

LSTM,全称为「长短期记忆」,是一种「时间递归神经网络」(RNN)。LSTM 适合于处理和预测时间序列中间隔和延迟非常长的重要事件。
通俗来讲,LSTM 非常适合用来预测与时间相关的数据,在文本处理方面更是应用广泛 (可以理解为某个词在 t 时间点出现,预测 t+1 时间点最有可能出现哪个词);往专业上讲,呃,我完全不懂。
但这不妨碍我们去使用 LSTM 去做点有趣的事情,好比你不知道电饭煲是怎么做出来的,但你总会煮饭是吧。接下来我们使用 Keras 这个强大的「电饭煲」来煮几煲好吃的饭。
自动写代码
这有点标题党,但其实还是个人工智障。比如你在写代码的时候,写下了这么一段:
def afunc(i):
i = i + 1
retur下一个字符很自然应该是「n」对不对。将一个个字符转化为数字序列作为输入,这些字符组成的序列的下一个字符作为输出,比如,序列长度为 3 的话,return 这个字符序列,可以转化为:
r,e,t -> u
e,t,u -> r
t,u,r -> n然后将这些单个字符分别映射为数字:
r -> 1
e -> 2
t -> 3
u -> 4
n -> 5变成这种形式:
x1 = [1,2,3], y1 = 4
x2 = [2,3,4], y2 = 1
x3 = [3,4,1], y3 = 5这样,我们就可以用 Keras 来训练了。
我使用的是「python requests」去掉了空行和注释的代码作为训练样本。
脚本具体可以参考
https://machinelearningmastery.com/text-generation-lstm-recurrent-neural-networks-python-keras/
训练 40 个 epoch 后的成绩:
Epoch 40/40
217004/217004 [==============================] - 270s - loss: 0.9860效果:

可以看到部分输出确实有点像代码的样子,但是重复的地方也比较多,这是因为过拟合了。
「GRU」是 LSTM 的一个变种,据说结构上比 LSTM 简单,参数少,比 LSTM 在过拟合方面好点:
model = Sequential()
model.add(GRU(256, input_shape=(X.shape[1], X.shape[2]), return_sequences=True))
model.add(GRU(256))
model.add(Dense(y.shape[1], activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')训练 20 个 epoch 的效果:
Epoch 20/20
217004/217004 [==============================] - 224s - loss: 0.8398
可以看到重复性方面解决得比 LSTM 要好,有时间再训练多些看下是否能得到更好的效果。
作诗机器人
其实就是把上面例子里的英文字母,换成汉字。
文本格式如下,冒号分隔诗名和诗,一行一首诗,一共一千首诗。
山阁晚秋:山亭秋色满,岩牖凉风度。疏兰尚染烟,残菊犹承露。古石衣新苔,新巢封古树。历览情无极,咫尺轮光暮。数据处理:
with open('poetry.txt') as f:
raw_text = f.read()
lines = raw_text.split("\n")[:-1]
poem_text = [i.split(':')[1] for i in lines]
char_list = [re.findall('[\x80-\xff]{3}|[\w\W]', s) for s in poem_text]
all_words = []
for i in char_list:
all_words.extend(i)
word_dataframe = pd.DataFrame(pd.Series(all_words).value_counts())
word_dataframe['id']=list(range(1,len(word_dataframe)+1))
word_index_dict = word_dataframe['id'].to_dict()
index_dict = {}
for k in word_index_dict:
index_dict.update({word_index_dict[k]:k})
seq_len = 2
dataX = []
dataY = []
for i in range(0, len(all_words) - seq_len, 1):
seq_in = all_words[i : i + seq_len]
seq_out = all_words[i + seq_len]
dataX.append([word_index_dict[x] for x in seq_in])
dataY.append(word_index_dict[seq_out])
X = np.array(dataX)
y = np_utils.to_categorical(np.array(dataY))序列长度我设置为 2,即用前面两个字来预测下一个字,一共 217687 条数据。
汉字的体量比英文字母高了几个级别,共 4620 个。我们得用 word embedding 来处理,将 one-hot 编码的词,映射为低维向量表达,以降低特征维度。
model = Sequential()
model.add(Embedding(len(word_dataframe)+1, 512))
model.add(GRU(512))
model.add(Dense(y.shape[1]))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')定义一个生成诗的函数:
def gen_poem(seed_text):
rows = 4
cols = 6
chars = re.findall('[\x80-\xff]{3}|[\w\W]', seed_text)
if len(chars) != seq_len:
return ""
arr = [word_index_dict[k] for k in chars]
for i in range(seq_len, rows * cols):
if (i+1) % cols == 0:
if (i+1) / cols == 2 or (i+1) / cols == 4:
arr.append(2)
else:
arr.append(1)
else:
proba = model.predict(np.array(arr[-seq_len:]), verbose=0)
predicted = np.argsort(proba[1])[-5:]
index = random.randint(0,len(predicted)-1)
new_char = predicted[index]
while new_char == 1 or new_char == 2:
index = random.randint(0,len(predicted)-1)
new_char = predicted[index]
arr.append(new_char)
poem = [index_dict[i] for i in arr]
return "".join(poem)为了不会每次都生成一样的句子,我设置了随机从最有可能的 5 个结果里面取。
训练了 25 个 epoch 看下效果:

还不错吧!起码语句还是比较通顺的!
该诗描述了,在一个月明的夜里传来了阵阵的猿声,猿猴才不可惜眼前的这座空城呢,它发现了一面崭新的梳妆铜镜,然而它四处张望,三千里内杳无人烟,找不到镜子的主人。表达了诗人的一种孤寂虚无的情怀。( 原谅我的强行解释 ... )
以下是生成的部分诗句:
1. 清泉落花开,何处不见花。玉门前山水,不得无限情。
2. 二月出长生,何为谁知音。礼容备乐钟,天地气调弦。
3. 小荷恩重重,天涯不相见。一别有事征,云际会春花。
4. 残菊还畏风,金石咸来此。礼容暗通三,天下朝斑竹。
5. 悠然影曲与,云浮黄云际。风何处处在,一杯酒熟金。
训练了 75 个 epoch 的效果:
1. 清泉鸣天不,一杯酒若游。此时月悬舞,一何不归去。
2. 二月明月悬,何不知天涯。今宵似生长,金香玉春色。
3. 小荷休征衣,天不相顾非。今宵光如可,何日更畏凉。
4. 残菊杯色摇,金甲云盖极。风花落日月,云愁思君子。
5. 悠然知天地,何年光彩云。君不可怜故,天涯天地无。
来个七言:
1. 清泉凝愁夜长思,一何处欲待我行。君王道远烟雾里,天地来不相见无。
2. 二月悬舞凤凰天,何年光如可荐严。风动四时得无声,云愁不相如此生。
3. 小荷休气齐复来,金香金屋夹流水。今已枕在何须尽,金香风吹落花开。
4. 残菊杯色犹倚望,云愁夜月悬舞红。今奉君之何须一,云中绣衣襟艳芳。
5. 悠然身自有时人,一生百年无声至。君不可见少别有,一人行晚朝云浮。
文本情感分析
上面都是玩票的性质,接下来用 LSTM 做下比较实用的文本情感分析。
文本情感分析一般是指给出一段文本,然后给机器判断该文本表达的情绪是正面的还是负面的。
比如说:
「太喜欢这个产品了,我会推荐给朋友用。」是正面的,
「垃圾,不推荐,要求退货。」是负面的。
文本情感分析在网上做舆论分析时特别有用。
所用的语料,我爬了下京东的产品评论,url 类似下面这个例子:
https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv3006&productId=2695276&score=1&sortType=5&page=0&pageSize=10&isShadowSku=0参数 productId 为商品的 id;score=1 为一星评论 (负面),score=5 为五星评论 (正面)。
抓好后,整理成 csv 文件,如:
0,"很山寨!根本读不出来,换了两台电脑winXP和win10都读不出来!"
0,"刚买完就降价,必须差评。"
...
1,"很好的移动硬盘,价格合理,不比其它品牌差,很满意。"
1,"办公室必备之物,非常不错"0 表示负面;1 表示正面。差评和好评数量要均衡点。
在这个例子中,跟上面的诗词又不一样了,我们需要分词处理,否则输入序列就太长了。
数据预处理:
import pandas as pd
import numpy as np
import jieba
from keras.preprocessing import sequence
comments = pd.read_csv('jd_comments.csv', encoding='utf-8')
comments['words'] = comments['content'].apply(lambda x: list(jieba.cut(x)))
all_words = []
for w in comments['words']:
all_words.extend(w)
word_dict = pd.DataFrame(pd.Series(all_words).value_counts())
word_dict['id'] = list(range(1, len(word_dict)+1))
comments['w2v'] = comments['words'].apply(lambda x: list(word_dict['id'][x]))
# 规整为 50 个词
comments['w2v'] = list(sequence.pad_sequences(comments['w2v'], maxlen=50))
训练和测试数据:
x_train = np.array(list(comments['w2v']))[::2]
y_train = np.array(list(comments['score']))[::2]
x_test = np.array(list(comments['w2v']))[1::2]
y_test = np.array(list(comments['score']))[1::2]模型:
model = Sequential()
model.add(Embedding(len(word_dict)+1, 256))
model.add(LSTM(256))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])输出只有 1 维,所以激活函数要用 sigmoid,损失函数用 binary_crossentropy。
训练:
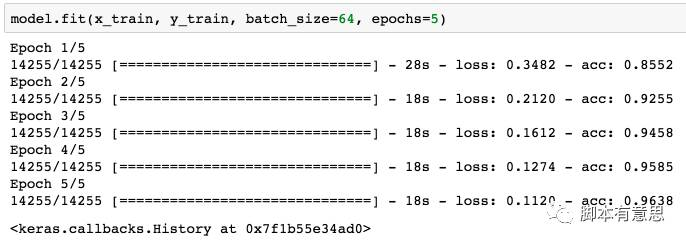
我只用了 14255 条数据,所以训练起来非常快,准确率也达到了 96.38% 。
看下测试数据集的准确率:
model.evaluate(x=x_test,y=y_test,verbose=0)
[0.37807498600423312, 0.87680651045320612]也有 87.68% 的准确率,总体来说还算过得去了。
定义一个函数用来看下效果:
def new_data(new_comment):
words = list(jieba.cut(new_comment))
w2v = [word_dict['id'][x] for x in words]
xn = sequence.pad_sequences([w2v], maxlen=50)
return xn准确率还是不错的:

「他们都说好用,我就呵呵了。」 都能判断正确,神奇了哎。
