


不久之前,我看了一篇文章,大意是Kotlin与Java之间的对比,像这种文章,我一般是直接忽略的,但是那天我还是打开了,然后就看到一个非常吃惊的结果。里面有一段是关于Kotlin与Java之间可读性的对比的文章,作者的结论是:Kotlin并不比Java更具有可读性,所有认为Kotlin 比Java更具有可读性的结论都是“主观性”的。并且作者举了一个在我看来,不知道该怎么来描述的例子:
这个作者的大意是,上面这段文章,你多读个两三遍,你也会很快的理解它的意思,所以“对于熟练的读者而言,外观很少会成为可读性的障碍。”我不知道,如果某一天,这个作者突发奇想,决定全部使用大写字母来写代码——所有的类名、方法名、局部变量成员变量名等等全部使用大写,我不知道跟作者合作的同事是不是会欣然的耐心的把作者所有的代码先读它个两三遍,然后再来慢慢的理解它的意思。如果是我,我不会。如果在小红书有个同事非要执意这样写代码,理由是“你多读个两三遍不就好了嘛?”我想我只能把他开除了。其实,如果一段代码需要你多读个两三遍才能很好的理解,这本身不就说明,这段代码的可读性不高吗?这里的重点是,这里的这一段大写的文字你看个三遍,再看的话,是熟悉了,但是再看别的用大写写的文字片段,你依然要很费劲。所以,这个例子是不能代表大写这种风格的可读性的。在比较两种不同的风格的可读性的时候,你不能用具体的某一个一次性的片段来说明。另外,这篇文章还暗含了这样一个观点,那就是,代码的可读性,仅仅是指,看到一段代码, 能不能理解这段代码的含义。这是一个很多人都会错误的观点。但是,在真正工作中,代码的可读性,恐怕不至这一个方面。为了考察所谓代码的可读性涉及到哪些方面,我们来假设两个case:1. 你去到一家新公司,接手一个新项目。这个时候,你的需求是,快速了解某个类、某个模块、某个方法做的是什么事情。在这个基础上,整个app、模块的结构是怎么样的。2. 你老板叫你fix一个bug,这个bug是另外一个同事写的,今天这个同事请假了不在。在这个case里面,你需要的是,快速的定位到出问题的代码在什么地方,然后再尽快的了解这个地方的代码做了什么事情,并且保证你的理解是对的。所以,总结一下,代码的可读性,可以归纳成三点:
-
理解一段代码的速度
-
找到你关心的代码的速度
-
确保正确理解一段代码的难易程序。这跟第一点看似一样,其实还真不一样,下面你会看到。
下面,依次解释一下这三点,以及为什么说,Kotlin的可读性会对Java高。
1. 理解一段代码的速度
如果大家仔细的思考下,你会发现,我们在理解一段代码的时候,大多数情况下,我们是想要了解这段代码做了什么事情,是这段代码的意图(Intention),而不是具体这个事情是怎么做的。比如一个Button被点击了,我们的App做了什么,是做了什么运算,发了网络请求,还是保证了一些数据到数据库。也就是说,大多数情况下,我们关心的是What,而不是How。只有少数情况下,我们会关心“How”,一是出于学习的目的,我们想要了解一个算法是怎么实现的,一个效果是怎么实现的,这个时候,我们会关心“How”。二是当这个“How”出了问题的时候,就是有了Bug,我们要去了解这个 “How”,然后再fix过来。而且,即使是在这些少数情况下,了解“How”的过程,也只不过是了解一个个子“What”的过程。敏捷开发和TDD先驱、JUnit开发作者和一系列经典编程书籍作者Kent Beck提出了一个著名的“four rules of simple design”,是以下4条:
-
Passes the tests
-
Reveals intention
-
No duplication
-
Fewest elements
第一条Passes the test说的是程序的正确性。第二条Reveals Intention,说的就是我们这里讨论的“What”。
那么,Kotlin相对于Java,在帮助我们了解“What”,在帮助Reveals Intention这方面,有什么样的优势呢?我们看一个简单的例子:

在这段Java代码例子中,这7行代码做的事情很简单,就是从personList中找出id值等于somePersonId这个变量的值的那个Person,然后赋值给 person这个变量。要理解这段代码并不难(其实后面你会看到,要确保正确理解这么代码也没那么简单),但是速度并不快,你必须从头到尾看完这8行代码,就算你说最后两行可以一扫而过,那也必须看完前面6行,你才能知道“哦,原来这段代码做的事情是,从personList中找出id值等于。。。”
下面,我们来看对应的Kotlin代码是怎么样的:
val person = personList.find { it.id == somePersonId }是的,就一行代码。看完这行代码,你就知道了它做的是什么事情。因为在这行代码中,find这个单词就已经表达出了这里做的事情是“找出一些东西”,而大括号里面,就是找出它的条件。也就是说,Kotlin的写法直接就帮我们表达出了“What”。如果平均来说,一个人理解一行Java代码的速度跟理解一行Kotlin代码的速度是一样的(虽然在我看来,理解一行Kotlin代码会更容易,因为Kotlin里面有很多帮助开发者减轻负担的语法,接下来会提到这一点),那么在这个例子中,一个人理解Kotlin代码的速度是理解对应的Java代码的5~6陪。之所以说
5~,是因为在Java里面,你还可以写成foreach语法,如果写成foreach语法的话,那么Java代码是5行。但是以我的经历,多数情况下大家还是会习惯性的写成fori,因为这两者差别并没那么大,优势也不是那么明显。在Kotlin里面,Collection类有一整套像 find这样,直接可以reveal intention的方法,简单点的有filter、 count、reduce,
map、any、 all等等,高级点的有mapTo、 zip、associate、 flatMap、groupBy等等。绝大多数情况下,所有需要手动for循环的地方,都有对应的更加能“reveal intention”的方法。当然,如果只有一个collection,就说Kotlin在
Reveal Intention这点上比Java更有优势,那是不够的。Kotlin有一系列的机制和便利,能帮助开发者更好的达到“Reveal intension”的目。比如null的处理, if、when表达式(不是语句),比如循环的处理,比如所有对象都有的 let, apply, run等方法,比如data
class以及它的copy方法等等等等。此外,通过Extension Function这个机制,Kotlin对Java中绝大多数的常用类都作了扩展。前面提到的各种Collection方法,也是使用这种方式来进行扩展的。此外,就算有一些类没有你想要的扩展,你也可以非常轻松容易的自己写一个扩展方法,来让你的代码更加“Reveal Intension”。相比之下,跟Kotlin相比,Java代码更像逼我们去通过了解“how”之后,来总结归纳出它的“what”。在描述一门语言的时候,有一个术语叫做抽象程度,也就是一门言语表达“What”、屏蔽“How”的能力。从这点来说,无疑Kotlin的抽象程度是比Java要高的,就像是C语言的抽象程度比汇编要高一样。实际上,我还还真有个朋友拿Java比作汇编。他是写Scala的,有一天他这么跟我说
我之前一年多时间都是写Scala的,现在我看到Java代码,就像在看汇编一样。
基于Kotlin的抽象程度更接近Scala,我想写一年多Kotlin之后,你也会有类似的感觉。OK,第一点讲到这里。接下来我们来看第二点。
找到你关心的代码的速度
当谈到Kotlin的优势时,有一点我相信是公认的,那就是Kotlin比Java更简洁。而简洁带来的好处之一,就是能够让人更快的找到他关心的代码,而不用在一堆杂七杂八的没用的代码里面去翻找自己在乎的代码。我们还是以一个例子来说明吧,以下两段代码。
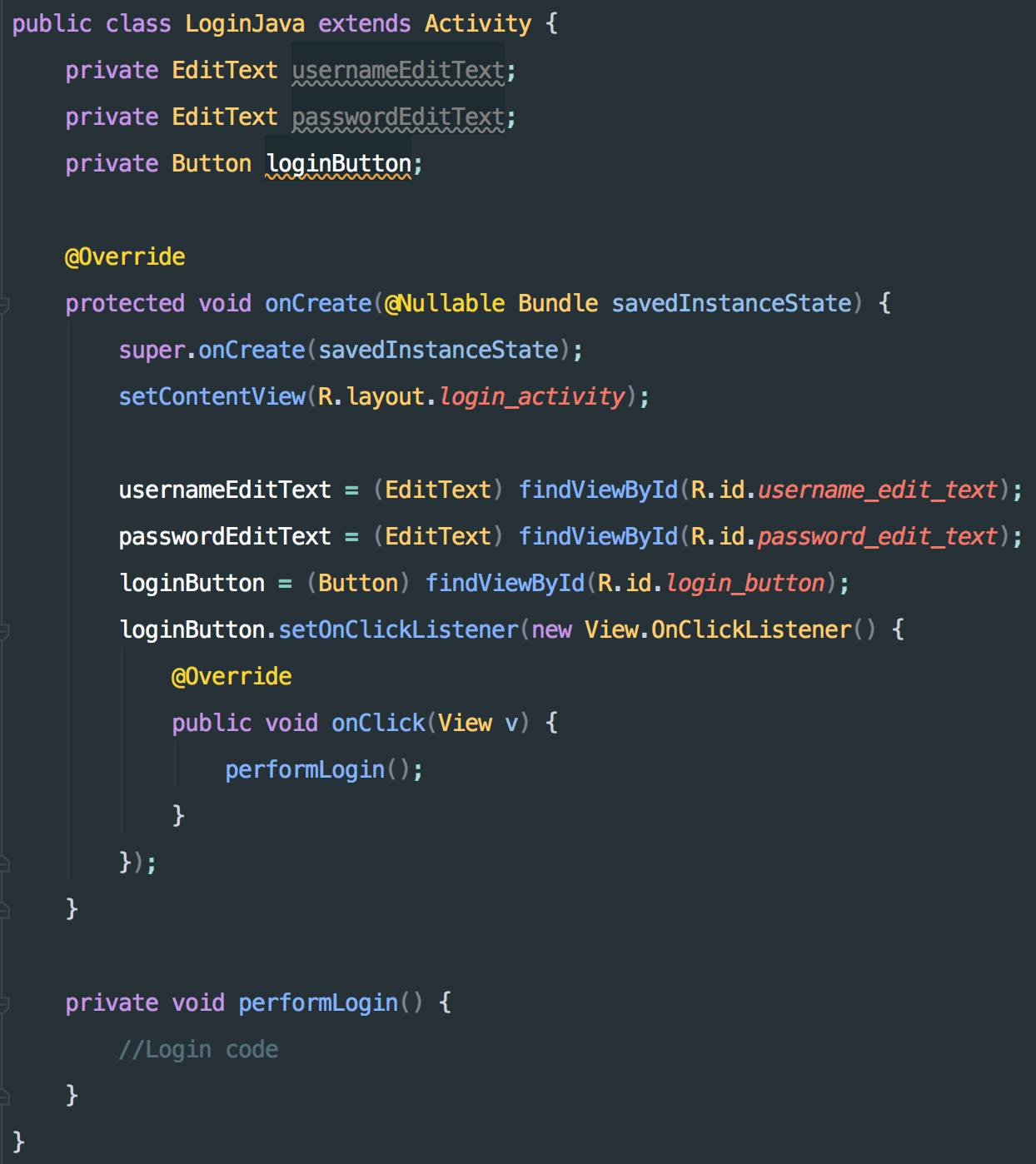
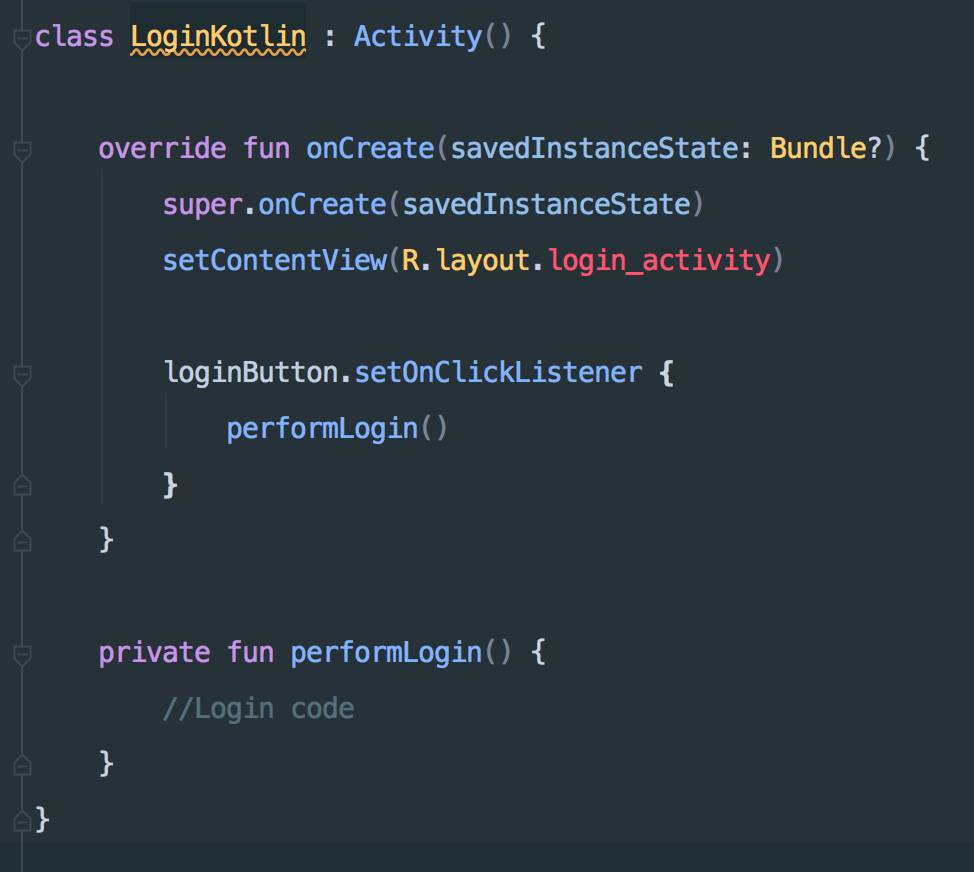
如果说,要你找出点击loginButton以后,代码做了什么事情,那以上两段代码中,无疑第二段代码能让你更快的找到。上面这个例子还大大的简化了很多东西,实际开发过程中,代码更加复杂,Kotlin的优势也更明显。
确保正确理解一段代码的难易程序
这是很多人会忽略的事情。能否理解一段代码,跟确保正确的理解这段代码,其实中间还是有一些差别的。很多代码看起来很简单,但是要确保自己正确的理解,其实还是非常费劲的。还是看文章开头这个例子:
这一段代码要确保正确的理解,容易吗?其实没那么容易,如果你工作年限多一点,你一定碰到过这样的代码,在for循环里面, i是从1开始的,而不是从0开始的,或者是中间的终止条件是i < personList.size() - 1,而不是 i < personList.size(),或者最后部分不是i++,而是 i = i + 2,或者i--。很多人更是碰到过很多bug,就是因为没有看清楚这里面i的起始值、终止条件,或者是步长导致的。我就曾经碰到过很多这样的bug,也曾经因为没有注意这些地方,而导致过很多bug,最后调了半天,发现原来是因为for里面是
i=1,而不是i=0。那时候,就只能在心里默默的大叫一声:FUCK!因为有这些非典型代码的存在,所以现在,每次看到这样写的for循环,我心里都会觉得如履薄冰,会特别小心翼翼的看得很仔细,确保 i的初始值是什么,终止条件是什么,步长是什么。这在无形之中会给人增加特别大的心理负担。然而因为是无形之中的,是潜意识里面的,所以一般人不会注意到。毕竟,大家都这么写,而且写了几十年了,能有什么问题呢?其实,是有的。这也是为什么Java5增加了Foreach语法的原因,然而可惜的是,大部分人并不清楚具体为什么要使用foreach,而且还声称fori比foreach性能更高,这真是令人遗憾。说回Kotlin,那为什么说Kotlin代码能让人更容易正确的理解呢?让我们再看一下上面的例子对应的Kotlin代码:
val person = personList.find { it.id == somePersonId }在这一行代码中,你根本无需担心i的初始值、终止条件、步长,因为这里面根本没有这些东西。所以,一个很大的心理担负消失了。你也不用担心这里面有没有break,或者你是否忘了写break。这就是Kotlin让代码更容易理解的地方。同样的,像这种减轻看代码的人心理负担的机制Kotlin里面有很多,这里再介绍一个很重要的“小”特性:使用val把一个变量定义成不可变的“变量”。我 之前一篇文章说过,Kotlin的nullsafety是我最喜欢的特性,如果说第二喜欢的特性是什么,那就是val关键字。在团队里面,我也一遍一遍的跟同事强调,能用
val的地方就不要用var。因为它带来的心理上的relief,是巨大的。我们看以下 LinearLayout里面的代码。
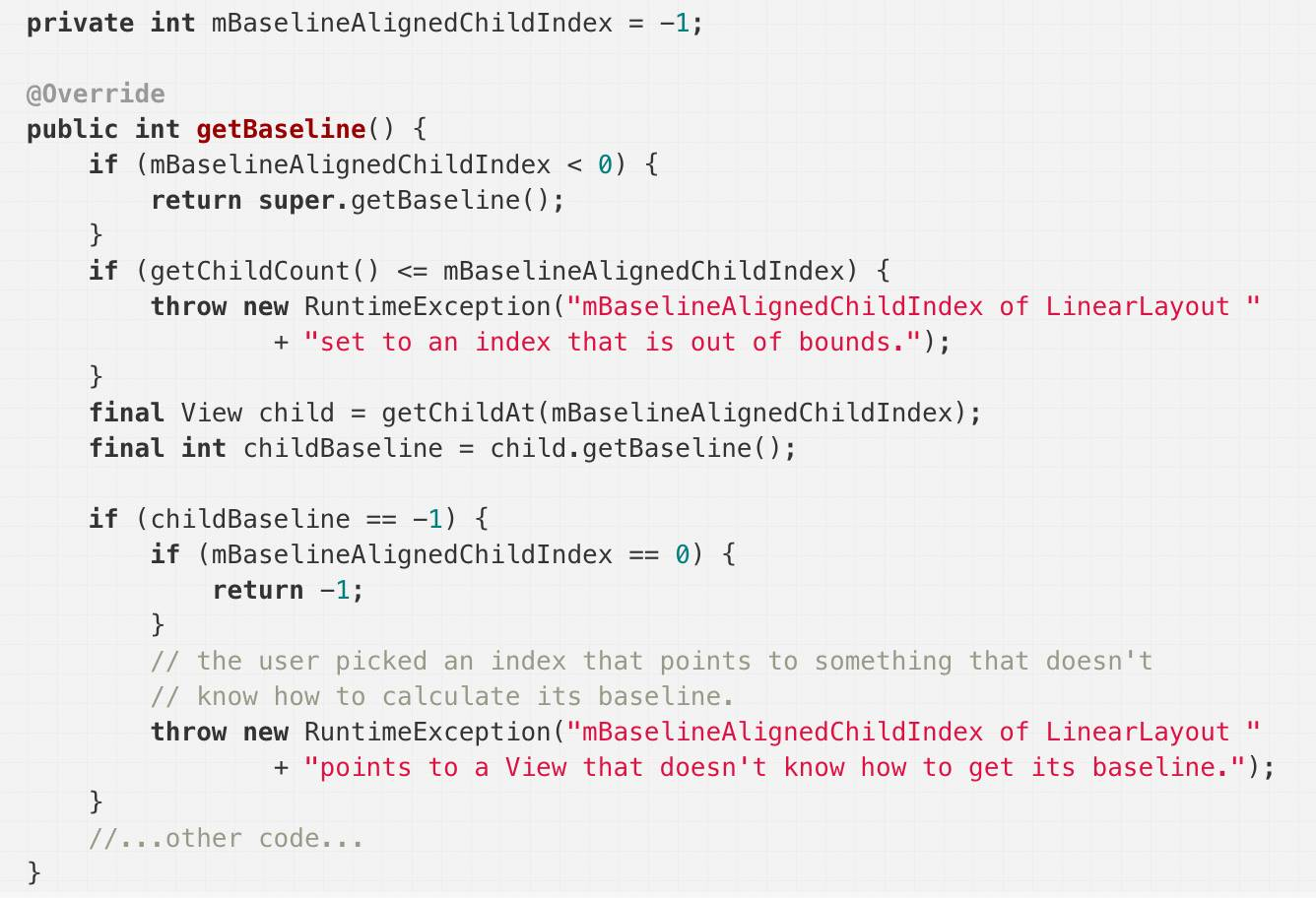
如果你写了个自定义Layout继承自LinearLayout,结果它表现出来的样子不符合你的预期,你可能会去看源码。看到上面这段,最后你发现,原来是 mBaselineAlignedChildIndex这个成员变量的值不对。那么,你怎么知道是哪里改变了这个变量的值,导致它被赋给了一个错误的值呢?你可能要在这个类里面找出所有会改变这个变量的地方,然后一个一个去check,哪里会走到,哪里不会走到。更糟糕的是,也许这个值在某个public方法里面被改变了,这样的话,你还要去找出所有调用这个public方法的地方,然后去确定到底是谁,在哪里调用了这个方法,而这些调用的地方又是谁调用的,导致出错了。这想想就是一件非常头疼的事情。但是,如果这个值是
final的话,这些麻烦就都不存在了。它的值要么是在它定义的地方就确定了,要么是在构造方法里面确定的,你只需要检查两个地方就可以了,这对于代码理解,是一件极大的减少工作量的事情。这,就是为什么Effective Java里面,建议把所有能用final修饰的地方都用 final修饰的原因。很多人认为,使用final是为了避免多线程同步的问题。但是,诚实的说,算了吧,作为安卓开发的你,上一次碰到多线程同步的原因导致一个变量的值出错,是什么时候的事了呢?
final的真正优点,在于让人在看代码的时候,不用到处去找可能会改变这个值的地方,也消去“这个值会不会在哪里被改变”的大心理负担。思考深入的读者可能会发现,其实上面的这个例子有点矛盾。因为我说的是使用final来定义变量,但是像上面的 mBaselineAlignedChildIndex这个成员变量,是不能加final的,因为它就是要可变的啊,它就是需要在某些条件下被重新赋值的啊,这不是矛盾了吗?是的,很多时候,我们不能使用
final来定义一个成员变量。但是,如果你试着给那些可以加上final的成员变量加上 final,你会发现,其实大部分成员变量和几乎所有局部变量都是可以加上final的,但是现实情况是什么呢?是几乎所有的成员变量和局部变量,我们都没有使用 final来定义。我们写代码的默认设置是,先不加final,如果在哪个地方编译出错了——比如写一个匿名内部类,引用了前面的局部变量——迫使我们使用
final来修饰一个变量的时候,我们才加上。为什么会出现这种情况呢?有两点原因:
-
final的好处并不为大家所知,也不是一眼能看出来的。 -
使用
final要写多写一个单词。
当一个东西的优势不是很容易被识别(注意,不容易被识别,不代表这个优势不大,或者不重要,这是两回事),同时又要多付出一些努力的时候,我们写代码的默认设置是不加final,这就非常合情合理了。那Kotlin在这点上,又有什么优势呢?Kotlin的优势有几个,先讲一个不起眼的优势:使用 val来定义“变量”。这里之所以给“变量”加上双引号,是因为使用val来定义的“变量”一旦被赋值,是不能被改变的,所以好像称他们为“变”量不大合适。但我又找不到合适的词来叫这个东西,所以暂且还是称作“变量”吧。不要小看了这个优势。当你可以使用
var或val这两个看起来写起来都差别不大的方式来定义一个东西的时候,人们自然会想要去了解,这两者到底有什么区别?我应该使用哪个?这时候,就会有一些讨论,有一些标准出来,人们就会认识到,不可变性(Immutability)原来有这么大的价值,原来是这么好的一个东西。同时,因为 val和var写起来没有差别,所以人们也会更愿意使用 val来定义“变量”。当然,要我说,kotlin这一点做得还不够。应该像Rust一样,让可变的变量定义起来比不可变的变量定义起来更费劲,这才能更加促进不可变量这种好的practice的发扬光大。
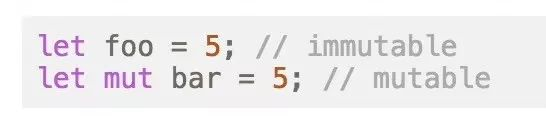
在StackOverflow的调查中([2017](https://insights.stackoverflow.com/survey/2017#technology-most-loved-dreaded-and-wanted-languages),[2016](https://insights.stackoverflow.com/survey/2016#technology-most-loved-dreaded-and-wanted)),Rust连续几年被评为“程序员最喜爱的语言(Most
Loved)”,这不是没有原因的,它的设定也不是没有原因的。除此之外,Kotlin还使用了一些方式,来让原本不能定义为val的变量,也可以使用 val来定义,比如by lazy和 lateinit,这些机制综合起来,即让val写起来很容易,也扩大了 val的适合范围。上面花了很多篇幅来解释,Kotlin中val的价值。跟
Collection中的众多扩展方法一样,这些都是Kotlin中,一些让代码更容易理解的机制。像这样的机制还有很多,比如说在Kotlin中,if、when(Kotlin中的switch)都是表达式(Expression,会返回一些值),而不像在Java中,只是语句(Statement,不会有返回值),比如说对 null的处理,如果你看过多层嵌套的null判断,你就知道那种代码看起来有多费劲了。而使用Kotlin,结合val,在定义的时候把它定义成非
null,你可以明显的告诉代码的读者,也告诉你自己,这个地方是不需要进行null判断的。这就大大的减少了null判断的数量。由于篇幅的关系,这些还有剩下的一些机制,这里就不展开讲了。当你写kotlin代码的时候,多思考一下,Kotlin为什么要这样设定,你就会明白,都是有原因的,多数情况下,都是有优势的。
为什么代码的可读性这么重要?
以上从三个方面解释了什么叫代码的可读性,可以看到,无论在哪个方面,Kotlin都有比Java更大的优势。那接下来的一个问题就是,So what?可读性有这么重要吗?能吃吗?值多少钱?别说,可读性还真可以吃,而且很值钱!关于可读性的重要性,其实上面分析什么叫可读性的时候,已经提到了,这里归纳一下,只说两点:
-
更快的找到你关心的代码,更快的理解代码。要知道,我们现实开发过程中,大部分时间是在看代码,而不是在写代码。更快的理解代码,意味着更高的工作效率,节省更多的时间,时间就是金钱,所以更高的可读性,意味着省钱。或者用省下来的时间去赚更多的钱。
-
更容易正确的理解代码,从而不会因为对老代码的理解不到位而改错,造成新的bug。大家可以回想一下,过去有多少bug的发生,是因为对遗留代码的理解不到位,不全面导致的呢?在小红书,这个比例不少,也造成过不小的问题。痛定思痛,我们现在能做的,就是引以为戒。写代码的时候,重视可读性,让后来的人,让后来的自己,不要再吃这样的亏,不要再背这样的锅。
“人生苦短,快用Kotlin,珍爱生命,远离Java”。这是小红书安卓客户端Coding Style的第一条规则。顺便说一句,使用Kotlin之后,目前我们的app crash原因里面,Top10没有任何一个NullPointerException了,Top20有两个,这两个都是发生在系统层面的,也就是说,我们自己代码里面的 NullPointerException,基本都已经消灭了。而在6月份,上Kotlin之前,我有统计过的一次,Crash里面Top10有5个NullPointerException,Top20里面有12个。所以Kotlin的作用,是非常明显的。目前,小红书总体的Crash率,除非意外发生,可以很轻松的保持在0.2%甚至0.1%之内,这在业界,即便不是最好的水平,也是个非常好的水平。
在Google声明Kotlin成为安卓开发的官方支持语言那一天,我建了一个微信群。目前偶尔还是有人在群里面问,Kotlin值得学习吗?有风险吗?看到现在还在问这样的问题,我是觉得有点遗憾的。希望上面的文章能让你从代码可读性的角度,了解Kotlin的优势。让好的技术在这个世界盛行,对技术人来说,是一件非常值得欣慰的事情。

