


摘要
如火如荼的 kubernetes 在容器云系统领域大受关注,从今天起我们将启动 kubernetes 系列技术分享,希望能为社区提供更多的力量,这次的作者是阿里巴巴技术专家新胜,将从运行流程和list-watch看kubernetes系统的设计理念开始将起。大家有更多想要了解的技术内容可以留言给我,请踊跃的提需求吧~
1. 写在前面
kubernetes作为容器化应用集群管理系统,为容器化应用提供了便利的资源调度, 部署运行,服务发现, 扩容缩容,自动运维等贴心功能。也正因为其强大且不断丰富的功能,让kubernetes在容器云系统领域越来越受到大家关注。而做为kubernetes系统的设计开发人员,更关注kubernetes系统的设计理念层面,从而可以更好的增强和优化kubernetes。kubernentes的主要设计理念如下:
-
系统运行基于声明式(Declarative)数据而非命令式(Imperative)数据
-
组件间消息传递基于
Level Trigger而非Edge Trigger -
系统运行状态控制基于各类闭环控制器
-
系统可扩展基于各类抽象接口(CRI, CNI, CSI, scheduler, admission等)
本文通过分析kubernetes整体运行流程和list-watch机制,来说明上述的设计理念1和理念2。而理念3和理念4在后续的文章中详述。
2. kubernetes整体运行流程分析
我打算用最常用的ReplicationController(副本控制器)为依托来说明整体运行机制。
副本控制器: 望名识意,就是可以精确控制Pod的运行数量
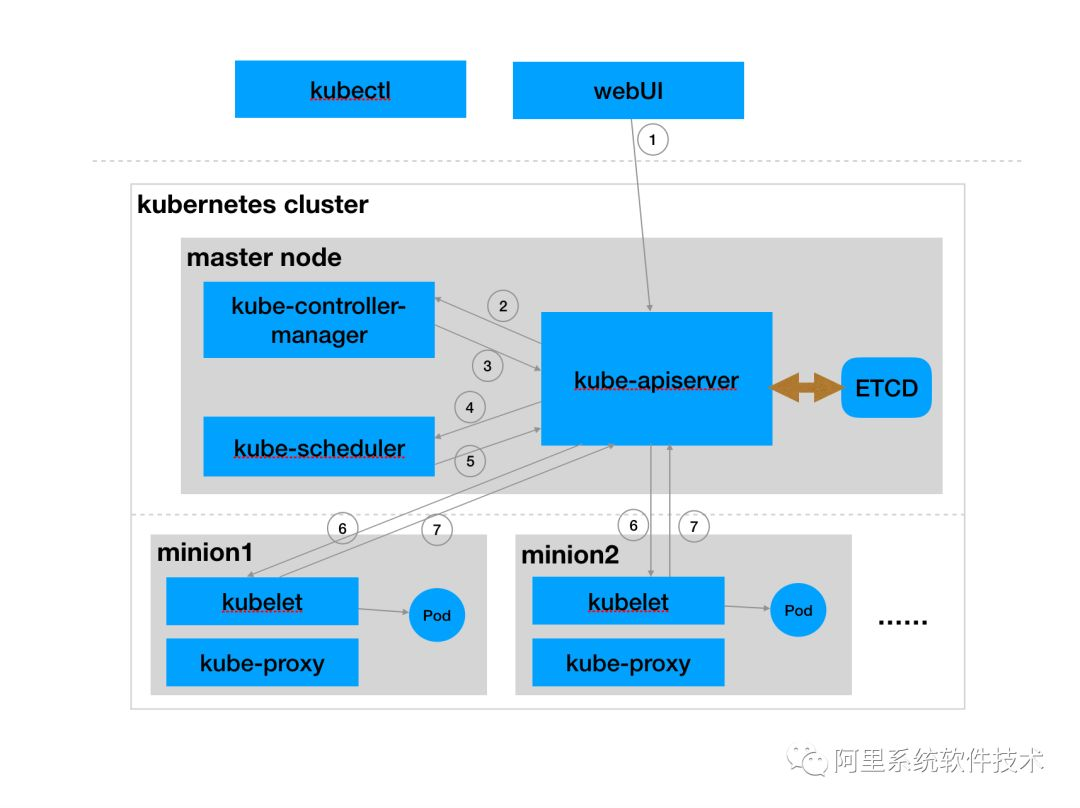
上图中流程1~7为用户创建ReplicationController副本控制器来运行Pod的整体运行流程
-
流程1(RC创建)用户通过WebUI或者kubectl工具调用
kube-apiserver提供的标准REST API接口创建一个ReplicationController。假定在ReplicationController数据结构中定义为2个Pod。用户相当执行了下面的curl命令。curl -XPOST -d "v1.ReplicationController" -H "Content-Type: application/json" http://ip:port/api/v1/namespaces/{namespace}/replicationcontrollers而此处的
v1.ReplicationController即用户的声明式数据,其中会指定应用的实例数,使用镜像等信息 -
流程2~3(Pod创建)
kube-controller-manager会通过list-watch机制获取到新建中的v1.ReplicationController数据,并驱使ReplicationController控制器工作。kube-controller-manager中各个控制器模块的工作就是让集群现状趋于用户期待。假定用户声明实例是2,而当前集群中对应的Pod数量为0,则控制器就会创建2个Pod.当然后续controller-manager也会通过list-watch机制获取到新创建的两个Pod,因为和用户期待值一致,ReplicationController的控制逻辑就收敛在用户期待状态了。
-
流程4~5(Pod调度)
kube-scheduler也会通过list-watch机制获取到新创建的v1.Pod,然后根据调度算法为Pod选择最合适的节点。假定调度结果是两个Pod选择的是minion1和minion2.即刷新v1.Pod数据的spec.nodeName字段为minion1和minion2的nodeName。 -
流程6~7(Pod运行)最后minion上的
kubelet也会通过list-watch机制获取到调度完的v1.Pod数据,然后通过container.Runtime接口创建Pod中指定的容器。并刷新ETCD中Pod的运行状态。 -
运行流程看Pod状态数据变化根据上述的介绍,在运行过程中Pod状态变化如下表示:
| 流程/Pod状态 | PodPhase | PodCondition | 组件 |
|---|---|---|---|
| 流程1 | - | - | 用户声明RC数据: 创建RC,无Pod |
| 流程2~3 | Pending | - | kube-controller-manager: RC控制器创建Pod |
| 流程4~5 | Pending | PodScheduled=true | Kube-scheduler: 调度器调度Pod成功 |
| 流程6~7 | Running | PodScheduled=true; PodInitialized=true; PodReady=true | kubelet: Work node上成功运行容器 |
3. 整体运行流程的几点思考
-
系统各个组件分工明确(APIServer是所有请求入口,CM是控制中枢,Scheduler主管调度,而Kubelet负责运行),配合流畅,整个运行机制一气呵成。
-
可以看出除了配置管理和持久化组件ETCD,其他组件并不保存数据。意味
除ETCD外其他组件都是无状态的。因此从架构设计上对kubernetes系统高可用部署提供了支撑。 -
同时因为组件无状态,组件的升级,重启,故障等并不影响集群最终状态,只要组件恢复后就可以从中断处继续运行。
-
各个组件和kube-apiserver之间的数据推送都是通过list-watch机制来实现。所以理解list-watch机制是深入理解kubernetes的关键。
-
整体运行机制基于声明式数据(如
v1.ReplicationController)而非用户输入各种命令来工作,这是kubernetes最核心的设计理念。
4. list-watch机制分析
由于kubernetes系统的采取Level Trigger而非Edge Trigger的设计理念,所以各组件只需要感知数据最新的状态,而不需要担心错过数据的变化过程。而作为kubernentes系统消息通知机制(或者说数据实时通知机制),我想应该满足下面几点要求:
-
需求1: 实时性(即数据变化时,相关组件越快感知越好)
-
需求2: 保证消息的顺序性(即消息要按发生先后顺序送达目的组件。很难想象在Pod创建消息前收到该Pod删除消息时组件应该怎么处理)
-
需求3: 保证消息不丢失或者有可靠的重新获取机制(比如说kubelet和kube-apiserver间网络闪断,需要保证网络恢复后kubelet可以收到网络闪断期间产生的消息)
4.1 需求1的解决方案
kubernetes组件间主要通过http/2协议(kubernetes1.5之前采用http1.1,另Go1.7之后开始支持http/2)进行数据交互,满足实时性主要下面2种方案。
-
方案1: http long polling客户端发起http request,服务端有请求数据时就回复一个response(如没有数据服务端就等到有数据再回复),客户端收到response后马上又发起新的request,如此往复。具体流程如下图所示:
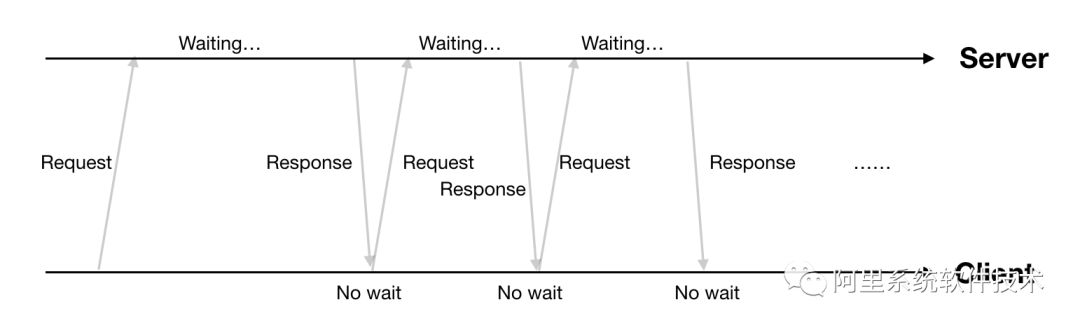
方案缺点: 通信消耗大一些(每个response多一个request)
-
方案2: http streaming客户端发起http request,服务端有请求数据就回复一个response(回复的http header中会带上”Transfer-Encoding”:”chunked”)。客户端收到这种header的response后就会继续等待后续数据,而服务端有新的数据时会继续通过这条连接发数据。具体流程如下图所示:
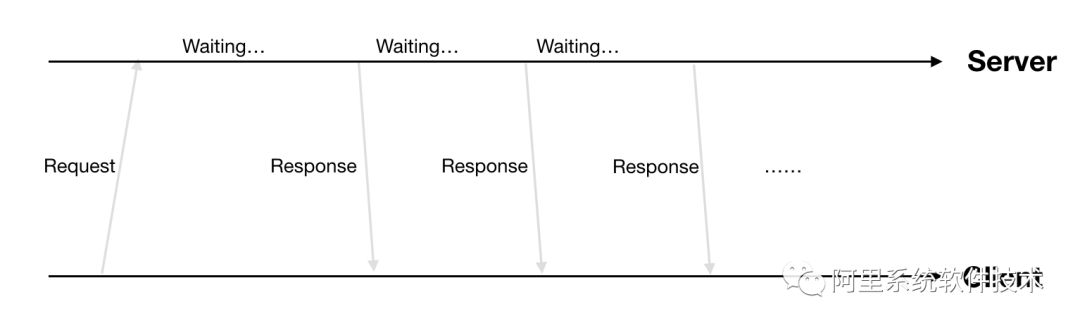
方案2缺点: 需要对返回数据做定制
上面两种方案都有自己的优缺点,在kubernetes中选择了方案2,且在kubernetes中的http streaming请求我们称为watch请求(其实就是一个http get请求)
注: ETCD2中watch功能选用的是方案1
4.2 需求2的解决方案
kubernetes中为每一个REST数据加了一个ResourceVersion字段,并且该字段的值由ETCD来保证全局单调递增(当ETCD中写入一个数据时,全局ResourceVersion就加1)。这样就保证了不同时刻的数据ResourceVersion不同,并且后产生数据的ResourceVersion较之前数据的ResourceVersion大。这样客户端发起watch请求时,只需要带上请求数据在本地缓存中的最新ResourceVersion,而服务端就根据ResourceVersion从小到大把
大于客户端ResourceVersion的数据按顺序推送给客户端即可。这样就保证了推送数据的顺序性。
// ResourceVersion字段就在REST资源结构体的ObjectMeta中。具体如下:
type ObjectMeta struct {
Name string
GenerateName string
Namespace string
SelfLink string
UID types.UID
ResourceVersion string <-- 保证顺序就靠它了。
Generation int64
CreationTimestamp Time
DeletionTimestamp *Time
DeletionGracePeriodSeconds *int64
Labels map[string]string
Annotations map[string]string
OwnerReferences []OwnerReference
Initializers *Initializers
Finalizers []string
ClusterName string
}具体如下图所示:
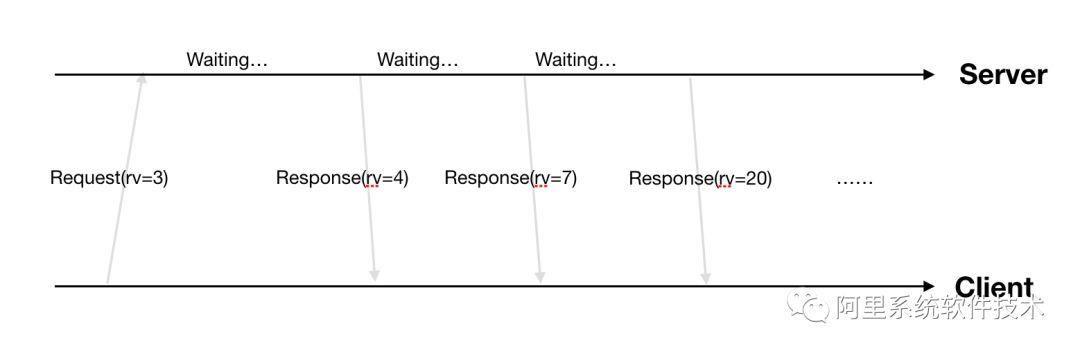
因为ETCD保证全局单调+1,所以某类数据的RV可能不会逐步+1变化
4.3 需求3的解决方案
基于需求1和需求2的解决方案,需求3主要是对异常状况处理的完善。kubernetes中结合watch请求增加了list请求,主要做如下两件事情:
-
watch请求开始之前,先发起一次list请求,获取集群中当前所有该类数据(同时得到最新的ResourceVersion),之后基于最新的ResourceVersion发起watch请求。
-
当watch出错时(比如说网络闪断造成客户端和服务端数据不同步),重新发起一次list请求获取所有数据,再重新基于最新ResourceVersion来watch。
kubernetes中的list-watch流程如下:
具体代码参见: kubernetes/vendor/k8s.io/client-go/tools/cache/reflector.go#ListAndWatch()
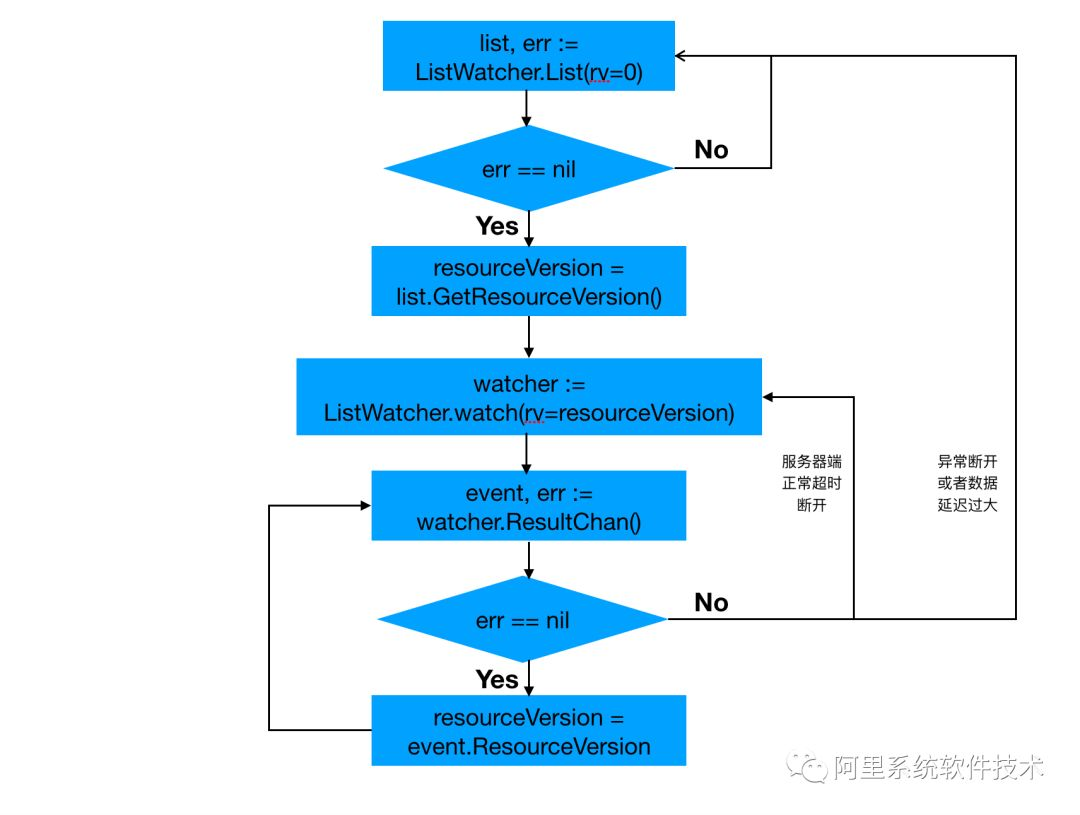
watch处理中的ResourceVersion更新是在watchHandler()中实现的。
综合上面的方案分析,我们可以综合总结一下解决方案: kubernetes中基于ResourceVersion信息采用list-watch(http streaming)机制来保证组件间的数据实时可靠传送。从今往后,我们就统称该方案为list-watch机制*
5. list-watch机制的几点思考
-
list请求是返回全量的数据,如果数据量较大时(比如20wPod),如果watch失败后需要relist,这时候的list请求成本是很高的。(服务端和客户端都需要对20w数据进行编解码,序列化和反序列化等)。kubernetes大规模应用场景下,需要尽量减少relist发生次数。
-
watch请求采用http streaming方式,http1.1时(kubernetes1.5前)因为长连接是独立的TCP连接,假如网络断了,客户端是感知不到网络断开的,而只是以为服务端一直没有数据。tcp keep-alive机制检测到网络断开后(golang默认http client的keep-alive时间是30s),会主动rst掉该连接,然后再次建立新的连接。而在http/2(大于kubernetes1.5中使用)中因为大家共用一条TCP连接,客户端不断的各种请求导致keep-alive机制无法发挥作用,最后只能由数据的重传超时来reset掉这条TCP连接,这种场景下对系统的影响可能要大一些。
-
同时kubernetes1.5之前http1.1中每个REST资源的list-watch都有一条长连接,这样对服务器压力很大。不过这个问题因为http/2的连接复用机制,在kubernetes1.5后得到了很好的解决。从这点考虑建议大家尽量使用kubernetes1.5以后的版本。
-
tcp长连接断开考虑: 因为watch请求是http streaming方式,客户端不清楚服务端是否还有数据需要发送,所以客户端一般不会主动关闭长连接。需要断开长连接时,应该考虑由服务端来断开。
-
如果客户端挂掉后,服务端同样不知道,这样在kubernets1.5之前(因为使用http1.1)服务端维护大量的无效连接,造成服务端资源的大量浪费。kubernetes的解决方案是: watch请求中带一个超时参数(TimeoutSeconds),默认为5~10min间的随机数。所以服务端只要超时时间一到就会断开连接。为什么是5~10min并没有相关介绍,我的考虑是服务端断开连接,time_wait将砸在服务端的手里。而time_wait的有效时间为1min~4min,所以5~10min是一个比较好的选择,可以保证服务端的time_wait保持在一个比较稳定的数量。
-
正因为kubernetes采用了基于
level trigger而非edge trigger的设计理念,因此在kubernetes中没有像其他的分布式系统中额外引入MQ,降低了系统的整体复杂度(如openstack中的rabbitmq, cloudFoundary中的nuts等)。而只是简单通过http/2 + protobuffer的方式实现了一套list-watch机制来解决各个组件间的消息通知(满足了系统需求)。
