在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。
这是 PaperDaily 的第 63 篇文章本期推荐的论文笔记来自 PaperWeekly 社区用户 @yanjoy。本文全面概述了深度神经网络的压缩方法 ,主要可分为参数修剪与共享、低秩分解、迁移/压缩卷积滤波器和知识精炼,论文对每一类方法的性能、相关应用、优势和缺陷等方面进行了独到分析。
如果你对本文工作感兴趣,点击底部的阅读原文即可查看原论文。
关于作者:小一一,北京大学在读硕士,研究方向为深度模型压缩加速。个人主页:http://yanjoy.win
■ 论文 | A Survey of Model Compression and Acceleration for Deep Neural Networks
■ 链接 | https://www.paperweekly.site/papers/1675
■ 作者 | Yu Cheng / Duo Wang / Pan Zhou / Tao Zhang
研究背景
在神经网络方面,早在上个世纪末,Yann LeCun 等人已经使用神经网络成功识别了邮件上的手写邮编。至于深度学习的概念是由 Geoffrey Hinton 等人首次提出,而在 2012 年,Krizhevsky 等人采用深度学习算法,以超过第二名以传统人工设计特征方法准确率 10% 的巨大领先取得了 ImageNet 图像分类比赛冠军。
此后的计算机视觉比赛已经被各种深度学习模型所承包。这些模型依赖于具有数百甚至数十亿参数的深度网络,传统 CPU 对如此庞大的网络一筹莫展,只有具有高计算能力的 GPU 才能让网络得以相对快速训练。
如上文中比赛用模型使用了 1 个包含 5 个卷积层和 3 个完全连接层的 6000 万参数的网络。通常情况下,即使使用当时性能顶级的 GPU NVIDIA K40 来训练整个模型仍需要花费两到三天时间。对于使用全连接的大规模网络,其参数规模甚至可以达到数十亿量级。
当然,为了解决全连接层参数规模的问题,人们转而考虑增加卷积层,使全连接参数降低。随之带来的负面影响便是大大增长了计算时间与能耗。
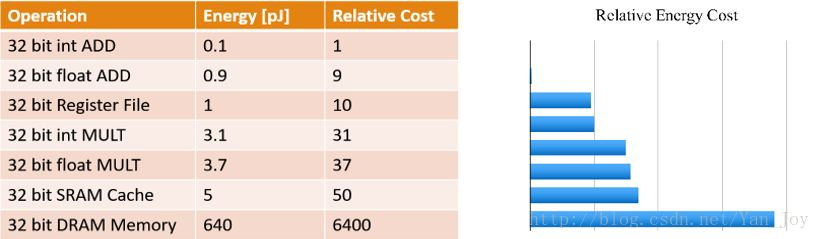
对于具有更多层和节点的更大的神经网络,减少其存储和计算成本变得至关重要,特别是对于一些实时应用,如在线学习、增量学习以及自动驾驶。
在深度学习的另一端,即更贴近人们生活的移动端,如何让深度模型在移动设备上运行,也是模型压缩加速的一大重要目标。
Krizhevsky 在 2014 年的文章中,提出了两点观察结论:卷积层占据了大约 90-95% 的计算时间和参数规模,有较大的值;全连接层占据了大约 5-10% 的计算时间,95% 的参数规模,并且值较小。 这为后来的研究深度模型的压缩与加速提供了统计依据。
一个典型的例子是具有 50 个卷积层的 ResNet-50 需要超过 95MB 的存储器以及 38 亿次浮点运算。在丢弃了一些冗余的权重后,网络仍照常工作,但节省了超过 75% 的参数和 50% 的计算时间。
当然,网络模型的压缩和加速的最终实现需要多学科的联合解决方案,除了压缩算法,数据结构、计算机体系结构和硬件设计等也起到了很大作用。本文将着重介绍不同的深度模型压缩方法,并进行对比。
研究现状
综合现有的深度模型压缩方法,它们主要分为四类:
-
参数修剪和共享(parameter pruning and sharing)
-
低秩因子分解(low-rank factorization)
-
转移/紧凑卷积滤波器(transferred/compact convolutional filters)
-
知识蒸馏(knowledge distillation)
基于参数修剪和共享的方法针对模型参数的冗余性,试图去除冗余和不重要的项。基于低秩因子分解的技术使用矩阵/张量分解来估计深度学习模型的信息参数。基于传输/紧凑卷积滤波器的方法设计了特殊的结构卷积滤波器来降低存储和计算复杂度。知识蒸馏方法通过学习一个蒸馏模型,训练一个更紧凑的神经网络来重现一个更大的网络的输出。
一般来说,参数修剪和共享,低秩分解和知识蒸馏方法可以用于全连接层和卷积层的 CNN,但另一方面,使用转移/紧凑型卷积核的方法仅支持卷积层。
低秩因子分解和基于转换/紧凑型卷积核的方法提供了一个端到端的流水线,可以很容易地在 CPU/GPU 环境中实现。
相反参数修剪和共享使用不同的方法,如矢量量化,二进制编码和稀疏约束来执行任务,这导致常需要几个步骤才能达到目标。
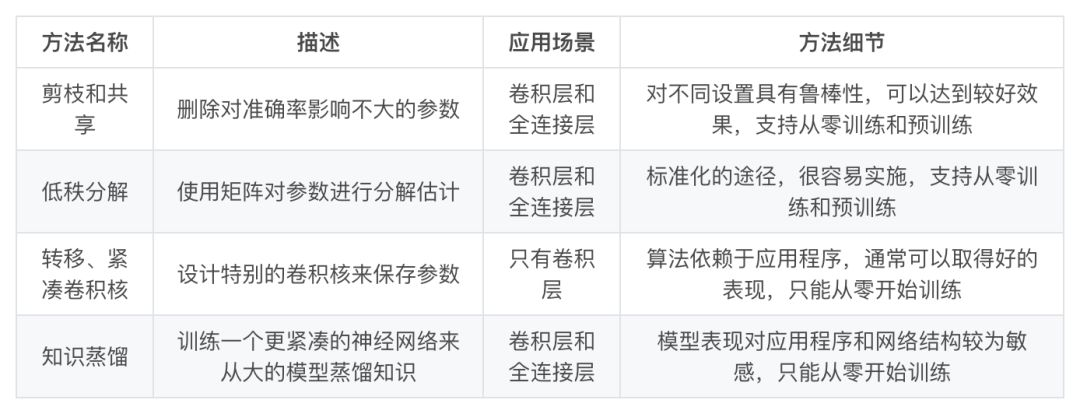
▲ 表1:不同模型的简要对比
关于训练协议,基于参数修剪/共享、低秩分解的模型可以从预训练模型或者从头开始训练,因此灵活而有效。然而转移/紧凑的卷积核和知识蒸馏模型只能支持从零开始训练。
这些方法是独立设计和相辅相成的。例如,转移层和参数修剪和共享可以一起使用,并且模型量化和二值化可以与低秩近似一起使用以实现进一步的加速。
不同模型的简要对比,如表 1 所示。下文针对这些方法做一简单介绍与讨论。
参数修剪和共享
根据减少冗余(信息冗余或参数空间冗余)的方式,这些参数修剪和共享可以进一步分为三类:模型量化和二进制化、参数共享和结构化矩阵(structural matrix)。
量化和二进制化
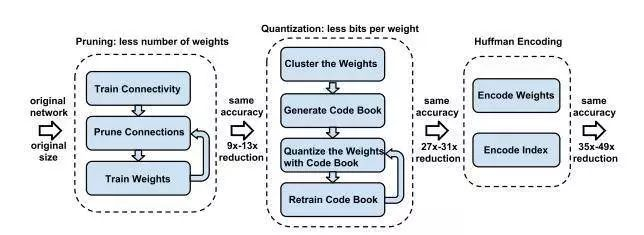
▲ 图2
网络量化通过减少表示每个权重所需的比特数来压缩原始网络。Gong et al. 对参数值使用 K-Means 量化。Vanhoucke et al. 使用了 8 比特参数量化可以在准确率损失极小的同时实现大幅加速。
Han S 提出一套完整的深度网络的压缩流程:首先修剪不重要的连接,重新训练稀疏连接的网络。然后使用权重共享量化连接的权重,再对量化后的权重和码本进行霍夫曼编码,以进一步降低压缩率。如图 2 所示,包含了三阶段的压缩方法:修剪、量化(quantization)和霍夫曼编码。
修剪减少了需要编码的权重数量,量化和霍夫曼编码减少了用于对每个权重编码的比特数。对于大部分元素为 0 的矩阵可以使用稀疏表示,进一步降低空间冗余,且这种压缩机制不会带来任何准确率损失。这篇论文获得了 ICLR 2016 的 Best Paper。
在量化级较多的情况下准确率能够较好保持,但对于二值量化网络的准确率在处理大型 CNN 网络,如 GoogleNet 时会大大降低。另一个缺陷是现有的二进制化方法都基于简单的矩阵近似,忽视了二进制化对准确率损失的影响。
剪枝和共享
网络剪枝和共享起初是解决过拟合问题的,现在更多得被用于降低网络复杂度。
早期所应用的剪枝方法称为偏差权重衰减(Biased Weight Decay),其中最优脑损伤(Optimal Brain Damage)和最优脑手术(Optimal Brain Surgeon)方法,是基于损失函数的 Hessian 矩阵来减少连接的数量。
他们的研究表明这种剪枝方法的精确度比基于重要性的剪枝方法(比如 Weight Decay 方法)更高。 这个方向最近的一个趋势是在预先训练的 CNN 模型中修剪冗余的、非信息量的权重。
在稀疏性限制的情况下培训紧凑的 CNN 也越来越流行,这些稀疏约束通常作为 l_0 或 l_1 范数调节器在优化问题中引入。
剪枝和共享方法存在一些潜在的问题。首先,若使用了 l_0 或 l_1 正则化,则剪枝方法需要更多的迭代次数才能收敛,此外,所有的剪枝方法都需要手动设置层的超参数,在某些应用中会显得很复杂。
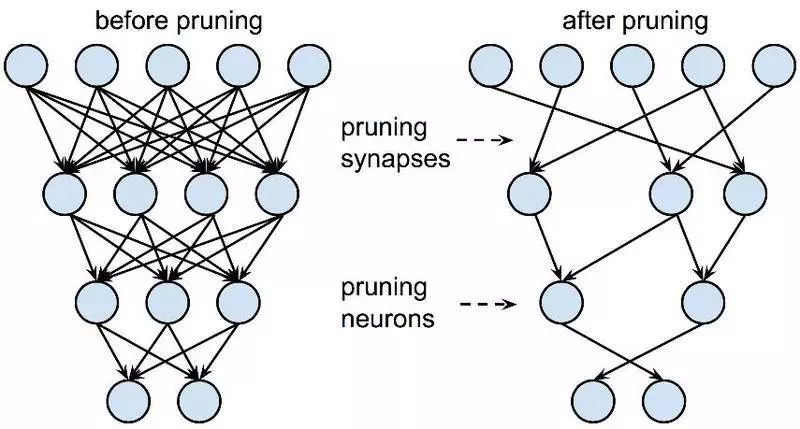
▲ 图3:剪枝和共享
设计结构化矩阵
该方法的原理很简单:如果一个 m×n 阶矩阵只需要少于 m×n 个参数来描述,就是一个结构化矩阵(structured matrix)。通常这样的结构不仅能减少内存消耗,还能通过快速的矩阵-向量乘法和梯度计算显著加快推理和训练的速度。
这种方法的一个潜在的问题是结构约束会导致精确度的损失,因为约束可能会给模型带来偏差。另一方面,如何找到一个合适的结构矩阵是困难的。没有理论的方法来推导出来。因而该方法没有广泛推广。
低秩分解和稀疏性
一个典型的 CNN 卷积核是一个 4D 张量,而全连接层也可以当成一个 2D 矩阵,低秩分解同样可行。这些张量中可能存在大量的冗余。所有近似过程都是逐层进行的,在一个层经过低秩滤波器近似之后,该层的参数就被固定了,而之前的层已经用一种重构误差标准(reconstruction error criterion)微调过。这是压缩 2D 卷积层的典型低秩方法,如图 4 所示。
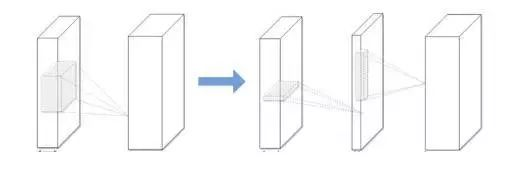
▲ 图4:压缩2D卷积层的典型低秩方法
使用低阶滤波器加速卷积的时间已经很长了,例如,高维 DCT(离散余弦变换)和使用张量积的小波系统分别由 1D DCT 变换和 1D 小波构成。
学习可分离的 1D 滤波器由 Rigamonti 等人提出,遵循字典学习的想法。Jaderberg 的工作提出了使用不同的张量分解方案,在文本识别准确率下降 1% 的情况下实现了 4.5 倍加速。
一种 flatten 结构将原始三维卷积转换为 3 个一维卷积,参数复杂度由 O(XYC)降低到 O(X+Y+C),运算复杂度由 O(mnCXY) 降低到 O(mn(X+ Y+ C)。
低阶逼近是逐层完成的。完成一层的参数确定后,根据重建误差准则对上述层进行微调。这些是压缩二维卷积层的典型低秩方法,如图 2 所示。
按照这个方向,Lebedev 提出了核张量的典型多项式(CP)分解,使用非线性最小二乘法来计算。Tai 提出了一种新的从头开始训练低秩约束 CNN 的低秩张量分解算法。它使用批量标准化(BN)来转换内部隐藏单元的激活。一般来说, CP 和 BN分解方案都可以用来从头开始训练 CNN。
低秩方法很适合模型压缩和加速,但是低秩方法的实现并不容易,因为它涉及计算成本高昂的分解操作。另一个问题是目前的方法都是逐层执行低秩近似,无法执行全局参数压缩,因为不同的层具备不同的信息。最后,分解需要大量的重新训练来达到收敛。
迁移/压缩卷积滤波器
虽然目前缺乏强有力的理论,但大量的实证证据支持平移不变性和卷积权重共享对于良好预测性能的重要性。
使用迁移卷积层对 CNN 模型进行压缩受到 Cohen 的等变群论(equivariant group theory)的启发。使 x 作为输入,Φ(·) 作为网络或层,T(·) 作为变换矩阵。则等变概念可以定义为:
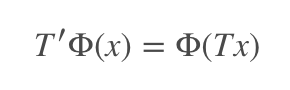
即使用变换矩阵 T(·) 转换输入 x,然后将其传送至网络或层 Φ(·),其结果和先将 x 映射到网络再变换映射后的表征结果一致。注意 T 和 T' 在作用到不同对象时可能会有不同的操作。 根据这个理论,将变换应用到层次或滤波器 Φ(·) 来压缩整个网络模型是合理的。
使用紧凑的卷积滤波器可以直接降低计算成本。在 Inception 结构中使用了将 3×3 卷积分解成两个 1×1 的卷积;SqueezeNet 提出用 1×1 卷积来代替 3×3 卷积,与 AlexNet 相比,SqueezeNet 创建了一个紧凑的神经网络,参数少了 50 倍,准确度相当。
这种方法仍有一些小问题解决。首先,这些方法擅长处理广泛/平坦的体系结构(如 VGGNet)网络,而不是狭窄的/特殊的(如 GoogleNet,ResidualNet)。其次,转移的假设有时过于强大,不足以指导算法,导致某些数据集的结果不稳定。
知识蒸馏
利用知识转移(knowledge transfer)来压缩模型最早是由 Caruana 等人提出的。他们训练了带有伪数据标记的强分类器的压缩/集成模型,并复制了原始大型网络的输出,但是,这项工作仅限于浅模型。
后来改进为知识蒸馏,将深度和宽度的网络压缩成较浅的网络,其中压缩模型模拟复杂模型所学习的功能,主要思想是通过学习通过 softmax 获得的类分布输出,将知识从一个大的模型转移到一个小的模型。
Hinton 的工作引入了知识蒸馏压缩框架,即通过遵循“学生-教师”的范式减少深度网络的训练量,这种“学生-教师”的范式,即通过软化“教师”的输出而惩罚“学生”。 为了完成这一点,学生学要训练以预测教师的输出,即真实的分类标签。 这种方法十分简单,但它同样在各种图像分类任务中表现出较好的结果。
基于知识蒸馏的方法能令更深的模型变得更加浅而显著地降低计算成本。但是也有一些缺点,例如只能用于具有 Softmax 损失函数分类任务,这阻碍了其应用。另一个缺点是模型的假设有时太严格,其性能有时比不上其它方法。
讨论与挑战
深度模型的压缩和加速技术还处在早期阶段,目前还存在以下挑战:
-
依赖于原模型,降低了修改网络配置的空间,对于复杂的任务,尚不可靠;
-
通过减少神经元之间连接或通道数量的方法进行剪枝,在压缩加速中较为有效。但这样会对下一层的输入造成严重的影响;
-
结构化矩阵和迁移卷积滤波器方法必须使模型具有较强的人类先验知识,这对模型的性能和稳定性有显著的影响。研究如何控制强加先验知识的影响是很重要的;
-
知识精炼方法有很多优势,比如不需要特定的硬件或实现就能直接加速模型。个人觉得这和迁移学习有些关联。
-
多种小型平台(例如移动设备、机器人、自动驾驶汽车)的硬件限制仍然是阻碍深层 CNN 发展的主要问题。相比于压缩,可能模型加速要更为重要,专用芯片的出现固然有效,但从数学计算上将乘加法转为逻辑和位移运算也是一种很好的思路。
量化实验中问题与讨论
实验框架的选择
TensorFlow 支持的是一种静态图,当模型的参数确定之后,便无法继续修改。这对于逐阶段、分层的训练带来了一定的困难。相比之下,Pytorch 使用了动态图,在定义完模型之后还可以边训练边修改其参数,具有很高的灵活性。这也是深度学习未来的发展方向。
目前的开发者版本 nightly 中,TensorFlow也开始支持动态图的定义,但还未普及。 因此在选择上,科研和实验优先用 Pytorch,工程和应用上可能要偏 TensorFlow。
聚类算法的低效性
聚类算法是量化的前提,sklearn 中提供了诸如 K-Means,Mean-shift,Gaussian mixtures 等可用的方法。
其中 K-Means 是一种简单有效而较为快速的方法了。在个人电脑上,由于训练网络参数规模较小,因而无法体现出其运算时间。在对 VGG 这样大型的网络测试时,发现对于 256 个聚类中心,在 fc 的 4096∗4096 维度的全连接层进行聚类时,耗时超过 20 分钟(没有运行完便停止了),严重影响了算法的实用性。
目前的解决办法是抽样采样,如对 1% 的参数进行聚类作为整体参数的聚类中心。这样操作后聚类时间能缩短到 5 分钟以内。
有没有一个更加简便的方法呢? 对于训练好的一个模型,特别是经过 l2 正则化的,其参数分布基本上可以看作是一个高斯分布模型,对其进行拟合即可得到分布参数。
这样问题就转化为:对一个特定的高斯分布模型,是否能够根据其参数直接得到聚类中心?
如果可以,那这个聚类过程将会大大缩短时间:首先对权重进行直方图划分,得到不同区间的参数分布图,再由此拟合高斯函数,最后用这个函数获得聚类中心。这个工作需要一定的数学方法,这里只是简单猜想一下。
重训练带来的时间成本
我们日常说道的数据压缩,是根据信源的分布、概率进行的,特别是通过构建字典,来大大减少信息冗余。
这套方法直接使用在模型上,效果往往不好。一个最重要的原因就是参数虽然有着美妙的分布,但几乎没有两个相同的参数。在对 Alexnet 进行 gzip 压缩后,仅仅从 233MB 下降到 216MB,远不如文本以及图像压缩算法的压缩率。因此传统方法难以解决深度学习的问题。
剪枝量化虽好,但其问题也是传统压缩所没有的,那就是重训练所带来的时间成本。这个过程就是人为为参数增加条件,让网络重新学习降低 loss 的过程,因此也无法再重新恢复成原始的网络,因为参数不重要,重要的是结果。
这个过程和训练一样,是痛苦而漫长的。又因为是逐层训练,一个网络的训练时间和层数密切相关。
Mnist 这种简单任务,512∗512 的权重量化重训练,由最开始的 8s 增加到 36s,增加了约 4 倍时间(不排除个人代码优化不佳的可能)。 如果在 GPU 服务器上,Alex 的时间成本可能还是勉强接受的,要是有 GoogleNet,ResNet 这种,真的是要训到天荒地老了。
实现过程中,有很多操作无法直接实现,或者没有找到简便的方法,不得不绕了个弯子,确实会严重降低性能。
本文由 AI 学术社区 PaperWeekly 精选推荐,社区目前已覆盖自然语言处理、计算机视觉、人工智能、机器学习、数据挖掘和信息检索等研究方向,点击「 阅读原文」即刻加入社区!