

-
本文為CocoaChina網友 品位生活 投稿
北京時間2017.6.6日淩晨1點,新一屆的WWDC召開,蘋果在大會上發布了iOS11的beta版,伴隨著iOS 11的發布,也隨之推出了一些新的API,如:ARKit 、Core ML、FileProvider、IdentityLookup 、Core NFC、Vison 等。
本篇文章主要簡單介紹下其中的 Vision API 的使用(Vision更強大的地方是可以結合Core ML模型實現更強大的功能,本篇文章就不詳細展開了)
Vison 與 Core ML 的關系
Vision 是 Apple 在 WWDC 2017 推出的圖像識別框架。
Core ML 是 Apple 在 WWDC 2017 推出的機器學習框架。
Core ML
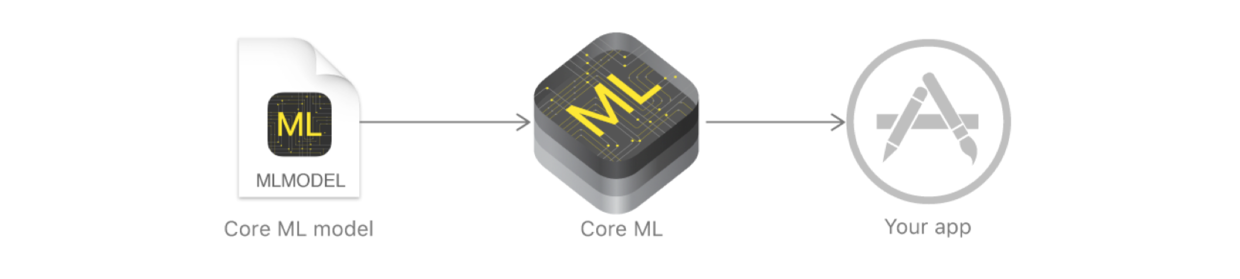
根據這張圖就可以看出,Core ML的作用就是將一個Core ML模型,轉換成我們的App工程可以直接使用的對象,就是可以看做是一個模型的轉換器。
Vision在這裏的角色,就是相當於一個用於識別Core ML模型的一個角色.
Vision

根據官方文檔看,Vision 本身就有Face Detection and Recognition(人臉檢測識別)、Machine Learning Image Analysis(機器學習圖片分析)、Barcode Detection(條形碼檢測)、Text Detection(文本檢測)。。。。。等等這些功能。
所以可以這樣理解:
Vision庫裏本身就已經自帶了很多訓練好的Core ML模型,這些模型是針對上面提到的人臉識別、條形碼檢測等等功能,如果你要實現的功能剛好是Vision庫本身就能實現的,那麽你直接使用Vision庫自帶的一些類和方法就行,但是如果想要更強大的功能,那麽還是需要結合其它Core ML模型。
Vision 與 Core ML 總結
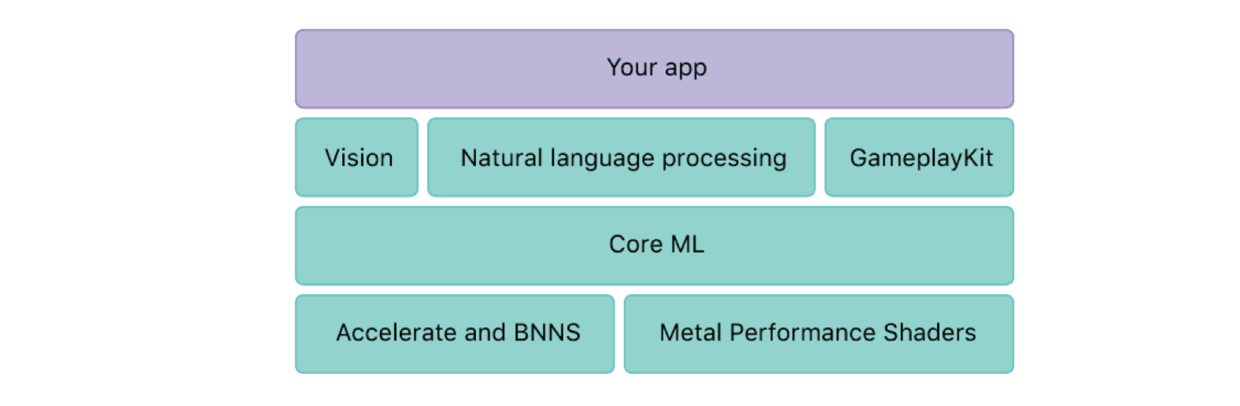
Core ML可以看做一個模型的轉換器,可以將一個 ML Model 格式的模型文件自動生成一些類和方法,可以直接使用這些類去做分析,讓我們更簡單的在app中使用訓練好的模型。
Vision本身就是能對圖片做分析,他自帶了針對很多檢測的功能,相當於內置了一些Model,另外Vision也能使用一個你設置好的其它的Core ML Model來對圖進行分析。
Vision就是建立在Core ML層之上的,使用Vision其實還是用到了Core ML,只是沒有顯式地直接寫Core ML的代碼而已。
Vison 的應用場景
圖像配準
矩形檢測

二維碼/條形碼檢測

目標跟蹤:臉部,矩形和通用模板

文字檢測:監測文字外框,和文字識別

人臉檢測:支持檢測笑臉、側臉、局部遮擋臉部、戴眼鏡和帽子等場景,可以標記出人臉的矩形區域

人臉特征點:可以標記出人臉和眼睛、眉毛、鼻子、嘴、牙齒的輪廓,以及人臉的中軸線

Vison 的設計理念
蘋果最擅長的,把復雜的事情簡單化,Vision的設計理念也正是如此。
對於使用者我們抽象的來說,我們只需要:提出問題-->經過機器-->得到結果。
開發者不需要是計算機視覺專家,開發者只需要得到結果即可,一切復雜的事情交給Vision。
Vison 的性能對比
Vision 與 iOS 上其他幾種帶人臉檢測功能框架的對比:

根據官方提供的資料可以看出來,Vision 和 Core Image、AV Capture 在精確度,耗時,耗電量來看基本都是Best、Fast、Good。
Vision 支持的圖片類型
Vision 支持多種圖片類型,如:
-
CIImage
-
NSURL
-
NSData
-
CGImageRef
-
CVPixelBufferRef
Vison 的使用 與結構圖
Vision使用中的角色有:
Request,RequestHandler,results和results中的Observation數組。
結果圖
Request類型:
有很多種,比如圖中列出的 人臉識別、特征識別、文本識別、二維碼識別等。
結果圖

使用概述:
我們在使用過程中是給各種功能的 Request 提供給一個 RequestHandler,Handler 持有需要識別的圖片信息,並將處理結果分發給每個 Request 的 completion Block 中。可以從 results 屬性中得到 Observation 數組。
observations數組中的內容根據不同的request請求返回了不同的observation,如:VNFaceObservation、VNTextObservation、VNBarcodeObservation、VNHorizonObservation,不同的Observation都繼承於VNDetectedObjectObservation,而VNDetectedObjectObservation則是繼承於VNObservation。每種Observation有boundingBox,landmarks等屬性,存儲的是識別後物體的坐標,點位等,我們拿到坐標後,就可以進行一些UI繪制。
具體人臉識別使用示例:
1,創建處理圖片處理對應的RequestHandler對象。
// 轉換CIImage
CIImage *convertImage = [[CIImage alloc]initWithImage:image];
// 創建處理requestHandler
VNImageRequestHandler *detectRequestHandler = [[VNImageRequestHandler alloc]initWithCIImage:convertImage options:@{}];2, 創建回調Handler。(用於識別成功後進行回調執行的一個Block)
// 設置回調
CompletionHandler completionHandler = ^(VNRequest *request, NSError * _Nullable error) { NSArray *observations = request.results;
};3, 創建對應的識別 Request 請求,指定 Complete Handler
VNImageBasedRequest *detectRequest = [[VNDetectFaceRectanglesRequest alloc]initWithCompletionHandler: completionHandler];4,發送識別請求,並在回調中處理回調接受的數據
[detectRequestHandler performRequests:@[detectRequest] error:nil];代碼整合:
總的來說一共經過這幾步之後基本的人臉識別就實現了。
// 轉換CIImage
CIImage *convertImage = [[CIImage alloc]initWithImage:image];
// 創建處理requestHandler
VNImageRequestHandler *detectRequestHandler = [[VNImageRequestHandler alloc]initWithCIImage:convertImage options:@{}];
// 設置回調
CompletionHandler completionHandler = ^(VNRequest *request, NSError * _Nullable error) {
NSArray *observations = request.results;
[self handleImageWithType:type image:image observations:observations complete:complete];
};
// 創建BaseRequest
VNImageBasedRequest *detectRequest = [[VNDetectFaceRectanglesRequest alloc]initWithCompletionHandler:completionHandler];
// 發送識別請求
[detectRequestHandler performRequests:@[detectRequest] error:nil];VNFaceObservation 介紹:
VNFaceObservation裏面,我們能拿到的有用信息就是boundingBox。
/// 處理人臉識別回調+ (void)faceRectangles:(NSArray *)observations image:(UIImage *_Nullable)image complete:(detectImageHandler _Nullable )complete{
NSMutableArray *tempArray = @[].mutableCopy;
for (VNFaceObservation *observation in observations) {
CGRect faceRect = [self convertRect:observation.boundingBox imageSize:image.size];
}boundingBox直接是CGRect類型,但是boundingBox返回的是x,y,w,h的比例,需要進行轉換。
/// 轉換Rect+ (CGRect)convertRect:(CGRect)oldRect imageSize:(CGSize)imageSize{
CGFloat w = oldRect.size.width * imageSize.width;
CGFloat h = oldRect.size.height * imageSize.height;
CGFloat x = oldRect.origin.x * imageSize.width;
CGFloat y = imageSize.height - (oldRect.origin.y * imageSize.height) - h; return CGRectMake(x, y, w, h);
}關於Y值為何不是直接oldRect.origin.y * imageSize.height出來,是因為這個時候直接算出來的臉部是MAX Y值而不是min Y值,所以需要進行轉換一下。

特征識別介紹:
VNDetectFaceLandmarksRequest 特征識別請求返回的也是VNFaceObservation,但是這個時候VNFaceObservation 對象的 landmarks 屬性就會有值,這個屬性裏面存儲了人物面部特征的點。
如:
// 臉部輪廊@property (nonatomic, strong) VNFaceLandmarkRegion2D * _Nonnull faceContour;// 左眼,右眼@property (nonatomic, strong) VNFaceLandmarkRegion2D * _Nullable leftEye;@property (nonatomic, strong) VNFaceLandmarkRegion2D * _Nullable rightEye;// 鼻子,鼻脊@property (nonatomic, strong) VNFaceLandmarkRegion2D * _Nullable nose;@property (nonatomic, strong) VNFaceLandmarkRegion2D * _Nullable noseCrest;@property (nonatomic, strong) VNFaceLandmarkRegion2D * _Nullable medianLine;// 外唇,內唇@property (nonatomic, strong) VNFaceLandmarkRegion2D * _Nullable outerLips;@property (nonatomic, strong) VNFaceLandmarkRegion2D * _Nullable innerLips;// 左眉毛,右眉毛@property (nonatomic, strong) VNFaceLandmarkRegion2D * _Nullable leftEyebrow;@property (nonatomic, strong) VNFaceLandmarkRegion2D * _Nullable rightEyebrow;// 左瞳,右瞳@property (nonatomic, strong) VNFaceLandmarkRegion2D * _Nullable leftPupil;@property (nonatomic, strong) VNFaceLandmarkRegion2D * _Nullable rightPupil;每個特征對象裏面都有一個pointCount屬性,通過特征對象的pointAtIndex方法,可以取出來特征裏面的每一個點,我們拿到點進行轉換後,相應的UI繪制或其他操作。
例如:
UIImage *sourceImage = image;
// 遍歷所有特征
for (VNFaceLandmarkRegion2D *landmarks2D in pointArray) {
CGPoint points[landmarks2D.pointCount]; // 轉換特征的所有點
for (int i=0; iVision Demo演示:
圖像識別:
以上是簡單列舉了一些代碼,具體更詳細的可參考官方文檔或Demo代碼(後面有Demo 下載鏈接)
下面GIF演示一下Vision Demo ,此Demo比較簡單,演示了基本的一些Vision的使用
圖像識別:
人臉識別、特征識別、文字識別

動態識別:
動態監測人臉,動態進行添加

Demo下載地址
https://github.com/DaSens/Vision_Demo
https://github.com/DaSens/Vision_Track.git
參考資料:
http://www.jianshu.com/p/174b7b67acc9
http://www.jianshu.com/p/e371099f12bd
https://github.com/NilStack/HelloVision
https://developer.apple.com/documentation/vision
https://github.com/jeffreybergier/Blog-Getting-Started-with-Vision
https://tech.iheart.com/iheart-wwdc-familiar-faces-1093fe751d9e
http://yulingtianxia.com/blog/2017/06/19/Core-ML-and-Vision-Framework-on-iOS-11/
