

基础概念
堆排序是比较基础的排序算法,也是我认为比较难的一种算法,因为它的流程比较多,理解起来不会像冒泡排序和选择排序那样直观。
要理解堆排序,需要先理解二叉树:
二叉树是每个节点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree),而二叉树还有个名字叫做二叉堆(看起来一堆。。。)。
二叉堆是一棵被完全填满的二叉树,有例外的可能是底层元素,底层元素从左到右填入,这样的树被称为完全二叉树。
仔细观察可以发现,其实一个数组可以被表示成一个二叉树:
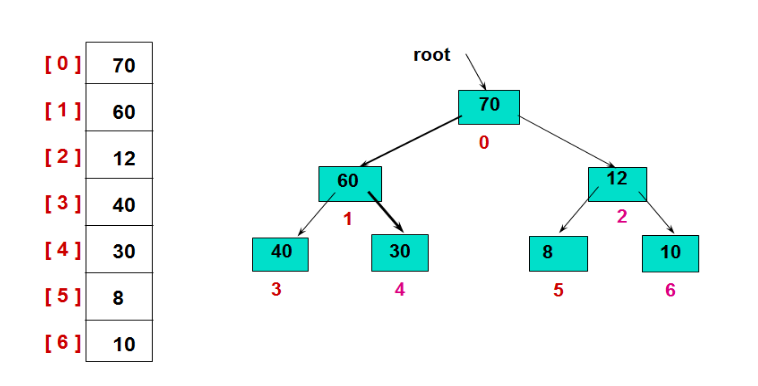
Paste_Image.png
左边为数组,而右边为数组的二叉树的表达方式。
观察上图可以发现,任意一位置i上元素,其左儿子为2i+1上,右儿子在2i+2上。
我们现在的需求是对数组元素进行从小到大排序,那么我们需要根据既定的数据构建堆,这也是堆排序必要的一步。在构建堆的时候,我们需要满足堆序性质。
堆序性质:任意一个节点小于(大于)它的后裔,这取决于你测排序方式。
这里以从小到大排序为例。那么,此时我们需要节点要小于它的后裔,那么这样我们就可以保证根节点是最小的元素。
堆排序主要分三步:
(1).构建堆
(2).调整堆
(3).堆排序
首先需要明确一点,构建堆是在数组基础上构建的,换句话说就是将数组抽象成一个二叉堆,而不需要另构建。
在构建堆之前需要保证一点,构建之后的结构需要堆序性质,什么是堆序性质?
堆序性质所描述的是:在一个二叉堆中任意父节点大于其两个子节点。
堆排序的流程和实现
下面通过一个例子来看一下堆排序是一个怎样的流程。
首先要构建堆,构建堆其实是先将数组抽象成二叉堆之后调整堆的过程。
首先给定数组S、O、R、T、E、X、A、M、P、L、E,排序规则为字典序。
根据已知数组构建堆如下:
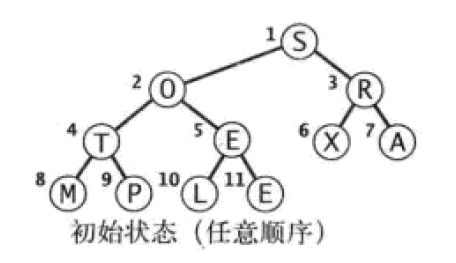
Paste_Image.png
上图可以看出来,初始的堆顺序和数组顺序是一致的。显然上图是不符合堆序性质的,那么接下来需要进行堆的调整。
调整堆时我们需要制定一个起始点进行调整,我们将这个起始点定为N/2,N为目标数组的长度。由于二叉堆是一个完全二叉树,那么N/2对应着倒数第二层,且有子节点的最后一个节点(没有子节点不需要进行调整)。那么这个节点是E节点index为5。由于E字典序小于L,同时需要构建大根堆,所以需要交换E和L。
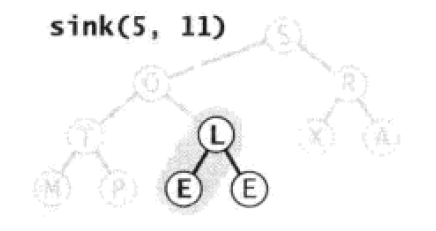
Paste_Image.png
接下来调整到T节点,T节点大于下面两个节点,那么不需要进行调整。
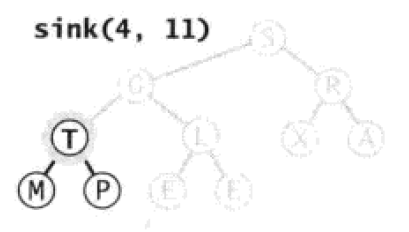
Paste_Image.png
接下来到R节点,由于R小于X,所以进行交换:
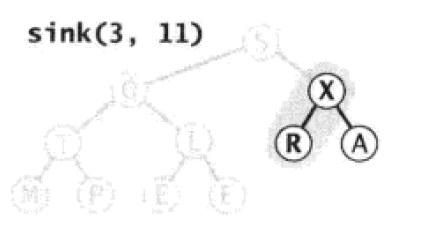
Paste_Image.png
接下来调整到O节点,O节点比较特殊,它小于T节点同时小于P节点,所以O节点会下沉到最后一层。
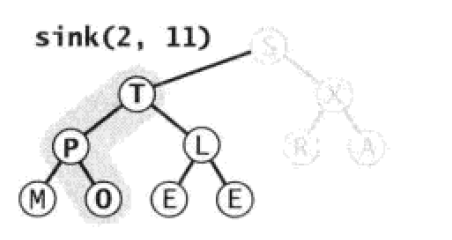
Paste_Image.png
最后调整到S节点,由于S小于X,那么进行调整:
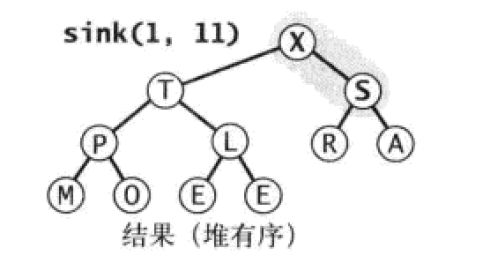
Paste_Image.png
调整之后的结构如上所示,上述堆结构保证了堆的有序,继而能确定全局的最大节点X。
构建堆的代码如下:
/**
* 此调整为从上到下调整,直到节点超出范围
* @param data
* @param heapSize
* @param index
*/
private static void maxHeap(String[] data,int heapSize,int index){
//取得当前节点的左右节点,当前节点为index
int left=getChildLeftIndex(index);
int right=getChildRightIndex(index);
//对左右节点和当前节点进行比较
int largest=index;
if(left<heapSize&&data[index].compareTo(data[left])<0){
largest=left;
}
if(right<heapSize&&data[largest].compareTo(data[right])<0){
largest=right;
}
//交换位置
if(largest!=index){
String temp=data[index];
data[index]=data[largest];
data[largest]=temp;
maxHeap(data,heapSize,largest);
}
}
/**
* 初始化构建堆
* @param data
*/
private static void buildMaxHeap(String[] data){
//根据最后一个元素获取,开始调整的位置
int startIndex=getParentIndex(data.length-1);
//反复进行调整
for(int i=startIndex;i>=0;i--){
maxHeap(data,data.length,i);
}
}其实搞定了调整堆,堆排序就成功了一半了,那么接下来需要做的是,循环N次 ,进行N次调整堆操作,每一次调整 堆得到的最大值,将此值和数组的最后一个元素进行交换,交换后“减小”数组的长度(最后n个值不参与堆的调整),直到最后一个元素,就完成了堆的排序.
此过程是从上到下的调整过程,因为构建好之后的堆具有堆序性质,从根节点调整时只选择一个子节点一直进行调整即可。
代码如下:
/**
* 排序操作
* @param data
*/
private static void heapSort(String[] data){
//每次循环都能取到一个最大值,该值为根节点
for(int i=data.length-1;i>0;i--){
String temp=data[0];
data[0]=data[i];
data[i]=temp;
//每次调整都是从根节点开始i不断减小,保证前一次最大节点不会参与到调整堆
maxHeap(data,i,0);
}
}从代码可以看出来,每次调整都是从根节点开始,不断的缩小排序范围。继而达到把所有的节点全部排序。
完整代码如下:
package heapsort;
public class HeapSort{
private static String[] sort=new String[]{"S","O","R","T","E","X","A","M","P","L",
"E"};
public static void main(String[] args){
buildMaxHeap(sort);
heapSort(sort);
print(sort);
}
/**
* 初始化构建堆
* @param data
*/
private static void buildMaxHeap(String[] data){
//根据最后一个元素获取,开始调整的位置
int startIndex=getParentIndex(data.length-1);
//反复进行调整
for(int i=startIndex;i>=0;i--){
maxHeap(data,data.length,i);
}
}
/**
* 此调整为从上到下调整,直到节点超出范围
* @param data
* @param heapSize
* @param index
*/
private static void maxHeap(String[] data,int heapSize,int index){
//取得当前节点的左右节点,当前节点为index
int left=getChildLeftIndex(index);
int right=getChildRightIndex(index);
//对左右节点和当前节点进行比较
int largest=index;
if(left<heapSize&&data[index].compareTo(data[left])<0){
largest=left;
}
if(right<heapSize&&data[largest].compareTo(data[right])<0){
largest=right;
}
//交换位置
if(largest!=index){
String temp=data[index];
data[index]=data[largest];
data[largest]=temp;
maxHeap(data,heapSize,largest);
}
}
/**
* 排序操作
* @param data
*/
private static void heapSort(String[] data){
//每次循环都能取到一个最大值,该值为根节点
for(int i=data.length-1;i>0;i--){
String temp=data[0];
data[0]=data[i];
data[i]=temp;
//每次调整都是从根节点开始i不断减小,保证前一次最大节点不会参与到调整堆
maxHeap(data,i,0);
}
}
/**
* 获取父节点的位置
* @param current
* @return
*/
private static int getParentIndex(int current){
return(current-1)>>1;
}
/**
* 获得左子节点的位置
* @param current
* @return
*/
private static int getChildLeftIndex(int current){
return(current<<1)+1;
}
/**
* 获得右子节点的位置
* @param current
* @return
*/
private static int getChildRightIndex(int current){
return(current<<1)+2;
}
private static void print(String[] data){
for(int i=0;i<data.length;i++){
System.out.print(data[i]+",");
}
}
}时间复杂度
堆排序是一种十分高效的排序算法,因为它的排序流程分三步,那么可以分别计算时间复杂度进行相加:
1.构建堆:
构建堆是从N/2处开始进行调整,每一次调整的时间复杂度为节点的深度H,那么N/2次调整则为O(H1)+O(H2).....O(HnN/2)。由于H为常数,那么时间复杂度为O(N)
2.调整堆:
调整堆比较简单,由二叉堆具有堆序性质,那么调整堆的过程其实,就是堆的深度即lgN
3.堆排序
此过程是进行N-1次调整堆的操作,那么此过程的时间复杂为(N-1)lgN。
汇总后整体的时间复杂度为O(N+(N-1)*lgN)
~ O(NlgN)
可见堆排序的时间复杂度是比较低的,但是这种排序一般比较适合大数据集合的排序,因为大量使用了递归操作,那么在小数据集的情况下是十分消耗性能的,在小数据集的情况下最好使用插入、选择这种简单的排序算法,往往能起到更好的效果。
对TopK问题的优势:
堆排序另外一个比较好的特性就是TopK,因为堆排序是渐进排序,也就是说不是将所有的数据排序好后输出。这种特性也就决定了,在TopK场景往往能够有更好的表现。
空间复杂度
从上面程序可以看出来,我们并没有引入第二个存储元素,而每一次元素的交换仅仅依靠一个元素的存储空间,所以堆排序的空间复杂度为O(1)
参考:
