

- 原文地址:Node.js Child Processes: Everything you need to know
- 原文作者:本文已获原作者 Samer Buna 授权
- 译文出自:掘金翻译计划
- 译者:熊贤仁
- 校对者:CACppuccino, wilsonandusa
如何使用 spawn(),exec(),execFile() 和 fork()
截图来自我的视频教学课程 - Node.js 进阶
Node.js 的单线程、非阻塞执行特性在单进程下工作的很好。但是,单 CPU 中的单进程最终不足以处理应用中增长的工作负荷。
不管你的服务器性能多么强劲,单个线程只能支持有限的负荷。
Node.js 运行于单线程之上并不意味着我们不能利用多进程,当然,也能运行在多台机器上。
使用多进程是扩展 Node 应用的最佳之道。Node.js 天生适合在多节点上构建分布式应用。这是它被命名为 “Node” 的原因。可扩展性被深深烙印进平台,自应用诞生之初就已经存在。
这篇文章是我的 Node.js 视频教学课程的补充。在课程的视频中也讲到了相似的内容。
请注意,在阅读这篇文章之前,你需要对 Node.js 的事件和流有足够的理解。如果还没有,我推荐你先去读下面两篇文章:
子进程模块
我们可以使用 Node 的 child_process 模块来简单地创造子进程,子进程之间可以通过消息系统简单的通信。
child_process 模块通过在一个子进程中执行系统命令,赋予我们使用操作系统功能的能力。
我们可以控制子进程的输入流,并监听它的输出流。我们也可以修改传递给底层 OS 命令的参数,并得到任意我们想要的命令输出。举例来说,我们可以将一条命令的输出作为另一条命令的输入(正如 Linux 中那样),因为这些命令的所有输入和输出都能够使用 Node.js 流来表示。
注意:这篇文章举的所有例子都基于 Linux。如果在 Windows 上,你要切换为它们对应的 Window 命令。
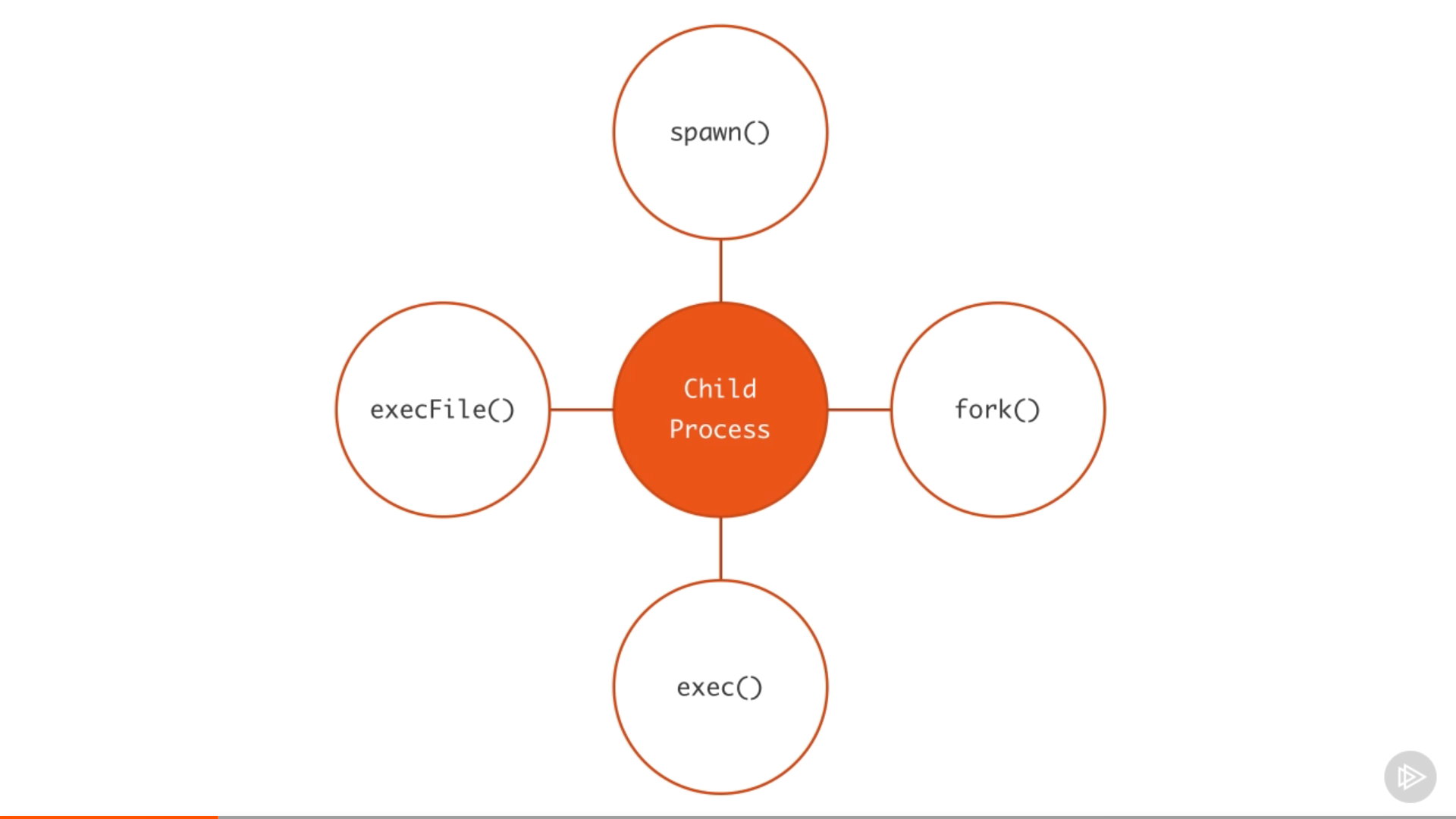
Node.js 里创建子进程有四种不同的方式:spawn(), fork(), exec() 和 execFile()。
我们将学习这四个函数之间的区别及其使用场景。
衍生的子进程
spawn 函数会在一个新的进程中启动一条命令,我们可以使用它来给这条命令传递任意参数。比如,下面的代码会衍生一个执行 pwd 命令的新进程。
const { spawn } = require('child_process');
const child = spawn('pwd');
我们简单地从 child_process 模块中解构 spawn 函数,然后将系统命令作为第一个参数来执行该函数。
spawn 函数(上面的 child 对象)的执行结果是一个 ChildProcess 实例,该实例实现了 EventEmitter API。这意味着我们可以直接在这个子对象上注册事件处理器。比如,当在子进程上注册一个
exit 事件处理器时,我们可以在事件处理函数中执行一些任务:
child.on('exit', function (code, signal) {
console.log('child process exited with ' +
`code ${code} and signal ${signal}`);
});
上面的处理器给出了子进程的退出 code 和 signal,这两个变量可以用来终止子进程。子进程正常退出时 signal 变量为 null。
ChildProcess 实例上还可以注册 disconnect、error、close 和 message 事件。
disconnect事件在父进程手动调用child.disconnect函数时触发。- 如果进程不能被衍生或者杀死,会触发
error事件。 close事件在子进程的stdio流关闭时触发。message事件最为重要。它在子进程使用process.send()函数来传递消息时触发。这就是父/子进程间通信的原理。下面将给出一个例子。
每一个子进程还有三个标准 stdio 流,我们可以分别使用 child.stdin、child.stdout 和 child.stderr 来使用这三个流。
当这几个流被关闭后,使用了它们的子进程会触发 close 事件。这里的 close 事件不同于 exit 事件,因为多个子进程可能共享相同的 stdio 流,因此一个子进程退出并不意味着流已经被关闭了。
既然所有的流都是事件触发器,我们可以在归属于每个子进程的 stdio 流上监听不同的事件。不像普通的进程,在子进程中,stdout/stderr 流是可读流,而 stdin 流是可写的。这基本上和主进程相反。这些流支持的事件都是标准的。最重要的是,在可读流上我们可以监听 data 事件,通过 data 事件可以得到任一命令的输出或者执行命令过程中发生的错误:
child.stdout.on('data', (data) => {
console.log(`child stdout:\n${data}`);
});
child.stderr.on('data', (data) => {
console.error(`child stderr:\n${data}`);
});
上述两个处理器会输出两者的日志到主进程的 stdout 和 stderr 事件上。当我们执行前面的 spawn 函数时,pwd 命令的输出会被打印出来,并且子进程带着代码 0 退出,这表示没有错误发生。
我们可以给命令传递参数,命令由 spawn 函数执行,spawn 函数用上了第二个参数,这是一个传递给该命令的所有参数组成的数组。比如说,为了在当前目录执行 find 命令,并带上一个 -type f 参数(用于列出所有文件),我们可以这样做:
const child = spawn('find', ['.', '-type', 'f']);
如果这条命令的执行过程中出现错误,举个例子,如果我们在 find 一个非法的目标文件,child.stderr data 事件处理器将会被触发,exit 事件处理器会报出一个退出代码 1,这标志着出现了错误。错误的值最终取决于宿主操作系统和错误类型。
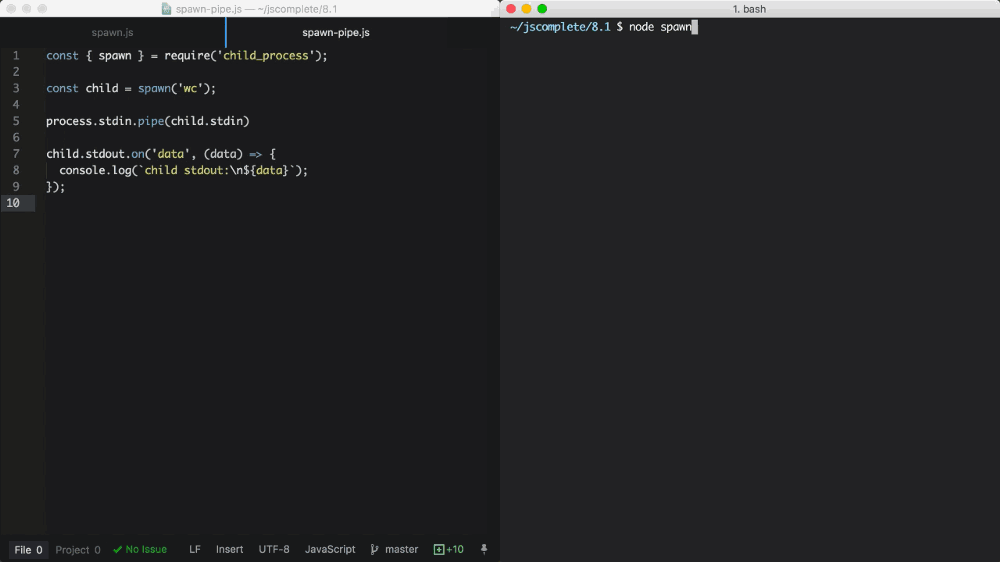
子进程中的 stdin 是一个可写流。我们可以用它给命令发送一些输入。就跟所有的可写流一样,消费输入最简单的方式是使用 pipe 函数。我们可以简单地将可读流管道化到可写流。既然主线程的 stdin 是一个可读流,我们可以将其管道化到子进程的 stdin 流。举个例子:
const { spawn } = require('child_process');
const child = spawn('wc');
process.stdin.pipe(child.stdin)
child.stdout.on('data', (data) => {
console.log(`child stdout:\n${data}`);
});
在这个例子中,子进程调用 wc 命令,该命令可以统计 Linux 中的行数、单词数和字符数。我们然后将主进程的 stdin 管道化到子进程的 stdin(一个可写流)。这个组合的结果是,我们得到了一个标准输入模式,在这个模式下,我们可以输入一些字符。当敲下 Ctrl+D 时,输入的内容将会作为 wc 命令的输入。
Gif 截图来自我的视频教学课程 - Node.js 进阶
我们也可以将多个进程的标准输入/输出相互用管道连接,就像 Linux 命令那样。比如说,我们可以管道化 find 命令的 stdout 到 wc 命令的 stdin,这样可以统计当前目录的所有文件。
const { spawn } = require('child_process');
const find = spawn('find', ['.', '-type', 'f']);
const wc = spawn('wc', ['-l']);
find.stdout.pipe(wc.stdin);
wc.stdout.on('data', (data) => {
console.log(`Number of files ${data}`);
});
我给 wc 命令添加了 -l 参数,使它只统计行数。当执行完毕,上述代码会输出当前目录下所有子目录文件的行数。
Shell 语法和 exec 函数
默认情况下,spawn 函数并不为我们传进的命令而创建一个 shell 来执行,这使得它相比创建 shell 的 exec 函数,效率略微更高。exec 函数还有另一个主要的区别,它缓冲了命令生成的输出,并传递整个输出值给一个回调函数(而不是使用流,那是 spawn 的做法)。
这里给出了之前 find | wc 例子的 exec 函数实现。
const { exec } = require('child_process');
exec('find . -type f | wc -l', (err, stdout, stderr) => {
if (err) {
console.error(`exec error: ${err}`);
return;
}
console.log(`Number of files ${stdout}`);
});
既然 exec 函数使用 shell 执行命令,我们可以使用 shell 语法 来直接利用 shell 管道特性。
当 stdout 参数存在,exec 函数缓冲输出并传递它给回调函数(exec 的第二个参数)。这里的 stdout 参数是命令的输出,我们要将其打印出来。
如果你需要使用 shell 语法,并且来自命令的数据规模较小,exec 函数是个不错的选择。(记住,exec 会在返回之前,缓冲所有数据进内存。)
当命令预期的数据规模比较大时,选择 spawn 函数会好得多,因为数据将会和标准 IO 对象被流式处理。
我们可以令衍生的子进程继承其父进程的标准 IO 对象,但更重要的是,我们同样可以令 spawn 函数使用 shell 语法。下面同样是 find | wc 命令, 由 spawn 函数实现:
const child = spawn('find . -type f', {
stdio: 'inherit',
shell: true
});
因为有上面的 stdio: 'inherit' 选项,当代码执行时,子进程继承主进程的 stdin、stdout 和 stderr。这造成子进程的数据事件处理器在主进程的 process.stdout 流上被触发,使得脚本立即输出结果。
shell: true 选项使我们可以在传递的命令中使用 shell 语法,就像之前的 exec 例子中那样。但这段代码还可以利用 spawn 函数带来的数据的流式。真正实现了共赢。
除了 shell 和 stdio,child_process 函数的最后一个参数还有其他可以的选项。比如,使用 cwd 选项改变脚本的工作目录。举个例子,这里有个和前述相同的统计所有文件数量的例子,它利用 spawn 函数实现,使用了一个 shell 命令,并把工作目录设置为我的 Downloads 文件夹。这里的 cwd 选项会让脚本统计
~/Downloads 里的所有文件数量。
const child = spawn('find . -type f | wc -l', {
stdio: 'inherit',
shell: true,
cwd: '/Users/samer/Downloads'
});
另一个可以使用的选项是 env,它可以指定哪些环境变量对于子进程是可见的。此选项的默认值是 process.env,这会赋予所有命令访问当前进程上下文环境的权限。如果想覆盖默认行为,我们可以简单地传递一个空对象,或者是作为唯一的环境变量的新值给 env 选项:
const child = spawn('echo $ANSWER', {
stdio: 'inherit',
shell: true,
env: { ANSWER: 42 },
});
上面的 echo 命令没有访问父进程环境变量的权限。比如,它不能访问 $HOME 目录,但它可以访问 $ANSWER 目录,因为通过 env 选项,它被传递了一个指定的环境变量。
这里要解释的最后一个重要的子进程选项,detached 选项,使子进程独立于父进程运行。
假设有个文件 timer.js,使事件循环一直忙碌运行:
setTimeout(() => {
// keep the event loop busy
}, 20000);
我们可以使用 detached 选项,在后台执行这段代码:
const { spawn } = require('child_process');
const child = spawn('node', ['timer.js'], {
detached: true,
stdio: 'ignore'
});
child.unref();
分离的子进程的具体行为取决于操作系统。Windows 上,分离的子进程有自己的控制台窗口,然而在 Linux 上,分离的子进程会成为新的进程组和会话的领导进程。
如果 unref 函数在分离的子进程中被调用,父进程可以独立于子进程退出。如果子进程是一个长期运行的进程,这个函数会很有用。但为了保持子进程在后台运行,子进程的 stdio 配置也必须独立于父进程。
上述例子会在后台运行一个 node 脚本(timer.js),通过分离和忽略其父进程的 stdio 文件描述符来实现。因此当子进程在后台运行时,父进程可以随时终止。
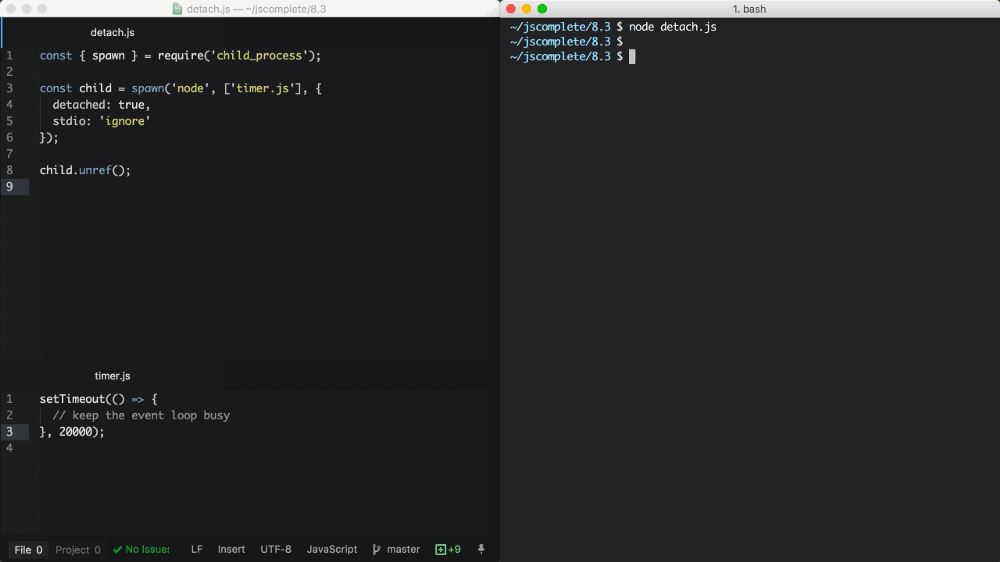
Gif 来自我的视频教学课程 - Node.js 进阶
execFile 函数
如果你不想用 shell 执行一个文件,那么 execFile 函数正是你想要的。它的行为跟 exec 函数一模一样,但没有使用 shell,这会让它更有效率。Windows 上,一些文件不能在它们自己之上执行,比如 .bat 或者 .cmd 文件。这些文件不能使用 execFile 执行,并且执行它们时,需要将 shell 设置为 true,且只能使用 exec、spawn 两者之一。
*Sync 函数
所有 child_process 模块都有同步阻塞版本,它们会一直等待直到子进程退出。
截图来自我的视频教学课程 - Node.js 进阶
这些同步版本在简化脚本任务或一些启动进程任务上,一定程度上有所帮助。但除此之外,我们应该避免使用它们。
fork() 函数
fork 函数是 spawn 函数针对衍生 node 进程的一个变种。spawn 和 fork 最大的区别在于,使用 fork 时,通信频道建立于子进程,因此我们可以在 fork 出来的进程上使用 send 函数,这些进程上有个全局 process 对象,可以用于父进程和 fork 进程之间传递消息。这个函数通过
EventEmitter 模块接口实现。这里有个例子:
父文件,parent.js:
const { fork } = require('child_process');
const forked = fork('child.js');
forked.on('message', (msg) => {
console.log('Message from child', msg);
});
forked.send({ hello: 'world' });
子文件,child.js:
process.on('message', (msg) => {
console.log('Message from parent:', msg);
});
let counter = 0;
setInterval(() => {
process.send({ counter: counter++ });
}, 1000);
上面的父文件中,我们 fork child.js(将会通过 node 命令执行文件),并监听 message 事件。一旦子进程使用 process.send,事实上我们每秒都在执行它,message 事件就会被触发,
为了实现父进程向下给子进程传递消息,我们可以在 fork 的对象本身上执行 send 函数,然后在子文件中,在全局 process 对象上监听 message 事件。
执行上面的 parent.js 文件时,它将首先向下发送 { hello: 'world' } 对象,该对象会被 fork 的子进程打印出来。然后 fork 的子进程每秒会发送一个自增的计数值,该值会被父进程打印出来。
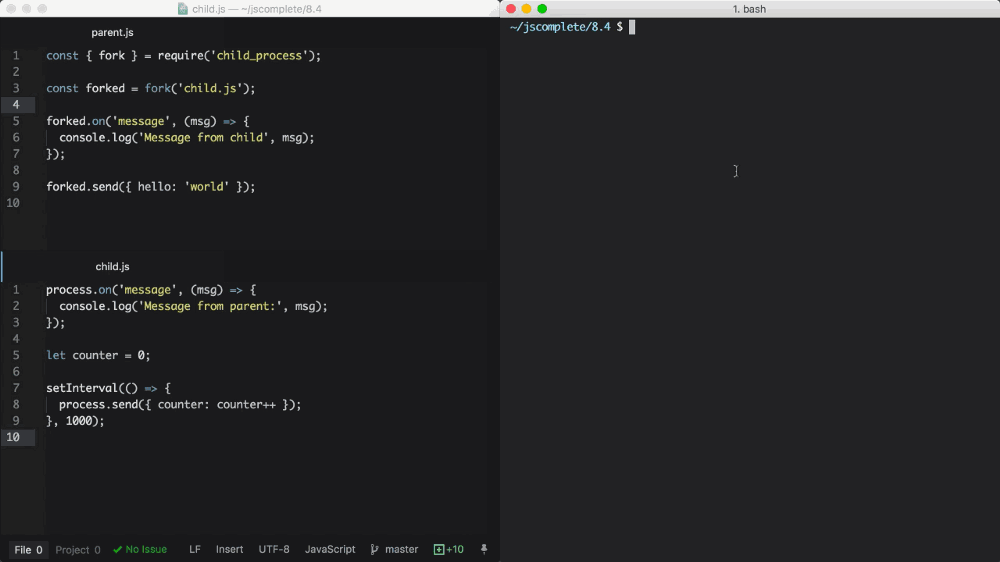
截图来自我的视频教学课程 - Node.js 进阶
我们来用 fork 函数实现一个更实用的例子。
这里有个 HTTP 服务器处理两个端点。一个端点(下面的 /compute)计算密集,会花好几秒种完成。我们可以用一个长循环来模拟:
const http = require('http');
const longComputation = () => {
let sum = 0;
for (let i = 0; i < 1e9; i++) {
sum += i;
};
return sum;
};
const server = http.createServer();
server.on('request', (req, res) => {
if (req.url === '/compute') {
const sum = longComputation();
return res.end(`Sum is ${sum}`);
} else {
res.end('Ok')
}
});
server.listen(3000);
这段程序有个比较大的问题:当 /compute 端点被请求,服务器不能处理其他请求,因为长循环导致事件循环处于繁忙状态。
这个问题有一些解决之道,这取决于耗时长运算的性质。但针对所有运算都适用的解决方法是,用 fork 将计算过程移动到另一个进程。
我们首先移动整个 longComputation 函数到它自己的文件,并在主进程通过消息发出通知时,在文件中调用这个函数:
一个新的 compute.js 文件中:
const longComputation = () => {
let sum = 0;
for (let i = 0; i < 1e9; i++) {
sum += i;
};
return sum;
};
process.on('message', (msg) => {
const sum = longComputation();
process.send(sum);
});
现在,我们可以 fork compute.js 文件,并用消息接口实现服务器和复刻进程的消息通信,而不是在主进程事件循环中执行耗时操作。
const http = require('http');
const { fork } = require('child_process');
const server = http.createServer();
server.on('request', (req, res) => {
if (req.url === '/compute') {
const compute = fork('compute.js');
compute.send('start');
compute.on('message', sum => {
res.end(`Sum is ${sum}`);
});
} else {
res.end('Ok')
}
});
server.listen(3000);
上面的代码中,当 /compute 来了一个请求,我们可以简单地发送一条消息给复刻进程,来启动执行耗时运算。主进程的事件循环并不会阻塞。
一旦复刻进程执行完耗时操作,它可以用 process.send 将结果发回给父进程。
在父进程中,我们在 fork 的子进程本身上监听 message 事件。当该事件触发,我们会得到一个准备好的 sum 值,并通过 HTTP 发送给请求。
上面的代码,当然,我们可以 fork 的进程数是有限的。但执行这段代码时,HTTP 请求耗时运算的端点,主服务器根本不会阻塞,并且还可以接受更多的请求。
我的下篇文章的主题,cluster 模块,正是基于子进程 fork 和负载均衡请求的思想,这些子进程来自大量的 fork,我们可以在任何系统中创建它们。
以上就是我针对这个话题要讲的全部。感谢阅读!下次再见!
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、 React、前端、后端、产品、 设计 等领域,想要查看更多优质译文请持续关注 掘金翻译计划。
