

原文: Logging millions of requests everyday and what it takes
HackerEarth的web服务器每天处理数以百万计的请求。这些请求日志可以用来分析挖掘一些对关键业务非常有用的见解和指标,例如,每天的浏览量,每个子产品的浏览量,最受欢迎的用户导航流程等等。
最初的想法
HackerEarth使用Django作为其主要WEB开发框架,并保存一些为性能和可扩展性定制的部件。在正常运行期间,我们的服务器平均每秒处理80-90个请求,而当多个竞争在一个时间差上重叠时,这会激增到每秒200-250个请求。我们需要一个系统,它能够很容易的扩展以满足高峰期流量每秒500个请求。另外,该系统应该添加最小处理开销到web服务器上,而收集到的数据应该存储以用于运算和离线处理。
架构
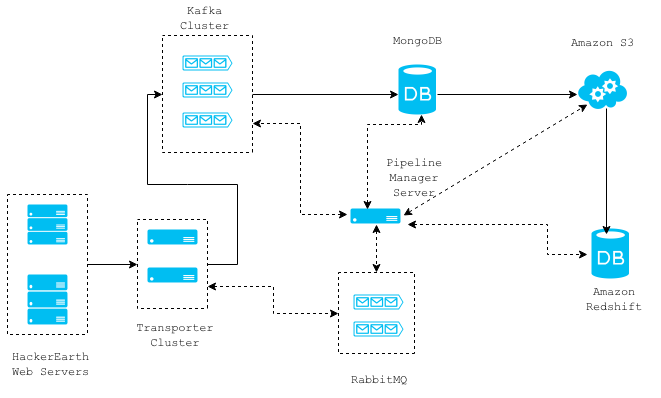
上图显示了我们的请求日志收集系统的高层体系结构。实线代表不同组件之间的数据流,而虚线代表不同组件之间的通信。整个架构是基于消息和无状态,因此各个组件可以很容易地被移除/替换,而无需停机。
下面是一个关于在数据流顺序中的每个元件的更详细解释。
Web服务器
在web服务器上,我们部署了一个Django中间件,它为给定的请求异步检索所需数据,然后将它转发给Transporter集群服务器。这是通过使用一个线程完成的,而该中间件为Django请求/响应循环添加了2毫秒的开销。
class RequestLoggerMiddleware(object):
"""
Logs data from requests
"""
def process_request(self, request):
if settings.LOCAL or settings.DEBUG:
return None
if request.is_ajax():
is_ajax = True
request.META['IS_AJAX'] = is_ajax
before = datetime.datetime.now()
DISALLOWED_USER_AGENTS = ["ELB-HealthChecker/1.0"]
http_user_agent = request.environ.get('HTTP_USER_AGENT','')
if http_user_agent in DISALLOWED_USER_AGENTS:
return None
# this creates a thread which collects required data and forwards
# it to the transporter cluster
run_async(log_request_async, request)
after = datetime.datetime.now()
log("TotalTimeTakenByMiddleware %s"%((after-before).total_seconds()))
return NoneTransporter集群
transporter集群是非阻塞Thrift服务器阵列,用于从web服务器接收数据,然后将其路由到任何其他诸如MongoDB, RabbitMQ, Kafka这样的组件这一唯一目的。一条给定的消息应该被路由到哪里是来自于web服务器的消息自身指定的。从web服务器到transporter服务器的通信只有唯一一种方式,而这节省了花费在确认由thrift服务器接收的信息上的一些时间资源。由于这个原因,我们可能会失去一些请求日志,但是这样值得。当前,请求日志被路由到Kafka集群。web服务器和transporter服务器之间的通信平均花费1-2毫秒,并且可以水平缩放以处理负载的增加。
以下是thrift配置文件的一部分。该文件定义了一个DataTransporter服务,支持作为一个修改器的带oneway的方法,这基本上意味着RPC调用将会立即返回。
service DataTransporter {
oneway void transport(1:map<string, string> message)
}Kafka集群
Kafka是一个支持发布/订阅消息模式的高通量分布式消息系统。这种消息传递基础结构使我们能够建立一个依赖于该流请求日志的其他管线。我们的Kafka集群保存15天有意义的日志,所以我们可以让我们实现的任何新的消费者开始处理数据15天内的任何数据。
Pipeline管理服务器
这个服务器管理来自Kafka topics的请求日志消息的消费,将其存储在MongoDB中,然后将它们移动到Amazon S3以及Amazon Redshift。MongoDB仅作为从Kafka topics消费的数据的分段区域,而该数据每隔一小时被转移到S3。每个保存到S3的文件被加载到Amazon Redshift这一可以扩展到数据PB级的数据仓库解决方案。我们使用Amazon Redshift来分析/度量来自请求日志数据的计算。该服务器与一个 RabbitMQ集群协同工作,这个集群被用来对任务完成和启动进行通信。
下面是从S3加载数据到Redshift的脚本。该脚本首先通过移除任何重复行,然后插入新数据来处理重复数据的插入。
import os
import sys
import subprocess
from django.conf import settings
def load_s3_delta_into_redshift(s3_delta_file_path):
"""s3_delta_file_path is path after the bucket
name.
"""
bigdata_bucket = settings.BIGDATA_S3_BUCKET
attrs = {
'bigdata_bucket': bigdata_bucket,
's3_delta_file_path': s3_delta_file_path,
}
complete_delta_file_path = "s3://{bigdata_bucket}/{s3_delta_file_path}".format(**attrs)
schema_file_path = "s3://{bigdata_bucket}/request_log/s3_col_schema.json".format(**attrs)
data = {
'AWS_ACCESS_KEY_ID': settings.AWS_ACCESS_KEY_ID,
'AWS_SECRET_ACCESS_KEY': settings.AWS_SECRET_ACCESS_KEY,
'LOG_FILE': complete_delta_file_path,
'schema_file_path': schema_file_path
}
S3_REDSHIFT_COPY_COMMAND = " ".join([
"copy requestlog_staging from '{LOG_FILE}' ",
"CREDENTIALS 'aws_access_key_id={AWS_ACCESS_KEY_ID};aws_secret_access_key={AWS_SECRET_ACCESS_KEY}'",
"json '{schema_file_path}';"
]).format(**data)
LOADDATA_COMMAND = " ".join([
"begin transaction;",
"create temp table if not exists requestlog_staging(like requestlog);",
S3_REDSHIFT_COPY_COMMAND,
'delete from requestlog using requestlog_staging where requestlog.row_id=requestlog_staging.row_id;',
'insert into requestlog select * from requestlog_staging;',
"drop table requestlog_staging;",
'end transaction;'
#'vacuum;' #sorts new data added
])
redshift_conn_args = {
'host': settings.REDSHIFT_HOST,
'port': settings.REDSHIFT_PORT,
'username': settings.REDSHIFT_DB_USERNAME
}
REDSHIFT_CONNECT_CMD = 'psql -U {username} -h {host} -p {port}'.format(**redshift_conn_args)
PSQL_LOADDATA_CMD = '%s -c "%s"'%(REDSHIFT_CONNECT_CMD, LOADDATA_COMMAND)
returncode = subprocess.call(PSQL_LOADDATA_CMD, shell=True)
if returncode !=0:
raise Exception("Unable to load s3 delta file into redshift ",
s3_delta_file_path)下一步
对于任何Web应用程序,数据就像金子。若以正确的方式处理,那么它可以提供的洞察以及它可以驱动的增长是惊人的。使用请求日志,可以构建几十个的功能和见解,包括推荐引擎,更好的内容交付,并提高产品的整体构建。所有这一切都有助于使HackerEarth更好的服务于我们的用户。
如果你有任何疑问,或者希望更多地讨论这个架构或者涉及的任意技术,可以给我发邮件:praveen@hackerearth.com。
