


近日,UCloud推出了UAI Train 智能一体化训练平台,结合此前已推出的UAI Service、GPU及安全屋等AI系列产品,UCloud现已初步形成一站式AI全服务。
UAI Train灵活便捷的训练任务托管服务,能够帮助用户摆脱资源采购运维烦恼,降低AI使用门槛;同时,平台采用按需付费模式,降低AI成本投入,避免闲置资源浪费。
AI模型训练的痛点
随着人工智能产业的兴起,人工智能技术已经被广泛运用于各行各业。近年来,人工智能技术在图像(物体识别、人脸识别等)、自然语言(语音识别、翻译、对话机器人)、智能医疗、智能推荐(广告、新闻、视频)等领域取得了飞速发展。与此同时,人工智能技术对计算资源的需求也快速增加,因而“云计算如何服务于人工智能产业的发展”已成为公有云服务的一个新方向。
通常来说,构建人工智能服务包括三个步骤:大数据收集与处理、AI模型训练、AI模型在线服务,其中的每一个环节都需要投入大量计算资源。
对于大数据处理,可通过采购一定数量的云主机或物理机来搭建一个数据处理集群 ,也可通过采用UHadoop产品来搭建Hadoop或Spark集群来处理数据;对于AI在线服务,可通过使用云主机搭建服务集群或直接使用UCloud AI Service服务,来快速部署AI在线推理服务。
然而,对于AI模型训练,用户通常需要高性能的GPU资源来满足AI模型训练过程中所产生的庞大的浮点计算需求,以及处理随之而来的诸多挑战:
1.成本投入高:GPU硬件或GPU云主机的采购成本非常高。一块P40 GPU的采购价格超过5万,即使是租用P40云主机,其成本也在4500元/月以上,因此使用GPU硬件一次性投入的成本非常高。
2.资源闲置:自行采购GPU还会面临空闲资源闲置等问题。在AI算法研发、迭代过程中,算法设计、数据处理都需要花费大量时间,但此时GPU设备却通常因为无法被充分利用而造成闲置,进一步增加GPU的使用成本。
3.采购周期长:GPU采购和备货周期比普通CPU服务器更长。即便使用公有云服务也无法像使用CPU云主机一样,随时随地购买使用GPU云主机。
4.运维成本高:训练环境配置、GPU资源调度、数据存储、训练任务容灾等问题会随着业务量的增加而增加,从而不断提高GPU训练集群维护的运维成本。
诸多问题表明,对于从事AI业务的公司来说,所面临的挑战非常严峻。研发人员可能手握很好的AI算法模型和解决方案,却往往因为AI技术的高门槛要求而导致研发成本增加、研发周期变长。
为了帮助客户解决AI模型训练过程面临的四个关键问题,UCloud AI Train平台基于UCloud性能强大的GPU云主机集群构建,为AI训练任务提供充足的计算能力。同时,提供一站式训练任务托管服务,包括自动实现计算节点调度、训练环境准备、数据上传下载以及任务容灾等功能,能够帮助用户从繁杂的GPU资源采购、管理、运维工作中解放出来。另外,UAI Train平台按照实际计算消耗付费,不但可以降低GPU的成本投入,而且可以避免闲置资源浪费。
智能一体化训练平台的三大核心优势
一站式任务托管,实时训练状态追踪
UAI Train平台提供一站式训练任务托管服务,用户只需要提供打包好的训练镜像、数据源路径、数据输出路径以及训练所需的参数,就可以提交训练任务并等待任务结束。UAI Train平台将自动进行GPU资源调度、数据下载上传和计算节点容灾。
同时UAI Train平台提供了图形化的实时日志输出,以及TensorBoard的实时展示(Tensorflow和Keras可用),用户可以通过浏览器实时追踪训练的状态。
基于Docker容器技术,强大的AI兼容性
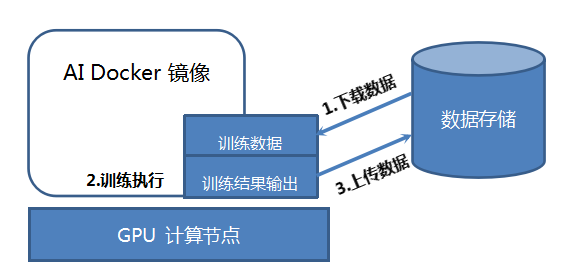
UAI Train基于Docker容器技术,提供兼容性极强的训练环境。用户只需将AI模型训练算法打包至Docker镜像中,即可以将训练任务提交至训练平台,训练平台将会负责:
1.训练数据下载;
2.训练任务执行;
3.训练结果输出并保存。
完全无需用户介入,整个过程如下图所示:
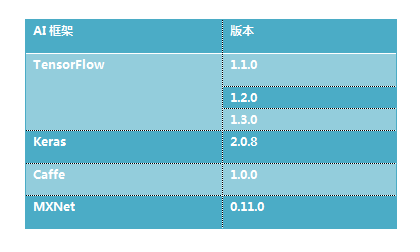
为简化UAI Train平台的使用过程,UCloud提供了Python SDK和基础Docker镜像,以此来协助用户封装Docker镜像。目前,UAI Train平台支持4种主流AI框架,包括镜像一键打包和测试工具以及基础镜像(后续还将计划增加对PyTorch、CNTK等开源框架的支持)。
同时,UAI Train平台也支持自定义Docker训练镜像,并提供了预装cuda和cudnn的基础镜像。
灵活配置选择,超高性价比
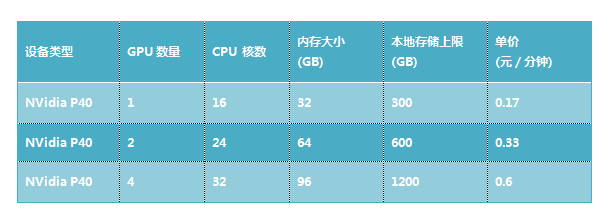
UAI Train平台目前支持3种GPU节点,按需使用收费,计费精确到分钟,具有极高的性价比。
 UAI Train平台还计划逐步推出种类更丰富的硬件加速计算设备,包括更新的GPU设备、Xeon
Phi设备等,另外还将推出分布式训练集群支持。
UAI Train平台还计划逐步推出种类更丰富的硬件加速计算设备,包括更新的GPU设备、Xeon
Phi设备等,另外还将推出分布式训练集群支持。
四大核心应用场景,助力企业AI业务发展
应用场景一:快速AI转型
AI模型训练任务执行环境配置复杂(GPU驱动、AI框架环境安装等)、GPU资源采购周期长、成本高、运维工作繁杂等,这都成为企业快速转型AI业务的绊脚石。使用UAI Train训练服务可以无需担心资源采购、环境配置、集群维护等问题,快速开展AI模型训练工作。
应用场景二:降低AI成本
AI训练任务执行需要花费大量计算资源。GPU硬件采购成本高,闲置资源浪费开销大。使用UAI Train训练服务不仅可以获得充足的GPU硬件资源,同时又可以按照实际计算消耗付费,使用较小的投入获取充足的计算资源,具有极高的性价比,可以有效减低AI成本。
应用场景三:简化AI运维
大规模执行AI模型训练任务需要处理计算资源调度、任务管理、任务容灾等问题。UAI Train训练平台自动帮助使用者解决计算节点调度、任务管理、容灾等问题,更为使用者提供了图形化界面展示训练任务状态。
应用场景四:共享GPU资源
使用GPU云主机、物理机很难在团队之间、部门之间以及各类使用者之间共享GPU资源。UAI Train训练平台则可以同时满足成千上百个使用者共享整个GPU资源池,同时又提供了资源隔离、配额管理功能,可以满足GPU资源共享场景的需求。
在9月份由创新工场联合搜狗、今日头条发起的“AI Challenger全球AI挑战赛”中,UCloud 便作为唯一的AI GPU合作方,为大赛独家提供了AI模型训练服务(UCloud AI Train)。此次合作也验证UCloud在AI领域强大的研发实力、快速响应服务以及自身平台稳定性,为大赛的成功举办保驾护航。
作为国内领先的云计算服务商,UCloud将继续深入研究AI训练平台的功能与性能,致力为用户提供更丰富的AI框架和分布式训练支持。同时,UCloud还将结合UAI Service 在线服务平台,打造从AI训练到AI在线服务的一体化解决方案,全方位提升面向AI产业的服务能力。
想要获取更多技术和活动资讯,可扫描以下二维码,关注“UCloud技术公告牌”微信公众号。

