

作为整体 Google AI 工作的一部分,Google Brain 团队希望通过研究和系统工程推动人工智能向前发展。去年,我们分享了团队在 2016 年的工作总结。自那以后,我们在实现让机器拥有智慧的长期研究愿景的道路上不断取得进展,并与 Google 和 Alphabet 内的多个团队协作,利用我们的研究成果来改善人们的生活。第一部分将重点回顾我们在 2017 年的工作,其中包含一些基础研究工作以及机器学习开放源代码软件、数据集和新硬件的相关动态。在第二篇博文中,我们将深入讨论团队在机器学习可以大展拳脚的具体领域(例如医疗保健、机器人和某些基础科学领域)进行的研究,还会介绍我们在创造性、公平性和包容性方面的工作,并详细介绍一下我们的文化。
核心研究
我们团队的一个重点是从事机器学习研究工作,旨在加深我们对这个领域的理解和提高解决新问题的能力。下面是我们去年的几个研究主题。
AutoML
自动化机器学习的目标是开发新技术,让计算机可以自动解决新的机器学习问题,无需人类机器学习专家干预每一个新问题。如果我们想要创造真正智能的系统,这一定是我们需要的一项基本能力。我们使用强化学习和进化算法开发了新方式来设计神经网络架构,并通过这项工作在 ImageNet 分类和检测中取得了目前最好的结果,还介绍了如何自动学习新的优化算法和有效激活函数。我们与 Cloud AI 团队积极合作,让更多的 Google 客户享受到这项技术带来的优势,以及持续推动在许多方向的研究。
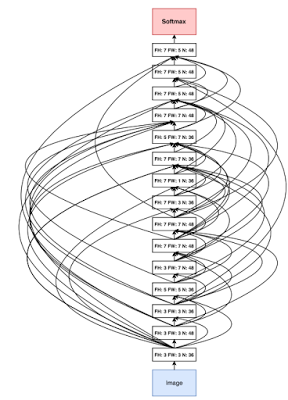 |
| 通过神经架构搜索发现的卷积架构 |
 |
| 使用通过 AutoML 发现的网络进行对象检测 |
另一个主题是开发新技术来提高我们的计算系统理解和生成人类语音的能力,其中包括与 Google 内的语音团队合作,为端到端语音识别方式开发大量改进,与 Google 的生产语音识别系统相比,这些改进将相对单词错误率降低了 16%。这项工作一个有趣的方面是,它需要汇聚多个不同的研究思路(您可以在 Arxiv 上找到相关思路的论文:1、2、3、4、5、 6、7、8、9)。
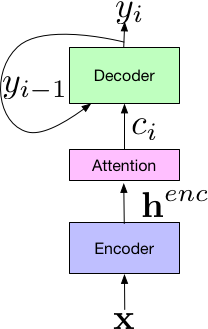 |
| 面向语音识别的 Listen-Attend-Spell 端到端模型的组成部分 |
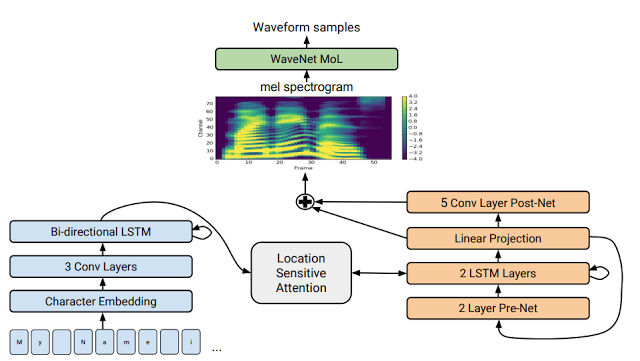 |
| Tacotron 2 的模型架构 |
我们继续开发新的机器学习算法和方式,这方面的工作包括胶囊(可以在激活特征中明确查找一致性,因而在执行视觉任务时,可用于评估多种不同的噪声假设)、稀疏门控专家混合层(可以实现超大但仍具有较高计算效率的模型)、超级网络(使用一个模型的权重为其他模型生成权重)、 新型多模式模型(在同一个模型中执行与音频、视觉和文本输入有关的多任务学习)、基于注意力的机制(可以替代卷积和递归模型)、符号式和 非符号式学习优化方法、 通过离散变量进行反向传播的技术,以及多项新的强化学习算法改进。
面向计算机系统的机器学习
使用机器学习替代计算机系统中的传统启发方法也深深吸引着我们。我们已经介绍了如何使用强化学习来作出比人类专家更好的放置决策,将计算图映射到一组计算设备。在 Google 研究团队其他同事的帮助下,我们在“The Case for Learned Index Structures”中证明,神经网络可以比 B 树、哈希表和布隆过滤器等传统数据结构更快和小得多。正如在 Machine Learning for Systems and Systems for Machine Learning 这个 NIPS 专题讲座中谈到的一样,我们认为,目前我们还只是刚刚拉开机器学习在计算机系统中应用的序幕。
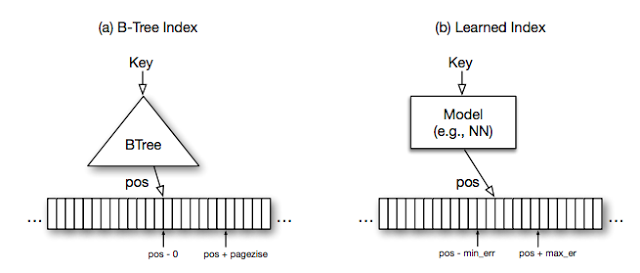 |
| 索引结构形式的学习模型 |
机器学习及其与安全和隐私的交互将继续作为我们的一个主要研究重点。我们在一篇论文中介绍到,能够以一种提供差异化隐私保证的方式应用机器学习技术,这篇论文在 ICLR 2017 上获得了其中一项最佳论文奖。我们还将继续研究对抗样本的属性,包括 展示物质世界中的对抗样本和如何在训练过程中大规模利用对抗样本,从而提升模型处理对抗样本的稳健性。
理解机器学习系统
尽管我们在深度学习方面取得了骄人的成绩,理解它的工作原理和局限性仍然非常重要。在另一篇获得 ICLR 2017 一项最佳论文奖的论文中,我们论证了当前的机器学习理论框架无法解释深度学习方式带来的显著成果。我们还证明了优化方法发现的“平滑性”并不像最初想象的一样与良好泛化紧密相关。为了更好地理解深度架构下的训练机制,我们发表了一系列分析 随机矩阵(它们是大多数训练方式的出发点)的论文。另一个理解深度学习的重要途径是更好地衡量它们的表现。在最近的一项研究中,我们介绍了良好的实验设计和统计严谨性的重要性,在对许多 GAN 进行比较之后,我们发现许多受到追捧的生成式模型增强实际上并没有提高性能。我们希望这项研究可以为其他研究员提供一个范例,努力提升实验研究的稳健性。
我们正在开发可以更好地解释机器学习系统的方法。去年 3 月,我们与 OpenAI、DeepMind 和 YC Research 等研究机构联合 启动 Distill,这是一本致力于促进人类对机器学习理解的全新开放性在线科学期刊。它因为机器学习概念的清晰阐释和文章中提供的出色交互式可视化工具获得了广泛好评。在创刊元年,Distill 发布了许多旨在了解各种机器学习技术内部工作的启发性 文章,我们期待 2018 年能够发布更多优秀文章。
 |
| 特征可视化 |
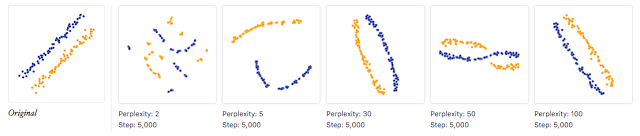 |
| 如何有效使用 t-SNE |
MNIST、CIFAR-10、ImageNet、SVHN 和 WMT 等开放数据集极大地推动了机器学习领域的发展。作为一个整体,过去一年我们团队和 Google 研究团队一直在通过提供更多大型标记数据集的方式,积极地为开放机器学习研究提供有趣的开源新数据集,其中包括:
- YouTube-8M:使用 4,716 个不同类别标记超过 700 万个 YouTube 视频
- YouTube-Bounding Boxes:500 万个边界框,涉及 210,000 个 YouTube 视频
- Speech Commands Dataset:简短命令语,涉及数千个人
- AudioSet:使用 527 个不同的声音事件标记 200 万个时长为 10 秒的 YouTube 剪辑
- 原子视觉动作 (AVA):21 万个动作标签,涉及 57,000 个视频剪辑
- Open Images:使用 6000 个类别标记 900 万个创意共享许可图像
- 带边界框的 Open Images:120 万个边界框,适合 600 个类别
 |
| YouTube-Bounding Boxes 数据集中的示例:以每秒 1 帧的速度采样的视频片段,在目标项目周围成功标识边界框 |
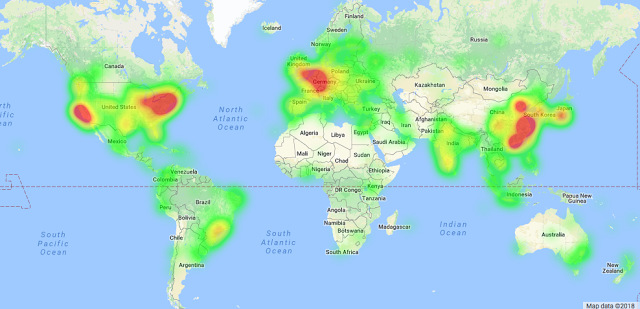 |
| TensorFlow 用户全球分布图(来源) |
同样是在 2 月,我们举办了首届 TensorFlow 开发者峰会,450 多人参加了在山景城举办的活动,全球超过 6,500 人观看了活动的现场直播,其中在 35 个国家/地区组织了超过 85 场本地观看活动。所有演讲都已录成视频,主题涵盖新特性、使用 TensorFlow 的技巧以及低级别 TensorFlow 抽象的详细介绍。我们将于 2018 年 3 月 30 日在湾区举办第二届 TensorFlow 开发者峰会。立即注册,保存活动日期并关注最新消息。
| 这个石头剪刀布科学实验是 TensorFlow 的一种新型应用。我们对 2017 年看到 TensorFlow 得到广泛应用感到非常兴奋,这些应用包括黄瓜自动化分拣、 在航拍图像中寻找海牛、将切丁的马铃薯分类以制作更安全的婴儿食品、 识别皮肤癌、 帮助解读在新西兰鸟类保护区的鸟叫录音,以及 在坦桑尼亚为地球上最流行的根作物鉴定病株! |
TensorFlow 也从 Google 其他研究团队的相关开源工作中受益颇多,其中包括 TF-GAN(TensorFlow 中的轻量级生成式对抗模型库)、TensorFlow Lattice(一组用于处理点阵模型的估算器)和 TensorFlow Object Detection API。TensorFlow 模型代码库将继续发展壮大,添加越来越多的模型集。
除了 TensorFlow 之外,我们还发布了 deeplearn.js,这是一种开源的网页版硬件加速深度学习 API 实现(无需下载或安装任何工具,只需一个浏览器)。deeplearn.js 主页提供了大量示例,其中包括 Teachable Machine(一个使用您自己的网络摄像头就可以训练的计算机视觉模型)和 Performance RNN,这是一个基于实时神经网络的钢琴作曲和表演演示。我们将在 2018 年继续努力,以便将 TensorFlow 模型直接部署到 deeplearn.js 环境中。
TPU
 |
| Cloud TPU 可以提供高达每秒 180 万亿次浮点计算的机器学习加速 |
 |
| Cloud TPU Pod 可以提供高达每秒 1.15 万万亿次浮点计算的机器学习加速 |
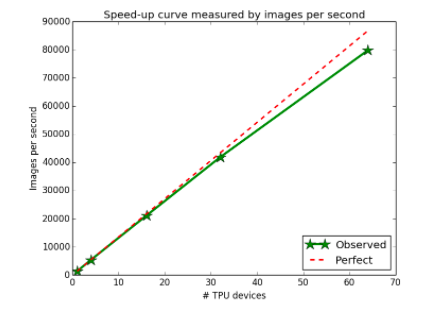 |
| 随着使用的 TPU 设备数量的增加,在 ImageNet 上进行的 ResNet-50 训练实验显示接近完美的线性加速。 |
感谢阅读!
(在第 2 部分中,我们将讨论团队在机器学习可以大显身手的领域(例如医疗保健、机器人和不同科学领域)进行的研究,还会介绍我们在创造性、公平性和包容性方面的工作。)
