

本文代码的完整例子可以在下面地址下载:
frombeijingwithlove/dlcv_for_beginners
Fast Gradient Sign方法
先回顾一下 瞎谈CNN:通过优化求解输入图像 - 知乎专栏 中通过加噪音生成对抗样本的方法,出自Christian Szegedy的论文《Intriguing properties of neural networks》:
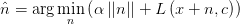
![\text {subject to} \ x+n \in [0,1]^m](https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2017/7/10/3e30446e861456897a9c6420e0ac6ab7~tplv-t2oaga2asx-jj-mark:3024:0:0:0:q75.png)
其中n是要求的噪音,
 是相应的系数,L是x+n属于某个类别的loss,c是某个错误类别的标签。论文中用来得到图像噪声的办法是L-BFGS,这个方法虽然稳定有效,但是很考验算力的,Christian在Google反正机器多又强,用这个方法产生对抗样本自然没有问题,但如果不是土豪的话就不太合适了。针对这个问题,这篇文章的第六作者,生成式对抗网络的发明人Ian
Goodfellow在《Explaining and Harnessing Adversarial Examples》中提出了一种更快速方便的方法来产生对抗样本:
是相应的系数,L是x+n属于某个类别的loss,c是某个错误类别的标签。论文中用来得到图像噪声的办法是L-BFGS,这个方法虽然稳定有效,但是很考验算力的,Christian在Google反正机器多又强,用这个方法产生对抗样本自然没有问题,但如果不是土豪的话就不太合适了。针对这个问题,这篇文章的第六作者,生成式对抗网络的发明人Ian
Goodfellow在《Explaining and Harnessing Adversarial Examples》中提出了一种更快速方便的方法来产生对抗样本: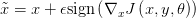
这种方法的思想非常简单,就是让输入图像朝着让类别置信度降低的方向上移动一个在各个维度上都是
 这么大小的一步。因为输入通常是高维的(比如224x224),再加上现在的主流神经网络结构都是ReLU系的激活函数,线性程度其实很高,所以即使是很小的
,每个维度的效果加一块,通常也足以对结果产生很大的影响,比如下面这样:
这么大小的一步。因为输入通常是高维的(比如224x224),再加上现在的主流神经网络结构都是ReLU系的激活函数,线性程度其实很高,所以即使是很小的
,每个维度的效果加一块,通常也足以对结果产生很大的影响,比如下面这样:<img src="https://pic2.zhimg.com/v2-ae1eadf3107819f3adbe4fc26da883dd_b.jpg" data-rawwidth="683" data-rawheight="277" class="origin_image zh-lightbox-thumb" width="683" data-original="https://pic2.zhimg.com/v2-ae1eadf3107819f3adbe4fc26da883dd_r.jpg">在计算上,这种方法优势巨大,因为只需要一次前向和一次后向梯度计算就可以了。Ian Goodfellow称之为
 在计算上,这种方法优势巨大,因为只需要一次前向和一次后向梯度计算就可以了。Ian Goodfellow称之为Fast
Gradient Sign method。
在计算上,这种方法优势巨大,因为只需要一次前向和一次后向梯度计算就可以了。Ian Goodfellow称之为Fast
Gradient Sign method。
用Caffe生成对抗样本
FGS法因为非常简单,用任何框架都很容易实现(Ian Goodfellow有个作为完整工具包的官方实现,基于TensorFlow:openai/cleverhans),这里给出Caffe的Python接口实现的例子。
首先需要准备要攻击的模型,这里我们用在ImageNet数据集上预训练好的SqueezeNet v1.0作为例子:
需要下载两个文件就够了:
因为需要进行后向计算,所以把deploy.prototxt下载后,第一件事是加入下面的一句:
force_backward: true
首先在Caffe中装载准备好的模型定义和参数文件,并初始化读取三通道彩色图片的transformer:
# model to attack
model_definition = '/path/to/deploy.prototxt'
model_weights = '/path/to/squeezenet_v1.0.caffemodel'
channel_means = numpy.array([104., 117., 123.])
# initialize net
net = caffe.Net(model_definition, model_weights, caffe.TEST)
n_channels, height, width = net.blobs['data'].shape[-3:]
net.blobs['data'].reshape(1, n_channels, height, width)
# initialize transformer
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
transformer.set_transpose('data', (2, 0, 1))
transformer.set_mean('data', channel_means)
transformer.set_raw_scale('data', 255)
transformer.set_channel_swap('data', (2, 1, 0))
因为只是演示如何制作对抗样本,为了方便,每次只处理一张图片,接下来就是读取图片并进行前向计算类别置信度,和后向计算梯度,我们用下面的白色小土狗的照片作为输入:
<img src="https://pic4.zhimg.com/v2-f07340bb8772462fca9c5eeac54c2147_b.jpg" data-rawwidth="227" data-rawheight="227" class="content_image" width="227">代码如下:
 代码如下:
代码如下: # Load image & forward
img = caffe.io.load_image('little_white_dog.jpg')
transformed_img = transformer.preprocess('data', img)
net.blobs['data'].data[0] = transformed_img
net.forward()
# Get predicted label index
pred = numpy.argmax(net.blobs['prob'].data.flatten())
# Set gradient direction to reduce the current prediction
net.blobs['prob'].diff[0][pred] = -1.
# Generate attack image with fast gradient sign method
diffs = net.backward()
diff_sign_mat = numpy.sign(diffs['data'])
adversarial_noise = 1.0 * diff_sign_mat
这样用于叠加在原始图片上的对抗样本噪声就好了,在这个代码中,我们执行的是生成一个对抗样本降低当前模型预测类别的,其中每个像素在梯度方向上的前进幅度是1.0。如果要生成一个对抗样本使模型预测图片为一个指定的类别,则需要把给梯度赋值的语句改成下面这句:
net.blobs[prob_blob].diff[0][label_index] = 1.
其中label_index是希望模型错误预测的类别。需要注意的是,用caffe.io.load_image读取的图片是一个值为0到1之间的ndarray,经过transformer的处理之后,得到的新的ndarray中每个像素的值会在0到255之间。另外得到的噪声往往不是最后结果,因为加入到原图片后还得考虑像素值是否会溢出,所以产生最后对抗样本图片的代码如下:
# clip exceeded values
attack_hwc = transformer.deprocess(data_blob, transformed_img + adversarial_noise[0])
attack_hwc[attack_hwc > 1] = 1.
attack_hwc[attack_hwc < 0] = 0.
attack_img = transformer.preprocess(data_blob, attack_hwc)
attack_img就是和Caffe的blob形状一致的对抗样本了,attack_hwc是维度按照图片高度,图片宽度,图片通道顺序的格式,可以用matplotlib直接可视化。
可视化和简单分析
为了方便分析,我们把产生对抗样本的过程打包到一个函数里:
def make_n_test_adversarial_example(
img, net, transformer, epsilon,
data_blob='data', prob_blob='prob',
label_index=None, top_k=5):
# Load image & forward
transformed_img = transformer.preprocess(data_blob, img)
net.blobs[data_blob].data[0] = transformed_img
net.forward()
probs = [x for x in enumerate(net.blobs[prob_blob].data.flatten())]
num_classes = len(probs)
sorted_probs = sorted(probs, key=itemgetter(1), reverse=True)
top_preds = sorted_probs[:top_k]
pred = sorted_probs[0][0]
# if label_index is set,
# generate a adversarial example toward the label,
# else
# reduce the probability of predicted label
net.blobs[prob_blob].diff[...] = 0
if type(label_index) is int and 0 <= label_index < num_classes:
net.blobs[prob_blob].diff[0][label_index] = 1.
else:
net.blobs[prob_blob].diff[0][pred] = -1.
# generate attack image with fast gradient sign method
diffs = net.backward()
diff_sign_mat = numpy.sign(diffs[data_blob])
adversarial_noise = epsilon * diff_sign_mat
# clip exceeded values
attack_hwc = transformer.deprocess(data_blob, transformed_img + adversarial_noise[0])
attack_hwc[attack_hwc > 1] = 1.
attack_hwc[attack_hwc < 0] = 0.
attack_img = transformer.preprocess(data_blob, attack_hwc)
net.blobs[data_blob].data[0] = attack_img
net.forward()
probs = [x for x in enumerate(net.blobs[prob_blob].data.flatten())]
sorted_probs = sorted(probs, key=itemgetter(1), reverse=True)
top_attacked_preds = sorted_probs[:top_k]
return attack_hwc, top_preds, top_attacked_preds
这个函数用caffe.io.load_image读取的ndarray作为输入图片,同时需要net和transformer,epsilon是噪声的幅度,label_index默认为None,此时产生的对抗样本减小当前预测的置信度。如果label_index设置为指定的类别,则产生的对抗样本会尝试增加模型预测为这个类别的置信度。最后函数返回可以被matplotlib直接可视化的对抗样本attack_hwc,模型对原始图片预测的top k类别和对应置信度top_preds,以及模型对对抗样本预测的top k类别和对应置信度top_attack_preds。
上面函数的结果可以用下面函数可视化:
def visualize_attack(title, original_img, attack_img, original_preds, attacked_preds, labels):
pred = original_preds[0][0]
attacked_pred = attacked_preds[0][0]
k = len(original_preds)
fig_name = '{}: {} to {}'.format(title, labels[pred], labels[attacked_pred])
pyplot.figure(fig_name)
for img, plt0, plt1, preds in [
(original_img, 231, 234, original_preds),
(attack_img, 233, 236, attacked_preds)
]:
pyplot.subplot(plt0)
pyplot.axis('off')
pyplot.imshow(img)
ax = pyplot.subplot(plt1)
pyplot.axis('off')
ax.set_xlim([0, 2])
bars = ax.barh(range(k-1, -1, -1), [x[1] for x in preds])
for i, bar in enumerate(bars):
x_loc = bar.get_x() + bar.get_width()
y_loc = k - i - 1
label = labels[preds[i][0]]
ax.text(x_loc, y_loc, '{}: {:.2f}%'.format(label, preds[i][1]*100))
pyplot.subplot(232)
pyplot.axis('off')
noise = attack_img - original_img
pyplot.imshow(255 * noise)
这段代码会同时显示原始图片及模型预测的类别和置信度,对抗样本图片及模型预测的类别和置信度,还有叠加在原始图片上的噪声。另外为了方便直观理解,需要输入每类别的名字,对于ImageNet的数据,可以下载Caffe自带的synset_words.txt,然后把里面的类别按顺序读取到一个列表里即可,下面例子中我们假设这个列表就是labels。
万事俱备,来看看效果,首先尝试用一个幅度为1的噪声降低模型预测的置信度:
attack_img, original_preds, attacked_preds = \
make_n_test_adversarial_example(img, net, transformer, 1.0)
visualize_attack('example0', img, attack_img, original_preds, attacked_preds, labels)
得到结果如下:
&amp;amp;lt;img src="https://pic2.zhimg.com/v2-edeb48d88375ebc8a6533b3e1fb0737d_b.png" data-rawwidth="673" data-rawheight="480" class="origin_image zh-lightbox-thumb" width="673" data-original="https://pic2.zhimg.com/v2-edeb48d88375ebc8a6533b3e1fb0737d_r.png"&amp;amp;gt;因为中华田园犬并不在ImageNet的类别里,所以模型预测的结果是大白熊犬(Great Pyrenees),考虑到小土狗的毛色和外形,这个结果合理,说明SqueezeNet v1.0还是不错的。而经过了1个像素的噪音叠加后,模型预测结果变成了黄鼠狼(weasel)……
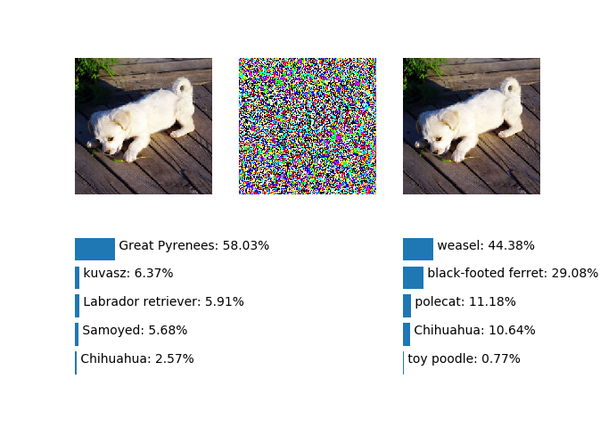 因为中华田园犬并不在ImageNet的类别里,所以模型预测的结果是大白熊犬(Great Pyrenees),考虑到小土狗的毛色和外形,这个结果合理,说明SqueezeNet
v1.0还是不错的。而经过了1个像素的噪音叠加后,模型预测结果变成了黄鼠狼(weasel)……
因为中华田园犬并不在ImageNet的类别里,所以模型预测的结果是大白熊犬(Great Pyrenees),考虑到小土狗的毛色和外形,这个结果合理,说明SqueezeNet
v1.0还是不错的。而经过了1个像素的噪音叠加后,模型预测结果变成了黄鼠狼(weasel)……
接下来试试生成让模型预测为指定类别的对抗样本,既然原始类别是大白熊犬,不妨试试直接预测为真的大白熊,也就是北极熊(ice bear):
attack_img, original_preds, attacked_preds = \
make_n_test_adversarial_example(img, net, transformer, 1.0, label_index=296)
visualize_attack('example1', img, attack_img, original_preds, attacked_preds, labels)
&amp;amp;lt;img src="https://pic2.zhimg.com/v2-51e6bee68b472702fcdcd36195cabfc9_b.png" data-rawwidth="640" data-rawheight="480" class="origin_image zh-lightbox-thumb" width="640" data-original="https://pic2.zhimg.com/v2-51e6bee68b472702fcdcd36195cabfc9_r.png"&amp;amp;gt;从结果来看还是很不错的,而且是个非常高的置信度,不过黄鼠狼又排在了第二。无论是大白熊犬,北极熊还是黄鼠狼,都是哺乳动物,其实外形还是比较类似的,接下来试个难一点的,尝试用幅度为1的噪声把小白狗预测为鸵鸟(ostrich),代码就是把上段代码的label_index换掉,就不再贴了:
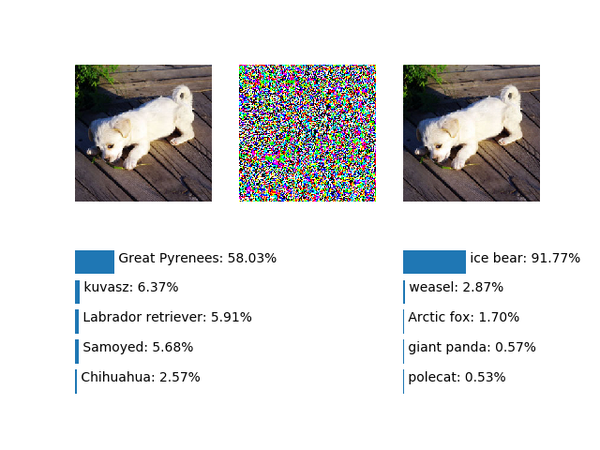 从结果来看还是很不错的,而且是个非常高的置信度,不过黄鼠狼又排在了第二。无论是大白熊犬,北极熊还是黄鼠狼,都是哺乳动物,其实外形还是比较类似的,接下来试个难一点的,尝试用幅度为1的噪声把小白狗预测为鸵鸟(ostrich),代码就是把上段代码的label_index换掉,就不再贴了:
从结果来看还是很不错的,而且是个非常高的置信度,不过黄鼠狼又排在了第二。无论是大白熊犬,北极熊还是黄鼠狼,都是哺乳动物,其实外形还是比较类似的,接下来试个难一点的,尝试用幅度为1的噪声把小白狗预测为鸵鸟(ostrich),代码就是把上段代码的label_index换掉,就不再贴了:
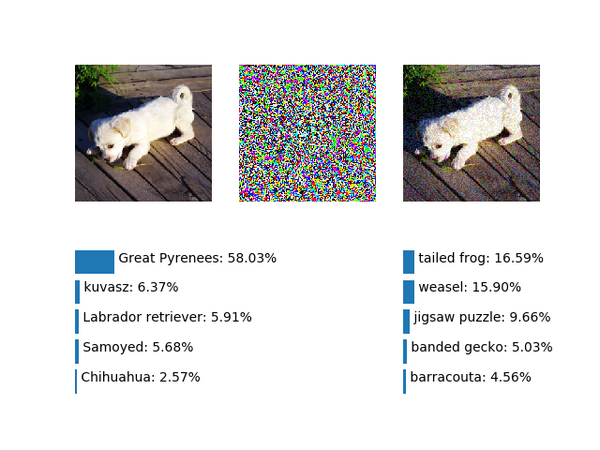
&amp;amp;lt;img src="https://pic4.zhimg.com/v2-5bcff63ee2f91fca0570d69bb849897f_b.png" data-rawwidth="640" data-rawheight="480" class="origin_image zh-lightbox-thumb" width="640" data-original="https://pic4.zhimg.com/v2-5bcff63ee2f91fca0570d69bb849897f_r.png"&amp;amp;gt;仍然是黄鼠狼,所以尝试用更强的噪声,把噪声幅度设为2.0:
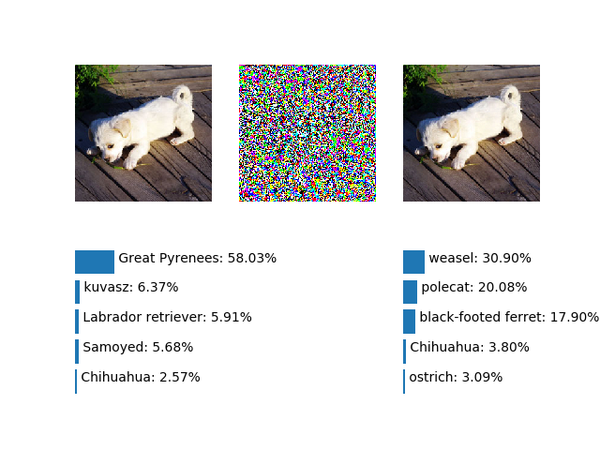 仍然是黄鼠狼,所以尝试用更强的噪声,把噪声幅度设为2.0:
仍然是黄鼠狼,所以尝试用更强的噪声,把噪声幅度设为2.0:
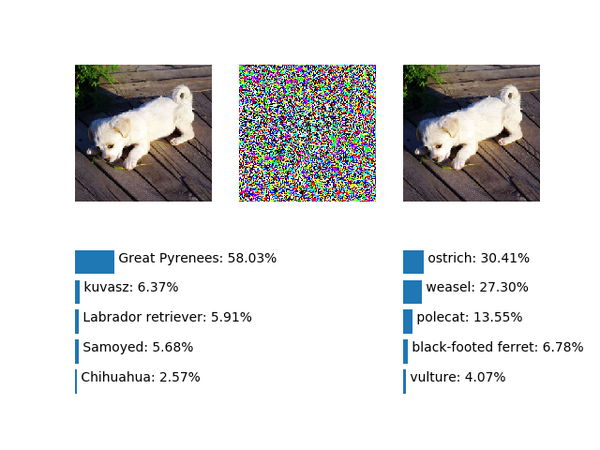
&amp;amp;lt;img src="https://pic3.zhimg.com/v2-f4092a62eac9fb7ff7e0e71a42eca532_b.png" data-rawwidth="640" data-rawheight="480" class="origin_image zh-lightbox-thumb" width="640" data-original="https://pic3.zhimg.com/v2-f4092a62eac9fb7ff7e0e71a42eca532_r.png"&amp;amp;gt;成功了,虽然置信度并不是很高,进一步提升噪声幅度到6.0:
 成功了,虽然置信度并不是很高,进一步提升噪声幅度到6.0:&amp;amp;lt;img src="https://pic4.zhimg.com/v2-e7237e33d28125d84a9a8481023e04df_b.png" data-rawwidth="640" data-rawheight="480" class="origin_image zh-lightbox-thumb" width="640" data-original="https://pic4.zhimg.com/v2-e7237e33d28125d84a9a8481023e04df_r.png"&amp;amp;gt;
成功了,虽然置信度并不是很高,进一步提升噪声幅度到6.0:&amp;amp;lt;img src="https://pic4.zhimg.com/v2-e7237e33d28125d84a9a8481023e04df_b.png" data-rawwidth="640" data-rawheight="480" class="origin_image zh-lightbox-thumb" width="640" data-original="https://pic4.zhimg.com/v2-e7237e33d28125d84a9a8481023e04df_r.png"&amp;amp;gt;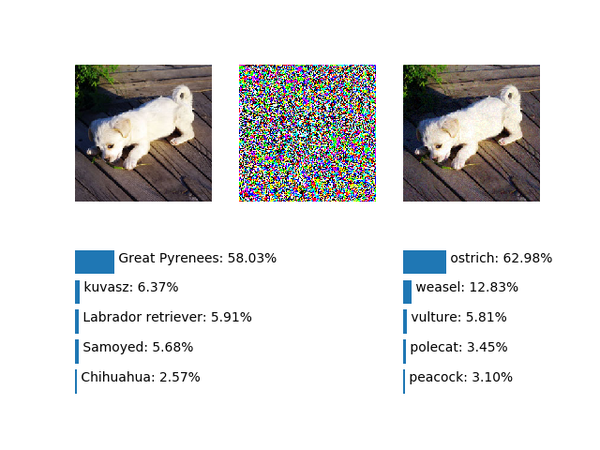
预测为鸵鸟的置信度大幅提升!那么是不是噪声幅度越大,预测为鸵鸟的置信度就越高呢,按照Ian的论文中的图(Fig. 4)似乎是这样的:
&amp;amp;lt;img src="https://pic3.zhimg.com/v2-7108c143a3382b3fc1f4edf1d8511baa_b.jpg" data-rawwidth="608" data-rawheight="464" class="origin_image zh-lightbox-thumb" width="608" data-original="https://pic3.zhimg.com/v2-7108c143a3382b3fc1f4edf1d8511baa_r.jpg"&amp;amp;gt;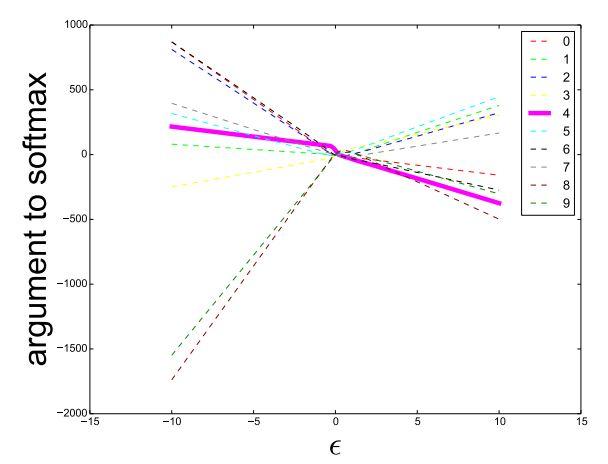
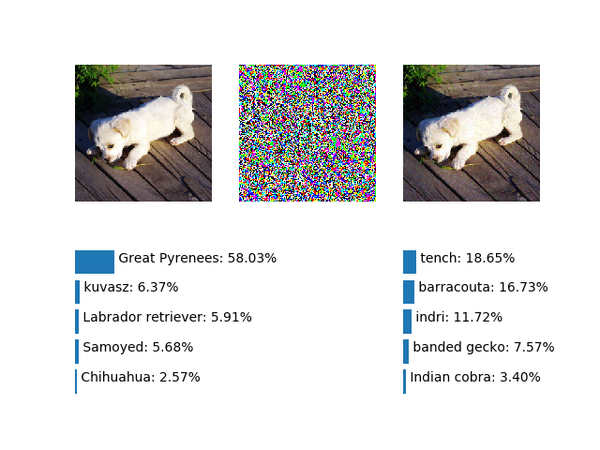
来试试把噪音幅度调到18.0:
&amp;amp;lt;img src="https://pic2.zhimg.com/v2-cfbe566d7f38ec1d6d0bdc51e7cc5da9_b.png" data-rawwidth="640" data-rawheight="480" class="origin_image zh-lightbox-thumb" width="640" data-original="https://pic2.zhimg.com/v2-cfbe566d7f38ec1d6d0bdc51e7cc5da9_r.png"&amp;amp;gt;变成蛤蟆了……Ian的论文中一个主要论点是,在现在流行的深度网络中,对抗样本存在的主因是因为模型的线性程度很高,佐证一个是上面出现过的论文中的fig. 4,还有就是对抗样本在不同模型之间可以泛化。不过为什么线性就是主因了?Ian似乎并没有给出量化的,特别令人信服的证据。事实上原文的fig 4只是在mnist上的一个图示,稍微复杂些的数据上线性程度已经有所减弱,比如Ian自己为kdnuggets写的文章
 变成蛤蟆了……Ian的论文中一个主要论点是,在现在流行的深度网络中,对抗样本存在的主因是因为模型的线性程度很高,佐证一个是上面出现过的论文中的fig.
4,还有就是对抗样本在不同模型之间可以泛化。不过为什么线性就是主因了?Ian似乎并没有给出量化的,特别令人信服的证据。事实上原文的fig 4只是在mnist上的一个图示,稍微复杂些的数据上线性程度已经有所减弱,比如Ian自己为kdnuggets写的文章Deep Learning Adversarial Examples - Clarifying Misconceptions中的配图:&amp;amp;lt;img src="https://pic2.zhimg.com/v2-a86bd53eaa78ebedf3d035081312eb09_b.jpg" data-rawwidth="509" data-rawheight="350" class="origin_image zh-lightbox-thumb" width="509" data-original="https://pic2.zhimg.com/v2-a86bd53eaa78ebedf3d035081312eb09_r.jpg"&amp;amp;gt;
变成蛤蟆了……Ian的论文中一个主要论点是,在现在流行的深度网络中,对抗样本存在的主因是因为模型的线性程度很高,佐证一个是上面出现过的论文中的fig.
4,还有就是对抗样本在不同模型之间可以泛化。不过为什么线性就是主因了?Ian似乎并没有给出量化的,特别令人信服的证据。事实上原文的fig 4只是在mnist上的一个图示,稍微复杂些的数据上线性程度已经有所减弱,比如Ian自己为kdnuggets写的文章Deep Learning Adversarial Examples - Clarifying Misconceptions中的配图:&amp;amp;lt;img src="https://pic2.zhimg.com/v2-a86bd53eaa78ebedf3d035081312eb09_b.jpg" data-rawwidth="509" data-rawheight="350" class="origin_image zh-lightbox-thumb" width="509" data-original="https://pic2.zhimg.com/v2-a86bd53eaa78ebedf3d035081312eb09_r.jpg"&amp;amp;gt;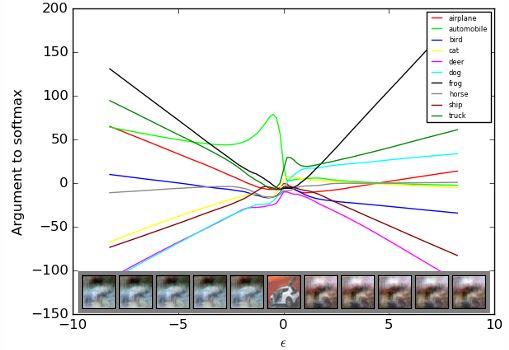
究其本质,对抗样本的存在还是因为高维空间搜索是不可行的,在数据和模型无法触及的角落,对抗样本的出现是很自然的事情。虽然感觉上模型的线性程度,及相应的对输入空间的划分是对抗样本存在的主因,但归因于其他因素的对抗样本也不是可以忽略的,比如小狗变蛤蟆的例子。毕竟神经网络作为universal approximator的根本是源于非线性。
利用迭代更好地生成对抗样本
分类模型虽然没有距离这个概念,但类别间在输入空间上显然还是相似的类别会更近一些,通过上部分的例子也可以看到,狗变成熊或者黄鼠狼相对容易一些,变成鸵鸟就难一点了,变成其他更不相似的比如球拍(Racket)就会更难。我们把鸵鸟对抗样本的四个幅度(1.0, 2.0, 6.0, 18.0)也在生成球拍的对抗样本上试试,结果如下:
&amp;amp;lt;img src="https://pic2.zhimg.com/v2-a0086ecf77adb10ec4aceea43f26cfdd_b.png" data-rawwidth="660" data-rawheight="480" class="origin_image zh-lightbox-thumb" width="660" data-original="https://pic2.zhimg.com/v2-a0086ecf77adb10ec4aceea43f26cfdd_r.png"&amp;amp;gt;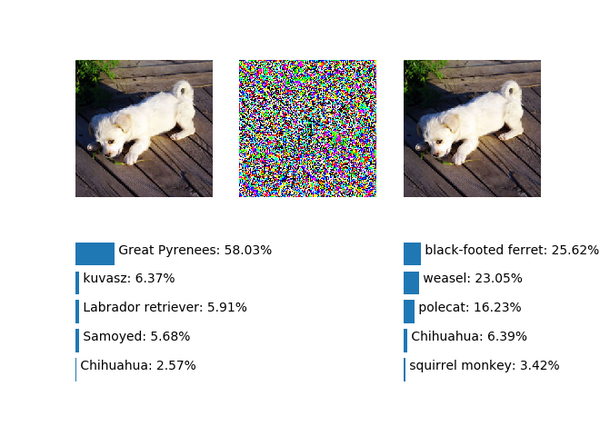 &amp;amp;lt;img src="https://pic2.zhimg.com/v2-3e2e919405f3264addf606c977dd084d_b.png" data-rawwidth="640" data-rawheight="480" class="origin_image zh-lightbox-thumb" width="640" data-original="https://pic2.zhimg.com/v2-3e2e919405f3264addf606c977dd084d_r.png"&amp;amp;gt;
&amp;amp;lt;img src="https://pic2.zhimg.com/v2-3e2e919405f3264addf606c977dd084d_b.png" data-rawwidth="640" data-rawheight="480" class="origin_image zh-lightbox-thumb" width="640" data-original="https://pic2.zhimg.com/v2-3e2e919405f3264addf606c977dd084d_r.png"&amp;amp;gt;
&amp;amp;lt;img src="https://pic2.zhimg.com/v2-4239c3313261de176707e3484d0016e9_b.png" data-rawwidth="640" data-rawheight="480" class="origin_image zh-lightbox-thumb" width="640" data-original="https://pic2.zhimg.com/v2-4239c3313261de176707e3484d0016e9_r.png"&amp;amp;gt;
 &amp;amp;lt;img src="https://pic2.zhimg.com/v2-5fa60a84639e45c4def49dad51778bb1_b.png" data-rawwidth="640" data-rawheight="480" class="origin_image zh-lightbox-thumb" width="640" data-original="https://pic2.zhimg.com/v2-5fa60a84639e45c4def49dad51778bb1_r.png"&amp;amp;gt;经历了黑足鼬(black-footed ferret)、黄鼠狼、丁鲷(tench),最后又变成了蛤蟆。说明线性大法对于这个和小狗差异很大的球拍并不灵。事实上如果用单纯的FGS在很多情况下造对抗样本都是不灵的,也许是因为两个类别差异过大;也许是某个类别类内差异性过大(比如把所ImageNet中所有狗算一类,其他算一类的二分类);甚至最极端的某个类别可能处在ReLU都小于0的“Dead Zone”内。只考虑前两种情况的话,需要比FGS更好更实用的方法。既然FGS直接前进一大步可能是错的,很自然的一个想法是借鉴梯度下降的思路,一步步迭代前进。虽然这样(从梯度方向上)很不线性,而且还要多次计算,不过比起L-BFGS法还是要简单,而且效果拔群。Ian Goodfellow在ICLR 2017的论文《Adversarial Examples in The Physical World》中描述了这种方法,并进一步细分为两种:1)减小预测为原始类别的置信度;2)增大原来被预测为最小可能类别的置信度。
&amp;amp;lt;img src="https://pic2.zhimg.com/v2-5fa60a84639e45c4def49dad51778bb1_b.png" data-rawwidth="640" data-rawheight="480" class="origin_image zh-lightbox-thumb" width="640" data-original="https://pic2.zhimg.com/v2-5fa60a84639e45c4def49dad51778bb1_r.png"&amp;amp;gt;经历了黑足鼬(black-footed ferret)、黄鼠狼、丁鲷(tench),最后又变成了蛤蟆。说明线性大法对于这个和小狗差异很大的球拍并不灵。事实上如果用单纯的FGS在很多情况下造对抗样本都是不灵的,也许是因为两个类别差异过大;也许是某个类别类内差异性过大(比如把所ImageNet中所有狗算一类,其他算一类的二分类);甚至最极端的某个类别可能处在ReLU都小于0的“Dead Zone”内。只考虑前两种情况的话,需要比FGS更好更实用的方法。既然FGS直接前进一大步可能是错的,很自然的一个想法是借鉴梯度下降的思路,一步步迭代前进。虽然这样(从梯度方向上)很不线性,而且还要多次计算,不过比起L-BFGS法还是要简单,而且效果拔群。Ian Goodfellow在ICLR 2017的论文《Adversarial Examples in The Physical World》中描述了这种方法,并进一步细分为两种:1)减小预测为原始类别的置信度;2)增大原来被预测为最小可能类别的置信度。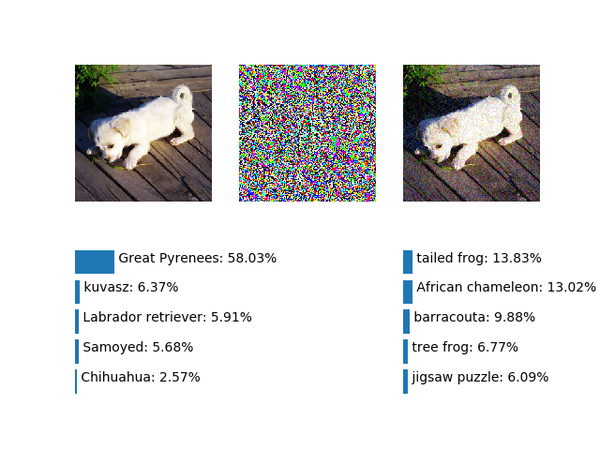 经历了黑足鼬(black-footed ferret)、黄鼠狼、丁鲷(tench),最后又变成了蛤蟆。说明线性大法对于这个和小狗差异很大的球拍并不灵。事实上如果用单纯的FGS在很多情况下造对抗样本都是不灵的,也许是因为两个类别差异过大;也许是某个类别类内差异性过大(比如把所ImageNet中所有狗算一类,其他算一类的二分类);甚至最极端的某个类别可能处在ReLU都小于0的“Dead
Zone”内。只考虑前两种情况的话,需要比FGS更好更实用的方法。既然FGS直接前进一大步可能是错的,很自然的一个想法是借鉴梯度下降的思路,一步步迭代前进。虽然这样(从梯度方向上)很不线性,而且还要多次计算,不过比起L-BFGS法还是要简单,而且效果拔群。Ian Goodfellow在ICLR 2017的论文《Adversarial Examples in The Physical World》中描述了这种方法,并进一步细分为两种:1)减小预测为原始类别的置信度;2)增大原来被预测为最小可能类别的置信度。
经历了黑足鼬(black-footed ferret)、黄鼠狼、丁鲷(tench),最后又变成了蛤蟆。说明线性大法对于这个和小狗差异很大的球拍并不灵。事实上如果用单纯的FGS在很多情况下造对抗样本都是不灵的,也许是因为两个类别差异过大;也许是某个类别类内差异性过大(比如把所ImageNet中所有狗算一类,其他算一类的二分类);甚至最极端的某个类别可能处在ReLU都小于0的“Dead
Zone”内。只考虑前两种情况的话,需要比FGS更好更实用的方法。既然FGS直接前进一大步可能是错的,很自然的一个想法是借鉴梯度下降的思路,一步步迭代前进。虽然这样(从梯度方向上)很不线性,而且还要多次计算,不过比起L-BFGS法还是要简单,而且效果拔群。Ian Goodfellow在ICLR 2017的论文《Adversarial Examples in The Physical World》中描述了这种方法,并进一步细分为两种:1)减小预测为原始类别的置信度;2)增大原来被预测为最小可能类别的置信度。
基于这个思路,我们把第二种方法变通一下,尝试用迭代法增大球拍的置信度,每次迭代0.1,迭代十次:
attack_img, original_preds, attacked_preds = \
make_n_test_adversarial_example(img, net, transformer, 0.1, label_index=752)
for i in range(9):
attack_img, _, attacked_preds = \
make_n_test_adversarial_example(attack_img, net, transformer, 0.1, label_index=752)
visualize_attack('racket_try1'.format(i), img, attack_img, original_preds, attacked_preds, labels)
需要注意外部调用进行迭代的写法效率是不高的,并且每次都包含一次冗余的前向计算。这里这样写只是为了简单,迭代完的结果如下:
&amp;amp;lt;img src="https://pic1.zhimg.com/v2-e43a5ab6c393a684fc844fb581cdac24_b.png" data-rawwidth="640" data-rawheight="480" class="origin_image zh-lightbox-thumb" width="640" data-original="https://pic1.zhimg.com/v2-e43a5ab6c393a684fc844fb581cdac24_r.png"&amp;amp;gt;成功得到了球拍。
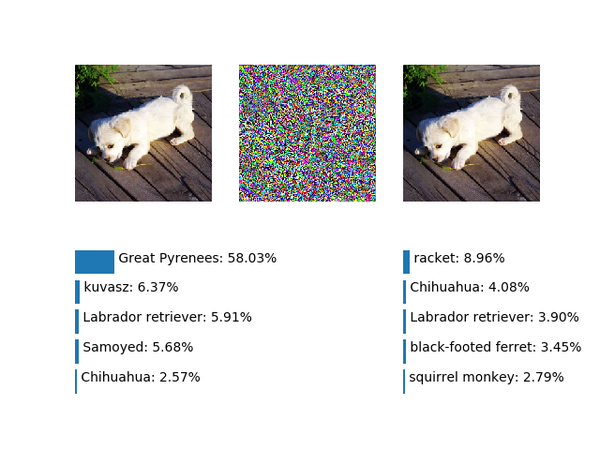 成功得到了球拍。
成功得到了球拍。