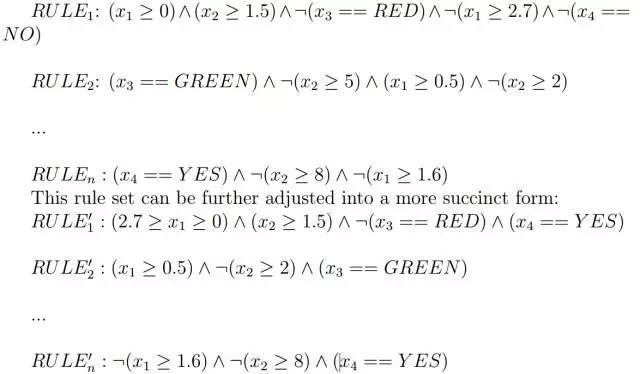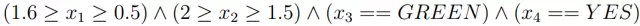翻译 | AI科技大本营(rgznai100)
参与 | 周翔、reason_W成龙,Shawn
今年 2 月,南京大学的周志华教授和他的学生 Ji Feng 提出了一种不同于深度神经网络(DNN)的 Deep Forest 模型——gcForest,这是一种决策树集成的方法,较之深度神经网络有很强的竞争力。深度神经网络需要花大力气调参,相比之下 gcForest 要容易训练得多。此外,深度神经网络需要大规模的训练数据,而 gcForest 在仅有小规模训练数据的情况下也照常运转。不仅如此,作为一种基于决策树的方法,gcForest 在理论分析方面也应当比深度神经网络更加容易。
半年之后,这两位学者又跟 DNN 杠上了,提出了首个基于决策树集成(Tree Ensamble)算法的自动编码器——EncoderForest (简称 eForest)。
通常,自动编码这个重要任务都是通过卷积神经网络(CNN)等深度神经网络(DNN)来实现的。但是周志华教授在论文中表示,他们提出的这种算法可以使森林(forests)能够利用决策树决策路径(decision paths)定义的等效类(equivalent classes)别来进行反向重构(backward reconstruction),并且证明了这种算法在监督学习和无监督学习中的可行性。
实验结果表明,与 DNN 自动编码器相比,eForest 能够不仅训练速度更快,而且数据重构的错误率根底,此外,模型本身对损坏有一定的容忍度,并且可以重复使用。
不管是 gcForest 还是 eForest,这种基于决策树集成的方法真的有取代 DNN 的潜力吗?让我们一起看看这篇论文,或许你会有更好的了解。
(注:本文截取论文重点进行编译,非全文编译。如需观摩原文,请查阅文末链接)
简介
自动编码器这类模型的作用是将输入映射到隐藏空间,然后再将其映射到原始空间,期间,重构失误率越小越好。在过去,构建这样的模型往往需要用到神经网络。例如,基于神经网络的自动编码器通常由一个编码器和一个解码器构成。编码器将输入映射到隐藏层,然后解码器将输入映射到输入空间。通过将这两步连接在一起,并将重构错误作为学习目标,我们可以使用反向传播算法来训练此类模型。这种算法被广泛应用于降维、表征学习以及生成模型近期的一些工作(例如变分自动编码器)。
集成学习(Ensemble learning)是一种强大的学习方式,它可以训练多个学习网络,并将它们结合起来处理问题。它广泛应用于很多种任务,并且都有着很好的表现。决策树集成算法或者森林算法(如随机森林)是适用于监督学习的最好方法之一。其他成功的决策树集成算法还有基于梯度的决策树(gradient based decision trees ,GBDT),这种算法的效果在过去 10 年间得到了很好的证明。除了监督学习任务之外,决策树集成算法还在其他任务中大显身手,例如isolation forest,这是一种可以有效检测异常的无监督学习方法。另外,最近提出的基于森林的深度模型也在多种任务中表现出与 DNN 比肩的性能,但是它的超参数数量更少。
在本论文中,我们提出了 eForest,它可以使决策树集成算法执行向前编码和向后解码的操作,这种自动编码器既能以监督学习又可以以无监督学习的方式进行训练。实验证明,eForest 有以下优势:
准确:它在实验中的重构错误率比基于多层感知器(MLP)或卷积神经网络(CNN)的自动编码器更低。
高效:eForest 在 KNL(多核 CPU)上的运行速度甚至比 CNN 自动编码器在 Titan-X GPU 上训练速度还快。
对损坏的容忍度:训练后的模型即使有部分损坏也能正常工作。
可重复利用:用一个数据集训练的模型可以被直接应用在相同域中的其他数据集上。
方法
自动编码器有两个基本功能:编码和解码。对森林来说,编码是没有困难的,因为至少上面的叶节点信息就可以被认为是一种编码方式;更不用说,节点的子集或者甚至路径分支都能够提供更多的编码信息。
首先,我们给出了 EncoderForest 的编码过程。给定一个训练过的 T 棵树的决策树集成模型( tree ensemble model),前向编码过程用来接收输入数据,并将该数据传递给集成中每棵树的根节点。一旦数据遍历完所有树的叶节点,程序将返回一个 T 维向量,其中每个元素 t 是对应的树 t 中叶节点的整数索引。
算法 1 展示了一种更具体的前向编码算法。需要注意的是,对于树来说,该编码过程与涉及到如何分割节点的特定学习规则是相互独立的。例如,决策规则既可以在诸如随机森林这样的监督集合中学习,也可以在比如完全随机树这样的无监督集合中学习。
另一方面,解码功能则没有那么明显。事实上,森林通常用于从每棵树的根节点到叶子的前向预测,而如何进行后向重建则是不清楚的,例如,如何通过叶子获得的信息合成原始样本。
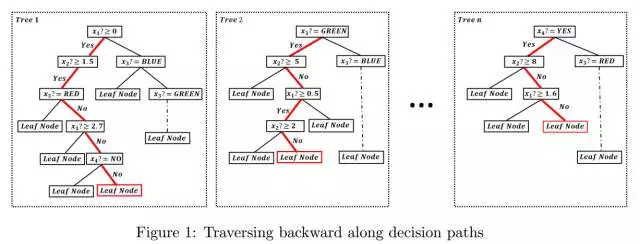
假设我们正在处理一个具有四个属性的二元分类任务。第一个和第二个属性是数字属性,第三个是布尔属性,值为 YES 或 NO;第四个是三值属性值为 RED、BLUE 或 GREEN。给定一个对象 x,令 xi 表示 x 的第 i 个属性的值。
现在,假设在编码步骤中,我们已经生成了一个图1所示的森林。现在,我们只知道对象 x 所在的叶节点,即图一中的红色节点,并且希望重构 x。在这里,我们提出了一个有效但简单、甚至是最简单的森林后向重建策略。首先,每个叶节点实际上都对应于一条来自根节点的路径,我们可以根据叶节点识别路径,同时避免不确定性。
例如,在图1中,识别出来的路径用红色突出显示。然后,每个路径对应一个符号规则;比如,突出显示的树形路径对应以下规则集,RULEi 对应森林中第 i 个树的路径,其中符号“:”表示否定判断:
然后,我们可以推导出最大相容规则(MCR)。MCR 是这样一个规则,即每个成员的覆盖范围都不能被放大,否则就会发生不兼容的问题。例如,从上面的规则集中,我们可以得到这样的 MCR:
对于 MCR 的每个组成部分,如(2 ≥ x2 ≥ 1:5),它的覆盖范围都不能扩大;比如,如果将其放大到(3 ≥ x2 ≥ 1:5),它就会与 RULE2 中的条件(x2 ≥ 2)冲突。算法2对这一规则给出了更详细的描述。
以下定理的证明非常容易,因此我们在本文中省略了证明过程。
定理1:原始样本必须位于由 MCR 定义的输入区域中。
所以,在获得 MCR 后,我们才可以重建原始样本。对于诸如 x3 和 x4 的这样的分类属性来说,原始样本在 MCR 中必须取这些值;对于数值属性来说,如 x2,我们可以选择其中具有代表性的值,如(2, 1.5)中的平均值。因此,重建后的样本就是 x = [0.55, 1.75, GREEN, YES]。注意,对于数值属性来说,我们有很多替代的方法都可以进行重建,比如中值、最大值、最小值,甚至可以计算它的直方图。
鉴于以上描述,现在我们给出 eForest 的后向解码过程。具体来说,给定一个训练好的 T 棵树的森林,同时对一个特定数据,有 RT(T 为上标)中的前向编码 xenc(enc 为下标)。后向解码将首先通过 xenc 中的每个元素定位单个叶节点,然后对于对应的决策路径,获得相应的 T 个决策规则。 然后,通过计算 MCR,我们可以将 xenc 返回给输入区域中的 xdec。算法3中给出了具体的算法。
通过前向编码和后向编码操作,eForest 就可以实现自动编码任务。另外,尽管超出了本文的范围,eForest 模型可能给出一些关于决策树集成模型的表征学习能力的理论性的洞察,并且有助于设计深层森林的新模型。
实验
1)图像重建
我们分别评测了 eForest 在监督集合和非监督集合里的表现。在实验中,我们采用随机森林(Random Forest)来构建监督森林(supervised forest),采用完全随机森林来(completely-random forest )构建非监督森林(unsupervised forest)。
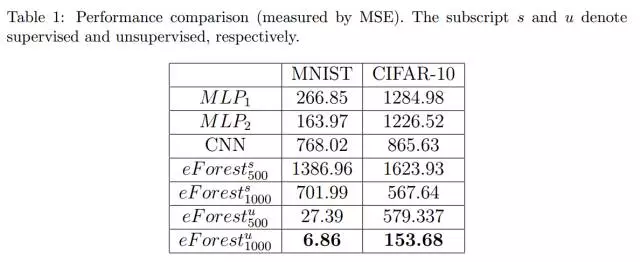
可以看出,eForest 的表现最好。我们使用了 Keras 文档推荐的用于图像自动编码的架构,并通过交叉验证仔细调试了其他的超参数,但是在 CIFAR-10 数据集上,基于 CNN 的自动编码器的表现并不好。我们相信,DNN 自动编码器可以通过进一步的调整来提高性能,不过,eForest 自动编码器不需要精心调整参数就可以表现的很好。
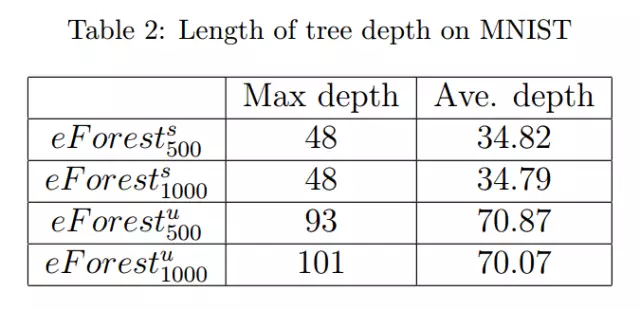
值得注意的是,在具有相同的 trees 的情况下,非监督 eForest 比监督 eForest 表现更好。请注意,每个决策树路径都对应着一个规则,而较长的规则意味着更加严格定义的 MCR。我们推测,更严格的 MCR 可能会让重建更加准确。因此,具有较长的 tree depth 的森林可能会有更好的表现。
实验结果也正面支持了我们的推测。如表2所示,非监督 eForest 的平均深度确实更长。
2)文字重建
注意,DNN 自动编码器主要用于图像,如果要用在文本领域,则需要增加一些额外的机制,比如通过嵌入 word2vec 对文字进行预处理。在本次实验中,我们想要研究模型直接在文本数据上自动编码的性能表现。
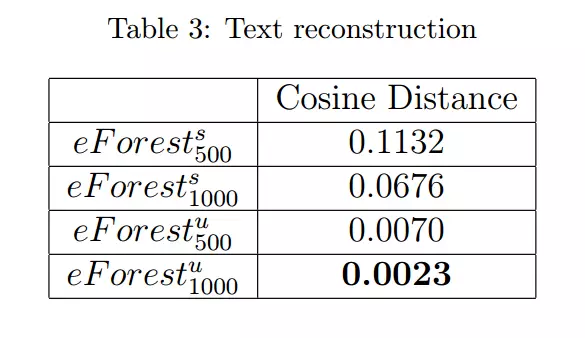
我们将余弦距离(Cosine distance)作为评判标准,余弦距离越小越好。
从上述结果可以看出,eForest 在文本数据重建任务中也有着上佳的表现。另外要注意的是,仅仅使用 10% 的表征位数(bits),eForest 就已经能够非常准确地重建原始输入。这个结果展示了 eForest 在压缩数据方面的前景。
3)计算效率
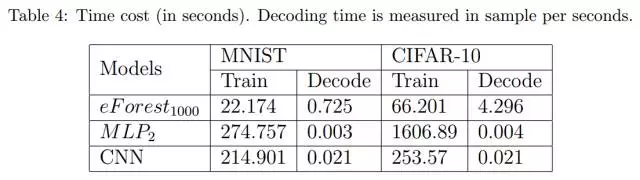
作为树组合模型的共通优势,并行实现同样也适用于 eForest。我们在单个 KNL-7250(英特尔 XEON Phi 多核产品系列)上运行 eForest,与串行计算相比,我们在无监督集合中训练 1000 棵决策树时实现了 67.7 倍的加速。
从表4中可以看出,与基于 DNN 的自动编码器相比,eForest 的训练速度快 100 倍,但是编码速度却更慢。我们希望未来通过优化可以加速 eForest 的解码速度。
4)对的损坏的容忍度
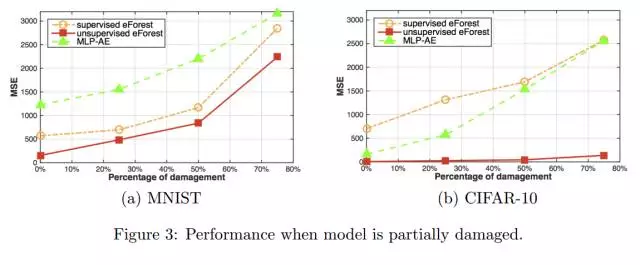
在某些情况下,模型会因为各种原因(如内存或磁盘故障)而部分损坏。然而,如果这种模型在受到损坏的情况下仍然能够运行,那么说明这个模型具备鲁棒性。而 eForest 的自动编码天生就具备鲁棒性,因为在森林只有一个树的子集的时候,我们仍然可以预测 MCR。
上图的结果表明,与 MLP-AE 相比,eForest 对损坏的容忍度更高,其中,又数 unsupervised eForest 的表现最好。
5)eForest的模型重用性
在开放的环境中,用于编码/解码的测试数据可能和训练数据具有不同的分布。在本节中,我们测试了模型重复使用的能力,其目的是在一个数据集中训练一个模型,并在另一个数据集中重用它,而无需任何修改或者重新训练。在这种情况下,模型重用的能力是未来机器学习发展的重要特性。
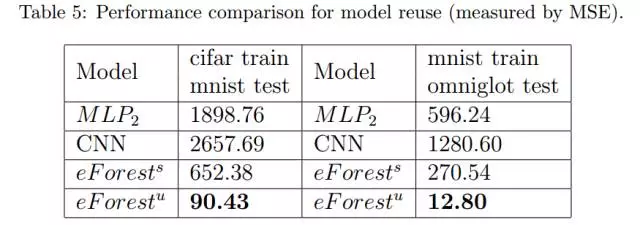
具体来说,我们是这样评估模型的重用能力的。我们在 CIFAR-10 数据集(已经转换和重新定标成了28×28的灰度数据)上训练了一个无监督和一个有监督的 eForest ,每个 eForest 由1000棵树组成,然后使用同一个模型对 MNIST 测试数据集中的数据进行了编码/解码。类似地,我们也在 MNIST 数据集上训练了两个这样的由 1000 棵树组成的 eForest,并在 Omniglot 数据集上直接进行了编码/解码的性能。为了公平比较,我们在相同的数据集上训练了一个 CNN自动编码器和一个 MLP 自动编码器,且没有进行微调。MLP/CNN-AE 的架构和训练过程与前面的部分相同。 最后,我们用 MSE 来进行性能评估。
一些随机抽取的重建样本如图4所示,整个测试集的数字化的评估见表5。可以看出,在 CIFAR-10 上训练的 eForest 可以在 MNIST 数据集上更好地执行编码/解码任务,而且这两个数据集完全不同。它显示了 eForest 模型重用的泛化能力。
总结
在该篇论文中,我们提出了 EncoderForest(简称 eForest),它是第一个基于自动编码器模型的树集合模型:通过设计一个有效的过程,使得森林能够通过使用由树的决策路径定义的 MCR(Maximal-Compatible Rule,最大相容规则)来重建原始路径。
实验证明,eForest 除了在精度和速度方面都表现良好,以及具备一定的鲁棒性之外,还能够重复使用。需要特别指出的是,在重建文本数据时,仅仅需要 10% 的输入位(input bits),该模型依然能够以很高的精度重建原始数据。
eForest 的另一个优点在于,它可以直接应用于符号属性或者混合属性的数据,而不需要将符号属性的数据转换成数字属性的数据。考虑到这种转换过程通常伴随着信息丢失和额外偏差,因此 eForest 的这种特性具有重要意义。
原文链接:https://arxiv.org/abs/1709.09018