

在数据中心管理方面,Google绝对是走在最前面的互联网公司,毕竟数据中心规模摆在那里。今天我们来看一下Google的内部大型集群管理系统,Borg,是如何运作的。原文在这里 http://delivery.acm.org/10.1145/2750000/2741964/a18-verma.pdf?ip=199.201.64.2&id=2741964&acc=OA&key=4D4702B0C3E38B35%2E4D4702B0C3E38B35%2E4D4702B0C3E38B35%2E5945DC2EABF3343C&CFID=821467408&CFTOKEN=85908090&__acm__=1508654694_a91a706f1002f46e69bca69f7f540b03。这个大型集群管理系统算是Kubernetes的前身,有兴趣知道Kubernetes具体信息的可以看这里( Kubernetes)。
在讲大型集群管理系统之前,我们先讲一下为什么需要这类系统。
第一,Borg,Kubernetes这类系统最重要的工作就是在尽量不影响你的软件运作效率的情况下,最大限度的帮公司省钱。如果一个公司的服务器端的软件都是一个一个组分开去provision的话(比如我所知道的微软就是一个一个组分开买机器的),那么很多机器需要用到的资源类型不同,也会出现程度的浪费。比如完全不叠加软件的公司里面各个机器的资源占有率可能是这样的

但是如果你允许大家叠加了之后就变成这样了:

这样我们就少用了两台机器,帮公司省了一半的钱。在一般的小的互联网公司这个不算什么,但是在Google、AWS这类每年动辄几十亿美元的服务器开销的公司里面这种级别的节省可能就会上亿,所以大公司会在这类东西上面下功夫。
第二,Google这个公司需要大量的MapReduce工作去优化它的搜索引擎和准备数据给机器学期训练,所以这类公司就需要大量的机器可以让它跑MapReduce。如果我用分开的集群去跑MapReduce那是一个非常大的浪费,我可不可以把MapReduce的工作叠加到所有的机器上面,然后只要机器有资源我就跑MapReduce呢?这个论文里面也说了事实上Google也是这么做的,所以上图就变成了这样:

这样就可以最大化MapReduce在集群上面可以榨取的CPU。对于Google这类拿CPU换钱的公司,这样可以给它制造更多的利润。Borg这类软件同时也要处理MapReduce所需要的scheduling的工作,所以Borg这类系统也会有scheduling的部分。
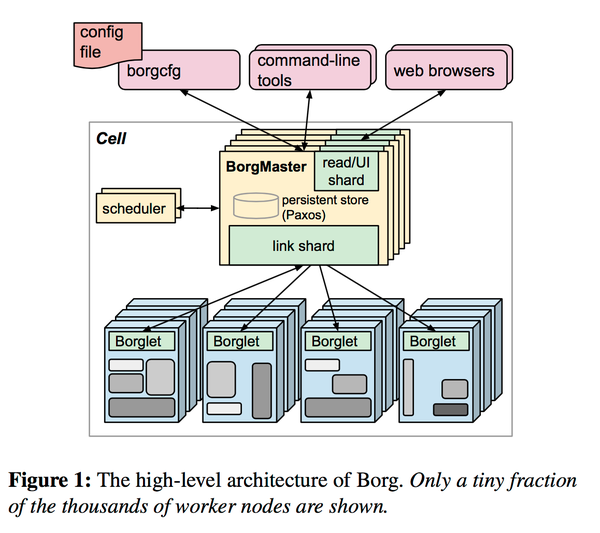
上图是Borg整体架构的概览,我们可以看到的是
- 每个集群叫一个cell,会有一个对应的BorgMaster。
- 这里BorgMaster画了好多层是刻意的,为了high availability每个cell有5个BorgMaster,但是不是这5个BorgMaster里面只有一个是真正的leader。这五个BorgMaster有一个基于Paxos的储存。
- BorgMaster这类软件一般不会有太多的外部的依赖,文章中讲到选完BorgMaster的leader之后会去Chubby拿个所告诉大家哪个是leader,但是Borg本身并不非常依赖于Chubby或者其它任何的Google内部服务。这很重要,因为对于Borg来说最重要的一个特性之一就是availability。
- 每个机器上面会有一个Borglet,BorgMaster定期会跟Borglet沟通你现在需要在这个机器上面做什么,开什么新的软件啊之类的
- 这里有一个设计是Borglet不跟BorgMaster主动沟通,因为如果出现突然断电这类意外,会有大量的Borglet同时想要跟BorgMaster沟通,这时候反而有可能因为访问太多把BorgMaster搞倒了。
- BorgMaster跟Borglet沟通的桥梁中间加了一层link shard,很大一个作用是只把Borglet的变化传给BorgMaster,这样可以减少沟通的成本和BorgMaster处理的成本。
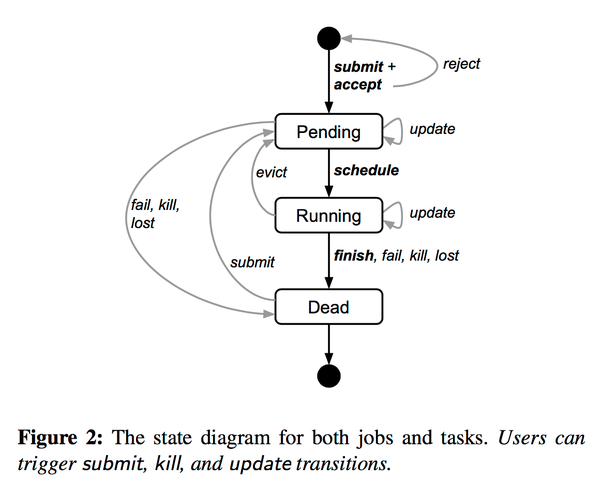
上图描述的是具体每一个task的生命周期。用户主要可以做的事情是
- 递交一个工作(submit)
- 销毁一个工作(kill)
- 更新一个工作(update)
更多的变化是borg内部会控制的。这里在一个cell里面一般更新是渐进的。销毁一个工作的时候用的是SIGTERM+SIGKILL。这里还要讲到其它一些Borg的概念
- 资源配置(alloc):每个工作可以告知系统需要给我预留多少资源,这样系统可以确保不会太过激进的去叠加
- 优先级(priority):可以告诉borg你的工作的优先级,高优先级的程序可以踢走低优先级的程序
- 整体工作配额(quota):这个部分是在工作发送给borg的时候决定要不要接受这个工作,具体quota是在capacity planning的时候做的,是一个项目资源占比的问题而不是一个软件问题。
- 如何发送工作给Borg:每个程序发现Borg是通过Chubby里面的文件的,文件会写明每个BorgMaster对应的cell跟它的网络信息。之后就是一般的RPC。
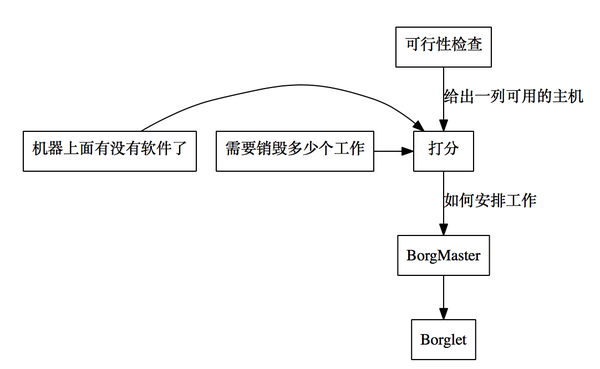
现在我们来讲Borg是怎么做调度(scheduling)的。调度算法有两个部分:可行性检查(feasibility checking)跟打分选机器(scoring)
- 可行性检查会找出所有可以安排的机器,打分的时候会选出最适合的机器
- 打分的时候主要还是要看把这个工作安排到哪个机器上面需要最小的代价,比如
- 最小化需要干掉的其它的工作
- 这个机器上已经有这个工作所需要的软件了
- 分散failure domain(这个概念在储存系统里面比较多)
- 为了优化系统的响应时间,打分之后的分数会被放到缓存里面,知道这个机器上面有变化了才会被重新计算
- 为了减少运算量,同样的机器在同样的需求下面所打的分数也会被放到缓存里面
- 每次检查可行性的时候,不会检查所有的机器的可行性,只要随机抽查到足够的机器符合条件就行
所以简单来说,每次调度的时候回走下面这个流程:
一开始的时候Borg在分配工作的时候会把所有工作平均分配到所有机器上面。这么做有一个好处就是spike会处理的很好,但是工做非常碎片化,所以最后用的算法会在碎片化跟spike预留做一个权衡。
在了解这么多Borg的系统概念之后,我们来看看具体用Borg的效果如何。Paper里面也提到了其它公司batch job跟prod是分开的,这个paper也看了一下如果batch job是分开跑的话Google需要多出多少钱:
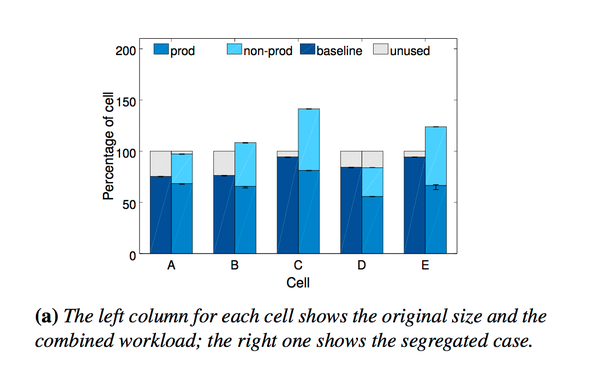
这里可以看到利用率有很高的提升。Paper里面也检查了stacking对CPI(cycles per instruction) 的影响,结论是影响不大。它们也研究了cell是大点好还是小点好,结论是cell的大小是越大越好,这里就是需要对Borg 的availability跟大cell可以节省的资源去做平衡。Borg为了可以给Google节省跟多的资源做了下面的优化
- fine grain resource control:可以让程序要求小数点个CPU,因为有的时候根本用不到一个CPU
- resource reclaimation:虽然程序要求一定的资源,Borg通过自己的判断去降低这个要求,比如可以拿更多的OOM来换取更极限的叠加。效果如下图
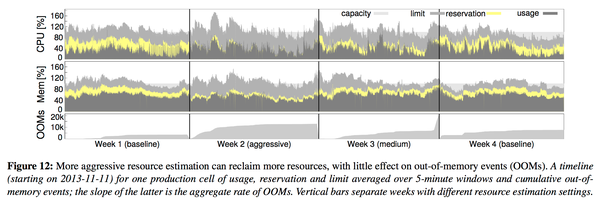
可以看到Borg的判断有的时候是还可以接受的,但是通过更极限的叠加是可以让资源占有率提高的(黄色越少越好)。
- 在isolation上面,Google用的是chroot、cgroup,而VM只在GCE这类面向外部的部门用
- Borg在具体到每一个机器的使用率控制上面把程序和资源的分成两类:
- 每个程序会标记是不是需要快速响应(latency sensitive)
- 每个资源被分成可不可以被压缩的。内存和硬盘是不可压缩资源,CPU跟网络是可压缩资源
- 系统会优先分配资可压缩源给需要快速响应的程序,而不需要快速响应的程序在想要获得可压缩资源的时候会被throttle
- 如果不需要快速响应的程序被starve太久,会被销毁
- 不可压缩资源如果低优先级的程序占有太多的话会直接被销毁
为了做这些功能,borg的人优化了linux系统的scheduling,以确保系统反应这些scheduling变化的速度足够快。
那么在做了borg这么多年之后,borg的人给我们能分享的经验是什么呢?
- Borg的最基础单位是job,没有办法在job下面做更复杂的分配,所以很多内部用户需要hack一些奇怪的东西来表达topology。这个在Kubernetes里面解决了,可以用label。
- Borg假设一个host只能有一个IP,这样导致Borg会把port当成一个资源来分配。Kubernetes里面可以有多个IP了。
- Borg为了大用户做了很多优化,所有API非常复杂,但是一般用户很多API根本用不到。这个Kubernetes做的还是不错的。
- 资源配置单位是非常重要的,Kubernetes里面叫Pod
- 集群控制不只是task management,Kubernetes支持服务的load balancing跟naming
- 优良的debugging工具是非常重要的,Kubernetes基本复制了所有Borg的debugging能力
- BorgMaster就跟整个集群的kernel一样,未来需要做很多kernel能做而Borg不能做的事情
Google这些大集群管理经验非常值得我们借鉴,也希望Kubernetes可以越走越远吧。最后再写一下,原文在这里http://delivery.acm.org/10.1145/2750000/2741964/a18-verma.pdf?ip=199.201.64.2&id=2741964&acc=OA&key=4D4702B0C3E38B35%2E4D4702B0C3E38B35%2E4D4702B0C3E38B35%2E5945DC2EABF3343C&CFID=821467408&CFTOKEN=85908090&__acm__=1508654694_a91a706f1002f46e69bca69f7f540b03
