

12月的第一天,祝所有小伙伴儿的12月都能够被温柔以待。
能在学校悠哉写推送的日子所剩不多了,为了珍惜剩下所剩不多的推送机会,打算12月写一些实践性强一些的内容,比如数据库(包括关系型的和noSQL)。
前段时间一直在探索数据抓取的内容,那么现在问题来了,抓完数据如何存储呢?
保存成本地文件是一种方案,但是借助关系型数据库或者noSQL数据库,我们可以给自己获取的数据提供一个更为理想的安身之所。
今天这一篇粗浅的聊一聊非结构化数据存储,以及R语言和Python与mongoDB之间的通讯。
写这一篇是因为之前在写web数据抓取的时候,涉及大量的json数据,当然我们可以直接将json转换为R语言(dataframe/list)或者Python(dict/DataFrame)中的内置数据对象,但是保存原始数据往往也很重要,即便是list或者dict,如果不能转化为关系型表格,通常也需要在本地保存成json格式的数据源。
那么通过mongoDB这种专业的noSQL数据库来保存非结构化数据,可以完成批量保存、批量读取、条件查询和更新,这样可以集中维护,显得更具有安全性、便利性、专业性。
mongo数据库的数据对象是bson,这种数据结构相当于json标准的扩展,R语言中的list可以与json互转,Python中的dict本身就与json高度兼容。
R语言
在R语言中,通常通过rmongodb包来进行非结构化数据存储。(当然有替代的包,只是这个包资料相对较多一些!)
###下载:
devtools::install_github("mongosoup/rmongodb")
library("rmongodb")
创建/断开连接
mongo <- mongo.create(host = "localhost")
mongo.is.connected(mongo) #检查是否连接成功
mongo.destroy(mongo) #断开连接
关于如何在系统中启动mongodb服务,网络上有很多此类教程,照葫芦画瓢就好,如果你想使用一个类似MySQL的navicat那样的可视化操作界面,可以考虑安装Robo可视化界面,这样基本就可以手动操作mongodb中的数据对象了。
mongodb中的数据对象,与MySQL中的数据对象略有不同,不过从层级上来看,仍然是分成数据库 》集合(表) 》key-value.
一个数据库中可以有很多个集合(相当于表),每一个集合中又包含很多的documents结构。每一个documents作为一条记录,相当于SQL中的一行,而documents内是键值对结构,且允许包含嵌套结构。一个documents对象内嵌套的同一层级key-value对象,被称为fileds,可以近似理解为SQL中的column。
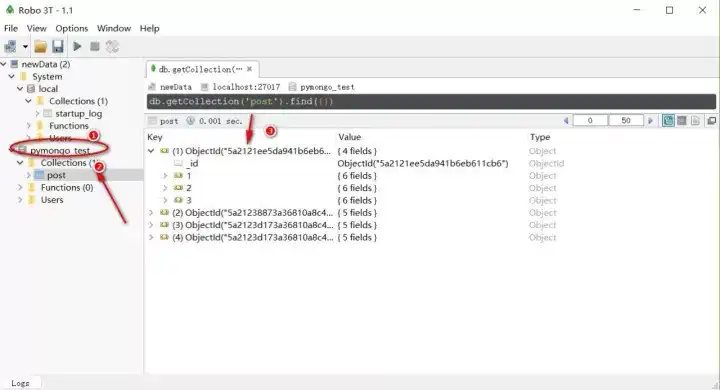
mongodb的数据对象叫做bson,是Binary JSON Serialization的缩写简称,关于详细的json和bson的概念及其内含关系,可以查阅相关资料,或者通过W3C网站了解。
接下来进入R语言与mongodb链接的操作讲解。
以上已经建立了一个名为mongo的链接(mongo.is.connected结果可以用于测试连接是否成功!)。
###查看本地数据库文件
mongo.get.databases(mongo) #查看本地数据库名称
mongo.get.database.collections(mongo, db = "pymongo_test") #查看pymongo_test数据库内的各个集合名称
mongo.count(mongo, ns = "pymongo_test") #查看pymongo_test数据库内的集合数量
mongo.rename(mongo, "pymongo_test.posts", "pymongo_test.post") #修改pymongo_test数据库内posts表名称
删除操作
mongo.drop.database(mongo, db = "database")
#移除数据库及其内部所有集合
mongo.drop(mongo, ns = "database.collection")
#仅删除数据库内全部集合(collection)
mongo.drop(mongo, ns = "rmongo_test.mydata1")
#移除数据集合内的某一特定表
mongo.remove(mongo, ns, criteria = mongo.bson.empty())
#移除集合内选定条件的记录
其中ns是命名空间参数,格式为“数据库名称.集合名称”。
rmongodb内没有专门创建数据库或者在数据库中创建集合的函数,想要创建的话仅需在插入数据时指定一个不存在的ns参数即可。
R语言中的非结构化数据对象是list,因为list结构与json或者bson差别比较大,在插入mongo之前需要使用特定函数进行list/json与bson之间的相互转化。
涉及转化的函数有两个:
mongo.bson.from.JSON #将json对象转换为mongodb中的bson对象。
mongo.bson.from.list #将list对象转换为mongodb中的bson对象。
使用json格式数据插入mongo
#新建一个json对象
json <- '{"A":1,"B":2,"C":{"D":3,"E":4}}'
[1] "{\"A\":1,\"B\":2,\"C\":{\"D\":3,\"E\":4}}"
#如果你不想手写json,也可以使用jsonlite包中的toJSON函数(一定记得anto_unbox设置为RUE)
json <- jsonlite::toJSON(list("A"=1,"B"=2,"C"=list("D"=3,"E"=4)),auto_unbox = TRUE)
{"A":1,"B":2,"C":{"D":3,"E":4}}
#注:使用jsonlite::toJSON函数将一个list转为一个json字符串,这个字符串拥有一个名为json的类,
但是并未改变其内容,仅仅是添加了一个类,同时输出的外观优化了下。所以以上两种list转json的方法等价。
#将json对象转换为mongodb可识别的bson对象:
bson <- mongo.bson.from.JSON(json)
A : 16 1
B : 16 2
C : 3
D : 16 3
E : 16 4
#转化为basn后的数据结构内容未变,但是出现了树状层级结构。
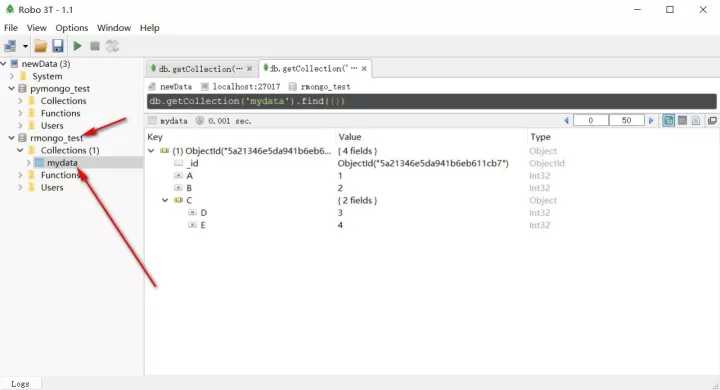
插入mongo(注意这里的rmongo_test.mydata是数据库名+“.”+表名,而且数据库名和表明都是不存在的,这样会自动创建新数据库及表)
mongo.get.databases(mongo)
[1] "pymongo_test"
mongo.insert(mongo,ns="rmongo_test.mydata",bson)
[1] TRUE
mongo.get.databases(mongo)
[1] "pymongo_test" "rmongo_test"
使用list结构插入mongodb与使用json格式步骤差不多,不同的是要使用list转bson的转化函数。
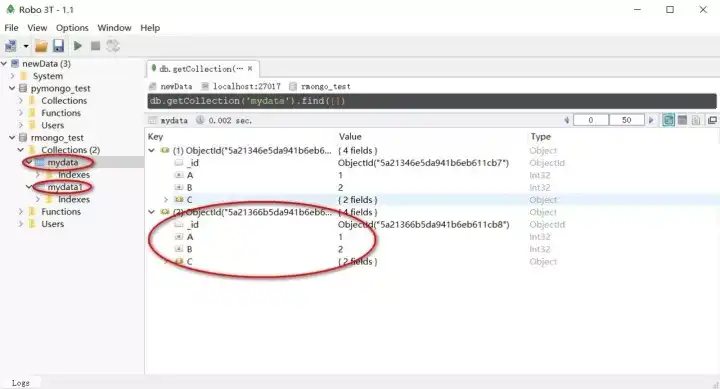
list <- list(a=2, b=3, c=list(d=4, e=5))
bson <- mongo.bson.from.list(list)
mongo.insert(mongo,"rmongo_test.mydata",bson)
#使用之前的数据库+表名会将本次插入的记录添加到mydata已经存在的记录后面
mongo.insert(mongo,"rmongo_test.mydata1",bson)
#换一个表名则会在rmongo_test数据库中新建一个表
mongo.drop(mongo, ns = "rmongo_test.mydata1")
#移除数据集合内的某一特定表(删掉刚才新插的mydata1)
数据查询
查询其中一条记录(第一条),使用mongo.find.one函数。
tmp <- mongo.find.one(mongo, ns = "rmongo_test.mydata")
_id : 7 5a21346e5da941b6eb611cb7
A : 16 1
B : 16 2
C : 3
D : 16 3
E : 16 4
tmp对象是一个bson结构,需要转化为list才能得到内置数据结构。
tmp <- mongo.bson.to.list(tmp)
$`_id`
{ $oid : "5a21346e5da941b6eb611cb7" }
$A
[1] 1$B
[1] 2$C
$C$D
[1] 3$C$E
[1] 4
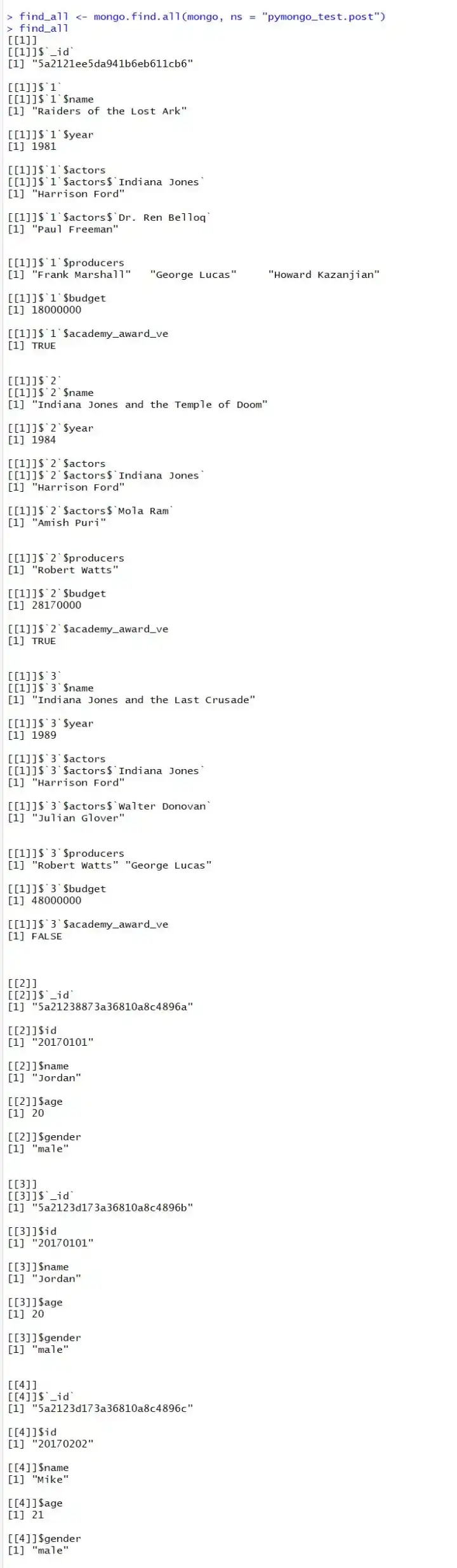
查询表中所有记录要使用mongo.find.all函数。
find_all <- mongo.find.all(mongo, ns = "pymongo_test.post")
#find_all直接是将post内的bson对象转化为一个list,很奇怪,
#为啥mongo.find.one输出的是一个bson,需要使用函数转为list,不是很理解设计的原因。
mongo.find函数可以支持条件查询:
#创建索引条件:
buf <- mongo.bson.buffer.create()
mongo.bson.buffer.append(buf, name="gender", value="male")
query <- mongo.bson.from.buffer(buf)
构造查询:
cursor <- mongo.find(mongo,"pymongo_test.post",query)
[1] "mongo.cursor"
cursor对象类似SQL中的一个游标对象,不能直接查看内部结构,需要借助迭代函数进行输出
while (mongo.cursor.next(cursor)) #判断是否还有剩余迭代次数
print(mongo.cursor.value(cursor)) #打印当前迭代记录
mongo.cursor.destroy(cursor) #关闭查询游标
_id : 7 5a21238873a36810a8c4896a
id : 2 20170101
name : 2 Jordan
age : 16 20
gender : 2 male
_id : 7 5a2123d173a36810a8c4896b
id : 2 20170101
name : 2 Jordan
age : 16 20
gender : 2 male
_id : 7 5a2123d173a36810a8c4896c
id : 2 20170202
name : 2 Mike
age : 16 21
gender : 2 male
所以也可以把cursor当成是一个迭代器,想要提取里面的查询数据,需要构造循环与迭代函数,自行提取,而mongo.find.one函数和mongo.find.all函数相当于两个快捷函数,直接提取符合条件的记录或者所有记录。
rmongosb的mongo.find函数可以支持mongodb原生的复杂查询,支持很多高级符号函数,这一点儿我暂未深入了解,留待以后再做探讨。如果你想要详细的了解mongodb的用法, 最好参考关于mongodb的专业操作书,rmongodb内的函数与mongodb的原生函数相比,还有很多地方不完善,无法支持,不过对于平时的数据存储而言最够了,用的最频繁的就是插入、读取操作了。
Python:
from pymongo import MongoClient,ASCENDING, DESCENDING
import pymongo,json
之前说到过,因为Python中的dict与json高度兼容(并不代表一模一样),而bson结构又是基于json的扩展,所以在Python中可以直接将dict插入mongodb数据库,而基本无需做类型转换,这一点儿Python完胜R语言。
#连接MongDB:
client = MongoClient()
client = MongoClient(host='localhost',port= 27017)
client = MongoClient('mongodb://localhost:27017')
以上三种连接方法等价。
#连接数据库:
db = client.pymongo_test
db = client['pymongo_test']
以上两句等价,用于连接数据库,与Python中访问属性的操作相同。
#指定集合(相当于SQL中的table)
collection = db.post
collection = db['post']
以上两句等价,db的基础上连接mongodb中的集合(相当于表)。
使用本地的json数据,创建一个带插入的临时dict结构:
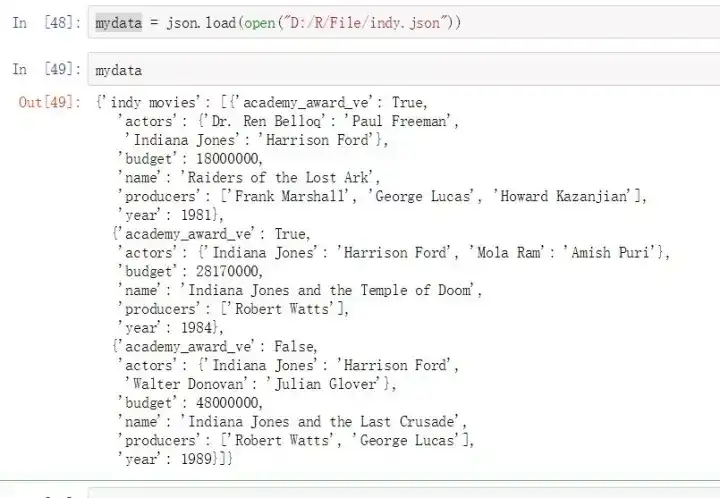
mydata = json.load(open("D:/R/File/indy.json"))
mydata = mydata['indy movies']
mydata1 = mydata[1];mydata1
mydata2 = mydata[-2:];mydata2
为了防止数据混乱,现将之前在R语言中添加的表记录删除:
collection.remove({})
collection.insert_one(mydata1)
results = collection.find_one()
{'_id': ObjectId('5a2143c573a36810a8c4896f'), 'academy_award_ve': True, 'actors': {'Indiana Jones': 'Harrison Ford', 'Mola Ram': 'Amish Puri'}, 'budget': 28170000, 'name': 'Indiana Jones and the Temple of Doom', 'producers': ['Robert Watts'], 'year': 1984}
当然也可以一次插入多条记录,不过将记录构造成一个列表即可。
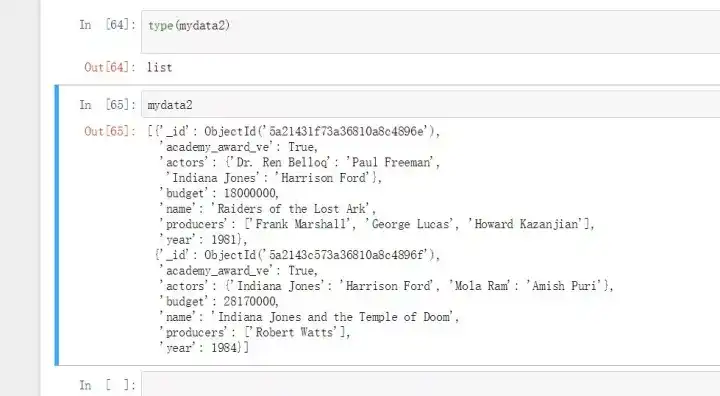
type(mydata2)
list
collection.remove({})
collection.insert_many(mydata2)
for item in collection.find():
print(item)
{'_id': ObjectId('5a2143c573a36810a8c4896f'), 'name': 'Indiana Jones and the Temple of Doom', 'year': 1984, 'actors': {'Indiana Jones': 'Harrison Ford', 'Mola Ram': 'Amish Puri'}, 'producers': ['Robert Watts'], 'budget': 28170000, 'academy_award_ve': True}
{'_id': ObjectId('5a21451673a36810a8c48970'), 'name': 'Indiana Jones and the Last Crusade', 'year': 1989, 'actors': {'Indiana Jones': 'Harrison Ford', 'Walter Donovan': 'Julian Glover'}, 'producers': ['Robert Watts', 'George Lucas'], 'budget': 48000000, 'academy_award_ve': False}
查询函数可以直接提供给for循环进行记录的遍历。
mangodb不允许插入重复记录,还有一些保留字符要注意。(比如英文句点“.”)
查询则提供了更为丰富的函数及可选参数。
#查询一条记录:
results = collection.find_one({'budget': 28170000})
{'_id': ObjectId('5a2143c573a36810a8c4896f'), 'academy_award_ve': True, 'actors': {'Indiana Jones': 'Harrison Ford', 'Mola Ram': 'Amish Puri'}, 'budget': 28170000, 'name': 'Indiana Jones and the Temple of Doom', 'producers': ['Robert Watts'], 'year': 1984}
条件查询:
results = collection.find({'year': 1984})
for result in results:
print(result)
{'_id': ObjectId('5a2143c573a36810a8c4896f'), 'name': 'Indiana Jones and the Temple of Doom', 'year': 1984, 'actors': {'Indiana Jones': 'Harrison Ford', 'Mola Ram': 'Amish Puri'}, 'producers': ['Robert Watts'], 'budget': 28170000, 'academy_award_ve': True}
查询条件支持符号函数以及正则表达式:
results = collection.find({'budget': {'$gt':30000000}})
#budget大于30000000的记录
for result in results:
print(result)
{'_id': ObjectId('5a21451673a36810a8c48970'), 'name': 'Indiana Jones and the Last Crusade', 'year': 1989, 'actors': {'Indiana Jones': 'Harrison Ford', 'Walter Donovan': 'Julian Glover'}, 'producers': ['Robert Watts', 'George Lucas'], 'budget': 48000000, 'academy_award_ve': False}
布尔条件查询:
results = collection.find({'academy_award_ve': True})
for result in results:
print(result)
{'_id': ObjectId('5a2143c573a36810a8c4896f'), 'name': 'Indiana Jones and the Temple of Doom', 'year': 1984, 'actors': {'Indiana Jones': 'Harrison Ford', 'Mola Ram': 'Amish Puri'}, 'producers': ['Robert Watts'], 'budget': 28170000, 'academy_award_ve': True}
正则表达式查询:
results = collection.find({'name': {'$regex': 'Doom$'}})
for result in results:
print(result)
{'_id': ObjectId('5a2143c573a36810a8c4896f'), 'name': 'Indiana Jones and the Temple of Doom', 'year': 1984, 'actors': {'Indiana Jones': 'Harrison Ford', 'Mola Ram': 'Amish Puri'}, 'producers': ['Robert Watts'], 'budget': 28170000, 'academy_award_ve': True}
更新操作:
student = collection.find_one({'year':1984})
{'_id': ObjectId('5a2143c573a36810a8c4896f'), 'academy_award_ve': True, 'actors': {'Indiana Jones': 'Harrison Ford', 'Mola Ram': 'Amish Puri'}, 'budget': 28170000, 'name': 'Indiana Jones and the Temple of Doom', 'producers': ['Robert Watts'], 'year': 1984}
collection.update_one({"year": 1984}, {"$set": {"name": "Indiana Jones and Doom"}})
{'_id': ObjectId('5a2143c573a36810a8c4896f'), 'academy_award_ve': True, 'actors': {'Indiana Jones': 'Harrison Ford', 'Mola Ram': 'Amish Puri'}, 'budget': 28170000, 'name': 'Indiana Jones and Doom', 'producers': ['Robert Watts'], 'year': 1984}
删除操作:
result = collection.delete_one({'name': 'Indiana Jones and Doom'})
data1 = collection.find()
for result in data1:
print(result)
{'_id': ObjectId('5a21451673a36810a8c48970'), 'name': 'Indiana Jones and the Last Crusade', 'year': 1989, 'actors': {'Indiana Jones': 'Harrison Ford', 'Walter Donovan': 'Julian Glover'}, 'producers': ['Robert Watts', 'George Lucas'], 'budget': 48000000, 'academy_award_ve': False}
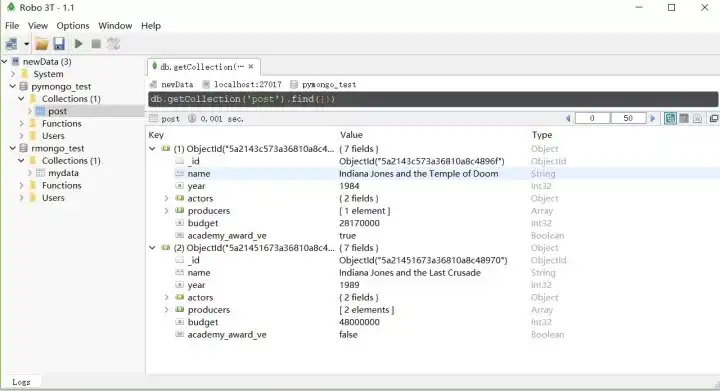
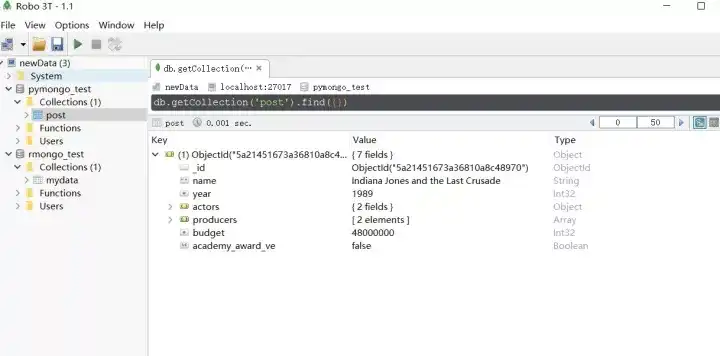
删除之后只剩一个记录了。
Python支持的符号运算符还有很多!
符号含义示例
{'age': {'$lt': 20}} #$lt小于
{'age': {'$gt': 20}} #$gt大于
{'age': {'$lte': 20}} #$lte小于等于
{'age': {'$gte': 20}} #$gte大于等于
{'age': {'$ne': 20}} #$ne不等于
{'age': {'$in': [20, 23]}} #$in在范围内
{'age': {'$nin': [20, 23]}} #$nin不在范围内
正则表达式含义:
{'name': {'$regex': '^M.*'}} #$regex,name以M开头
{'name': {'$exists': True}} #$exists,name属性存在
{'age': {'$type': 'int'}} #$type,age的类型为int
{'age': {'$mod': [5,0]}} #$mod数字模操作,年龄模5余0
{'$text': {'$search': 'Mike'}} #$text文本查询,text类型的属性中包含Mike字符串
{'$where': 'obj.fans_count == obj.follows_count'}#$where高级条件查询,自身粉丝数等于关注数
这些运算符号以及正则表达式可以用在查询、更新、删除等所有操作上。
最后吐槽一句,R语言的rmongodb包的查询函数实在是太麻烦了,很难用,Pymongo的函数设计就很友好。
以上便是R语言、Python与mongodb数据库通讯的基础操作,如果想要了解更为详细的高阶查询操作,可以参考关于mongodb的专业技术书籍及资料。
参考资料:
docs.mongodb.com/manual/refe…
api.mongodb.com/python/curr…
api.mongodb.com/python/curr…
在线课程请点击文末原文链接:
Hellobi Live | R语言可视化在商务场景中的应用
往期案例数据请移步本人GitHub:
github.com/ljtyduyu/Da…
