test.html HTTP/1.0 "200" ......总结
在使用 get_headers 获取响应头的时候,默认用的是 GET 方法,这就意味着除了返回头信息外,还有响应内容,这不就是直接下载了么?
事实上,在获取到头信息和少量的响应内容后,get_headers 方法就会主动关闭 tcp 连接,这样就不会把整个文件下载到内存了。
但是,我们的需求毕竟是只获取响应头,所以,在使用 get_headers 的时候建议手动指定 HEAD 请求方法。
还有问题?联系作者微信/微博 @Ceelog
