

前言
上一篇中介绍了计算图以及前向传播的实现,本文中将主要介绍对于模型优化非常重要的反向传播算法以及反向传播算法中梯度计算的实现。因为在计算梯度的时候需要涉及到矩阵梯度的计算,本文针对几种常用操作的梯度计算和实现进行了较为详细的介绍。如有错误欢迎指出。
首先先简单总结一下, 实现反向传播过程主要就是完成两个任务:
- 实现不同操作输出对输入的梯度计算
- 实现根据链式法则计算损失函数对不同节点的梯度计算
再附上SimpleFlow的代码地址: github.com/PytLab/simp…
正文
反向传播
对于我们构建的模型进行优化通常需要两步:1.求损失函数针对变量的梯度;2.根据梯度信息进行参数优化(例如梯度下降). 那么该如何使用我们构建的计算图来计算损失函数对于图中其他节点的梯度呢?通过链式法则。我们还是通过上篇中的表达式
L
o
s
s
(
x
,
y
,
z
)
=
z
(
x
+
y
)" role="presentation" style="position: relative;">对应的计算图来说明:

我们把上面的操作节点使用字母进行标记,可以将每个操作看成一个函数,接受一个或两个输入有一个或者多个输出, 则上面的表达式
可以写成
L o s s ( x , y , z ) = g ( z , f ( x , y ) )" role="presentation" style="text-align: center; position: relative;">Loss(x,y,z)=g(z,f(x,y)) L o s s ( x , y , z ) = g ( z , f ( x , y ) )
那么根据链式法则我们可以得到
L
o
s
s" role="presentation" style="position: relative;">对
x" role="presentation" style="position: relative;">
的导数为:
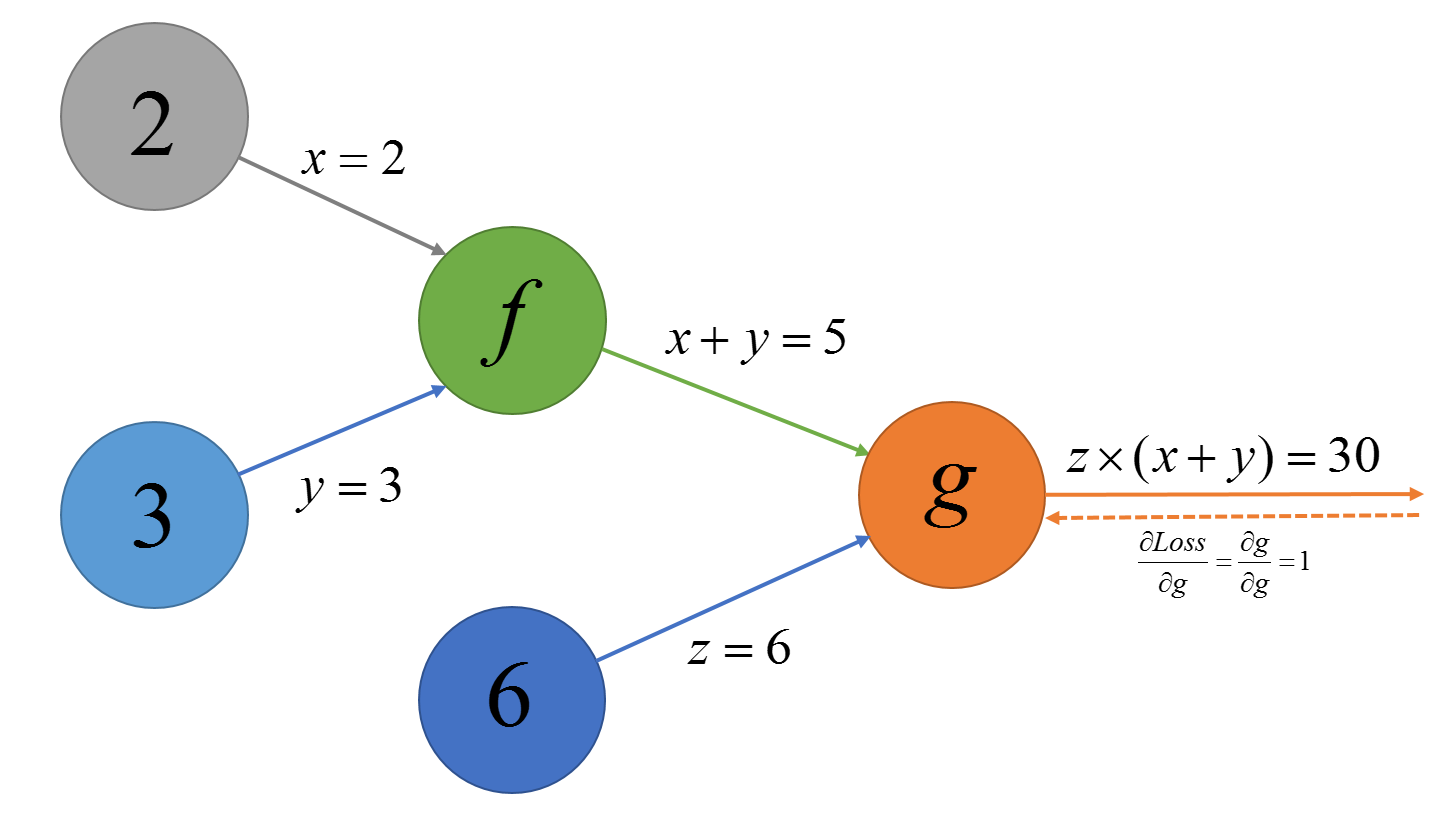
假设图中的节点已经计算出了自己的输出值,我们把节点的输出值放到节点里面如下:

然后再把链式法则的式子每一项一次计算,在图中也就是从后向前进行计算:
-
∂ L o s s ∂ g = 1" role="presentation" style="position: relative;">
-
∂ g ∂ f = z = 6" role="presentation" style="position: relative;">
(当然也可以计算出 ∂ g ∂ z = x + y = 5" role="presentation" style="position: relative;">
). 进而求出 ∂ L o s s ∂ f = ∂ L o s s ∂ g ∂ g ∂ f = 1 × z = 6" role="presentation" style="position: relative;">
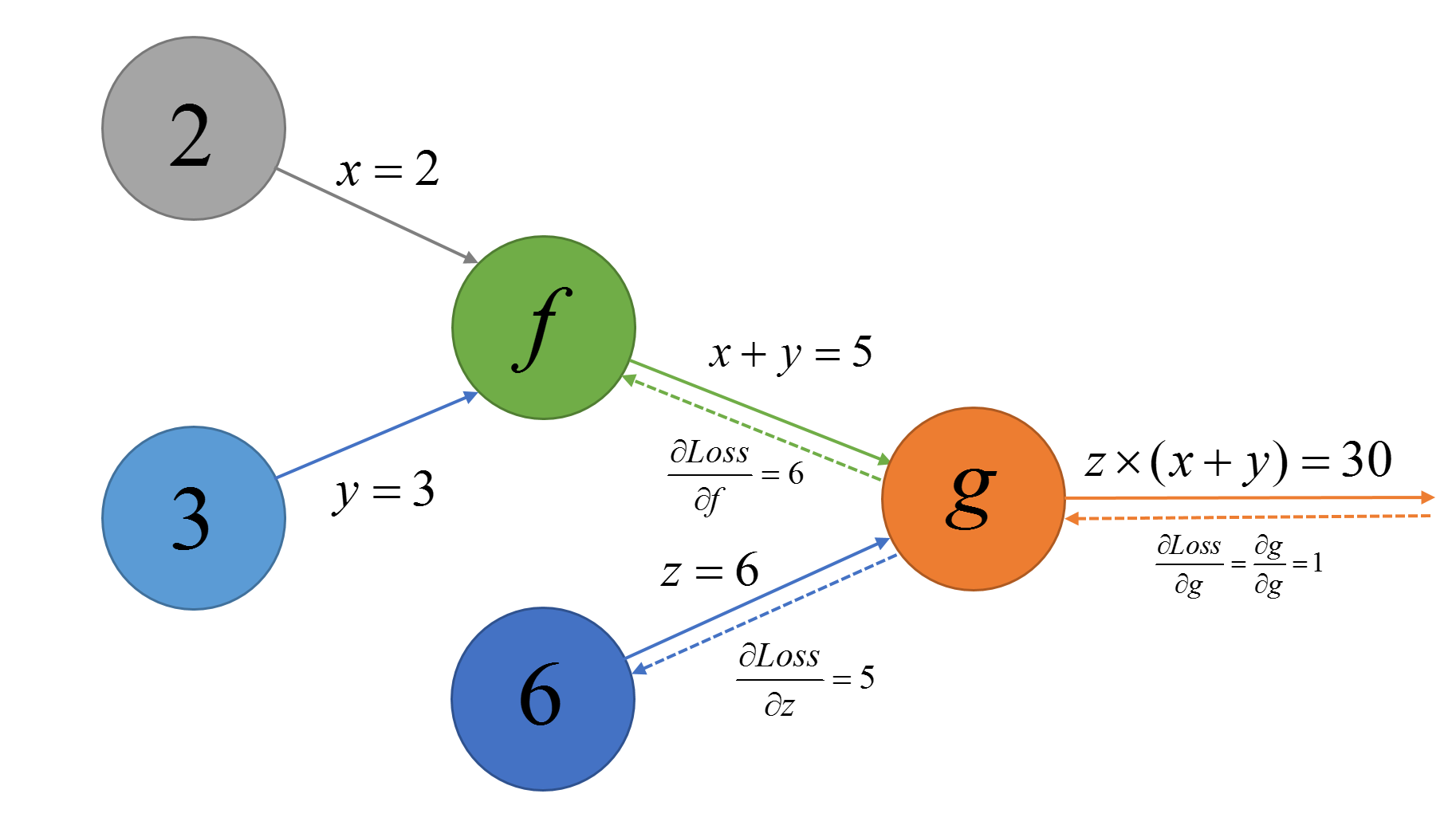
-
∂ f ∂ x = 1" role="presentation" style="position: relative;">
(同时也可以算出 ∂ f ∂ y = 1" role="presentation" style="position: relative;">
). 进而求出 ∂ L o s s ∂ x = ∂ L o s s ∂ g ∂ g ∂ f ∂ f ∂ x = 1 × z × 1 = 6" role="presentation" style="position: relative;">
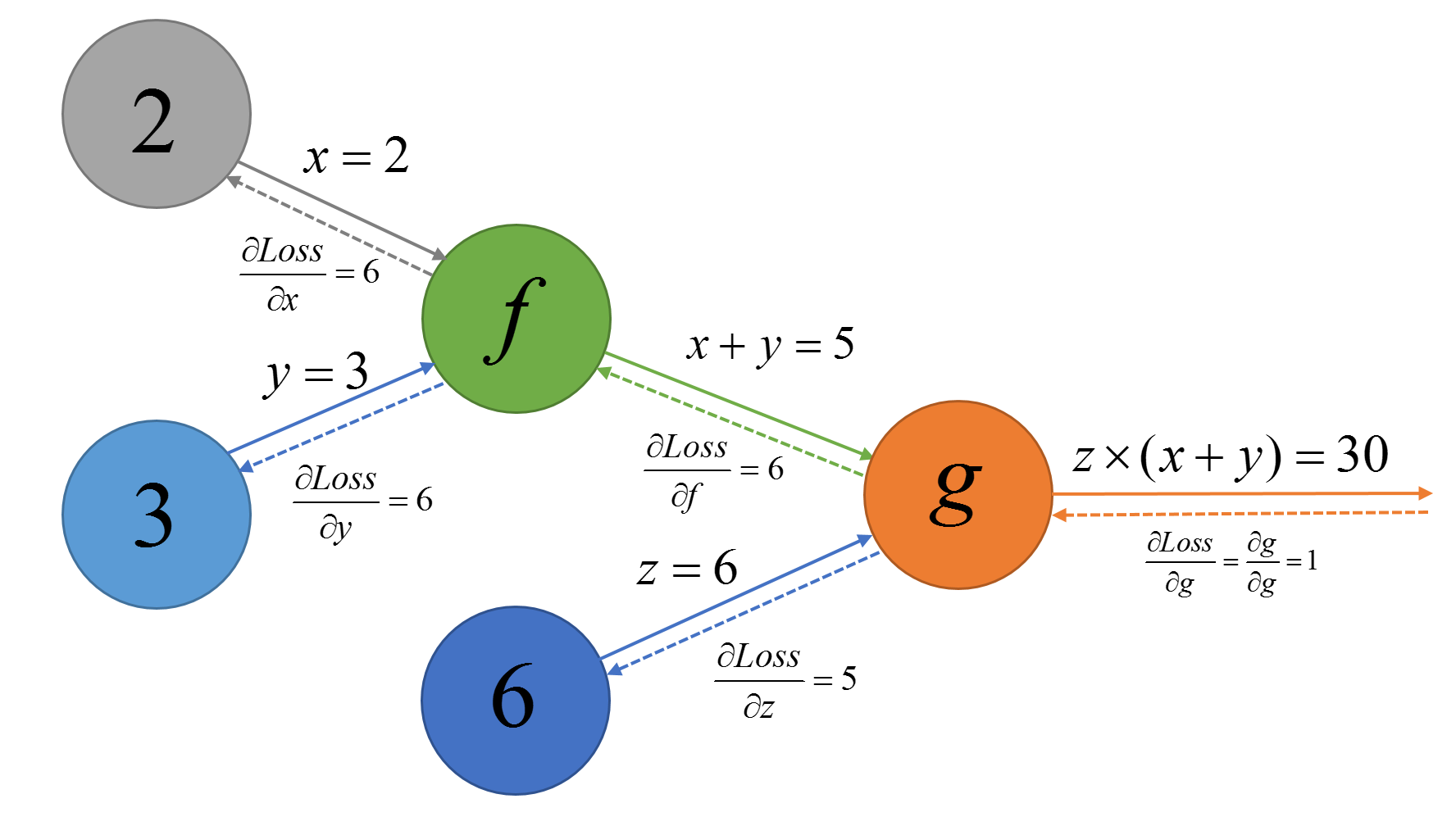



这样从后向前逐级计算通过链式法则就可以计算出与损失值对其相关节点的梯度了。因此我们下一步要做的就是给定某个损失函数节点并计算它对于某一节点的梯度计算。
下面在看一个不同的计算图:

这里的
x" role="presentation" style="position: relative;">节点有将输出到两个不同的节点中,此时我们需要计算所有从
g" role="presentation" style="position: relative;">
到
x" role="presentation" style="position: relative;">
的路径然后按照上面单挑路径的链式法则计算方法计算每条路径的梯度值,最终再将不同路径的梯度求和即可。因此
L
o
s
s" role="presentation" style="position: relative;">
对
x" role="presentation" style="position: relative;">
的梯度为:
梯度计算
通过上面对反向传播的介绍我们已经知道损失值对某个节点的梯度是怎么求的(具体的实现方法在下一部分说明),下面就是如何求取针对某个节点上的梯度了,只要每个节点上的梯度计算出来沿着路径反方向不断乘下去就会得到你想要的节点的梯度了。本部分就介绍如何求损失值对具体某个节点的梯度值。
本部分我们就是干这么一个事,首先我们先画个节点:

f" role="presentation" style="position: relative;">节点可以看成一个函数
z
=
f
(
x
,
y
)" role="presentation" style="position: relative;">
, 我们需要做的就是求
∂
f
(
x
,
y
)
∂
x
" role="presentation" style="position: relative;">
和
∂
f
(
x
,
y
)
∂
y
" role="presentation" style="position: relative;">
.
平方运算的梯度计算
我们先用一个平方运算(之所以不用求和和乘积/矩阵乘积来做例子,因为这里面涉及到矩阵求导维度的处理,会在稍后进行总结, 而平方运算并不会涉及到维度的变化比较简单):
class Square(Operation):
''' Square operation. '''
# ...
def compute_gradient(self, grad=None):
''' Compute the gradient for square operation wrt input value.
:param grad: The gradient of other operation wrt the square output.
:type grad: ndarray.
'''
input_value = self.input_nodes[0].output_value
if grad is None:
grad = np.ones_like(self.output_value)
return grad*np.multiply(2.0, input_value)其中grad为损失值对Square输出的梯度值,也就是上图中的
∂
L
o
s
s
∂
z
" role="presentation" style="position: relative;">的值, 它的
shape一定与Square的输出值的shape一致。
神经网络反向传播的矩阵梯度计算
矩阵梯度的计算是实现反向传播算法重要的一部分, 但是在实现神经网络反向传播的矩阵求导与许多公式列表上罗列出来的还是有差别的。
矩阵/向量求导
首先先看下矩阵的求导,其实矩阵的求导本质上就是目标矩阵中的元素对变量矩阵中的元素求偏导,至于求导后的导数矩阵的形状大都也都是为了形式上的美观方便求导之后的继续使用。所以不必被那些复杂的矩阵求导形式迷惑了双眼。这里上传了一份矩阵求导公式法则的列表PDF版本,可以一步一步通过(行/列)向量对标量求导再到(行/列)向量对(行/列)向量求导再到矩阵对矩阵的求导逐渐扩展。
例如标量
y" role="presentation" style="position: relative;">对矩阵
X
=
[
x
11
x
12
x
21
x
22
]
" role="presentation" style="position: relative;">
求导, 我们就对标量
y" role="presentation" style="position: relative;">
对于
X" role="presentation" style="position: relative;">
的所有元素求偏导,最终得到一个导数矩阵,矩阵形状同
X" role="presentation" style="position: relative;">
相同:
神经网络反向传播中的矩阵求导
之所以把矩阵求导分成两部分,是因为在实现矩阵求导的时候发现做反向传播的时候的矩阵求导与矩阵求导公式的形式上还是有区别的。所谓的区别就是,我们在神经网络进行矩阵求导的时候其实是Loss(损失)函数对节点中的矩阵进行求导,而损失函数是标量,那每次我们对计算图中的每个节点计算梯度的时候其实是计算的标量(损失值)对矩阵(节点输出值)的求导. 也就是说在进行反向传播的时候我们用的只是矩阵求导中的一种,即标量对矩阵的求导, 也就是上面举的例子的形式。再进一步其实就是损失函数对矩阵中每个元素进行求偏导的过程,通俗的讲就是计算图中矩阵中的每个元素对损失值的一个影响程度。因此这样计算出来的导数矩阵的形状与变量的形状一定是一致的。
直观上理解就是计算图中对向量/矩阵求导的时候计算的是矩阵中的元素对损失值影响程度的大小,其形状与矩阵形状相同。
求和操作的梯度计算
现在我们以求和操作的梯度计算为例说明反向传播过程中矩阵求导的实现方法。
对于求和操作:
C
=
A
+
b" role="presentation" style="position: relative;">, 其中
A
=
[
a
11
a
12
a
21
a
22
]
" role="presentation" style="position: relative;">
,
b
=
b
0
" role="presentation" style="position: relative;">
, 则
C
=
[
a
11
+
b
0
a
12
+
b
0
a
21
+
b
0
a
22
+
b
0
]
" role="presentation" style="position: relative;">
, 损失值
L" role="presentation" style="position: relative;">
对
C" role="presentation" style="position: relative;">
梯度矩阵为
G
=
[
∂
L
∂
c
11
∂
L
∂
c
12
∂
L
∂
c
21
∂
L
∂
c
22
]
" role="presentation" style="position: relative;">
下面我们计算
∂
L
∂
b
" role="presentation" style="position: relative;">, 根据我们之前说的这个梯度的维度(形状)应该与
b" role="presentation" style="position: relative;">
相同,也就是一个标量,那么具体要怎么计算呢?我们分成两部分来处理:
-
先计算对于 C = A + B" role="presentation" style="position: relative;">
∂ L ∂ B = [ ∂ L c 11 ∂ c 11 ∂ b 0 ∂ L c 12 ∂ c 12 ∂ b 0 ∂ L c 21 ∂ c 21 ∂ b 0 ∂ L c 22 ∂ c 22 ∂ b 0 ] = [ ∂ L c 11 × 1 ∂ L c 12 × 1 ∂ L c 21 × 1 ∂ L c 22 × 1 ] = ∂ L ∂ C = G" role="presentation" style="text-align: center; position: relative;">∂L∂B=⎡⎣∂Lc11∂c11∂b0∂Lc21∂c21∂b0∂Lc12∂c12∂b0∂Lc22∂c22∂b0⎤⎦=[∂Lc11×1∂Lc21×1∂Lc12×1∂Lc22×1]=∂L∂C=G ∂ L ∂ B = [ ∂ L c 11 ∂ c 11 ∂ b 0 ∂ L c 12 ∂ c 12 ∂ b 0 ∂ L c 21 ∂ c 21 ∂ b 0 ∂ L c 22 ∂ c 22 ∂ b 0 ] = [ ∂ L c 11 × 1 ∂ L c 12 × 1 ∂ L c 21 × 1 ∂ L c 22 × 1 ] = ∂ L ∂ C = G, ∂ L ∂ B " role="presentation" style="position: relative;">
的梯度值,其中 B = [ b 0 b 0 b 0 b 0 ] " role="presentation" style="position: relative;">
是通过对 b" role="presentation" style="position: relative;">
进行广播操作得到的
-
计算 L" role="presentation" style="position: relative;">
对 b" role="presentation" style="position: relative;">
。因为 B" role="presentation" style="position: relative;">
是对 b" role="presentation" style="position: relative;">
则梯度的值为:
∂ L ∂ b = ∑ i = 1 2 ∑ j = 1 2 ∂ L ∂ c i j " role="presentation" style="text-align: center; position: relative;">∂L∂b=∑i=12∑j=12∂L∂cij ∂ L ∂ b = ∑ i = 1 2 ∑ j = 1 2 ∂ L ∂ c i j
针对此例 b" role="presentation" style="position: relative;">
∂ L ∂ b = [ 1 1 ] G [ 1 1 ] " role="presentation" style="text-align: center; position: relative;">∂L∂b=[11]G[11] ∂ L ∂ b = [ 1 1 ] G [ 1 1 ]若 b" role="presentation" style="position: relative;">
∂ L ∂ b = [ ∂ L ∂ c 11 + ∂ L ∂ c 12 ∂ L ∂ c 21 + ∂ L ∂ c 22 ] " role="presentation" style="text-align: center; position: relative;">∂L∂b=[∂L∂c11+∂L∂c12∂L∂c21+∂L∂c22] ∂ L ∂ b = [ ∂ L ∂ c 11 + ∂ L ∂ c 12 ∂ L ∂ c 21 + ∂ L ∂ c 22 ]则需要将 G" role="presentation" style="position: relative;">
中的每一列进行相加得到与 b" role="presentation" style="position: relative;">
下面是求和操作梯度计算的Python实现:
class Add(object):
# ...
def compute_gradient(self, grad=None):
''' Compute the gradients for this operation wrt input values.
:param grad: The gradient of other operation wrt the addition output.
:type grad: number or a ndarray, default value is 1.0.
'''
x, y = [node.output_value for node in self.input_nodes]
if grad is None:
grad = np.ones_like(self.output_value)
grad_wrt_x = grad
while np.ndim(grad_wrt_x) > len(np.shape(x)):
grad_wrt_x = np.sum(grad_wrt_x, axis=0)
for axis, size in enumerate(np.shape(x)):
if size == 1:
grad_wrt_x = np.sum(grad_wrt_x, axis=axis, keepdims=True)
grad_wrt_y = grad
while np.ndim(grad_wrt_y) > len(np.shape(y)):
grad_wrt_y = np.sum(grad_wrt_y, axis=0)
for axis, size in enumerate(np.shape(y)):
if size == 1:
grad_wrt_y = np.sum(grad_wrt_y, axis=axis, keepdims=True)
return [grad_wrt_x, grad_wrt_y]其中grad参数就是上面公式中的
G" role="presentation" style="position: relative;">它的shape应该与该节点的输出值(
output_value的形状一直)。
矩阵乘梯度的计算
这部分主要介绍如何在反向传播求梯度中运用维度分析来帮助我们快速获取梯度。先上一个矩阵乘操作的例子:
C = A B" role="presentation" style="text-align: center; position: relative;">C=AB C = A B其中,
C" role="presentation" style="position: relative;">是
M
×
K" role="presentation" style="position: relative;">
的矩阵,
A" role="presentation" style="position: relative;">
是
M
×
N" role="presentation" style="position: relative;">
的矩阵,
B" role="presentation" style="position: relative;">
是
N
×
K" role="presentation" style="position: relative;">
的矩阵。
损失值
L" role="presentation" style="position: relative;">对
C" role="presentation" style="position: relative;">
的梯度为
其形状与矩阵
C" role="presentation" style="position: relative;">相同同为
M
×
K" role="presentation" style="position: relative;">
通过维度分析可以通过我们标量求导的知识再稍微对矩阵的形状进行处理(左乘,右乘,转置)来凑出正确的梯度。当然如果需要分析每个元素的导数也是可以的,可以参考这篇神经网络中利用矩阵进行反向传播运算的实质, 下面我们主要使用维度分析来快速计算反向传播中矩阵乘节点中矩阵对矩阵的导数。
若我们想求
∂
L
∂
B
" role="presentation" style="position: relative;">, 根据标量计算的链式法则应该有:
根据向量已知的
∂
L
∂
C
" role="presentation" style="position: relative;">的形状为
M
×
K" role="presentation" style="position: relative;">
(与
C" role="presentation" style="position: relative;">
形状相同),
∂
L
∂
B
" role="presentation" style="position: relative;">
的形状为
N
×
K" role="presentation" style="position: relative;">
(与
B" role="presentation" style="position: relative;">
形状相同), 因此
∂
C
∂
B
" role="presentation" style="position: relative;">
应该是一个
N
×
M" role="presentation" style="position: relative;">
的矩阵,而且我们上面乘积的式子写反了,把顺序调换一下就是
根据我们在标量求导的规则里,
C" role="presentation" style="position: relative;">对于
B" role="presentation" style="position: relative;">
求导应该是
A" role="presentation" style="position: relative;">
, 但是
A" role="presentation" style="position: relative;">
是一个
M
×
N" role="presentation" style="position: relative;">
的矩阵而我们现在需要一个
N
×
M" role="presentation" style="position: relative;">
的矩阵,那么就将
A" role="presentation" style="position: relative;">
转置一下呗,于是就得到:
同理也可以通过维度分析得到
L" role="presentation" style="position: relative;">对
A" role="presentation" style="position: relative;">
的梯度为
G
B
T
" role="presentation" style="position: relative;">
下面是矩阵乘操作梯度计算的Python实现:
class MatMul(Operation):
# ...
def compute_gradient(self, grad=None):
''' Compute and return the gradient for matrix multiplication.
:param grad: The gradient of other operation wrt the matmul output.
:type grad: number or a ndarray, default value is 1.0.
'''
# Get input values.
x, y = [node.output_value for node in self.input_nodes]
# Default gradient wrt the matmul output.
if grad is None:
grad = np.ones_like(self.output_value)
# Gradients wrt inputs.
dfdx = np.dot(grad, np.transpose(y))
dfdy = np.dot(np.transpose(x), grad)
return [dfdx, dfdy]其他操作的梯度计算
这里就不一一介绍了其他操作的梯度计算了,类似的我们根据维度分析以及理解反向传播里矩阵梯度其实就是标量求梯度放到了矩阵的规则里的一种变形的本质,其他梯度也可以推导并实现出来了。
在simpleflow里目前实现了求和,乘法,矩阵乘法,平方,Sigmoid,Reduce Sum以及Log等操作的梯度实现,可以参考:github.com/PytLab/simp…
总结
本文介绍了通过计算图的反向传播快速计算梯度的原理以及每个节点相应梯度的计算和实现,有了每个节点的梯度计算我们就可以通过实现反向传播算法来实现损失函数对所有节点的梯度计算了,下一篇中将会总结通过广度优先搜索实现图中节点梯度的计算以及梯度下降优化器的实现。
