

前言
Sentry是Hadoop生态中的一员,扮演着“守门人”的角色,看守着大数据平台的数据安全的访问。它以Plugin的形式运行于组件中,通过关系型数据库(PostgreSQL、MySQL)或本地文件来存取访问策略,对数据使用者提供细粒度的访问控制。本文试图在源码层剖析Sentry的鉴权过程,以帮助更好的理解权限的鉴定过程。
Sentry架构简述
Sentry的设计目标是作为一层独立的访问控制层来对Hadoop组件(目前支持HDFS,Hive,Impala,solr,kafka,sqoop)进行授权/鉴权操作,因此它的耦合度很低,以插件的形式工作于组件之上。可以把它看作Java web中的filter,当用户请求过来的时候,sentry截获了用户的信息,对用户的权限进行验证,如果成功,则让该请求通过;否则,抛出异常,阻断该请求。
Sentry是一个分层的结构,如下图所示
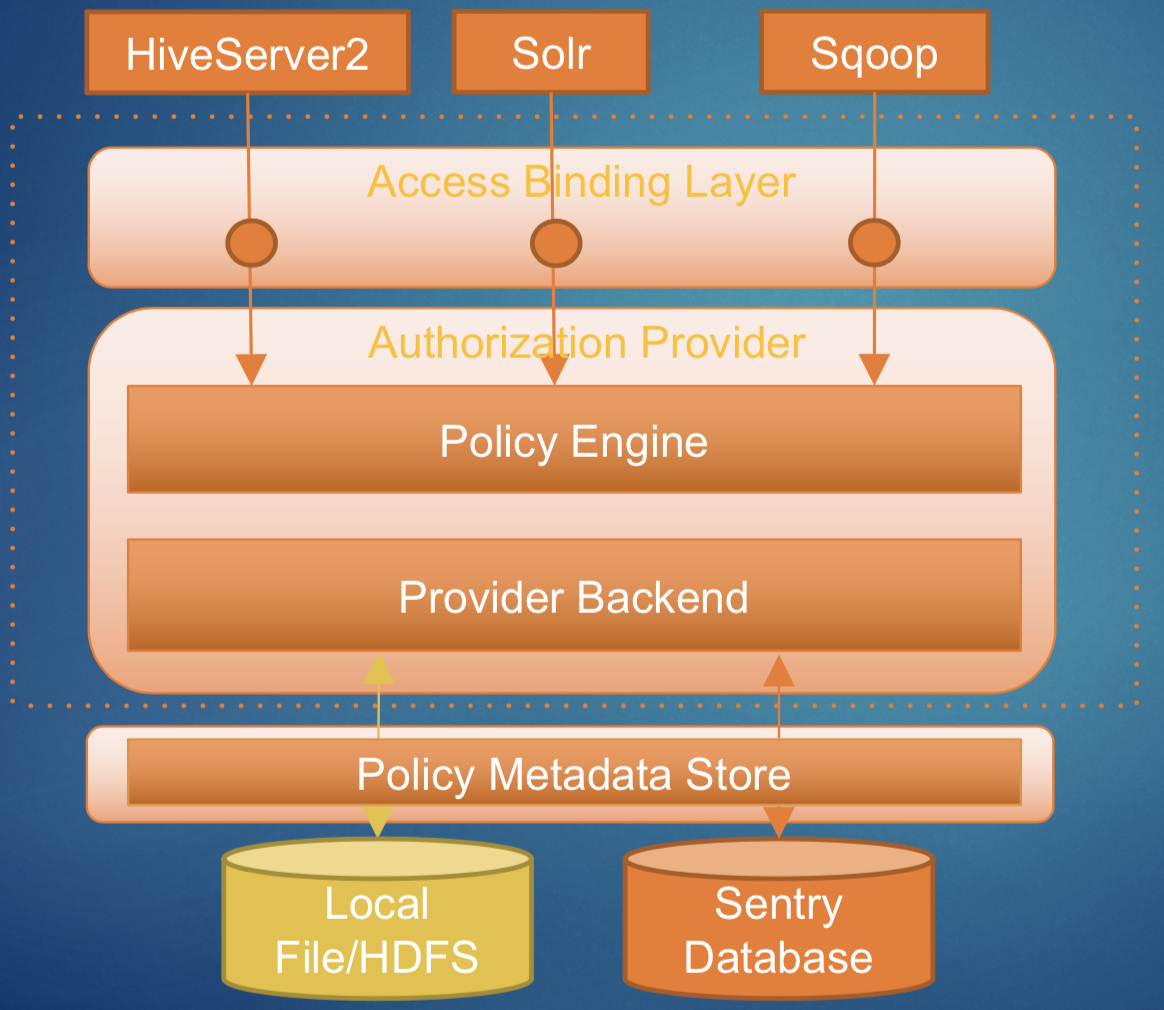
- Binding层 负责将用户对Hadoop组件的访问请求截获,并解析出其中的用户信息,以便进行鉴权
- Provider层 是一个较通用的权限策略验证层,在这里抽象了权限对象,并对用户所具备的权限对象进行验证
- Policy Metadata Store 负责与策略的存储和读取,目前支持文件存储和关系型数据库存储方式。
由上图结合源码分析,Sentry的大致工作流程为:
- Binding层拦截用户的访问,并将用户信息解析出来,暂存到一个subject对象中
- Policy Metadata Store层根据用户访问的资源对象(表名)和用户信息(subject)从底层存储(文件或关系型数据库)中读取两个权限对象列表:requireList(需要有的权限)和obtainList(用户当前的权限)
- Policy Engine根据读取到的两个权限对象列表,逐一进行权限的比对,缺少任何一个权限都要抛出异常,只有当完全满足时,将此访问请求通过
源码分析
下面以HiveServer2为例,分析Sentry是如何进行鉴权工作的,以此为切入点,剖析Sentry的通用鉴权模型。上面提到,Sentry的鉴权过程中主要分为了Binding、Policy Engine和Policy MetadataStore三层的协作,下面逐一进行分析。
Binding
上面谈到Binding的主要工作是解析用户信息,那么Sentry是如何截获用户对Hadoop组件的请求的呢?拿HiveServer2为例,用户在连接的时候,会由HiveServer2创建一个session,该session中保存了用户的用户名等信息,该session在该用户的整个TCP连接中都会保留,因此如果可以获得该session,便可以获得用户名。
HiveServer2中提供了一个方便的接口叫作HiveSessionHook,其中只有一个run方法,在session manager创建一个session的时候,会进行调用。这是一个Hive提供的hook机制,方便进行自定义的hook动作,Sentry使用了这个Hook,定义了一个HiveAuthzBindingSessionHookV2类实现了HiveSessionHook接口,重写了其中的run方法。代码如下:
@Override
public void run(HiveSessionHookContext sessionHookContext) throws HiveSQLException {
// Add sentry hooks to the session configuration
HiveConf sessionConf = sessionHookContext.getSessionConf();
appendConfVar(sessionConf, ConfVars.SEMANTIC_ANALYZER_HOOK.varname, SEMANTIC_HOOK);
// enable sentry authorization V2
sessionConf.setBoolean(HiveConf.ConfVars.HIVE_AUTHORIZATION_ENABLED.varname, true);
sessionConf.setBoolean(HiveConf.ConfVars.HIVE_SERVER2_ENABLE_DOAS.varname, false);
sessionConf.set(HiveConf.ConfVars.HIVE_AUTHENTICATOR_MANAGER.varname,
"org.apache.hadoop.hive.ql.security.SessionStateUserAuthenticator");
// grant all privileges for table to its owner
sessionConf.setVar(ConfVars.HIVE_AUTHORIZATION_TABLE_OWNER_GRANTS, "");
// Enable compiler to capture transform URI referred in the query
sessionConf.setBoolVar(ConfVars.HIVE_CAPTURE_TRANSFORM_ENTITY, true);
// set security command list
HiveAuthzConf authzConf = HiveAuthzBindingHookBaseV2.loadAuthzConf(sessionConf);
String commandWhitelist =
authzConf.get(HiveAuthzConf.HIVE_SENTRY_SECURITY_COMMAND_WHITELIST,
HiveAuthzConf.HIVE_SENTRY_SECURITY_COMMAND_WHITELIST_DEFAULT);
sessionConf.setVar(ConfVars.HIVE_SECURITY_COMMAND_WHITELIST, commandWhitelist);
// set additional configuration properties required for auth
sessionConf.setVar(ConfVars.SCRATCHDIRPERMISSION, SCRATCH_DIR_PERMISSIONS);
// setup restrict list
sessionConf.addToRestrictList(ACCESS_RESTRICT_LIST);
// set user name
sessionConf.set(HiveAuthzConf.HIVE_ACCESS_SUBJECT_NAME, sessionHookContext.getSessionUser());
sessionConf.set(HiveAuthzConf.HIVE_SENTRY_SUBJECT_NAME, sessionHookContext.getSessionUser());
// Set MR ACLs to session user
updateJobACL(sessionConf, JobContext.JOB_ACL_VIEW_JOB, sessionHookContext.getSessionUser());
updateJobACL(sessionConf, JobContext.JOB_ACL_MODIFY_JOB, sessionHookContext.getSessionUser());
}英文注释已经比较详细,在此有几点需要注意的是:
- HiveConf是Configuration的一个子类,可以把它看成一个Map集合,存放了Hive当前session的一些配置信息,默认会将hive-site.xml中的配置载入,因此通过HiveConf就可以获得hive-site.xml中的配置项。
- semantic analyzer hook也被注入了进来,它也是一个hook,在SQL语句的语法分析阶段触发,可以在此完成一些鉴权的操作,但sentry的主要鉴权逻辑并不在此实现
SCRATCH_DIR_PERMISSIONS的值为700,是对目录的权限赋值,对应为111000000,也就是对该用户有r、w、x权限ACCESS_RESTRICT_LIST是一个key的集合,该集合中的key值对应的value值不允许用户修改- HiveAuthzConf也是Configuration的一个子类,可以把它看做sentry-site.xml中的配置信息
- 设置subject name,这里为用户名,用于之后的用户鉴权,每个用户对应一定的权限。
Binding层至此就分析完毕了,主要使用了HiveServer2中的session hook,将session的用户名读取并设置到一个key值中,以备之后的使用。
权限验证
HiveServer2原生提供了访问控制逻辑,Sentry在此基础上进行了RBAC概念的强化,使得权限只能赋予给角色,角色赋予给用户/用户组,由此就有了权限——角色——用户组——用户的链式关系。当拿到用户名之后,通过数据库中读取其角色和相应的权限集合,便可以进行权限的验证了。Sentry中跟权限验证相关的类关系如下图所示:
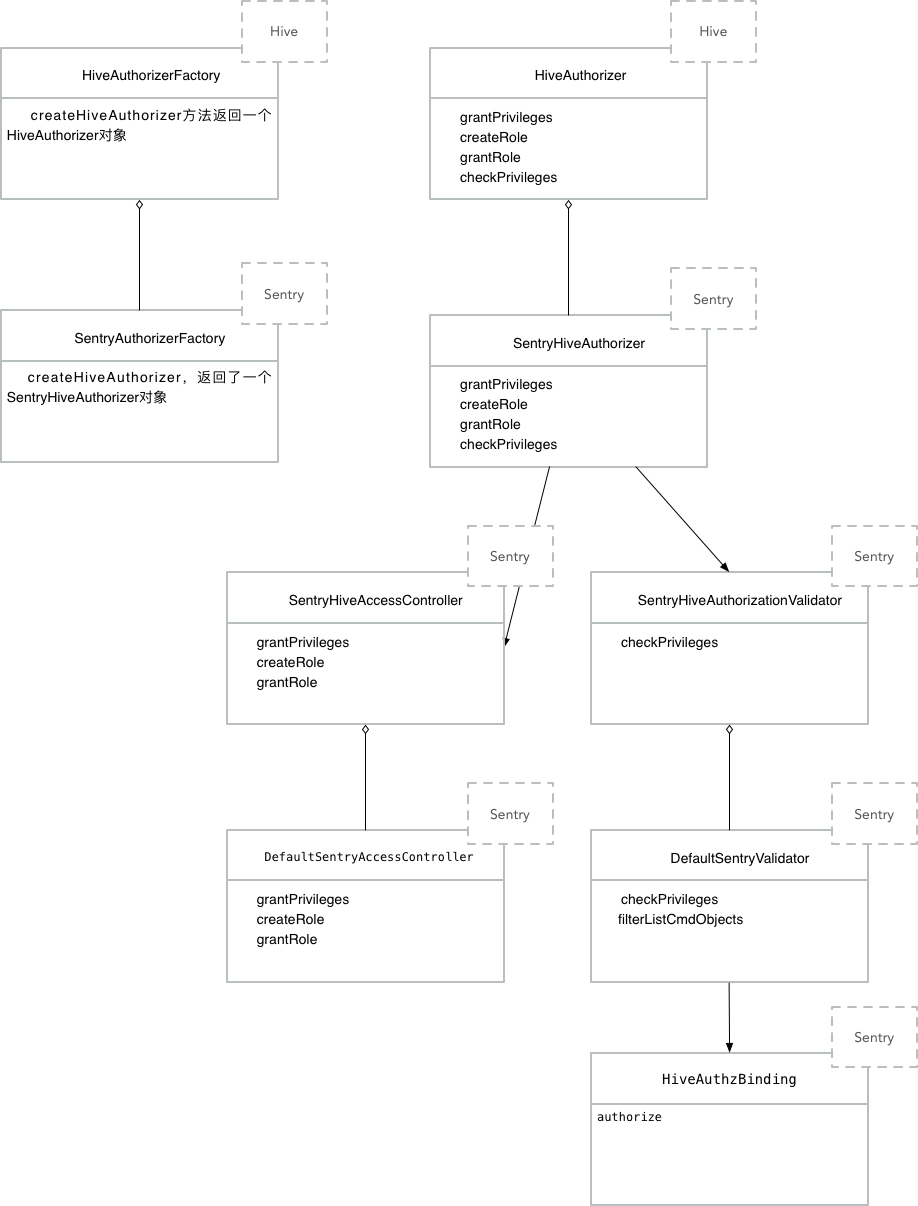
类/接口的右上角表示其属于Hive还是Sentry,空心菱形代表的是实现的接口,实心箭头指向的为内部的一个引用对象。
HiveAuthorizerFactory和HiveAuthorizer都来自于Hive且都为接口,HiveAuthorizerFactory实现了一个抽象工厂模式,返回一个HiveAuthorizerSentryAuthorizerFactory和SentryHiveAuthorizer分别是Sentry的两个对应实现,到此HiveServer2的访问控制就交给了Sentry处理SentryHiveAuthorizer内有两个引用接口,分别为SentryHiveAccessController和SentryHiveAuthorizationValidator,分别负责授权(grant/revoke)和鉴权(checkPrivileges)操作SentryHiveAccessController的默认实现为DefaultSentryAccessControllerSentryHiveAuthorizationValidator的默认实现为DefaultSentryValidator,其中的checkPrivileges方法负责鉴权,在该方法中调用了HiveAuthzBinding的authorize方法完成最终的权限验证
authorize
上面说到DefaultSentryValidator中的checkPrivileges方法调用了authorize方法进行实际的权限验证,代码如下:
hiveAuthzBinding.authorize(hiveOp, stmtAuthPrivileges,
new Subject(authenticator.getUserName()), inputHierarchyList, outputHierarchyList);- hiveOp是本次sql语句转化为的HiveOperation枚举对象,它表示了当前SQL对应的操作
- stmtAuthPrivileges表示本次操作所需的权限集合,它从一个预先定义好的系统常量表中根据hiveOp的类型取出
- new Subject表示的是当前的用户
- inputHierarchyList和outputHierarchyList分别表示输入对象和输出对象
由上面传入的参数可以看出,除了subject是用户相关的信息外,其他全部都是本次SQL操作所需要的权限信息,其中stmtAuthPrivileges直接表示本次operation需要的权限,inputHierarchyList和outputHierarchyList表示了本次SQL需要访问的输入、输出资源,因此,鉴权验证需要分为两步:
- 用户是否拥有对输入对象列表的该operation对应的访问权限
- 用户是否拥有对输出对象列表的该operation对应的访问权限
下面我们进入authorize方法一探究竟
public void authorize(HiveOperation hiveOp, HiveAuthzPrivileges stmtAuthPrivileges,
Subject subject, List<List<DBModelAuthorizable>> inputHierarchyList,
List<List<DBModelAuthorizable>> outputHierarchyList)
throws AuthorizationException {
if (!open) {
throw new IllegalStateException("Binding has been closed");
}
boolean isDebug = LOG.isDebugEnabled();
if(isDebug) {
LOG.debug("Going to authorize statement " + hiveOp.name() +
" for subject " + subject.getName());
}
/* for each read and write entity captured by the compiler -
* check if that object type is part of the input/output privilege list
* If it is, then validate the access.
* Note the hive compiler gathers information on additional entities like partitions,
* etc which are not of our interest at this point. Hence its very
* much possible that the we won't be validating all the entities in the given list
*/
// Check read entities
Map<AuthorizableType, EnumSet<DBModelAction>> requiredInputPrivileges =
stmtAuthPrivileges.getInputPrivileges();
if(isDebug) {
LOG.debug("requiredInputPrivileges = " + requiredInputPrivileges);
LOG.debug("inputHierarchyList = " + inputHierarchyList);
}
Map<AuthorizableType, EnumSet<DBModelAction>> requiredOutputPrivileges =
stmtAuthPrivileges.getOutputPrivileges();
if(isDebug) {
LOG.debug("requiredOuputPrivileges = " + requiredOutputPrivileges);
LOG.debug("outputHierarchyList = " + outputHierarchyList);
}
boolean found = false;
for (Map.Entry<AuthorizableType, EnumSet<DBModelAction>> entry : requiredInputPrivileges.entrySet()) {
AuthorizableType key = entry.getKey();
for (List<DBModelAuthorizable> inputHierarchy : inputHierarchyList) {
if (getAuthzType(inputHierarchy).equals(key)) {
found = true;
if (!authProvider.hasAccess(subject, inputHierarchy, entry.getValue(), activeRoleSet)) {
throw new AuthorizationException("User " + subject.getName() +
" does not have privileges for " + hiveOp.name());
}
}
}
if (!found && !key.equals(AuthorizableType.URI) && !(hiveOp.equals(HiveOperation.QUERY))
&& !(hiveOp.equals(HiveOperation.CREATETABLE_AS_SELECT))) {
//URI privileges are optional for some privileges: anyPrivilege, tableDDLAndOptionalUriPrivilege
//Query can mean select/insert/analyze where all of them have different required privileges.
//CreateAsSelect can has table/columns privileges with select.
//For these alone we skip if there is no equivalent input privilege
//TODO: Even this case should be handled to make sure we do not skip the privilege check if we did not build
//the input privileges correctly
throw new AuthorizationException("Required privilege( " + key.name() + ") not available in input privileges");
}
found = false;
}
for (Map.Entry<AuthorizableType, EnumSet<DBModelAction>> entry : requiredOutputPrivileges.entrySet()) {
AuthorizableType key = entry.getKey();
for (List<DBModelAuthorizable> outputHierarchy : outputHierarchyList) {
if (getAuthzType(outputHierarchy).equals(key)) {
found = true;
if (!authProvider.hasAccess(subject, outputHierarchy, entry.getValue(), activeRoleSet)) {
throw new AuthorizationException("User " + subject.getName() +
" does not have privileges for " + hiveOp.name());
}
}
}
if(!found && !(key.equals(AuthorizableType.URI)) && !(hiveOp.equals(HiveOperation.QUERY))) {
//URI privileges are optional for some privileges: tableInsertPrivilege
//Query can mean select/insert/analyze where all of them have different required privileges.
//For these alone we skip if there is no equivalent output privilege
//TODO: Even this case should be handled to make sure we do not skip the privilege check if we did not build
//the output privileges correctly
throw new AuthorizationException("Required privilege( " + key.name() + ") not available in output privileges");
}
found = false;
}
}由代码可知,传入的stmtAuthPrivileges包含了输入对象权限map和输出对象权限map,需要分别对它们进行权限的验证,map的key值为一个AuthorizableType枚举对象,取值为Server,Db,Table,Column,View,URI中的一种,对于每一个AuthorizableType,至少有一个inputList或outputList与其authzType相同,此时通过Provider的hasAccess方法判断该用户是否对该对象列表拥有相应的权限(entry.getValue代表了需要的权限)。
如果没有一个inputList或者outputList与之类型相同,且该AuthorizableType不是uri,hiveOp不是QUERY操作,则直接抛出异常,这里的意思说,如果对一个表A需要进行除去select之外的操作,则必须拥有相应的权限。
分析到这里发现,authorize并不是最终判断权限的方法,还需要调用Provider的hasAccess方法,这里也很好理解,因为我们这里只有本次操作的访问控制对象所需要的权限集合,并没有该用户当前获得的权限集合,因此,我们需要通过Provider来将用户的权限集合从存储介质中读出来,前面提到过,目前支持文件(本地/hdfs)和关系型数据库两种存储方式。
Provider中有三个相关的对象,分别为Policy Engine, Provider, Provider Backend。
- Policy engine 默认为org.apache.sentry.policy.engine.common.CommonPolicyEngine类
- Provider默认为org.apache.sentry.provider.common.HadoopGroupResourceAuthorizationProvider
- Backend默认为org.apache.sentry.provider.file.SimpleFileProviderBackend,可以在sentry-site.xml中配置sentry.hive.provider.backend为SimpleDBProviderBackend来使用数据库存储策略
它们三者的关系是:Provider 包含 Policy Engine 包含 Provider Backend
hasAccess方法内部调用了私有方法doHasAccess,其定义如下:
private boolean doHasAccess(Subject subject,
List<? extends Authorizable> authorizables, Set<? extends Action> actions,
ActiveRoleSet roleSet) {
//获得用户的组信息
Set<String> groups = getGroups(subject);
//用户名集合
Set<String> users = Sets.newHashSet(subject.getName());
//授权对象集合, 形如 table=student
Set<String> hierarchy = new HashSet<String>();
for (Authorizable authorizable : authorizables) {
hierarchy.add(KV_JOINER.join(authorizable.getTypeName(), authorizable.getName()));
}
//形如 table=student->select的数组
List<String> requestPrivileges = buildPermissions(authorizables, actions);
//使用policy engine获取用户,角色对应的权限集合,此时读取数据库或策略文件
Iterable<Privilege> privileges = getPrivileges(groups, users, roleSet,
authorizables.toArray(new Authorizable[0]));
lastFailedPrivileges.get().clear();
for (String requestPrivilege : requestPrivileges) {
//将形如table=student->select的字符串创建成Privilege对象,用于权限验证
Privilege priv = privilegeFactory.createPrivilege(requestPrivilege);
for (Privilege permission : privileges) {
/*
* Does the permission granted in the policy file imply the requested action?
*/
boolean result = permission.implies(priv, model);
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("ProviderPrivilege {}, RequestPrivilege {}, RoleSet {}, Result {}",
new Object[]{ permission, requestPrivilege, roleSet, result});
}
if (result) {
return true;
}
}
}
lastFailedPrivileges.get().addAll(requestPrivileges);
return false;
}permission.implies(priv, model);是最终的权限验证步骤,调用的是Privilege的该方法,在此处,是Privilege的一个实现类CommonPrivilege,它通过传入一个字符串进行构造,将其解析为一个KeyValue的List,然后在implies方法中使用它来进行权限的验证,implies方法如下:
@Override
public boolean implies(Privilege privilege, Model model) {
// By default only supports comparisons with other IndexerWildcardPermissions
if (!(privilege instanceof CommonPrivilege)) {
return false;
}
List<KeyValue> otherParts = ((CommonPrivilege) privilege).getParts();
if(parts.equals(otherParts)) {
return true;
}
int index = 0;
for (KeyValue otherPart : otherParts) {
// If this privilege has less parts than the other privilege, everything
// after the number of parts contained
// in this privilege is automatically implied, so return true
//这里的含义是,如果用户对table拥有权限,当前访问的对象(other)为column,则用户默认拥有对column的权限,粗粒度的权限包含了细粒度的权限
if (parts.size() - 1 < index) {
return true;
} else {
KeyValue part = parts.get(index);
String policyKey = part.getKey();
// are the keys even equal
if(!policyKey.equalsIgnoreCase(otherPart.getKey())) {
// Support for action inheritance from parent to child
if (SentryConstants.PRIVILEGE_NAME.equalsIgnoreCase(policyKey)) {
continue;
}
return false;
}
// do the imply for action
if (SentryConstants.PRIVILEGE_NAME.equalsIgnoreCase(policyKey)) {
if (!impliesAction(part.getValue(), otherPart.getValue(), model.getBitFieldActionFactory())) {
return false;
}
} else {
if (!impliesResource(model.getImplyMethodMap().get(policyKey.toLowerCase()),
part.getValue(), otherPart.getValue())) {
return false;
}
}
index++;
}
}
// If this privilege has more parts than the other parts, only imply it if
// all of the other parts are wildcards
//如果该用户有更细粒度的权限,只有其权限为*时,才让其通过验证
for (; index < parts.size(); index++) {
KeyValue part = parts.get(index);
if (!SentryConstants.PRIVILEGE_WILDCARD_VALUE.equals(part.getValue())) {
return false;
}
}
return true;
}至此,权限的验证已经分析完成了,sentry在最终验证权限之前才根据用户的组、角色从数据库中读取其拥有的权限,并与需要的权限进行比对,用户信息的读取是在Policy backend中进行的,Policy provider层屏蔽了不同组件的权限分类,使用通用的形式进行验证,可以进行重复使用。
小结
本文分析了Sentry是如何对HiveServer2进行用户的细粒度访问控制的,并详细介绍了从session hook设置用户信息,到Policy backend读取用户已有权限的代码逻辑,对sentry的工作原理和流程有了初步的认识。其鉴权的本质是将用户已有的权限与访问对象所需权限进行比对,如果全部满足,或者用户已有权限更加粗粒度,此时认为该用户拥有其资源的访问权限,可以理解为权限字符串的比对。sentry通过一个通用的Policy Provider来对屏蔽不同组件的权限对象的差异性,达到了一个通用模块来进行权限验证的目的。
