

0x00 前言
程序员应该无所畏惧,所以,一起来推导数学公式吧!
上文我们分享了 Bloom Filter 的基本原理和代码实现,在文章的结尾提到了 BF 的误判率以及几个重要参数的选取,我们只给出了最后的公式,而没有具体的推导过程。 这是会被狠狠地挑战的,本着追根刨底的精神,我们推导一下 BF 相关的数学公式。
文章结构
本文会分享关于 BF 的三个知识点:
-
错误率公式的推导
-
最佳哈希函数个数的推导
-
BF 的基数估计公式,即如何计算 BF 中的元素个数
0x01 背景补充
错误率
错误率有两种:
FP = A false positive error, or in short a false positive, commonly called a “false alarm”, is a result that indicates a given condition exists, when it does not.
FN = A false negative error, or in short a false negative, is a test result that indicates that a condition does not hold, while in fact it does.
对应 BF 的情况下,FP 就是「集合里没有某元素,查找结果是有该元素」,FN 就是「集合里有某元素,查找结果是没有该元素」。
FN 显然总是0,只要集合中有某元素,那么肯定能查到。FP 会随着 BF 中插入元素的数量而增加——极限情况就是所有 bit 都为 1,这时任何元素都会被认为在集合里。
0x02 数学推导
一、误判率怎么得到的?
假设哈希函数以相等的概率选择位数组中的位置。如果 m 是位数组中的比特数,则在插入元素期间某一特定比特位不被某个哈希函数设置为 1 的概率是:
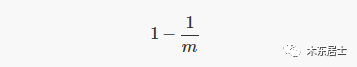
如果哈希函数的数量是 k,则通过 k 个哈希函数都未将该位设置为 1 的概率是:
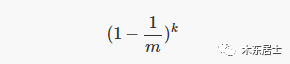
那么,如果我们插入了 n 个元素,某个位仍然为 0 的概率就是:
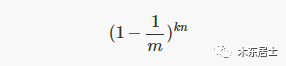
因此这一位的值为 1 的概率就是:
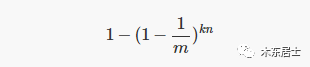
那么,BF 的误判率是怎么得出的?前面提到,我们主要关注 FP,即集合里没有某元素,查找结果是有该元素。
现在我们要判断一个元素是否在集合中,假设这个元素本不在集合中,理论上来讲,经过 k 个哈希函数计算后得到的位数组的 k 个位置的值都应该是 0,如果发生了误判,即这 k 个位置的值都为 1,这个概率如下:
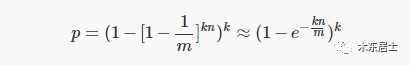
上面的公式就是 BF 的误判率。
注意,上面的证明并不是不是严格正确的,因为它假定每个位的概率被设置为独立性。不过,并不太影响我们对误判率的理解。
二、哈希函数个数该怎么选?
首先,哈希函数的数目 k 必须是正整数。对于给定值的 m 和 n,该如何选择 k 的取值才能使能使误判率 p 最小?这就要用到前面的公式,令 p 的取值为零,即可得到如下表达式:
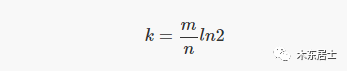
将 k 的最佳取值带入概率公式,就可以得到误判率 p 和 哈希函数个数 k 的关系:
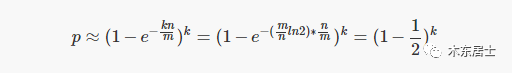
上述公式也可以表述为如下形式:
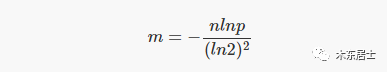
或者
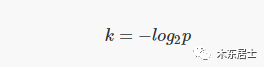
以上就是关于哈希函数个数 k 的最优化取值的数学推导。
三、如何估计 BF 的元素数量?
下面是维基百科给出公式,这里照搬过来,先不做推导了,感兴趣的可以自己来一遍。
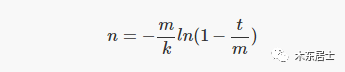
其中 n 是估计 BF 中的元素个数,t 是位数组中被置为 1 的位的个数。
有了能够估计 BF 中元素数量的方式,BF 就可以应用到基数估计的场景中了,这在后面提到 Hyperloglog 等算法的时候会有一些对比。
0xFF 总结
本文参考 BF 的维基百科和几篇经典论文。自己学习并推导一遍还是很能加深印象,公式是自己在 Markdown 中用 LaTeX 敲出来的,十分方便。

