

使用 Neuroph Java 框架创建人工神经网络
主宰您的“疯狂三月”办公室竞猜!
本教程集合了我感兴趣的三个方面:Java 语言、人工神经网络和年度 NCAA 男篮甲级锦标赛(也称为“疯狂三月”)。鉴于这一点,在本教程中,我将介绍以下四个主题:
- 人工神经网络 (ANN) 概念
- 多层感知器 (MLP)
- Neuroph Java 神经网络框架
- 案例研究:疯狂三月
我并不打算提供人工神经网络的全套(或近乎全套的)理论。网络上已经有很多资源都很好地阐述了这一复杂主题(在需要时我会提供链接)。我要做的是帮助您直观认识 ANN 并了解其工作原理。
请注意:文章涉及部分数学知识,但仅在绝对必要或更加简明起见才会对其进行展示。有时一个等式胜过千言万语,但我会尽量少用等式。
人工神经网络概念
人工神经网络是一个计算结构 — 在多数情况下它是一个计算机程序,受生物网络的启发,特别是动物大脑中发现的神经网络。它由多层人工神经元(以下简称为神经元)组成,其中每一层神经元都连接到直接相邻层的神经元。
网络上有太多关于此概念的描述,因此我不想过多解释多层神经网络,您可以通过下图了解:
图 1. 人工神经网络层描述(来源:维基百科)
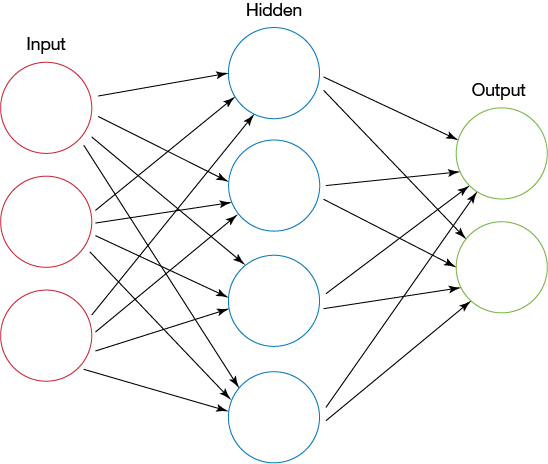
在本教程中,有时将"层"称作其相邻层的“上一层”和“下一层”。在图 1 中可以看到,我将输入层称为隐藏层的上一层,而隐藏层则是输出层的上一层。由此类推,输出层是隐藏层的下一层,而隐藏层则是输入层的下一层。
总的来说,其工作方式如下:网络给定层中的一个人工神经元可以向下一层中的每个其他神经元发送输出信号(即 -1 和 1 之间的数字)。如果神经元进入“激发”状态,它将发送输出信号,否则不发送。在此类型的前馈网络中,某一层神经元的输出是下一层神经元的输入。信号从某一层神经元正向传播以馈送到下一层神经元,最终,将在网络的输出层计算出合计总输出,这样网络就能计算出“答案”。
神经网络特别适用于模式识别这一类问题。使用包含已知输入和输出的数据(称为训练数据)来训练神经网络,直到网络可以准确识别出训练数据中的模式。
神经网络之所以擅长识别模式是因为其可塑性。每个神经元间连接都有一个与之相关的权重。训练网络时,首先将训练数据馈送到网络,接着计算出网络的输出,然后将其与期望结果进行比较。计算出实际结果与期望结果之间的差值(称为“误差”)。之后,训练程序通过调整网络层中所有神经元连接权重,从输出层开始小心地反向传播误差,随后再次发送训练数据(这样的每一次迭代称为一个训练循环)。
神经元连接权重中这一可变性(即,可塑性)会改变学习过程中每次运行的网络答案。
此过程将一直持续,直到误差容忍度达到可接受级别,则视为网络训练完成。会向新训练的网络馈送类似(但明显不同于)训练数据的输入数据,以查看网络给出的答案,从而对网络进行验证。
这种训练神经网络的方法称为监督式学习,稍后我们将更详细地探讨这种方法。
全部理解了吗?如果不理解也没有关系。刚才我提到了一连串的概念,现在来详细解释一下这些概念。
人工神经元
神经网络的核心是人工神经元。它有三个主要特征:
- 连接:在本教程所展示的各种网络中,给定层中的每个神经元都会连接到直接相邻层中的每个其他神经元。
- 输入信号:指上一层中每个神经元接收到的数字值的集合,或者对于输入层中的神经元来说是一个归一化值,稍后我们会介绍归一化。
- 输出信号:指神经元发送到下一层每个神经元的单个数字值,或者当此神经元位于输出层,则指“答案”。
监督式学习
简单来说,监督式学习需要采用一组示例,并且每个示例包含一个输入和一个期望输出。将输入馈送到神经网络,直至它能够(在指定的误差容忍度内)可靠地生成期望的输出。
也可以采用下面的方式来解释,就像我对我的孩子们解释的那样:
- 将已知数据馈送到网络。
- 问:网络生成正确的答案了吗?
- 是(在误差容忍度内):转至步骤 3。
- 否:
- 调整网络的连接权重。
- 转至步骤 1
- 完成。
(此时,孩子们会忍不住翻白眼,但他们完全理解了。)
有关监督式学习的更正式的讨论,请查看有关机器学习的 IBM developerWorks 教程。
多层感知器 (MLP)
多层感知器 (MLP) 是一种神经网络,具有一个输入层和一个输出层,中间还有一个或多个隐藏层。每一层的神经元数量可能不同但是固定的(即,定义网络结构后,在所有训练循环的持续时间内,这一数量是固定的)。
如前所述,每个神经元连接都有一个权重、一个输入函数和一个输出函数。本部分中,我将更详细描述上述概念,同时还将介绍另外几个概念,您将需要这些概念来了解如何在以下的案例研究中使用 MLP。
神经元权重
当像动物大脑这样的生物网络中某个神经元进入“兴奋”状态时,它会沿轴突将电信号发送到其所连接神经元的树突。信号的强度决定了"兴奋"神经元对任何“下游”神经元的影响力。
ANN 计算模型的设计与此类型生物网络相似,并用输出连接权重来模拟信号强度。
人工神经元权重包含两个概念:可塑性和信号强度。可塑性指的是可在训练循环之间调整权重的这一特性,信号强度指的是"兴奋"神经元对下一层中连接神经元的影响力。
总结如下,给定网络层中的每个神经元:
- 都与上一层的每个神经元相连接(输入神经元除外,它们没有上一层)
- 都与下一层的每个神经元相连接(输出神经元除外,它们没有下一层)
- 都有一个与其输出连接相关联的权重(用于模拟输出的信号强度)。
输入函数
可能会有多个(称为 n 个)信号进入人工神经元(见图
1),网络需要将所有这些信号转化为单个可估算值。这就是输入函数要完成的工作:将输入信号集合转化为单个值(通常是 -1 和 1 之间的数字)。
最常见的一类输入函数称为加权和。假设神经元 N 连接到网络上一层的 n 个神经元。神经元 N 的输入的加权和 A 使用如下公式计算:将全部 n 个输入中每个连接的输入值 a 与连接权重 w 的乘积相加。公式如下所示:
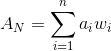
哇哦,使用了数学公式啊!确实如此。我们来举个例子吧。假设神经元 N 与上一层中的 3 个神经元连接,这样就有 n = 3 个输入值,以上公式中 a 的值为 { 0.3, 0.5, 0.6 },而其对应的权重 w 值分别为 { 0.4, -0.2, 0.9 }。因此,神经元 N 的加权和 A 将为:
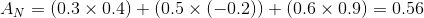
输出(激活)函数
输出函数决定某个神经元是否激发,即,是否将其输出信号传送到网络下一层的所有神经元。
MLP 网络中最常用的一类激活函数是 Sigmoid 函数。对于给定神经元的任何加权和 A,A 的 Sigmoid 值 V 使用如下公式计算:
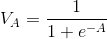
Sigmoid 函数是非线性的,因此非常适用于神经网络。扫一眼上述公式就会发现,A 趋近于负无穷大时,分母相应变得无穷大,该函数值趋近于零。由此类推,A 趋近于正无穷大时,指数项消失,该函数值趋近于 1。
您可以在此阅读有关 Sigmoid 函数的更多信息。
网络误差函数
监督式学习主要是对神经网络输出进行缓慢的系统化误差校正,因此,训练程序首先需要一种方法来计算误差。
MLP 网络中最常用的误差函数是均方误差函数。从本质上讲,该函数的作用是计算训练程序算出的实际值与训练数据中的期望值之间的平均“差异”。
数学公式如下:
假设有 n 个输出神经元,每个输出神经元的加权和为 A,训练程序计算训练数据给出的值与网络给出的值的差,求出其平方值,将所有输出神经元的这些值相加,然后除以输出神经元数 n,从而求出总输出误差 E。
简单来说:假设您的目标是投掷一个飞镖,让其击中标靶中心(靶心)。每次投掷飞镖时,其在标靶上的落镖位置与靶心的距离为 d(正中靶心则表示 d = 0)。
要算出您的命中情况怎么样,可计算您偏离的平均距离,以便了解后面的投掷必须校正到什么程度才能使投掷得更准确。
虽然神经网络不像投掷飞镖那样简单,但道理相同:在每个训练循环中,训练者将计算由网络计算出的值(从训练数据得出的 Aexpected)离靶心的“距离”(误差 E),然后相应地调整网络权重。原则上讲,校正的幅度与网络中的误差成正比。或者以投掷飞镖为例:如果落镖点距靶心较远,则需要大幅校正;如果距靶心较近,则只需小幅校正。
误差反向传播
训练循环结束时,训练程序会计算神经网络误差,并修改网络中的连接权重。如上一部分中所述,反向传播是从输出层开始反向进行(目的地是输入层),在操作过程中调整每个神经元连接的权重。
这称为误差反向传播,也是训练神经网络的一种有效方法。
如果您想知道训练程序到底如何调整权重,我这里有好消息也有坏消息。首先,坏消息是此项技术由四个等式组成,使用来自多变量微积分、统计和线性代数的先进技术。很显然,这将会涉及到许多数学知识。这不仅让您心生畏惧,还超出了此教程的范围。
现在来说说好消息:您不需要了解实现过程就可以使用反向传播!只要您对于原理有直观认识,就可以采用反向传播来训练一些十分了不起的网络(相信我)。
但是,如果想要查看所涉及的所有数学知识,可以查看 Michael Nielsen 发布的这一精彩内容。
Neuroph Java 神经网络框架
好了,理论部分说的够多的了。下面来谈一谈如何使用。
对我们来说,幸运的是有一个名为 Neuroph 的基于 Java 的框架,它实施了前一部分中一笔带过的所有晦涩难懂的细节 (大部分)。在本部分中,我想要介绍 Neuroph 框架,并简要说明一下选它进行案例研究的原因。
我喜欢 Neuroph 框架的几个原因:
- 纯 Java 编码:还需要多说吗?需要的话,那下面来讲一讲。Java 语言是全球最流行的语言(话筒掉落)。
- 支持多种类型的网络:包括多层感知器。
- Neuroph API 使用起来超级方便,因为相关资料较少,所以这是一个很大的优势。
下载并安装 Neuroph
要下载 Neuroph,请访问此页面,选择 Neuroph 框架 ZIP 文件。
在计算机上解压 .zip 文件,找到 Neuroph 核心 .jar 文件,编写本文件时名为 neuroph-core-2.94.jar。
本次编写时,最新的 Neuroph 版本 (2.94) 不在 Maven Central 中,要使用它的话,需要在本地 Maven 库中安装。我将在视频中展示如何执行该操作。
如果要使用用户界面,请选择适合您平台的下载文件。可以使用用户界面加载并训练网络,尽管我发现此功能稍显欠缺(我完全承认这可能是我自己的原因)。
对于小型网络(输入神经元数量不足 10 个),用户界面的使用效果很好,但对于本案例研究中使用的网络,我发现要一直来回滚动才能看到全貌。即便这样,我也从未在屏幕上看到过完整的网络。
另外,我喜欢编写代码,而 Neuroph API 与其理论概念完全相符,因此我启用了 Eclipse,开始写一些代码!
案例研究:视频
案例研究:疯狂三月
早在几年前,我就萌生出利用 ANN 预测 NCAA 男篮甲级锦标赛(也称为“疯狂三月”)冠军的想法。但我不知道该从何处入手。
我知道神经网络非常擅长发现数据元素中“隐藏”的关系,而这些关系对于人类来说并不那么明显。从孩提时代我就是一个篮球迷,因此我会查看两队赛季表现的统计汇总,大致判断出他们在锦标赛中所表现出的水平。但看了几个统计类别后,我就开始头疼了。对于像我这样的正常人类来说,这样的数据量实在太过庞大。
但我不能将这个想法束之高阁。“数据中一定隐含着什么”,我一直这样对自己说。我拥有学术背景,我和我的三个孩子完成了大约(貌似)一百万个科学展览项目。因此,我决定将科学知识运用到其中,并提出了以下问题:“是否有可能仅使用常规赛数据准确 (> 75%) 选出某项体育赛事的冠军?”
我的假设:是的。有可能。
经过几年的磕磕碰碰后,我创建了本案例研究中现在所述的过程,来预测 2017 NCAA 男篮甲级锦标赛的冠军。
通过使用涵盖 21 个统计类别和 5 个赛季的有价值的历史数据,我训练了 30 多个独立网络,将它们作为网络“阵列”同时运行(目的是通过多个网络来消除误差)来对锦标赛对阵表作出预测。
这些网络的出色表现让我感到震惊。67 项赛事中,我的网络阵列正确预测了 48 个(约为 72%)。不错,但很遗憾,我的假设被证实是错的。现在,回过头看,对于科学来说这是一件好事:失败会激发我们不断尝试。
言归正传,下面来介绍一下训练和运行网络阵列所遵循的过程。请注意:这一过程十分先进。此处我将展示的是一种可行性,而非教程。但是,如果您在我展示的代码或过程中发现错误,或者想要提出改进建议(或分享您使用代码的成功案例),请留下评论。
1加载数据库
要创建数据来训练网络(训练数据),首先需要获取整个常规赛的统计数据。在对提供免费可用数据的网站进行全面搜索后,我选中了 ncaa.com,该网站几乎提供了全部赛事的历史常规赛数据,包括男篮(数据仅免费用于非商业用途,在下载任何内容前都请仔细阅读其服务条款)。
下载数据
Ncaa.com 提供了完善的(可能不太直观)界面来供用户下载所有类型的大型数据。我确认需要的是自 2010 年开始的常规赛的球队数据(而不是个人数据)。截止 2017 年三月完成这一项目时,总共使用了 8 年的历史数据(包含 2017 常规赛季)。
我浏览了多个屏幕(如果想了解更多信息,可以观看视频)来下载数据,并下载了自 2010 年起的球队数据,包括如下统计类别:
- 每场比赛的平均得分
- 投球命中率
- 罚球命中率
- 每场比赛的抢断
- 每场比赛的失误
及其他更多内容(请查看 GitHub 中的源代码以了解完整详细信息)。此数据涵盖三个主要领域:进攻(例如投球命中率)、防守(例如每场比赛的抢断)和失误(例如每场比赛的失误)。
Ncaa.com 提供了不同的下载格式,但我选择了逗号分隔变量 (CSV) 格式,这样就能使用 OpenCSV 进行处理。该赛季的所有统计数据都在单个文件中,通过标头分隔符指示数据所属的统计类别。后面是下一标头/数据组合,以此类推。在视频中,我将展示 CSV 数据的外观,所以一定要看哦!
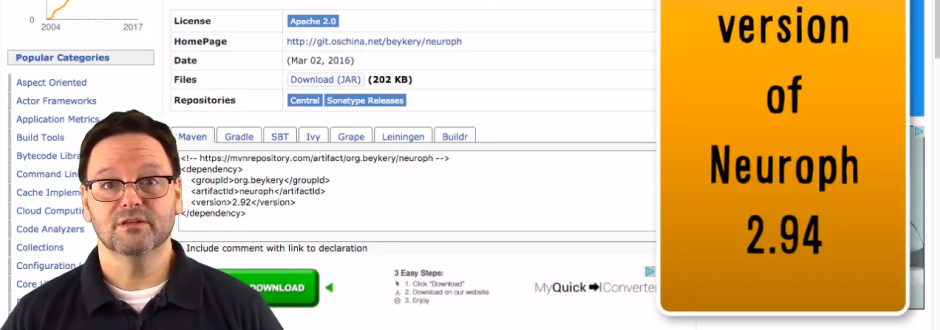
看完下面的图,您将明白数据是如何格式化的。
首先是文件顶部的数据。最开始是几个空行,后跟一个 3 行标头,统计类别(使用下划线标出)在标头的第 2 行,再后面是更多空行,接着是该统计类别的 CSV 数据(包括标题行)。
图 2. 文件一开始是 2011 赛季的 CSV 数据
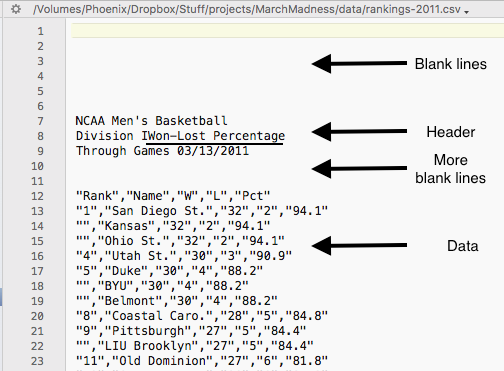
该统计类别的数据结束后,紧接着开始下一类别。对于剩余统计类别重复此模式。下图显示统计类别“进攻得分”的数据,这些数据紧跟在 图 2 中显示的数据末尾后面。
图 3. 更多的 2011 赛季 CSV 数据
生成 SQL 加载脚本
了解 CSV 文件的布局,我认为可以用编程方式处理数据,并决定使用策略模式来处理数据。这样,就算 Ncaa.com 的 IT 人员每年都更改文件中统计数据的顺序,但只要支持 { { header, data }, { header, data } ...} 元组,我的策略模式实施就能不受数据顺序变更的影响。
Strategy 接口定义如下:
package com.makotojava.ncaabb.sqlgenerator;
import java.util.List;
public interface Strategy {
String generateSql(String year, List<String[]> data);
String getStrategyName();
int getNumberOfRowsProcessed();
}针对每个统计类别都实施了一个 Strategy。在此我将不讨论详细信息,以免让你们感到枯燥。如果要查看更多内容,请查看源代码。
用于生成 SQL 的程序称为 SqlGenerator,它的主要工作是解析 CSV 文件,查找统计类别标头,选择用于处理该部分内容的相应策略,委托该策略进行处理,重复这一过程直至到达文件末尾,然后编写 SQL 加载脚本。如果未找到特定统计类别的对应策略(ncaa.com 提供的统计类别数量超过我决定要使用的类别数量),那么程序将跳到下一标头。
每个策略的工作是处理类别详细数据值,为其创建 SQL INSERT 语句,然后我可以使用这些语句将数据加载到数据库。SqlGenerator 针对每一年编写一个加载脚本,其中包含带有相应策略的所有统计类别数据的对应 SQL INSERT 语句。
编写程序(及所有策略)后,我又编写了一个名为 run-sql-generator.sh 的脚本来驱动该程序,然后针对要加载的所有年份运行此脚本。
2011 年的对应 SQL 脚本(名为 load_season_data-2011.sql)如下所示:
INSERT INTO won_lost_percentage(YEAR, TEAM_NAME, NUM_WINS, NUM_LOSSES, WIN_PERCENTAGE)VALUES(2011,'San Diego St',32,2,0.941);
INSERT INTO won_lost_percentage(YEAR, TEAM_NAME, NUM_WINS, NUM_LOSSES, WIN_PERCENTAGE)VALUES(2011,'Kansas',32,2,0.941);
INSERT INTO won_lost_percentage(YEAR, TEAM_NAME, NUM_WINS, NUM_LOSSES, WIN_PERCENTAGE)VALUES(2011,'Ohio St',32,2,0.941);
INSERT INTO won_lost_percentage(YEAR, TEAM_NAME, NUM_WINS, NUM_LOSSES, WIN_PERCENTAGE)VALUES(2011,'Utah St',30,3,0.909);
INSERT INTO won_lost_percentage(YEAR, TEAM_NAME, NUM_WINS, NUM_LOSSES, WIN_PERCENTAGE)VALUES(2011,'Duke',30,4,0.882);
.
(更多数据)
.
INSERT INTO won_lost_percentage(YEAR, TEAM_NAME, NUM_WINS, NUM_LOSSES, WIN_PERCENTAGE)VALUES(2011,'Toledo',4,28,0.125);
INSERT INTO won_lost_percentage(YEAR, TEAM_NAME, NUM_WINS, NUM_LOSSES, WIN_PERCENTAGE)VALUES(2011,'Centenary LA',1,29,0.033);
.
INSERT INTO scoring_offense(YEAR, TEAM_NAME, NUM_GAMES, NUM_POINTS, AVG_POINTS_PER_GAME)VALUES(2011,'VMI',31,2726,87.9);
INSERT INTO scoring_offense(YEAR, TEAM_NAME, NUM_GAMES, NUM_POINTS, AVG_POINTS_PER_GAME)VALUES(2011,'Oakland',34,2911,85.6);
INSERT INTO scoring_offense(YEAR, TEAM_NAME, NUM_GAMES, NUM_POINTS, AVG_POINTS_PER_GAME)VALUES(2011,'Washington',33,2756,83.5);
INSERT INTO scoring_offense(YEAR, TEAM_NAME, NUM_GAMES, NUM_POINTS, AVG_POINTS_PER_GAME)VALUES(2011,'LIU Brooklyn',32,2643,82.5);
INSERT INTO scoring_offense(YEAR, TEAM_NAME, NUM_GAMES, NUM_POINTS, AVG_POINTS_PER_GAME)VALUES(2011,'Kansas',34,2801,82.3);
.
(你们懂了吧)
.第 1 行显示的是“赢/输百分比”统计类别的第一个 SQL INSERT,第 12 行显示的是“得分进攻”统计类别的第一个 SQL INSERT。 将此代码与 图 2 和 图 3 进行比较,了解如何从 CSV 数据转换到 SQL INSERT。
从 CSV 数据生成所有 SQL 脚本后,我就准备好向数据库加载数据了。
将数据加载到 PostgreSQL 数据库
我编写了一个脚本来将数据加载到 PostgreSQL 数据库。在下面的示例中,我运行了 psql 交互式 shell。首先,我创建了 ncaabb 数据库,然后退出该 shell。
Ix:~ sperry$ "/Applications/Postgres.app/Contents/Versions/9.6/bin/psql" -p5432 -d "sperry"
psql (9.6.1)
Type "help" for help.
sperry=# create database ncaabb;
CREATE DATABASE
sperry=# \q
Ix:~ sperry$然后,我连接到 ncaabb 数据库,并运行了 build_db.sql 脚本:
Ix:~ sperry$ "/Applications/Postgres.app/Contents/Versions/9.6/bin/psql" -p5432 -d "ncaabb"
psql (9.6.1)
Type "help" for help.
ncaabb=# begin;
BEGIN
ncaabb=# \i /Users/sperry/home/development/projects/developerWorks/NcaaMarchMadness/src/main/sql/build_db.sql
BUILDING DB...
脚本变量:
ROOT_DIR ==> /Users/sperry/home/development/projects/developerWorks/NcaaMarchMadness/src/main
SQL_ROOT_DIR ==> /Users/sperry/home/development/projects/developerWorks/NcaaMarchMadness/src/main/sql
DATA_ROOT_DIR ==> /Users/sperry/home/development/projects/developerWorks/NcaaMarchMadness/src/main/data
LOAD_SCRIPT_ROOT_DIR ==> /Users/sperry/l/MarchMadness/data
CREATING ALL TABLES...
CREATING ALL VIEWS...
LOADING ALL TABLES:
YEAR: 2010...
YEAR: 2011...
YEAR: 2012...
YEAR: 2013...
YEAR: 2014...
YEAR: 2015...
YEAR: 2016...
YEAR: 2017...
LOADING TOURNAMENT RESULT DATA FOR ALL YEARS...
FIND MISSING TEAM NAMES...
DATABASE BUILD COMPLETE.
ncaabb=# commit;
COMMIT
ncaabb=#这时,数据已加载完毕,我准备好创建训练数据了。
2创建训练数据
我编写了一个名为 DataCreator 的程序,用于创建特定年份的训练数据。如同我编写的其他实用程序一样,我还编写了一个 shell 脚本来驱动此程序,并将该脚本命名为 run-data-creator.sh。
运行 DataCreator 非常简单。我仅指定了希望获取训练数据的年份,该程序将读取数据库并为我生成数据。当然,我必须编写一些支持类来使 DataCreator 实现以上操作,其中包含一组数据访问对象(DAO,用于从数据库读取数据)和一些 Java 模型对象(用于保存数据)。
确保在源代码中查看这些内容,特别是在 com.makotojava.ncaabb.dao 和 com.makotojava.ncaabb.model 程序包中。
要运行 run-data-creator.sh,我在 Mac 上打开了一个终端窗口,指定创建 2010 - 2017 年的数据:
Ix:$ ./run-data-creator.sh 2010 2011 2012 2013 2014 2015 2015 2017
Number of arguments: 8
Script arguments: 2010 2011 2012 2013 2014 2015 2015 2017
INFO: Properties file 'network.properties' loaded.
2017-09-28 15:40:38 INFO DataCreator:72 - *********** CREATING TRAINING DATA **************
2017-09-28 15:40:44 INFO DataCreator:132 - *********** SAVING TRAINING DATA **************
2017-09-28 15:40:44 INFO DataCreator:136 - Saved 128 rows of training data 'NCAA-BB-TRAINING_DATA-2010.trn'
2017-09-28 15:40:51 INFO DataCreator:132 - *********** SAVING TRAINING DATA **************
2017-09-28 15:40:51 INFO DataCreator:136 - Saved 134 rows of training data 'NCAA-BB-TRAINING_DATA-2011.trn'
2017-09-28 15:40:57 INFO DataCreator:132 - *********** SAVING TRAINING DATA **************
2017-09-28 15:40:57 INFO DataCreator:136 - Saved 134 rows of training data 'NCAA-BB-TRAINING_DATA-2012.trn'
2017-09-28 15:41:04 INFO DataCreator:132 - *********** SAVING TRAINING DATA **************
2017-09-28 15:41:04 INFO DataCreator:136 - Saved 134 rows of training data 'NCAA-BB-TRAINING_DATA-2013.trn'
2017-09-28 15:41:10 INFO DataCreator:132 - *********** SAVING TRAINING DATA **************
2017-09-28 15:41:10 INFO DataCreator:136 - Saved 134 rows of training data 'NCAA-BB-TRAINING_DATA-2014.trn'
2017-09-28 15:41:17 INFO DataCreator:132 - *********** SAVING TRAINING DATA **************
2017-09-28 15:41:17 INFO DataCreator:136 - Saved 134 rows of training data 'NCAA-BB-TRAINING_DATA-2015.trn'
2017-09-28 15:41:23 INFO DataCreator:132 - *********** SAVING TRAINING DATA **************
2017-09-28 15:41:23 INFO DataCreator:136 - Saved 134 rows of training data 'NCAA-BB-TRAINING_DATA-2015.trn'
2017-09-28 15:41:29 INFO DataCreator:132 - *********** SAVING TRAINING DATA **************
2017-09-28 15:41:29 INFO DataCreator:136 - Saved 134 rows of training data 'NCAA-BB-TRAINING_DATA-2017.trn'
Ix:~/home/development/projects/developerWorks/NcaaMarchMadness/src/main/script sperry$创建训练数据后,接下来是训练并验证网络,之后我将利用这些网络来选取 NCAA 男篮甲级锦标赛球队 。
本教程一开始我就说过,我将讨论归一化,现在是时候了。
对所有输入数据进行归一化的原因在于,并非所有数据都是以相同方式创建的(从数字表示角度来讲)。例如,每队的赢/输百分比这一数据统计类别是一个百分数,正如您所想的,其值介于 0 和 1 之间。相反,对于场均犯规次数(指所有比赛的平均值),其下限为 0,并且根本没有上限。
将两个范围不同的原始数字进行比较毫无意义。因此,需要对数据进行归一化,特别是使用名为特征缩放的归一化方法。我使用的等式很简单:
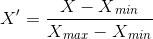
对于任何原始值 X,算出的归一化值 X' 的值范围为 Xmin 到 Xmax。当然,这意味着我需要计算所有统计类别的最大值和最小值。但因为数据位于数据库中,所以可以轻松地定义一个视图来让 PostgreSQL 执行此操作(查看 v_season_analytics 视图及其在 create_views.sql 中的定义)。
DataCreator 负责对所有训练数据进行归一化。现在,我终于准备好开始训练网络了。
训练并验证网络
使用监督式学习来训练和验证 ANN 时,既要讲求艺术性又要讲求科学性。我需要很好地了解数据(科学性),同时也要猜测(艺术性)最佳网络结构,直到找到有效的结构。我不得不提出诸如以下的问题:
- 23 个可用统计类别中我要用到哪些?
- 我希望网络中包含多少个隐藏层?
- 每个隐藏层中应该有多少个神经元?
- 网络的输出应该是怎样的?
结果,我选择了 23 个类别中的 21 个。因此有 42 个输入(每支球队一个)。对于输出,我认为应该是基于两队间示例对决的归一化得分:对于任何指定的模拟赛,归一化得分较高的球队获胜。
对于隐藏层的数量和每层的神经元数,我进行了一些研究,但最终结论是要靠反复试验来确定。我在网络中运行了多次训练数据,网络的猜中率均在 70% 以上。
我编写了一个名为 MlpNetworkTrainer 的程序,该程序的唯一使命就是训练并验证网络,最终保留那些猜中率超出指定阈值的网络。
下面是我的做法:我指导 MlpNetworkTrainer 使用 2010-2014 年的数据来训练网络,然后根据 2015 和 2016 年的数据来验证网络,最终保留那些猜中率超出阈值 (70%) 的网络。
如果网络的猜中率超出了阈值 (70%),程序将保留该网络作为锦标赛竞猜网络阵列中的一个网络。否则,将丢弃该网络。
我重复此过程,直到保留 31 个网络来构成模拟锦标赛的网络“阵列”。
4模拟锦标赛
常规赛结束后(3 月 10 号左右),我下载了 CSV 数据,通过 SqlGenerator 运行了该数据,并将该数据加载到数据库。
在“NACC 锦标赛选拔委员会”选择球队来参加 2017 年锦标赛后,我创建了一个名为 tourney_teams_file_2017.txt 的文件,其中包含将参加锦标赛的所有球队(我已对 2010 - 2016 赛季的球队执行了该操作)。
我运行了编写的程序来创建 SQL INSERT,这样我就能将 2017 年的参赛队加载到 tournament_participant 表中。前几年中我已经这样做了,因此我能创建验证网络所需的数据。
现在一切就绪。我有了 31 个经过训练并验证的网络,也有了 2017 年的赛季数据。现在,所有障碍都已清除。但我还需要一种方法来可视化球队之间两两对决的方式。
因此,我编写了一个名为 TournamentMatrixPredictor 的程序来为参加锦标赛的每支球队生成一个 CSV 文件,我可以将这个文件加载到 Open Office Calc。每个文件都包含某支特定球队与锦标赛中其他球队之间的模拟赛的预测结果。。
下图中显示了中田纳西州州立大学队的文件,此文件将作为 Calc 电子表格加载到 Open Office 中。
图 4. 中田纳西州州立大学队的网络预测
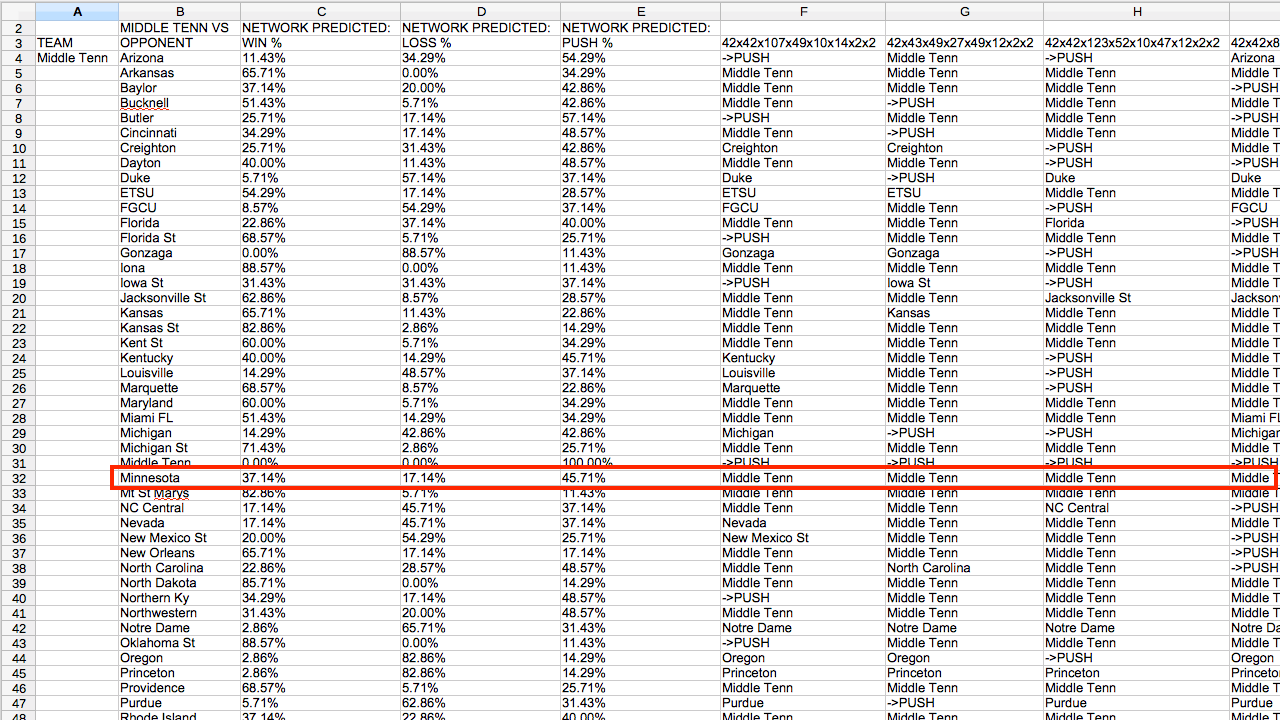
这些电子表格显示了中田纳西州州立大学队 (TEAM) 与锦标赛中(包括中田纳西州州立大学队自身)其他每个球队 (VS OPPONENT) 的模拟对决情况,以及 31 个网络的平均预测结果,其中中田纳西州州立大学队将打赢对手 (WIN %)、输给对手 (LOSS %) 或与对手打成平局 (PUSH %),另外还有单个网络的结果。
向右延伸(框架外)是单个网络的预测结果(仅预测出的获胜队)。例如,结构为 42x42x107x49x10x14x2x2 — 42 个输入神经元、6 个隐藏层(第一层 42 个神经元,下一层 107 个神经元,依此类推)和 2 个输出神经元 — 的网络显示了预测的每次对决的获胜队。
在第一轮中,12 号种子中田纳西州州立大学队的对手 5 号种子明尼苏达州大学队很被看好(种子编号越低,越被 NCAA 选拔委员会看好)。阵列的平均值有点让人摸不着头脑:31 个网络共同预测出中田纳西州州立大学队赢、输或平局的概率分别为 37.14%、17.14% 和 45.71%。
我完全不确定该怎么做。难道是科学欺骗了我吗?面对现实吧,体育赛事本就毫无规律(这也解释了“疯狂三月”中的“疯狂”二字)。因此,这样比分接近的比赛最终结果也只能靠猜。虽然阵列中多数网络无法选出明确的获胜方 (45.71%),但预测的获胜方的概率是其它两种情况的两倍(37.14% 到 17.14%)。
最终,我因为下面的两件事在对阵表预测中选择了中田纳西州州立大学队:他们刚刚在其联盟 (Central USA) 中获胜,有了锦标赛自动晋级资格,另外我的深层网络(这项工作的深入网络)一边倒地选择了中田纳西州州立大学队。因此,我选择中田纳西州州立大学队将打败明尼苏达州大学队。从最终结果看,网络是正确的。针对锦标赛中所有球队的比赛,我都执行了这一过程,填好对阵表,并希望获得最好的结果。
就像我前面所说,网络选择(也就是我的选择)的正确率约为 72%。这样的正确率还不错。而且充满乐趣。
结束语
在本教程中,我谈到了人工神经网络 (ANN) 的概念,然后讨论了多层感知器,最终带您分析了一个案例,在其中我训练了一个 MLP 网络阵列,使用该阵列选出 2017 年 NCAA 男篮甲级锦标赛的获胜队。
