

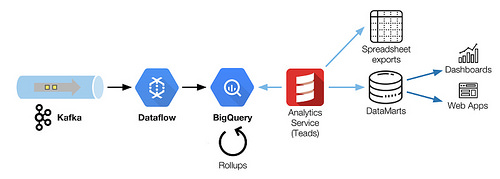
在这篇文章中,我们描述了如何协调Kafka,Dataflow和BigQuery共同采集和转换大数据流。当增加了模式和延时的约束时,调优和重新排序成了很大的挑战,下面展示了我们是如何解决它的。
发布者Tead是由Analytics提供支持的web应用之一
在数字广告中,日常运营产生了许多我们需要跟踪的事件,以便透明地报道活动的效益。这些事件来自:
-
用户与广告互动,通过浏览器发送。这些事件被称为可以标准化的(开始、完成、暂停、回复等)跟踪事件,或者使用Teads Studio构建的具有互动创意的自定义事件。我们每天收到大约100亿个跟踪事件。
-
来自我们的后端这些事件都是关于广告拍卖的大部分(实时出价流程)细节。在抽样之前我们每天产生的这些事件超过600亿,在2018年这个数字将翻一番。
在这篇文章中,我们聚焦于跟踪事件,因为它们是我们业务上最关键部分的。
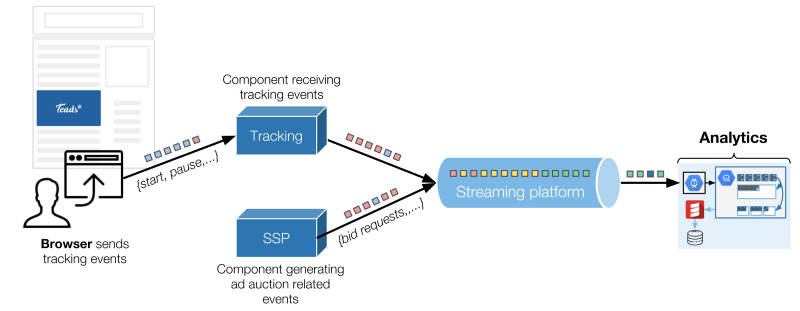
简单概述了我们技术环境的两个主要事件源
浏览器通过HTTP将跟踪数据发送到一个专用组件,其他的事情都列进了Kafka的topic中。Analytics是这些事件的服务对象之一。
我们用一个Analytics小组,他们的任务是按照如下定义管理这些事件:
我们获取了log的增长量,
我们将它们转化成面向业务的数据
我们为每一位顾客提供高效且定制的服务。
为了完成这个任务,我们建立和维护了一系列处理工具和管道。由于公司的有机增长和新产品的需求,我们定期挑战我们的结构。
为什么我们移向了BigQuery
回顾2016年,我们的Analytics跟踪基于lambda architecture系统架构(Storm、 Spark和Cassandra项目),并且出现了一些问题:
-
数据的模式使它不可能存放在单一的Cassandra表中,这会妨碍高效的交叉查询,
-
它是一个复杂的基础框架,在批处理和速度层都会出现代码复制,这阻碍了我们新功能的高效发布,
-
最终它将难以发展且不具有成本效益。
这时候,我们有了几种可能的选择。首先,我们可以建立一个增强的lambda,但它只能推迟我们要面临的问题。
我们考虑了几个有前景的替代品,像Druid何BigQuery。我们最终选择迁移到BiQuery,因为他有很多强大的功能。
通过BigQuery我们能够:
-
工作在原始事件,
-
使用SQL作为高效的数据处理语言,
-
使用BigQuery作为处理引擎,
-
使解释性访问数据更容易(相比Spark SQL或者Hive)
感谢flat-rate计划,我们高强度的用法(查询和存储方式)是具有高成本效益的。
然而,我们的技术环境不适合BigQuery。我们想用它来存储和转换来自多个Kafka topic 的所有事件。我们无法让我们的Kafka群组移出AWS,也无法使用与Kafka托管等效的Pub/Sub,因为这些群集也被我们托管在AWS上的一些广告投放组件使用。因此,我们不得不处理来自运营的多云基础框架的挑战。
今天,BigQuery是我们的数据仓库系统,用于我们的跟踪数据与其他的原始数据的协调核对。
获取
当处理追踪事件的时候,你面对的首要问题就是,你必须在不知道延迟的情况下无序地处理他们。
事件实际发生的时间(事件触发时间,event time)和系统注意到这个事件的时间(处理时间,processing time)之间的时间间隔的范围涵盖了从毫秒级到小时级。这些巨大的延迟并不罕见,而且当用户在浏览会话的时间中间连接断开了或者开启了飞行模式,就会出现这种情况。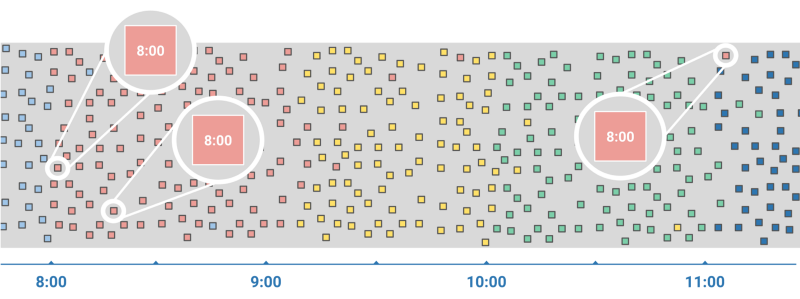
事件触发时间和处理时间的时间差
如果要获取流数据处理遇到的问题相关更多信息,我们建议去看Google Cloud Next’17 中Tyler Akidau(Google数据处理技术主管)和 Loïc Jaures(Teads的共同创始人和技术部高级副总裁)讨论《批处理和流处理之间的来回转换》。本文就是受到这个讨论的启发。
流的严酷现实
Dataflow是一个管理流系统,为了应对我们面对的事件的混乱本质的挑战而生。Dataflow有一个统一的流和批处理编程模型,流是它的主推特性。
由于Dataflow的承诺和对流模式的大胆尝试,我们购买了它。不幸的是,在面对真实生产环境的数据传输,我们感到了惊骇:BigQuery的流插入代价。
我们对压缩数据大小(即,通过网络的字节的实际数据卷)和非BigQuery的原始数据格式大小已经有了基本估算。幸运的是现在已经为每个数据类型提供了文档,因此你也可以做计算。
那时候,我们低估了这个额外代价的100倍,这几乎是我们整个获取渠道(Dataflow + BigQuery)的两倍代价。我们也遇到了其他的局限,例如100,000 events/s 速率限制,这已经几乎接近我们在做的事情了。
好消息是,有一种方法可以完全避免流插入限制:批量加载到BigQuery。
理想情况下,我们希望在流模式中使用Dataflow,在批处理模式下使用BigQuery。在那个时候,Dataflow SDK中没有用于无限制数据流的BigQuery批处理接收器。
然后我们考虑开发自己的自定义接收器。不幸的是,当时不可能在无限制的数据流中添加一个自定义的接收器(见Dataflow计划为在将来的版本中增加对编写无界数据的自定义接收器的支持——现在这是有可能的,Beam是官方的Dataflow SDK)。
我们别无选择,只能把我们的数据转换成批处理模式。由于Dataflow的统一模型,这仅仅是几行代码的问题。幸运的是,我们可以接收由切换到批处理模式所引入的额外数据处理延迟。
继续向前推进,我们目前的接入架构是基于Scio,这是一个由Spotify提供的Dataflow开源的Scala API。如前所述,Dataflow原生支持Pub/Sub,但集成Kafka还不太成熟。我们必须扩展Scio以支持检查点持久性和有效的并行性。
微型的批处理管道
我们的结果处理架构是一个30个节点的Dataflow批处理作业的链,按顺序排列,读取Kafka topic,并使用加载作业来写入BigQuery。
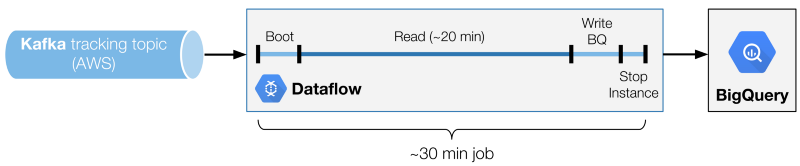
数据流小批量处理的多个阶段。
其中一个关键是找到理想的分批时间。我们发现在成本和读取性能之间有一个最佳的平衡点(因此延迟)。调整的变量是Kafka读取阶段的持续时间。
要得到完整的批处理时间,您必须将写入操作添加到BigQuery阶段也算在里面(不是成比例增加的,而是与读操作时间密切相关),再加上一个常量,也就是启动和关闭消耗的时间。
值得一提:
-
读取阶段太短会降低读取和非读取阶段之间的比例。在一个理想的情况下,1:1的比值意味着你必须能够以同样的速度进行读取和写入。在上面的例子中,我们有20分钟的读取阶段,对一个30分钟的批处理(比值为3:2)。这意味着我们必须能够在读取数据时比我们写入数据的速度快1.5倍。小的比值意味着需要更大的实例。
-
过长的读取阶段将简单地增加事件的发生时刻与BigQuery中其可用的时刻之间的延迟。
