

本文从 RNN 的局限性开始,通过简单的概念与详细的运算过程描述 LSTM 的基本原理,随后再通过文本生成案例加强对这种 RNN 变体的理解。LSTM 是目前应用非常广泛的模型,我们使用 TensorFlow 或 PyTorch 等深度学习库调用它甚至都不需要了解它的运算过程,希望本文能为各位读者进行预习或复习 LSTM 提供一定的帮助。
序列预测问题已经存在很长时间了。它被认为是数据科学领域里最难解决的问题之一。其中包括多种问题:从预测股价波动到理解人说话的方式,从语言翻译到预测你在 iPhone 键盘上打出的下一个单词。
近年来随着数据科学的技术突破,人们逐渐发现几乎所有的序列问题的最佳解决方案都是长短期记忆网络(即 LSTM),它被认为是最有效的方法。
LSTM 在许多方面比传统的前馈神经网络和 RNN 具有优势,这是因为它会在长时间尺度上有选择地记忆部分特征。本文将详细解释 LSTM 的原理,以让你能够对它进行更好的运用。
Note:为了理解本文内容,你需要一些循环神经网络和 Keras(一种流行深度学习库)的基础知识。
LSTM、GRU 与神经图灵机:详解深度学习最热门的循环神经网络
目录
1. 循环神经网络(RNN)简介
2. RNN 的限制
3. 提升 RNN 的性能:长短期记忆网络(LSTM)
4.LSTM 架构
4.1 遗忘门
4.2 输入门
4.3 输出门
4.4 LSTM 整体过程
5. 使用 LSTM 生成文本
1. 循环神经网络(RNN)简介
以股票市场中某支股票价格这样的连续数据为例。一个简单的机器学习模型(或称人工神经网络)可以通过学习股价历史的某些信息来预测未来价格:股票数量、股票开盘价等等。股票价格取决于股票的这些特征,同时也与过去几天的股票价格相关性很高。实际上,对于一个交易者来说,过去几天的价格(或趋势)是对于未来股价预测的决定性因素之一。
在传统的前馈神经网络中,所有的示例都被认为是独立的。这意味着当模型被用于预测某一天时不会考虑之前几天的股价。
这种时间关联性是由循环神经网络实现的。一个典型的 RNN 就像这样:
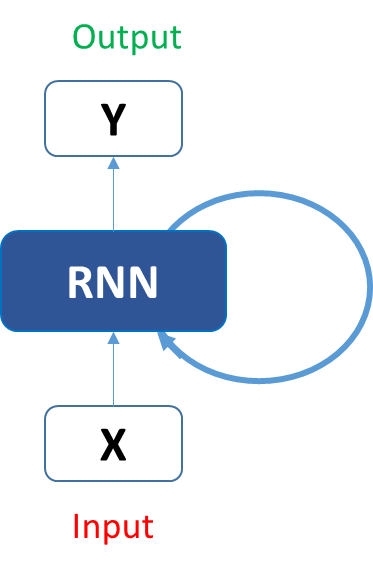
如果将其展开,它会变成这样:
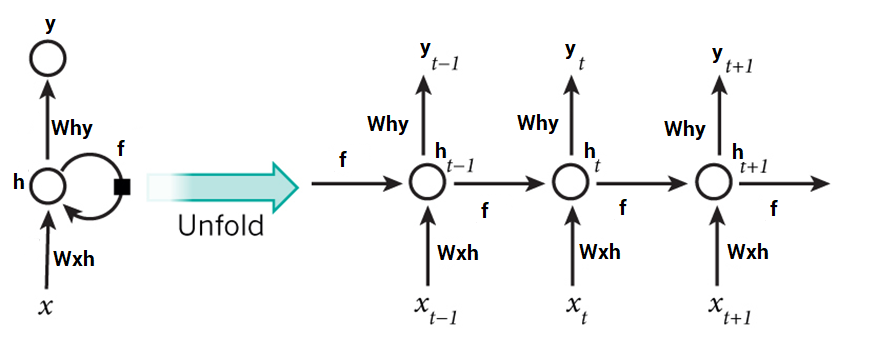
在预测今天的股价之前,我们现在更容易展示这些网络如何预测股票价格的趋势。这里,时间 t (h_t) 处的每个预测都依赖于先前所有的预测以及从中获知的信息。
RNN 可以在很大程度上实现我们处理序列的目的,但不是完全。我们想要计算机足够擅长写作莎士比亚十四行诗。当下 RNN 在短期语境上表现很好,但是为了能够创作一个故事并记住它,我们需要模型理解并记住序列之后的语境,就像人类一样。通过简单 RNN 这不可能实现。
为什么?让我们来探究一下。
2. RNN 的限制
当我们处理短期依赖性时,循环神经网络工作得很好。当应用于像这样的问题:

RNN 被证明相当有效。这是因为该问题与陈述的语境无关。RNN 不需要记住之前的信息,或者其含义,它只需知道大多数情况下天空是蓝的。因此预测将是:

然而,一般 RNN 无法理解输入蕴含的语境。当做出当前预测时,一些过去的信息无法被回忆。让我们通过一个实例理解它:

这里我们之所以能理解是因为作者在西班牙工作了 20 年,他很可能掌握了西班牙语。但是为了做出适当的预测,RNN 需要记住这个语境。相关信息可能会被大量不相关数据从需要的地方分离出来。这正是 RNN 失败的地方!
这背后的原因是梯度消失的问题。为了理解这一点,你需要了解前馈神经网络学习的一些知识。我们知道,对于传统的前馈神经网络,在特定层上应用的权重更新是学习率、来自前一层的误差项以及该层输入的倍数。因此,特定层的误差项可能是先前所有层的误差的结果。当处理像 sigmoid 那样的激活函数时,随着我们移向起始层,其小的导数值(出现在误差函数中)会倍增。结果,随着移向起始层,梯度几乎消失,这些层也变的难以训练。
一个类似情况出现在了 RNN 中。RNN 只有短期记忆,也就是说,如果我们在一小段时间之后需要这些信息是可行的,但是一旦大量的单词被输入,信息就会在某处丢失。这个问题可以通过应用稍加调整的 RNN——长短期记忆网络——来解决。
3. 提升 RNN 的性能:长短期记忆网络(LSTM)
当安排日程时,我们首先会考虑是否有会议预订。但是如果需要为更重要的事情腾出时间,我们可能会取消某些次要的会议。
但是 RNN 并不能做到这样,为了添加一个新信息,它需要通过一个函数完全地转换当前的信息。因此信息是以整体为单位进行修改的,模型并没有考虑重要的和不重要的信息。
另一方面,LSTM 会通过乘法和加法等运算对信息进行局部的修改。因此通过 LSTM,信息流会选择性地通过单元状态,也就是说 LSTM 会选择性地记忆或遗忘某些特征。此外,特定单元状态下的信息共有三种不同的依赖性。
我们将用一些例子理解这一点,若我们特定股票的股价为例,那么当今股价取决于:
前几天的股票走势,如上升或下降等,即前面时间步的单元状态或记忆的信息;
前一天的收盘价,因为它与当天的开盘价有很大的关系,即前一时间步的隐藏单元状态或记忆的信息;
当天可能影响股票的因素,即当前 LSTM 单元的输入值或输入的新信息。
LSTM 另一个比较重要的特征是它的序列处理方式,LSTM 利用这种方式收集更多的信息与语境关系。下图展示了 LSTM 的这种序列式的处理方式:
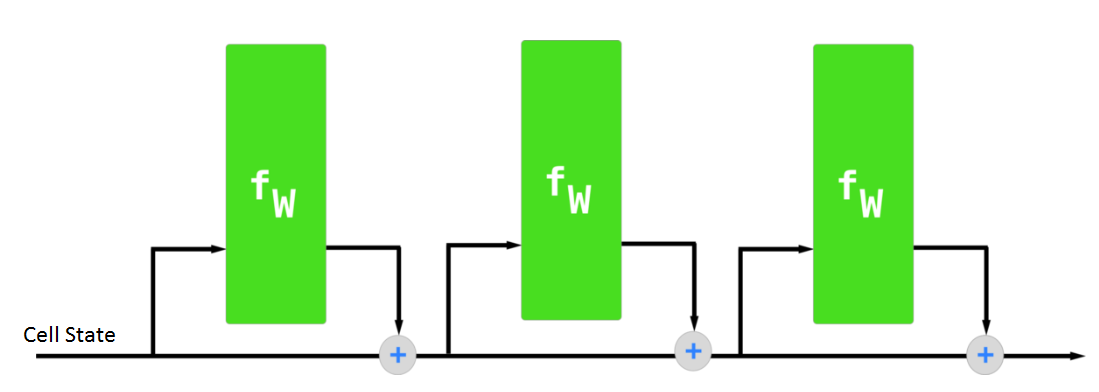
虽然上图并没有表明详细和真实的 LSTM 架构,但它能给我们一个直观的理解。此外,正因为 LSTM 这种属性,它不会对整个信息进行统一的运算,而是稍微修改一些局部的信息。因此 LSTM 可以选择性地记住或遗忘一些事情,它也就有了「较长的短期记忆」。
4.LSTM 架构
通过了解新闻报道谋杀案的过程,我们可以类似地理解与可视化 LSTM 的运算过程。现在假设一条新闻是围绕许多事实、证据和证人所构建的,无论发生任何谋杀事件,我们都可以通过这三方面进行报道。
例如,若最初假设谋杀是通过给被害人下毒完成的,但尸检报告表明死亡原因是「对头部的影响」。那么作为新闻团队的一部分,我们很快就会「遗忘」前面的原因,后主要关注后面的原因而展开报道。
如果一个全新的嫌疑人进入了我们的视角,而该嫌疑人曾怨恨被害者,那么是否他有可能就是凶手?因此我们需要把他「输入」到我们的新闻中作进一步分析。
但是现在所有这些碎片信息都不够在主流媒体上进行报道,因此在一段时间后,我们需要总结这些信息并「输出」对应的结果给我们的读者。也许这个输出就表明并分析了到底谁才是概率最大的凶手。
下面,我们将详细介绍 LSTM 网络的架构:
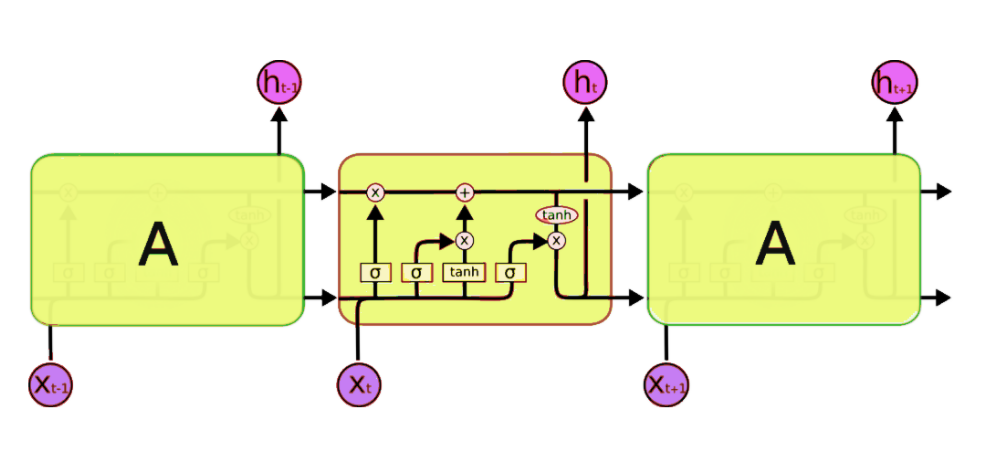
这个架构和我们之间了解的简化版完全不同,但是本文将详细解释它。一个典型的 LSTM 网络由不同的单元或记忆块组成,即上图中我们看到的黄色矩形块。LSTM 单元一般会输出两种状态到下一个单元,即单元状态和隐藏状态。记忆块负责记忆各个隐藏状态或前面时间步的事件,这种记忆方式一般是通过三种门控机制实现,即输入门、遗忘门和输出门。
4.1 遗忘门
我们下面将采用以下语句作为文本预测问题的案例,首先假设该语句已经馈送到 LSTM 网络中。

当模型遇到了「person」后面的第一个句号,遗忘门可能就会意识到下一个语句的语境可能会发生变化。因此语句的主语可能就需要遗忘,主语所处的位置也就空了出来。而当我们讨论到「Dan」时,前面空出来的主语位置就应该分配给「Dan」。遗忘前一语句的主语「Bob」的过程就由遗忘门控制。
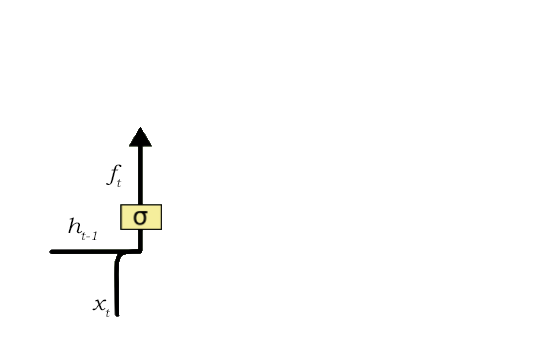
遗忘门负责从单元状态中移除信息,LSTM 不需要这些信息来理解事物,这些不太重要的信息将通过滤波器运算而得到移除。这是优化 LSTM 性能所必须考虑的方面。
该遗忘门采取两个输入,即 h_t-1 和 x_t。h_t-1 为前一个单元的隐藏状态或输出状态,x_t 为特定时间步的输入,即输入序列 x 的第 t 的元素。给定的输入向量与权重矩阵的乘积,再添加偏置项以输入 Sigmoid 函数。Sigmoid 函数将会输出一个向量,取值的范围为 0 到 1,其对应于单元状态中的每个数值。基本上,Sigmoid 函数决定保留哪些值和忘记哪些值。若单元状态取零这个特定值,那么遗忘门就要求单元状态完全忘记该信息。这个输出的 Sigmoid 函数向量最后会乘以单元状态。
4.2 输入门
下面我们使用另一个案例展示 LSTM 如何分析语句:

现在我们知道比较重要的信息是「Bob」知道游泳,且他在海军服役了四年。这可以添加到单元状态,因此这种添加新信息的过程就可以通过输入门完成。
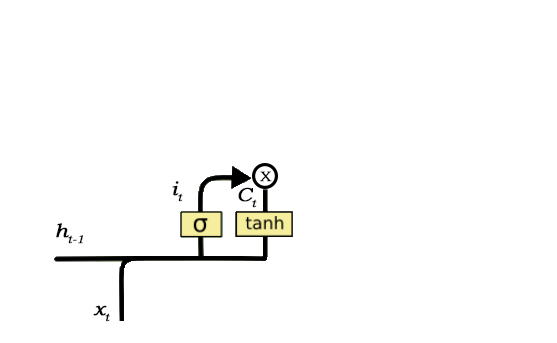
输入门负责将信息添加到单元状态,这一添加信息的过程主要可以分为三个步骤:
- 通过 Sigmoid 函数来调节需要添加到单元状态的值,这与遗忘门非常相似,它起到的作用就是作为一个滤波器过滤来自 h_t-1 和 x_t 的信息。
- 创建一个包含所有可能值的向量,它可以被添加到单元状态中。该过程通过使用 tanh 函数实现,输出值为-1 到 1.
- 将调节滤波器的值(Sigmoid 门控)乘以创建的向量(tanh 函数),然后将这些有用的信息添加到单元状态中。
在完成这三个步骤后,我们基本上确保了添加到单元状态的信息都是重要的,且不是冗余的。
4.3 输出门
并非所有在单元状态运行的信息都适合在特定时间输出。我们将用一个实例进行展示:

在这一语句中,空格处可以有大量选择。但是我们知道空格之前的输入「brave」是一个修饰名词的形容词。因此,不管怎样,空格处存在一个很强的名词倾向。因此,Bob 可能是一个正确的输出。
从当前单元状态中选择有用信息并将其显示为输出的工作是通过输出门完成的。其结构如下:
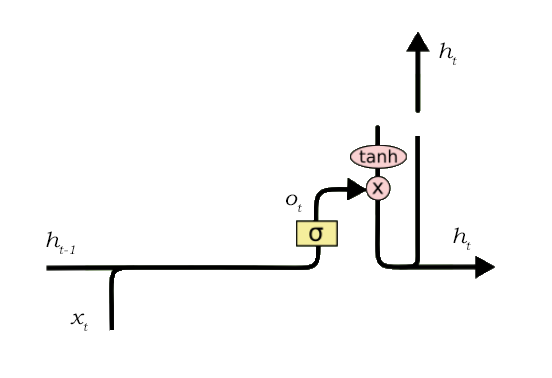
输出门的功能可再次分为三个步骤:
1. 把 tanh 函数应用到单元状态之后创建一个向量,从而将值缩放在-1 到+1 之间。
2. 使用 h_t-1 和 x_t 的值生成一个过滤器,以便它可以调节需要从上述创建的向量中输出的值。这个过滤器再次使用一个 sigmoid 函数。
3. 将此调节过滤器的值乘以在步骤 1 中创建的向量,并将其作为输出发送出去,并发送到下个单元的隐藏态。
上述实例中的过滤器将确保它减少除了「Bob」之外所有其他的值,因此过滤器需要建立在输入和隐藏态值上,并应用在单元状态向量上。
4.4 LSTM 整体过程
以上我们具体了解了 LSTM 的各个部分,但读者可能对 LSTM 的整体过程仍然不是太了解,下面我们简要地向读者介绍 LSTM 单元选择记忆或遗忘的具体处理流程。
以下是 LSTM 单元的详细结构,其中 Z 为输入部分,Z_i、Z_o 和 Z_f 分别为控制三个门的值,即它们会通过激活函数 f 对输入信息进行筛选。一般激活函数可以选择为 Sigmoid 函数,因为它的输出值为 0 到 1,即表示这三个门被打开的程度。
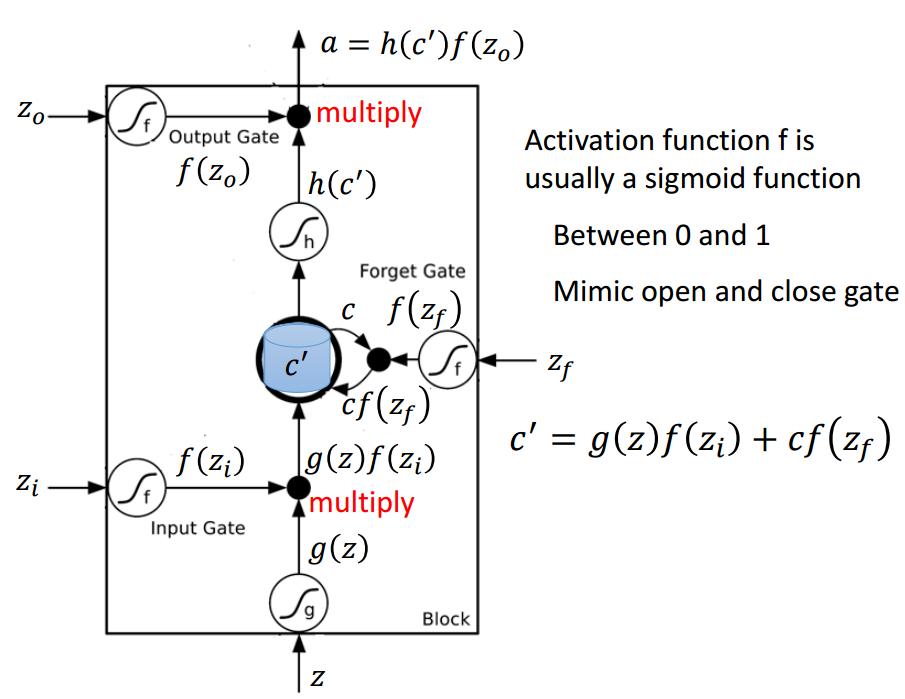
图片来源于李弘毅机器学习讲义。
若我们输入 Z,那么该输入向量通过激活函数得到的 g(Z) 和输入门 f(Z_i ) 的乘积 g(Z) f(Z_i ) 就表示输入数据经筛选后所保留的信息。Z_f 控制的遗忘门将控制以前记忆的信息到底需要保留多少,保留的记忆可以用方程 c*f(z_f)表示。以前保留的信息加上当前输入有意义的信息将会保留至下一个 LSTM 单元,即我们可以用 c' = g(Z)f(Z_i) + cf(z_f) 表示更新的记忆,更新的记忆 c' 也表示前面与当前所保留的全部有用信息。我们再取这一更新记忆的激活值 h(c') 作为可能的输出,一般可以选择 tanh 激活函数。最后剩下的就是由 Z_o 所控制的输出门,它决定当前记忆所激活的输出到底哪些是有用的。因此最终 LSTM 的输出就可以表示为 a = h(c')f(Z_o)。
5. 使用 LSTM 生成文本
我们已经对 LSTM 的理论概念和功能有了足够了解。现在我们尝试建立一个模型,预测 Macbeth 原始文本之后的「n」的字符数量。绝大多数经典文本不再受版权保护,你可以在这里找到(https://www.gutenberg.org/),更新的 TXT 版本可以在这里找到(https://s3-ap-south-1.amazonaws.com/av-blog-media/wp-content/uploads/2017/12/10165151/macbeth.txt)。
我们使用 Keras,它是一个用于神经网络的高阶 API,并在 TensorFlow 或 Theano 之上工作。因此在进入代码之前,请确保你已安装运行正常的 Keras。好的,我们开始生成文本!
导入依赖项
# Importing dependencies numpy and keras
import numpy
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import LSTM
from keras.utils import np_utils
我们导入所有必需的依赖项,并且这不证自明。
加载文本文件并创建字符到整数映射
# load text
filename = "/macbeth.txt"
text = (open(filename).read()).lower()
# mapping characters with integers
unique_chars = sorted(list(set(text)))
char_to_int = {}
int_to_char = {}
for i, c in enumerate (unique_chars):
char_to_int.update({c: i})
int_to_char.update({i: c})
文本文件已打开,所有字符都转换为小写字母。为了方便操作以下步骤,我们把每个字符映射到相应数字。这样做是为了使 LSTM 的计算部分更容易。
准备数据集
# preparing input and output dataset
X = []
Y = []
for i in range(0, len(text) - 50, 1):
sequence = text[i:i + 50]
label =text[i + 50]
X.append([char_to_int[char] for char in sequence])
Y.append(char_to_int[label])
数据需以这种格式准备如果我们想要 LSTM 预测「HELLO」中的「O」,我们需要输入 [H, E , L , L ],并且 [O] 作为预期输出。相似地,这里我们确定了想要的序列长度(在该实例中设置为 50),接着在 X 中保存前 49 个字符的编码和预期输出,即 Y 中的第 50 个字符。
重塑 X
# reshaping, normalizing and one hot encoding
X_modified = numpy.reshape(X, (len(X), 50, 1))
X_modified = X_modified / float(len(unique_chars))
Y_modified = np_utils.to_categorical(Y)
LSTM 网络希望输入形式是 [样本,时间步,特征],其中样本是我们拥有的数据点的数量,时间步是单个数据点中存在的与时间相关的步数,特征是我们对于 Y 中相应的真值的变量数目。我们接着把 X_modified 中的值在 0 到 1 之间进行缩放,并且在 Y_modified 中对真值进行独热编码(one hot encode)。
定义 LSTM 模型
# defining the LSTM model
model = Sequential()
model.add(LSTM(300, input_shape=(X_modified.shape[1], X_modified.shape[2]), return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(300))
model.add(Dropout(0.2))
model.add(Dense(Y_modified.shape[1], activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
使用一个含有线性堆栈层的序列模型。首层是一个带有 300 个记忆单元的 LSTM 层,并且它返回序列。如此做是为了确保下一 LSTM 层接收到序列,而不仅仅是随机分散的数据。每个 LSTM 层之后应用一个 dropout 层,以避免模型过拟合。最后,我们得到一个作为全连接层的最后一层,它带有一个 softmax 激活函数和与唯一字符数量相同的神经元,因为我们需要输出独热编码结果(one hot encoded result)。
拟合模型并生成字符
# fitting the model
model.fit(X_modified, Y_modified, epochs=1, batch_size=30)
# picking a random seed
start_index = numpy.random.randint(0, len(X)-1)
new_string = X[start_index]
# generating characters
for i in range(50):
x = numpy.reshape(new_string, (1, len(new_string), 1))
x = x / float(len(unique_chars))
#predicting
pred_index = numpy.argmax(model.predict(x, verbose=0))
char_out = int_to_char[pred_index]
seq_in = [int_to_char[value] for value in new_string]
print(char_out)
new_string.append(pred_index)
new_string = new_string[1:len(new_string)]
该模型拟合超过 100 个 epoch,每个批大小为 30。接着我们修复一个随机种子(为了便于复现),并开始生成字符。模型预测给出了已预测字符的字符编码,接着它被解码为字符值并附加到该模式。
下图展示了该网络的输出方式:

最终在训练足够的 epoch 之后,它会随着时间获得越来越好的结果。这正是你使用 LSTM 解决序列预测问题的方式。
结语
LSTM 是序列和时序相关问题方面的一个很有前途的解决方案,同时也有着难以训练的缺点。我们甚至需要大量时间和系统资源用来训练一个简单的模型。但这仅是一个硬件方面的限制。本文希望帮助你准确理解这些网络的基本知识,如有任何相关问题,欢迎留言。
原文链接:https://www.analyticsvidhya.com/blog/2017/12/fundamentals-of-deep-learning-introduction-to-lstm/
