

针对故障设计微服务架构
一个月前2017-8-15
服务边界定义良好的微服务使得隔离故障成为可能。但是正如其它的分布式系统,网络,硬件或者应用层出问题的概率更高。服务依赖的后果是任何组件可能暂时对用户不可用。为了让局部故障的影响最小化,我们需要构建能优雅响应部分依赖中断运行的容错的服务。
这篇文章介绍了RisingStack’s Node.js Consulting & Development experience里面关于构建高可用微服务最通用的技术和架构模式。
如果你不熟悉这篇文章里的模式,不一定意味着你做错了什么。构建高可用系统需要额外的开销。
微服务的风险
微服务架构把应用逻辑移到服务并通过网络层进行通信。网络层通信需要多个物理和逻辑层组件的协作,相比内存调动通信给系统带来了额外了延迟和复杂度。这种在分布式系统增加的复杂度使得某些网络异常的概率更高。
#microservices allow you to achieve graceful service degradation as components can be set up to fail separately. Click To Tweet
微服务架构相比同构最大的好处是各个小组可以独立设计开发和部署服务,对服务的生命周期有完全控制权。同时意味着我们无法控制服务的依赖因为很有可能由别的小组管理。在微服务架构下,我们需要时刻提醒自己,别人提供的服务或者组件会因为错误的发布,配置或者迁移等其它改变导致短暂不可用。
服务优雅降级
微服务最大的优势之一就是可以通过隔离系统不同组件的异常实现服务的优雅降级。比如在一个图片分享的应用中,用户处于不能上传新照片,但是仍然可以浏览编辑和分享现有的照片。
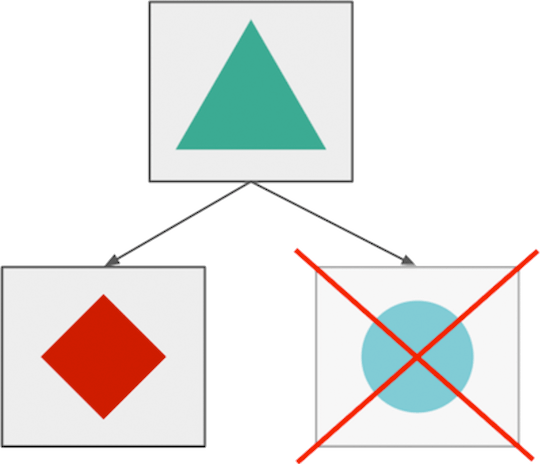
微服务分别停服(理论上)
大多数的这种情况难以实现这种优雅降级方案,因为分布式的应用互相依赖,并需要采用多种故障转移策略(本文会介绍部分)在应对短暂故障和中断。
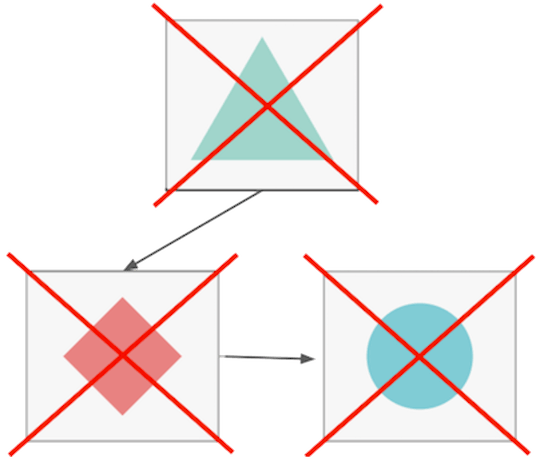
没有容错逻辑的互相依赖的服务会导致联带故障。
变动管理
Goodle 的站点可靠性团队发现线上系统大概70%的故障是变动引起。当对服务改动 - 发布新版或者修改配置 - 总是可能导致故障或者引入新的 bug。
微服务架构下,服务互相依赖。因此我们需要把异常和负面效果最小化。对于改动引起的问题,可以实现改动管理策略和自动回滚。
比如当你部署了新的代码,或者改变了配置,应该灰度发布,监控这些发布并在关键指标上检测到异常时自动回滚。
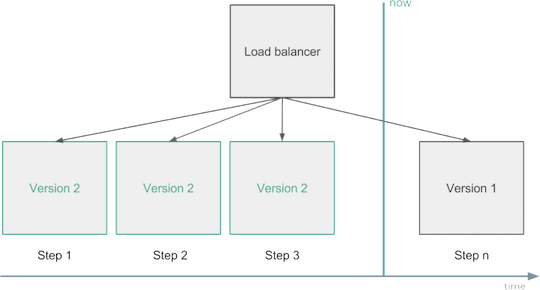
变动管理 - 平滑部署
另一种方案是同时允许两套生产环境。每次只发布到其中一套环境,并在验证新版本按预期工作后让负载均衡指向新环境。这种方案称为蓝-绿,或者红-黑部署。
回滚代码并不意味糟糕。我们不应该让错误代码跑在线上然后思考哪里出了错。一旦有需要就回滚代码。越快越好。
想了解更多如何构建健壮的微服务架构?
关注我们即将推出的培训!
健康检查和负载均衡
实例因为异常,部署或者弹性伸缩。导致服务间隔或永久不可用。为了避免这种情况,负载均衡应该能从路由中过滤不健康的实例。
应用实例的健康状态应该能从外部观测判断。可以通过不停发送GET /health请求或者主动报告实现。当前的服务发现方案能持续收集健康状态并配置负载均衡把流量导到健康的实例。
自我修复
自我修复能够帮助恢复应用。自我修复指的是应用可以采取必要措施从异常中恢复。大多数情况下是通过外部系统检测到异常状态并过一段时候后进行处理。自我修复通常很有用,但是某些情况下导致不停重启也会引起问题。比如应用因为过载或者数据库连接超时导致无法获取健康状态时就会发生。
针对特定场景实现高级的自我修复方案会很复杂 - 比如数据库连接丢失 -。这种情况需要额外的逻辑处理边界情况并让外部系统知道实例不需要立即重启。
故障备用缓存(Failover Caching)
服务通常因为网络事故或者系统变动导致故障。但是在大部分这样的中断中,可以通过自我修复或者高级的负载均衡方案让服务能继续工作。这时候故障备用缓存(Failover Caching)能为应用提供必要的数据。
故障备用缓存(Failover Caching)通常使用两个过期时间;较短的时间用于正常情况,较长的时间当异常情况发生时起作用。
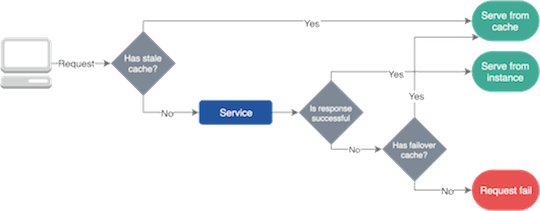
故障备用缓存(Failover Caching)
需要强调一点是故障备用缓存的使用条件是使用过期数据总比没有强。
设置缓存和故障备用缓存,可以通过标准的 HTTP 头实现。
比如,用max-age头设置资源的有效时间。用stale-if-error头决定在异常情况下让资源继续生效的时间。
当前 CDNs 和负载均衡器提供不同的缓存和故障转移行为,你也可以实现一套标准可靠的方案并在公司内分享。
重试逻辑
某些情况我们无法缓存数据或需要对数据进行修改,导致操作最终失败。这些情况可以通过重试操作并期望资源不久后会恢复或者负载均衡器把请求转发到正常的实例。
需要谨慎考虑是否在应用层和客户端加入重试逻辑,有一大部分重试导致更坏的后果甚至阻止应用恢复。
分布式系统中的微服务重试会触发多个请求或重试并导致级联效应。为了最小化重试影响,需要限制数量并使用一种指数补偿算法不断增加触发间隔直到达到最大重试限制。
当客户端发起重试 (浏览器,其它微服务等)并且不知道之前的操作或之后的响应是否失败,应用需要支持幂等操作。比如当你重试购买操作,不应该对客户重复收费。每个事务对应一个唯一幂等钥可以解决重试问题。
速率限制器和卸载器(Rate Limiters and Load Shedders)
速率限制是在一段时间内定义指定客户或应用程序可以接收或处理请求数的技术。通过速率限制,你可以过滤掉产生流量峰值的客户和微服务,或者你可以确保应用程序在弹性伸缩起作用前不会超载。
你还可以减少低优先级请求的响应,为关键事务让出资源。
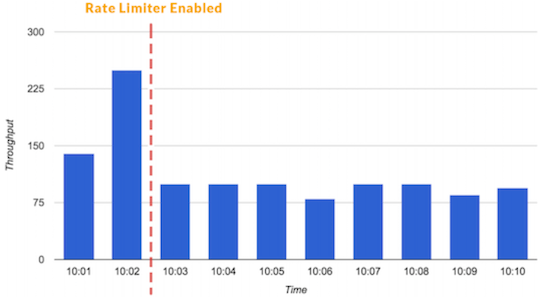
速率限制器可以拉低流量峰值
并发请求限制器(concurrent request limiter)是另一种速率限制器。当你不希望重要的端点被调用超过指定的次数,但仍然想要提供服务时会非常有用。
卸载器一个简单应用可以确保总是有足够的资源提供给关键的事务。它为高优先级请求保留一些资源,防止低优先级的事务占用所有资源。卸载器根据系统的整体状态做出决定,而不是基于单个用户请求的大小。卸载器有助于系统恢复,它保证发生意外时核心功能的正常工作。
更多关于速率限制器和卸载切,我推荐这篇文章Stripe’s article。
快速独立地失败
在微服务体系架构中,我们希望服务可以快速,独立地失败。在服务层面隔离故障,我们可以使用隔板模式(bulkhead pattern)。此文之后会介绍到舱壁模式。
我们也希望组件能够快速失败来避免等待一个坏掉的实例直到超时。没有什么比挂起的请求和无响应 UI 更令人失望。这不仅浪费资源,还会让用户体验变差。我们的服务在一个链里互相调用,任何的延迟会被累加放大,所以应该额外注意并防止挂起操作的发生。
第一个想法也许是对不同服务调用都采用细粒度超时。这种做法的问题是,你不能真正知道多长时间才是那个恰好的超时值,因为网络故障和其他问题发生的某些情况只会影响一两次操作。在这种情况下,你可能不想因为只有一些超时就拒绝这些请求。
我们可以说,对微服务中快速失败范式的实现中,使用超时是一种反模式,你应该避免使用。更好的选择可以采用根据操作的成功 / 失败统计的断路器模式。
想了解更多微服务相关?
查看接下来的培训!
舱壁模式
舱壁在工业中用于把船分区,这样在船身有缺口时可以封闭相应的区域。
舱壁的概念也可以在软件开发中应用于隔离资源。
通过使用舱壁模式,我们可以保护有限的资源不被用尽。例如,假定有两种操作与一个只能提供有限连接数的数据库通讯,可以使用两个连接池而不是单个共享的连接池。这样客户端就实现了-资源分离,一种操作超时或过度使用池不会导致另一种操作失败。
泰坦尼克号沉没的主要原因之一是其舱壁设计失败,水可以通过上面的甲板没过舱壁的顶部,并淹没整个船体。
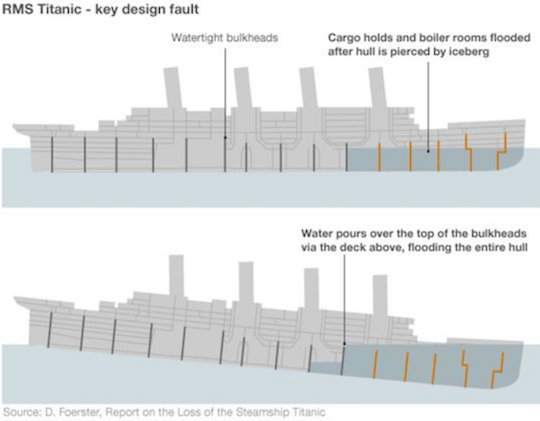
泰坦尼克号的舱壁(设计失败)
断路器(Circuit Breakers)
我们可以使用超时限制操作的持续时间。超时可以防止操作挂起并保证系统可以响应。然而,在微服务通信中使用静态,细调的超时是一种反模式,因为高度动态的环境几乎不可能确定适用所有情况超时时间限制。
既然不能使用小的和事务相关的的静态超时,我们可以使用断路器来处理错误。断路器以现实世界的电子元件命名,因为它们的行为是相同的。你可以使用断路器保护资源并帮助恢复资源。断路器在分布式系统中非常有用,因为重复的故障可能引起雪球效应并使整个系统停服。
当短时间内指定类型的错误多次发生,断路器会开启。开启的断路器可以拒绝接下来的请求-像防止电子流动一样。断路器通常在一定时间后关闭,为底层服务恢复提供足够空间。
请记住,并不是所有的错误都应该触发断路器。例如,你可能希望忽略客户端4xx响应代码但包含5xx的服务端异常。一些断路器还可以有半开状态。在这种状态下,服务发送第一个请求来检查系统可用性,同时让其他请求失败。如果这个第一个请求成功,就将断路器恢复到关闭状态允许流量进入。否则保持打开。否则保持打开。
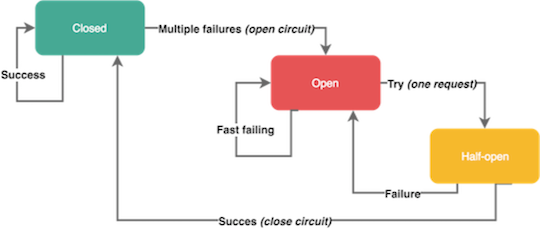
断路器
针对故障的测试
应该持续地测试系统的常见问题以确保服务可以在各种故障中的存活。经常测试故障让你的团队熟悉事故处理流程。
针对测试,可以使用外部服务识别出各个实例组,并随机终止某个组中的一个实例。这是针对单个实例的故障准备,你甚至可以关闭整个区域来模拟云提供商层面的程序中断。
最流行的测试解决方案之一是 Netflix 的ChaosMonkey。
最后
实现并维护一套可靠的服务并不容易。你需要付出很多努力并花费公司更多的成本。
可靠性有很多层次和方面,找到最适合团队的解决方案很重要。你应该使可靠性成为业务决策流程中的一个要素,并为其分配足够的预算和时间。
关键点
-
动态环境和分布式系统(如微服务)有更高的概率发生故障。
-
服务应单独失败以实现优雅降级,提升用户体验。
-
70%的问题是由变化引起的,恢复代码不是坏事。
-
快速,独立地失败。团队无法控制其服务依赖关系。
-
架构模式和技术,如缓存,舱壁,断路器和限速器有助于构建可靠的微服务。
学习更多相关参考我们免费的Node.js Monitoring, Alerting & Reliability 101 e-book。如果需要咨询微服务实现相关,联系@RisingStack Twitter,或者参与即将推出的Building Microservices with Node.js
Péter Márton
CTO at RisingStack,microservices and brewing beer with Node.js
twitter.com/slashdotpet… Node.js with Microservices Node.js Monitoring & Debugging DevOps - Node in Production Architectural Patterns
Node.js with Microservices Node.js Monitoring & Debugging DevOps - Node in Production Architectural Patterns
更多关于我们
更早的文章
