论文作者:Ranjay Krishna, Kenji Hata,Frederic Ren, Li Fei-Fei, Juan Carlos Niebles StanfordUniversity
编译 | Shawn
编辑 | 鸽子
今早,营长刚一起床,手机大屏幕上惊现李飞飞的新推文:
立即打开推文:
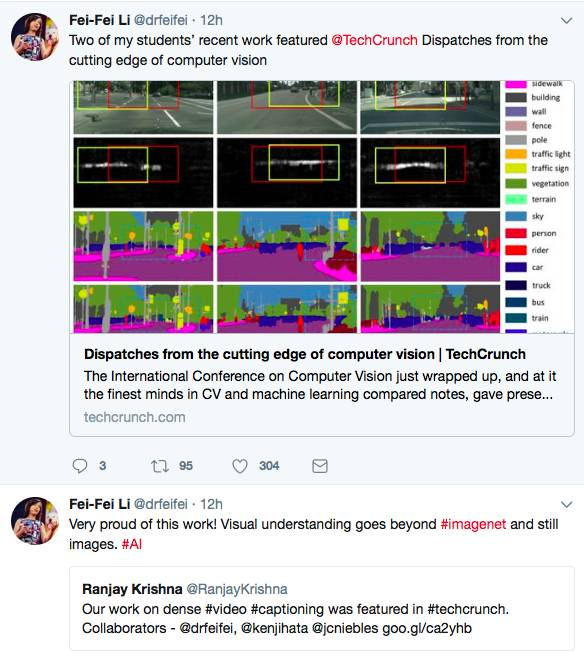
大意为:我的学生最近的论文被TechCrunch网站选为“计算机视觉最前沿的十篇论文”之一,我真是为它们感到骄傲。继Imagenet后,计算机视觉仍然在不断突破我们的想象力。
既然是大神李飞飞的得意门生,必是值得一读的大作。其实这篇论文早在今年5月就已公布,不少知乎网友也纷纷给出了自己的解读。在这篇文章中,第一部分为论文的摘要及引言翻译,第二部分为解读(不代表本文观点),希望对你有所帮助。
若需参看原文,请查阅文末链接。
摘要
大多数视频都包含着大量事件。举例来说,在一段钢琴演奏视频中,可能不仅仅包含钢琴演奏者,还可能包含着跳舞的人,或者鼓掌的观众。本论文提出了密集事件描述任务——检测和描述视频中的事件。作者提出了一个新模型,它可以识别出视频某一通道中的所有事件,同时还能用自然语言描述检测出的事件。
我们的模型介绍了一个与已有方法不同的描述模块,它可以捕捉到发生时间为几分钟到几十分钟的事件。为了捕捉视频中不同事件间的关系,该模型引入了一种新的描述模块(captioning module),该模块可以结合从过去和未来事件中得出的上下文信息,用它们来描述所有事件。作者还提出了ActivityNet Captions,这是一个用于密集事件描述任务的大型基准测试数据集。这个数据集包含了2万个视频(共长达849小时)以及10万条带有开始和结束时间的描述信息。最后,作者报告了该模型在密集事件描述、视频检索和定位任务中的性能。
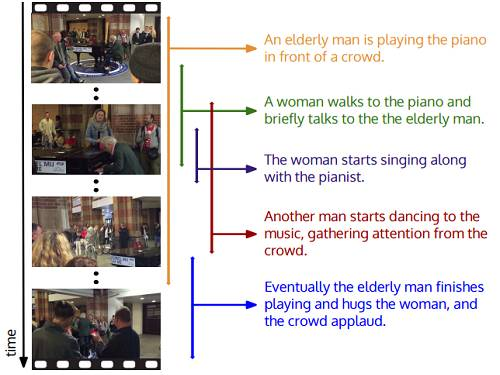
图1:密集事件描述任务要求模型检测和使用自然语言描述视频中发生的每个事件。这些事件有各自的开始时间和结束时间,因此事件可能同时发生,在时间上发生重叠。
1.引言
利用大型的活动数据集,模型可以将视频中的事件分类为一系列互不关联的行为类别。例如,在图1中,此类模型会输出“弹钢琴”或“跳舞”这样的标签。尽管这些方法取了很好的结果,但是它们有一个重要的局限:细节。
为了解决现有行为检测模型的细节缺失问题,论文作者通过试验探讨了如何使用语句描述解释视频含义。例如,在图1中,模型可能会集中注意在人群前弹奏钢琴的老人。虽然模型可以通过描述告诉我们是谁在谈钢琴以及现场有一群观众在观看表演,但是它未能识别并描述出视频中的所有其他事件。例如,在视频中的某一点,一位女士开始跟着演奏者一起唱起歌来,之后一名男士开始伴着音乐跳起舞来。为了让模型能识别并以自然语言描述视频中的所有事件,作者提出了密集事件描述任务,这种任务要求模型根据视频中发生的多个事件生成一系列描述,并在视频中对这些事件进行时间上的定位。
密集事件描述任务类似于密集图像描述任务。不同之处在于:前者要求模型对视频中的事件进行描述和时间上的定位,而后者则要求模型对图像区块(regions)进行描述和空间上的定位;处理这两种任务时需要解决的问题不同。视频中的事件可能发生于多个时域内,不同的事件可能会重叠在一起。
在视频中,钢琴演奏这个事件可能从头到尾都在发生,但是观众鼓掌这个事件只发生了十几秒。为了捕捉到所有事件,我们需要对长视频序列和短视频序列进行编码,来对事件进行描述。以往的方法使用均值池化法或循环神经网络(RNN)对整个视频序列进行编码,从而绕过了这个问题。在处理短视频时此类方法很好用,但是如果对长达几分钟或几十分钟的长视频序列进行编码,就会出现梯度消失的问题,从而导致无法成功地训练模型。为了克服这个局限,作者将 action proposals生成上的近期研究成果应用到了多时域事件检测任务中。另外,作者引入的模块在前向通道中处理每个视频,这样模型就可以在事件发生的同时对其进行检测。
该论文还发现:视频中的各事件之间往往存在联系。在图1中,观众鼓掌的原因是因为演奏者表演了钢琴弹奏。因此。模型必须能够利用从前后事件中得出的上下文信息,来捕捉每个时间。最近发表的一份论文试图通过多个语句来描述视频中的事件;但是论文中使用的是“烹饪”教学视频,视频中的事件和物体之间存在很高的关联性,而且事件有一定的发生顺序。
作者证明了他们的模型并不能适用于“开放”时域(“open” domain)视频,这此类视频中,事件的发生是由行为主导的,而且不同事件可能会重叠在一起。作者提出了一种描述模块,该模块可以使用action proposal模块中所有事件的上下文信息,为每个事件生成描述语句。另外,作者还给出了一个描述模块(captioning module)的变体,这个变体可以只根据前面发生的事件,对流视频(streaming video)中的事件生成描述。本论文中的模型参考前面和后面发生的事件,证明了使用上下文信息的重要性。
为了评估模型在密集事件描述任务中的性能以及基准的提高程度,我们引入了ActivityNet Captions数据集。ActivityNet Captions包含20000个采集自ActivityNet的视频,每个视频包含一系列时序定位的描述语句。为了验证模型对长视频序列的检测,数据集中包含有长达10分钟的视频,每个视频平均标记有3.65个语句。这些语句描述的是可能同时发生并导致视频片段重叠的事件。虽然本论文使用的是关于人类活动的视频,但是描述可能会涉及非人为事件,例如:两个小时后,材料一块美味的蛋糕。作者使用众筹(crowdsourcing)的方式收集描述,在这个过程中发现时序事件视频片段之间存在高度的一致性。这一发现验证了一些研究的结论:大脑活动会被本能地转化为在语义上有意义的事件。
借助ActivityNet Captions,我们率先在密集事件描述任务中得出结果。我们结合使用了proposal模块和在线描述模块,证明了我们可以检测和描述长视频或流视频中的事件。而且,我们证明了我们能够检测出长视频序列和短视频序列中的事件。另外,我们还证明了使用从其他事件中得出的上下文信息可以提升模型在密集事件描述任务中的性能。最后,我们证明了ActivityNet Captions可以被用于研究视频检索和事件定位。
论文地址:
http://openaccess.thecvf.com/content_ICCV_2017/papers/Krishna_Dense-Captioning_Events_in_ICCV_2017_paper.pdf
关于这篇论文,营长就不做过多解析了,以下是知乎上两位同学的分析,供参考。
原文地址:
https://www.zhihu.com/question/59639334/answer/167555411
知乎答主:米特兰
整个框架主要分成两部分:proposal module和captioning module。
模型如下:
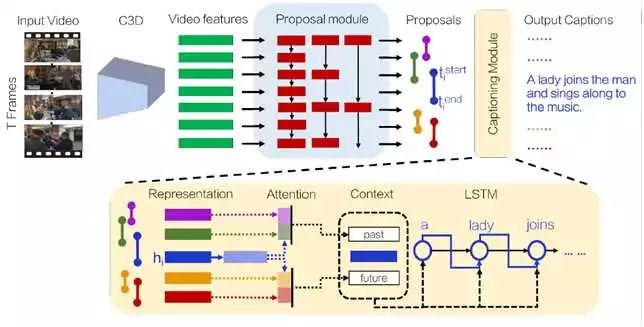
1.给定视频,生成特征序列。实验中以16帧为单位,输入C3D提取特征。
2.proposal module。proposal module是在DAPs的基础上做了一点修改,即在每一个time step输出K个proposals。采用LSTM结构,输入上述C3D特征序列,用不同的strides提取特征序列,strides={1,2,4,8}。生成的proposal在时间上会有重叠。每检测出一个event,就将当前的隐藏层状态作为视频描述。
3.captioning module。利用相邻事件的context来生成event caption。采用LSTM结构。
将所有的事件相对于当前事件分成两个桶:past events和future events。并发事件则依据结束时间分成past events和future events。计算公式如原文,不在此列出。
4.损失函数由两部分组成:
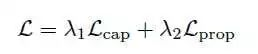
都采用cross-entropy。
5.实验:baseline:LSTM-YT、S2VT、H-RNN、full model和online model。其中full model是本文中模型,online model是在full model中只采用past events,而不采用future events。
6.评估:分别对proposal module和captioning module进行评估。
proposal model:recall,依赖两个条件:
-
the number of proposals and
-
the IoU with ground truth events。同时也测试不同的strides在event localization中的效果。
captioning module:采用video retrieval。即给定视频不同部分的描述,在测试集中检测出正确的视频。
本文模型解决的问题:
-
视频长短不一致。
-
事件之间的相互联系。
我认为本文的主要贡献有以下几点:
-
提出proposals module+captioning module,只处理一次视频就能同时生成short和long event。
-
利用neighboring events的context生成current event caption。
-
提出ActivityNet Captioning数据集
知乎答主:杨科
framework大致是:action segmentation proposal + video caption,首先做行为片段(或者说segmentation of interest吧)proposal,然后在proposal上做video caption;其中action segmentation proposal用的是eccv16的DAPs【1】。
【1】2016-eccv-DAPs Deep Action Proposals for Action Understanding
关于video caption,诸位可以去看知友@林天威最近的专栏文章(天威的专栏干货满满,做video相关的研究可以关注一下)
Video Analysis 相关领域介绍之Video Captioning(视频to文字描述)
https://zhuanlan.zhihu.com/p/26730181
我感觉最大的贡献是提出了这个dense video caption 的数据集(或者说task)吧,算法只是做一个baseline而已,(数据集在ActivityNet上加上了caption 的标注,ActivityNet是当前最火的行为识别/检测challenge的视频数据集)。
ActivityNet今年的比赛作为CVPR2017的workshop,FeiFei Li组这篇论文提出的这个dense caption的任务时今年ActivityNet比赛的五个比赛这一,大家伙有兴趣可以去参与一下: http://activity-net.org/challenges/2017/index.html
资源推荐
重磅 | 128篇论文,21大领域,深度学习最值得看的资源全在这了
爆款 | Medium上6900个赞的AI学习路线图,让你快速上手机器学习
Quora十大机器学习作者与Facebook十大机器学习、数据科学群组
Chatbot大牛推荐:AI、机器学习、深度学习必看9大入门视频
葵花宝典之机器学习:全网最重要的AI资源都在这里了(大牛,研究机构,视频,博客,书籍,Quora......)