偶然干这件事是因为同事发给我们一个百度知道的链接,让我们帮忙点赞,刚开始觉得下不为例,第一次点下以后就不用点了,后来第二天又要我们帮忙接着点,我就想是否能有更简便的方法来实现这件事,我最开始的想法是找几个百度的账号,然后登录点赞。
偶然间,同事说百度知道不用登录也可以点赞。我后来尝试了一下发现确实是这样。心想,那这就是限制IP的。果不其然。后来发现百度知道点赞的规则大概是这样。每个IP每天可以点赞一次。于是我直接能想到的方法那就是更换IP点赞。
其实我当时还有一个想法,那就是找到它的API,但很快想到,以百度的技术,肯定不会这么轻易的暴露API的。所以还是老老实实的用chrom浏览器+webdriver好了。
我的实现方法分两部分,一个是找IP,一个是换IP。
一、找IP,建立IP池
http://www.xicidaili.com/nn/1
上可以找到很多代理IP,有些IP可以用,有些IP不能用,免费的就凑合用吧,用起来还是够用的。其中的https的IP,有效的居多,然后把这些IP地址和端口号爬下来。
具体代码如下:
#encoding=utf8
import urllib2
import BeautifulSoup
User_Agent = 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0'
header = {}
header['User-Agent'] = User_Agent
url = 'http://www.xicidaili.com/nn/1'
req = urllib2.Request(url,headers=header)
res = urllib2.urlopen(req).read()
soup = BeautifulSoup.BeautifulSoup(res)
ips = soup.findAll('tr')
f = open("test.txt","w")
for x in range(1,len(ips)):
ip = ips[x]
tds = ip.findAll("td")
ip_temp = tds[1].contents[0]+"\t"+tds[2].contents[0]+"\n"
# print tds[2].contents[0]+"\t"+tds[3].contents[0]
f.write(ip_temp)
直接抓取td的标签,然后把爬到的ip和端口号写入test.txt文件。
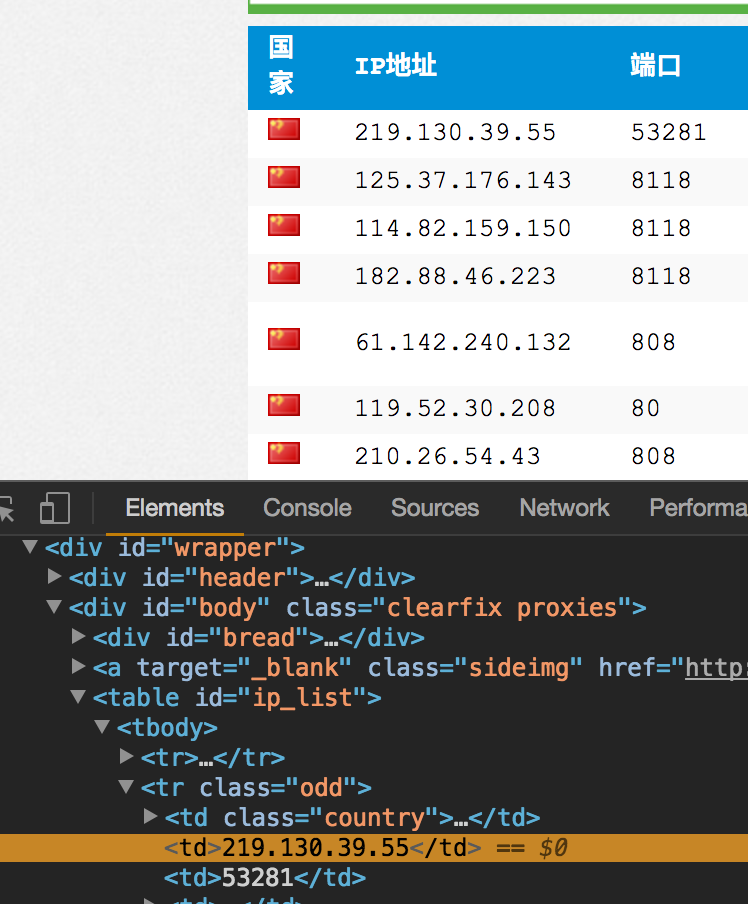
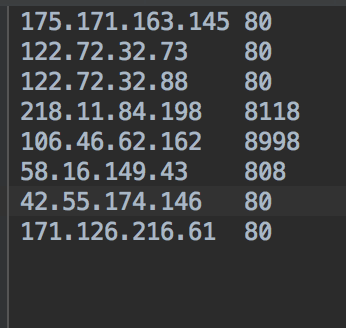
譬如,爬到的数据
二、更换IP访问,模拟点赞操作
先上代码
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
#从IP池中取出IP和接口
host=[]
port=[]
proxys=[]
#从IP池中取出IP和接口
with open('test.txt','r') as f0:
for i in f0:
tmp=i.split()
host.append(tmp[0])
port.append(tmp[1])
for h,p in zip(host,port):
PROXY = h+":"+p
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--proxy-server={0}'.format(PROXY))
chrome = webdriver.Chrome(executable_path='/Users/mac/Desktop/chromedriver', chrome_options=chrome_options)
try:
#访问要点赞的百度知道的网址
chrome.get('https://zhidao.baidu.com/question/621673501705715932.html')
#点赞的按钮的ID是固定的,找到对应答案的点赞按钮的ID
WebDriverWait(chrome, 20).until(EC.visibility_of_element_located((By.ID, 'evaluate-2796284381')))
elem = chrome.find_element_by_id("evaluate-2796284381").click()
#如果IP不能使用,抛出异常,程序继续循环执行
except Exception, e:
print PROXY
print e
continue
做过web自动化测试或者爬虫的,对selenium应该不会很陌生。加入WebDriverWait是因为在实际使用过程中,发现等待网页加载出来,会需要一段时间。怎么说,也是好歹能用。
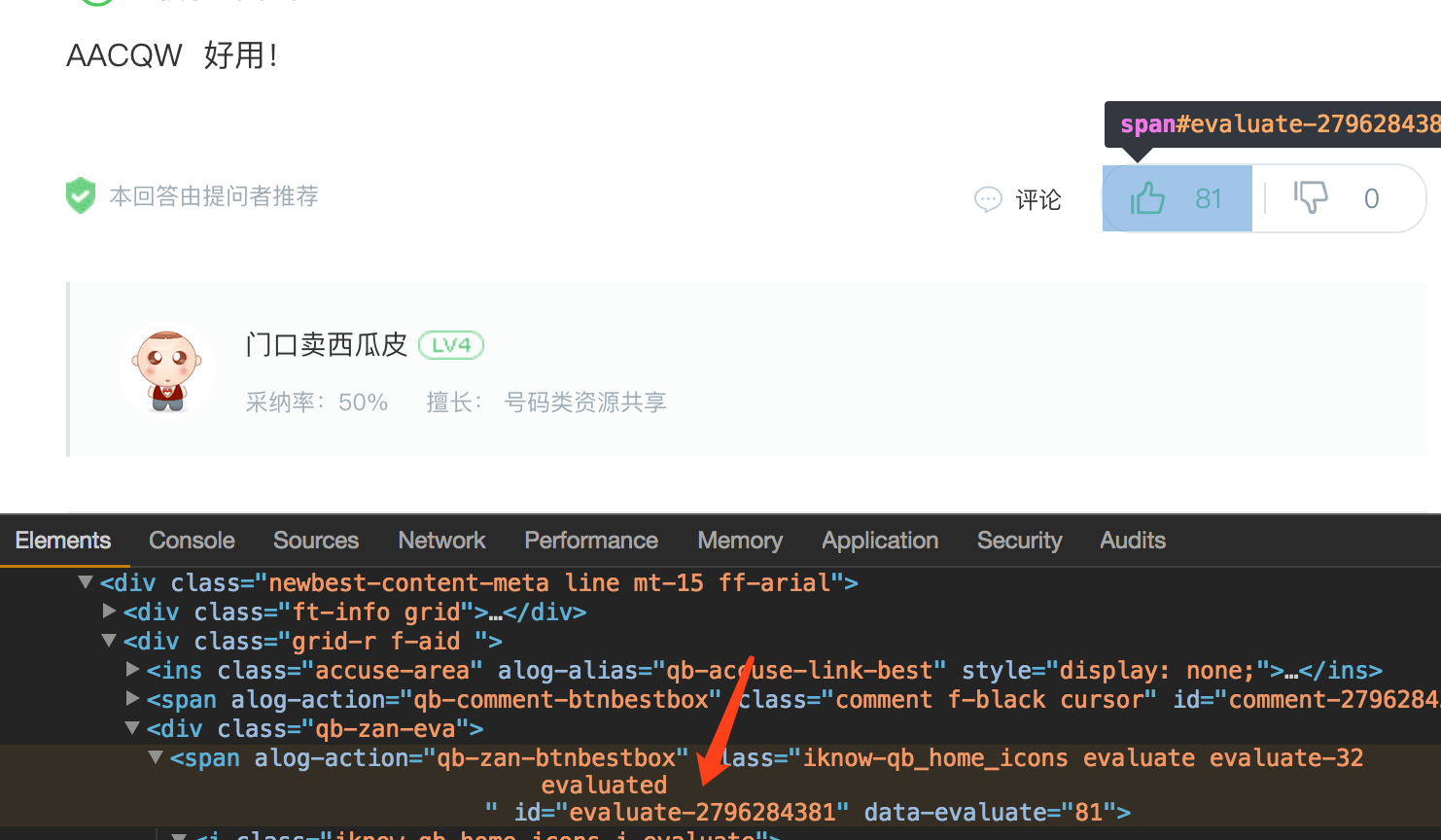
找点赞按钮的ID
这个脚本花了两个下班后晚上编译加调试。脚本不白写,送给同事后,喝到了人生中的第一杯星巴克。