


一、分布式系统的挑战
关于分布式系统有一个经典的CAP理论,
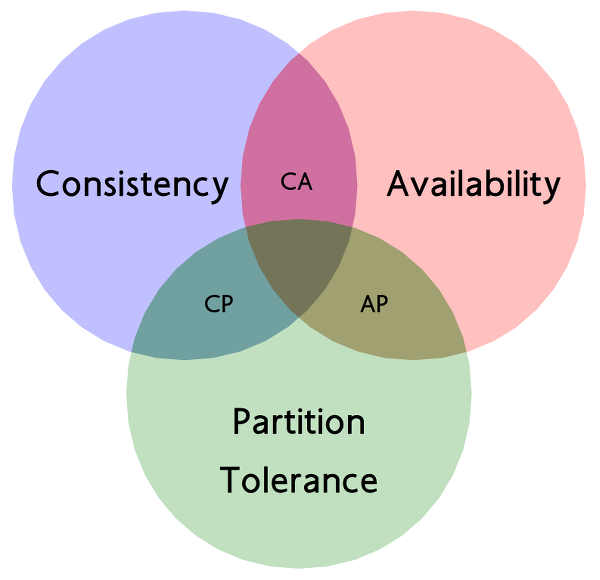
CAP理论的核心思想是任何基于网络的数据共享系统最多只能满足数据一致性(Consistency)、可用性(Availability)和网络分区容忍(Partition Tolerance)三个特性中的两个。
- Consistency 一致性
一致性指“all nodes see the same data at the same time”,即更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致。等同于所有节点拥有数据的最新版本。
- Availability 可用性
可用性指“Reads and writes always succeed”,即服务一直可用,而且是正常响应时间。
对于一个可用性的分布式系统,每一个非故障的节点必须对每一个请求作出响应。也就是,该系统使用的任何算法必须最终终止。当同时要求分区容忍性时,这是一个很强的定义:即使是严重的网络错误,每个请求必须终止。
- Partition Tolerance 分区容忍性
Tolerance也可以翻译为容错,分区容忍性具体指“the system continues to operate despite arbitrary message loss or failure of part of the system”,即系统容忍网络出现分区,分区之间网络不可达的情况,分区容忍性和扩展性紧密相关,Partition Tolerance特指在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
提高分区容忍性的办法就是一个数据项复制到多个节点上,那么出现分区之后,这一数据项就可能分布到各个区里。分区容忍就提高了。然而,要把数据复制到多个节点,就会带来一致性的问题,就是多个节点上面的数据可能是不一致的。要保证一致,每次写操作就都要等待全部节点写成功,而这等待又会带来可用性的问题。
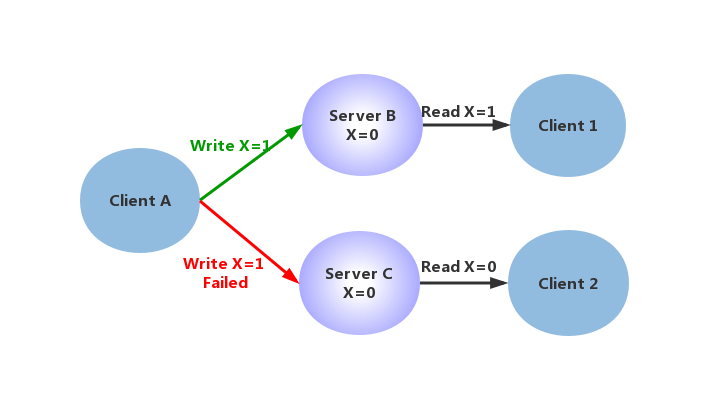
如图,Client A可以发送指令到Server并且设置更新X的值,Client 1从Server读取该值,在单点情况下,即没有网络分区的情况下,或者通过简单的事务机制,可以保证Client 1读到的始终是最新的值,不存在一致性的问题。
如果在系统中增加一组节点,Write操作可能在Server 1上成功,在Server 1上失败,这时候对于Client 1和Client 2,就会读取到不一致的值,出现不一致。如果要保持x值的一致性,Write操作必须同时失败,降低系统的可用性。
可以看到,在分布式系统中,同时满足CAP定律中“一致性”、“可用性”和“分区容错性”三者是不可能的。
在通常的分布式系统中,为了保证数据的高可用,通常会将数据保留多个副本(replica),网络分区是既成的现实,于是只能在可用性和一致性两者间做出选择。CAP理论关注的是绝对情况下,在工程上,可用性和一致性并不是完全对立,我们关注的往往是如何在保持相对一致性的前提下,提高系统的可用性。
二、数据一致性模型
在互联网领域的绝大多数的场景,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证“最终一致性”,只要这个最终时间是在用户可以接受的范围内即可。
对于一致性,可以分为从服务端和客户端两个不同的视角,即内部一致性和外部一致性。
没有全局时钟,绝对的内部一致性是没有意义的,一般来说,我们讨论的一致性都是外部一致性。外部一致性主要指的是多并发访问时更新过的数据如何获取的问题。
强一致性:
当更新操作完成之后,任何多个后续进程或者线程的访问都会返回最新的更新过的值。这种是对用户最友好的,就是用户上一次写什么,下一次就保证能读到什么。根据 CAP 理论,这种实现需要牺牲可用性。
弱一致性:
系统并不保证续进程或者线程的访问都会返回最新的更新过的值。用户读到某一操作对系统特定数据的更新需要一段时间,我们称这段时间为“不一致性窗口”。系统在数据写入成功之后,不承诺立即可以读到最新写入的值,也不会具体的承诺多久之后可以读到。
最终一致性:
是弱一致性的一种特例。系统保证在没有后续更新的前提下,系统最终返回上一次更新操作的值。在没有故障发生的前提下,不一致窗口的时间主要受通信延迟,系统负载和复制副本的个数影响。
最终一致性模型根据其提供的不同保证可以划分为更多的模型,包括因果一致性和读自写一致性等。
三、两阶段和三阶段提交
在分布式系统中,各个节点之间在物理上相互独立,通过网络进行沟通和协调。典型的比如关系型数据库,由于存在事务机制,可以保证每个独立节点上的数据操作可以满足ACID。但是,相互独立的节点之间无法准确的知道其他节点中的事务执行情况,所以两台机器理论上无法达到一致的状态。
如果想让分布式部署的多台机器中的数据保持一致性,那么就要保证在所有节点的数据写操作,要不全部都执行,要么全部的都不执行。但是,一台机器在执行本地事务的时候无法知道其他机器中的本地事务的执行结果。所以节点并不知道本次事务到底应该commit还是roolback。
所以实现分布式事务,需要让当前节点知道其他节点的任务执行状态。常规的解决办法就是引入一个“协调者”的组件来统一调度所有分布式节点的执行。著名的是二阶段提交协议(Two Phase Commitment Protocol)和三阶段提交协议(Three Phase Commitment Protocol)。
1、二阶段提交协议
Two Phase指的是Commit-request阶段和Commit阶段。
- 请求阶段
在请求阶段,协调者将通知事务参与者准备提交或取消事务,然后进入表决过程。在表决过程中,参与者将告知协调者自己的决策:同意(事务参与者本地作业执行成功)或取消(本地作业执行故障)。
- 提交阶段
在该阶段,协调者将基于第一个阶段的投票结果进行决策:提交或取消。当且仅当所有的参与者同意提交事务协调者才通知所有的参与者提交事务,否则协调者将通知所有的参与者取消事务。参与者在接收到协调者发来的消息后将执行响应的操作。
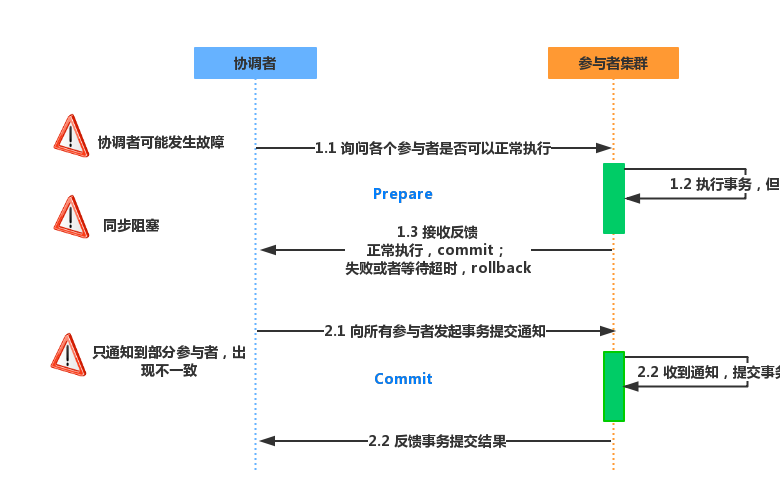
可以看出,两阶段提交协议存在明显的问题:
- 同步阻塞
执行过程中,所有参与节点都是事务独占状态,当参与者占有公共资源时,第三方节点访问公共资源被阻塞。
- 单点问题
一旦协调者发生故障,参与者会一直阻塞下去。
- 数据不一致性
在第二阶段中,假设协调者发出了事务commit的通知,但是因为网络问题该通知仅被一部分参与者所收到并执行commit,其余的参与者没有收到通知一直处于阻塞状态,这段时间就产生了数据的不一致性。
2、三阶段提交协议
Three Phase分别为CanCommit、PreCommit、DoCommit。
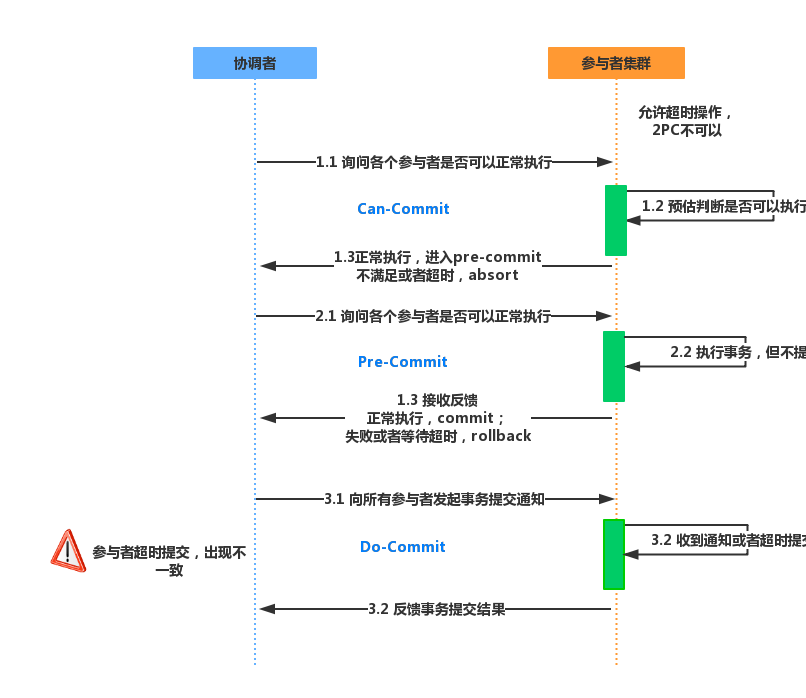
三阶段提交针对两阶段提交做了改进:
- 引入超时机制。在
2PC中,只有协调者拥有超时机制,3PC同时在协调者和参与者中都引入超时机制。 - 在第一阶段和第二阶段中插入一个准备阶段。保证了在最后提交阶段之前各参与节点的状态是一致的。
四、Paxos算法的提出
二阶段提交还是三阶段提交都无法很好的解决分布式的一致性问题,直到Paxos算法的提出,Paxos协议由Leslie Lamport最早在1990年提出,目前已经成为应用最广的分布式一致性算法。Google Chubby的作者Mike Burrows说过这个世界上只有一种一致性算法,那就是Paxos,其它的算法都是残次品。
1、节点角色
Paxos 协议中,有三类节点:
- Proposer:提案者
Proposer可以有多个,Proposer 提出议案(value)。所谓 value,在工程中可以是任何操作,例如“修改某个变量的值为某个值”、“设置当前 primary 为某个节点”等等。Paxos 协议中统一将这些操作抽象为 value。不同的 Proposer 可以提出不同的甚至矛盾的
value,例如某个 Proposer 提议“将变量 X 设置为 1”,另一个 Proposer 提议“将变量 X设置为2”,但对同一轮 Paxos 过程,最多只有一个 value 被批准。
- Acceptor:批准者
Acceptor有N个,Proposer提出的value必须获得超过半数(N/2+1)的Acceptor批准后才能通过。Acceptor之间完全对等独立。
- Learner:学习者
Learner学习被批准的value。所谓学习就是通过读取各个 Proposer 对 value 的选择结果,如果某个 value 被超过半数 Proposer 通过,则 Learner 学习到了这个 value。这里类似 Quorum 议会机制,某个
value 需要获得 W=N/2 + 1 的 Acceptor 批准,Learner 需要至少读取 N/2+1 个 Accpetor,至多读取N 个Acceptor的结果后,能学习到一个通过的value。
2、约束条件
上述三类角色只是逻辑上的划分,实践中一个节点可以同时充当这三类角色。有些文章会添加一个Client角色,作为产生议题者,实际不参与选举过程。Paxos中 proposer 和acceptor是算法的核心角色,paxos描述的就是在一个由多个 proposer 和多个 acceptor 构成的系统中,如何让多个 acceptor 针对
proposer 提出的多种提案达成一致的过程,而 learner 只是“学习”最终被批准的提案。
Paxos协议流程还需要满足几个约束条件:
Acceptor必须接受它收到的第一个提案;- 如果一个提案的v值被大多数
Acceptor接受过,那后续的所有被接受的提案中也必须包含v值(v值可以理解为提案的内容,提案由一个或多个v和提案编号组成); - 如果某一轮
Paxos协议批准了某个value,则以后各轮Paxos只能批准这个value;
每轮 Paxos 协议分为准备阶段和批准阶段,在这两个阶段 Proposer 和 Acceptor 有各自的处理流程。
Proposer与Acceptor之间的交互主要有4类消息通信,如下图:
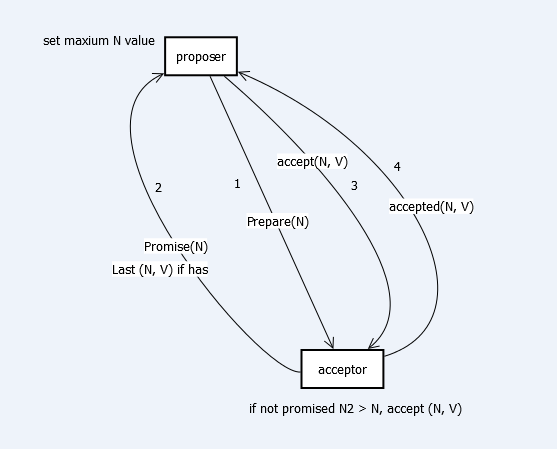
这4类消息对应于paxos算法的两个阶段4个过程:
- Phase 1
a)proposer向网络内超过半数的acceptor发送prepare消息
b)acceptor正常情况下回复promise消息 - Phase 2
a) 在有足够多acceptor回复promise消息时,proposer发送accept消息
b) 正常情况下acceptor回复accepted消息
3、选举过程
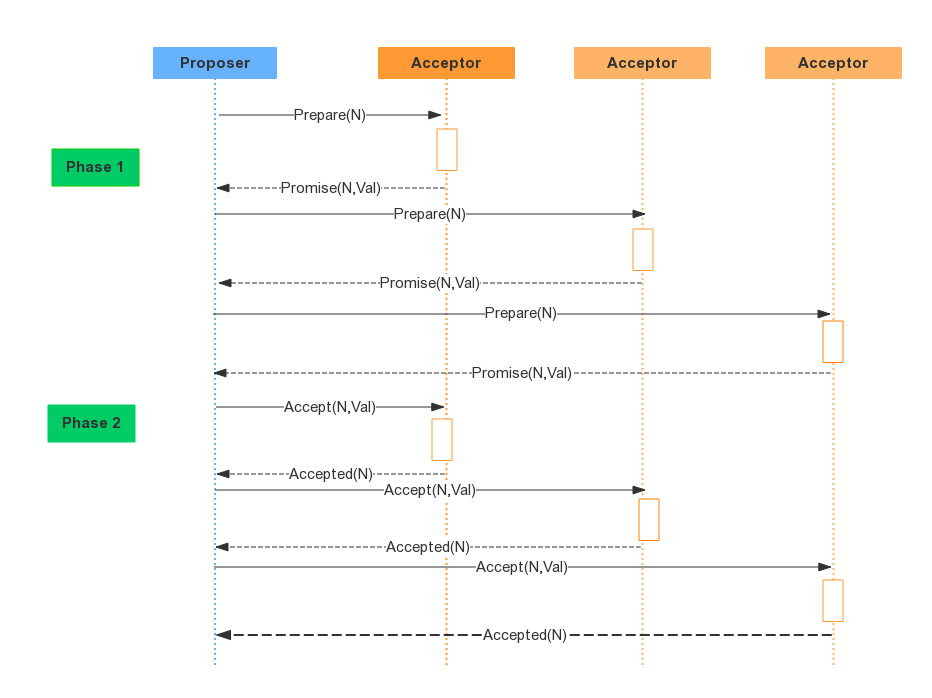
- Phase 1 准备阶段
Proposer 生成全局唯一且递增的ProposalID,向 Paxos 集群的所有机器发送 Prepare请求,这里不携带value,只携带N即ProposalID 。Acceptor 收到 Prepare请求 后,判断:收到的ProposalID 是否比之前已响应的所有提案的N大:
如果是,则:
(1) 在本地持久化 N,可记为Max_N。
(2) 回复请求,并带上已Accept的提案中N最大的value(若此时还没有已Accept的提案,则返回value为空)。
(3) 做出承诺:不会Accept任何小于Max_N的提案。
如果否:不回复或者回复Error。
- Phase 2 选举阶段
P2a:Proposer发送 Accept
经过一段时间后,Proposer 收集到一些 Prepare 回复,有下列几种情况:
(1) 回复数量 > 一半的Acceptor数量,且所有的回复的value都为空,则Porposer发出accept请求,并带上自己指定的value。
(2) 回复数量 > 一半的Acceptor数量,且有的回复value不为空,则Porposer发出accept请求,并带上回复中ProposalID最大的value(作为自己的提案内容)。
(3) 回复数量 <= 一半的Acceptor数量,则尝试更新生成更大的ProposalID,再转P1a执行。
P2b:Acceptor应答Accept
Accpetor 收到 Accpet请求 后,判断:
(1) 收到的N >= Max_N (一般情况下是 等于),则回复提交成功,并持久化N和value。
(2) 收到的N < Max_N,则不回复或者回复提交失败。
P2c: Proposer统计投票
经过一段时间后,Proposer收集到一些 Accept 回复提交成功,有几种情况:
(1) 回复数量 > 一半的Acceptor数量,则表示提交value成功。此时,可以发一个广播给所有Proposer、Learner,通知它们已commit的value。
(2) 回复数量 <= 一半的Acceptor数量,则 尝试 更新生成更大的 ProposalID,再转P1a执行。
(3) 收到一条提交失败的回复,则尝试更新生成更大的 ProposalID,再转P1a执行。
4.相关讨论
Paxos算法的核心思想:
(1)引入了多个Acceptor,单个Acceptor就类似2PC中协调者的单点问题,避免故障
(2)Proposer用更大ProposalID来抢占临时的访问权,可以对比2PC协议,防止其中一个Proposer崩溃宕机产生阻塞问题
(3)保证一个N值,只有一个Proposer能进行到第二阶段运行,Proposer按照ProposalID递增的顺序依次运行(3) 新ProposalID的proposer比如认同前面提交的Value值,递增的ProposalID的Value是一个继承关系
为什么在Paxos运行过程中,半数以内的Acceptor失效都能运行?
(1) 如果半数以内的Acceptor失效时 还没确定最终的value,此时,所有Proposer会竞争 提案的权限,最终会有一个提案会 成功提交。之后,会有半过数的Acceptor以这个value提交成功。
(2)
如果半数以内的Acceptor失效时 已确定最终的value,此时,所有Proposer提交前 必须以 最终的value 提交,此值也可以被获取,并不再修改。
如何产生唯一的编号呢?
在《Paxos made simple》中提到的是让所有的Proposer都从不相交的数据集合中进行选择,例如系统有5个Proposer,则可为每一个Proposer分配一个标识j(0~4),则每一个proposer每次提出决议的编号可以为5*i + j(i可以用来表示提出议案的次数)。
推荐larmport和paxos相关的三篇论文:
The Part-Time Parliament
Paxos made simple
Fast Paxos
参考:
CAP theorem
浅谈分布式系统的基本问题:可用性与一致性
分布式系统入门到实战
图解分布式一致性协议Paxos
Paxos协议学习小结
公众号ID:longjiazuoA

