

有一次,我们公司开会,机器学习团队的老大汇报业绩时候说到,我们最近做出来的最好的模型,KS 达到了 0.45(不要纠结这个数字哈,随便写了一个)。搞业务的某个同学就一脸懵逼地问,这个 KS 是个什么意思呢?这是好呢?还是不好呢?
当时,对这个问题的回答是失败的,会议陷入了小小的混乱。大家遇到的困扰是,很难用“人话”或者“普通话”,讲清楚到底什么是 KS。小 L 解释不清,老 B 上,还是解释不清,老 H 登场,最后还是没让听众彻底满意,当然,搞清楚这个也不是特别重要,最后一笑也就过去了,“回去自己百度/知乎”云云。
小生斗胆,想要尝试去解释清楚什么是 KS。咱们直接上干货吧。
我们公司的机器学习建模,目标是构建一种“二分类”模型,简单说,就是把一群人,分成“好人”和“坏人”。建模最后的结果是,我们使用模型给每个人打个分数,分数越低,人越坏,反之,则越好。然后,按照分数高低,我们可以把人给排列整齐。
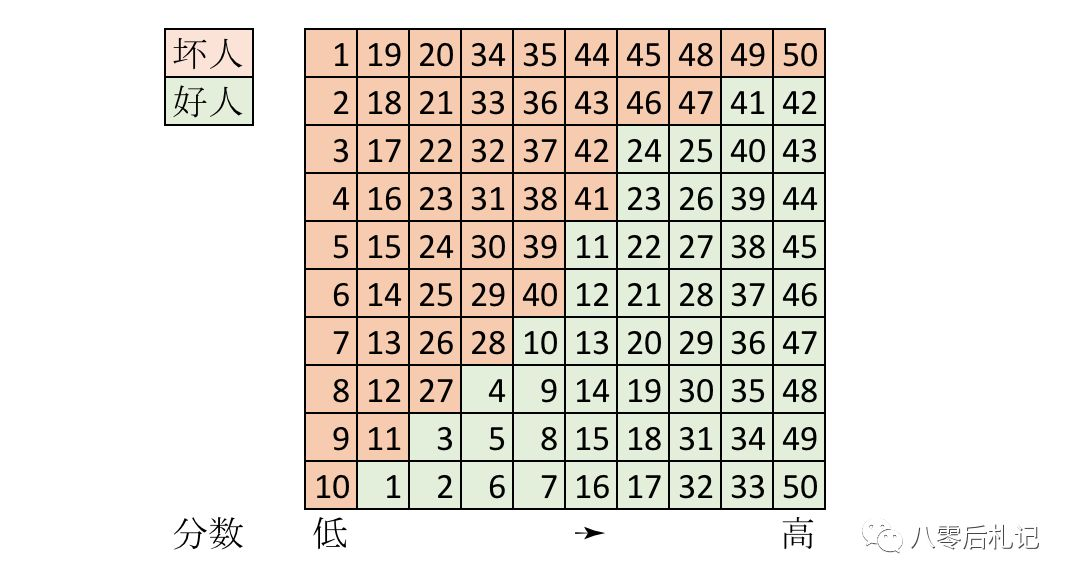
看上图,模型产生 10 个分数,从低到高,把 100 个人,按照从坏到好,排成 10 列。这种排列的方式,是模型的一种预测,它不知道真实的情况是什么。
我们用颜色代表真实的情况。图里,红色代表坏人,绿色代表好人。假如,我们这个模型是上帝做的,绝对正确,我们就会看到一种现象,左边 5 列都是红的,右边 5 列都是绿的。
但是,模型是人做的,难免猜错,就会出现上面的现象,大体左边坏人多一些,右边好人多一些,但是有一些猜错的现象。每个小格子里的编号,是为了让读者你方便计算数量。显然,这 100 个人里,正好 50 个好人,50 个坏人。
下面,我需要一个机器警察去抓坏人。不过,这个机器警察只能按照模型预测的分数去抓,我们设定一个分数值,机器警察会把小于等于这个分数的人,都给抓起来。
现在我们需要做一个表格,来计算每个分数下面,抓到的坏人占全部坏人的比率(抓对率),以及抓到的好人占全部好人的比率(误抓率)。

看上面的图。假设,我们设为 0 分,没有人会被抓。同理,设置为 10 分,则所有坏人(100%)和所有好人(100%)都会被抓。
上面图里的表格,每一列代表,设置为这个分数时候,抓住的好人占所有好人的概率(误抓率),以及抓住的坏人占所有坏人的概率(抓对率)。第三行数字,代表两种概率的差值(坏人的概率 减去 好人的概率)。
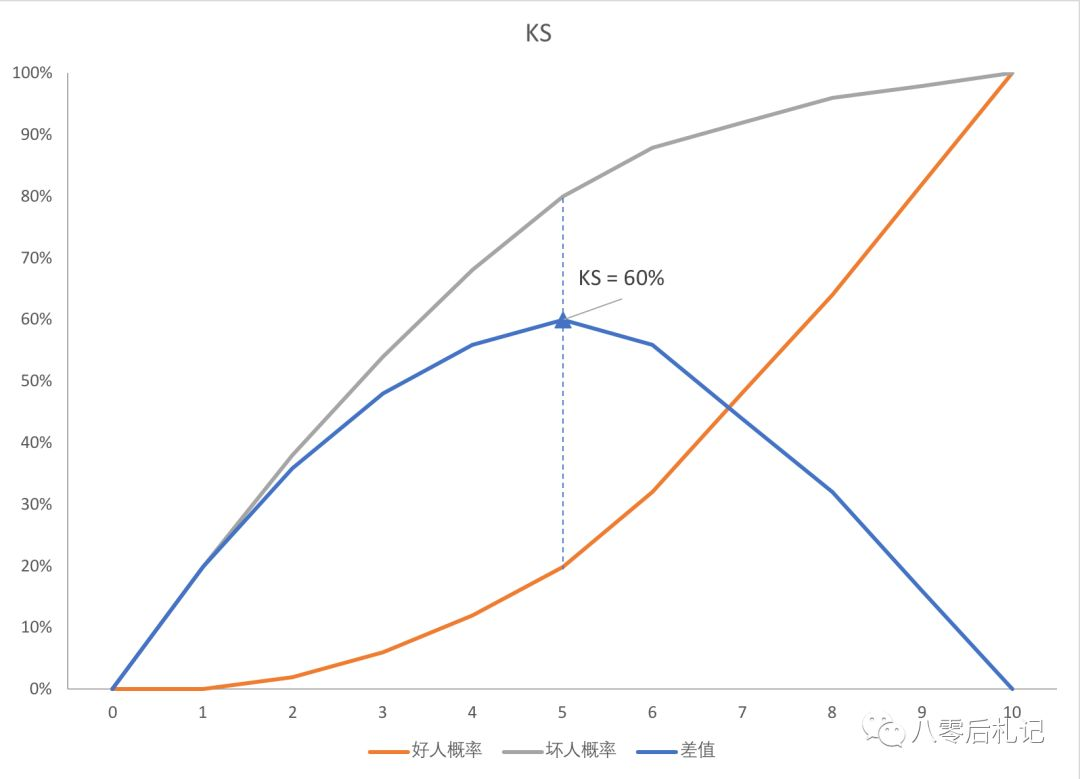
假如,我们把上面的那个表格,可视化一下,画成折线图,就会是上面的样子。
上面那根灰色的线,代表每个分值抓住的总坏人率,下面那根红线代表误抓的总好人率。蓝色的线代表差值的变化情况。
然后,关键来了。蓝色的线的顶点。就是我们的主角 KS 君。到这里,我们基本讲明白了什么是 KS,诸君看懂了么??
========
我猜,你的脸是下面这样的:

Hey, bro ? So what ? 翻译成中文是,他*的,什么鬼?
KS 有毛用?抓人呢?
嗯……
简单说,KS 就是这样一种东西,确实也没什么用,至于抓人怎么决策什么的,KS 君也很难帮你。
如果,你很仁慈,你应该把机器警察的抓人分,设置成 1 分。一个好人也不误抓,宁肯让一些坏人逍遥法外。如果你很残暴,错杀一千不放过一个,你就设置成 10 分,把所有人都抓了。
对对,我当然知道 KS 是 60%,发生在设置为 5 分的时候,但是那又怎么样???不能怎么样。你没看错,不能怎么样。具体设置在几分呢?还是看心情。
======
回归严肃脸。
KS 量化评估了一个模型,累计好人和累计坏人相差最大的那个位置,从很小的一个侧面反应了一个模型的区分能力。几乎没有卵用。显然,预测的目标人群里,真实好坏客户的占比,会严重干扰KS的值。
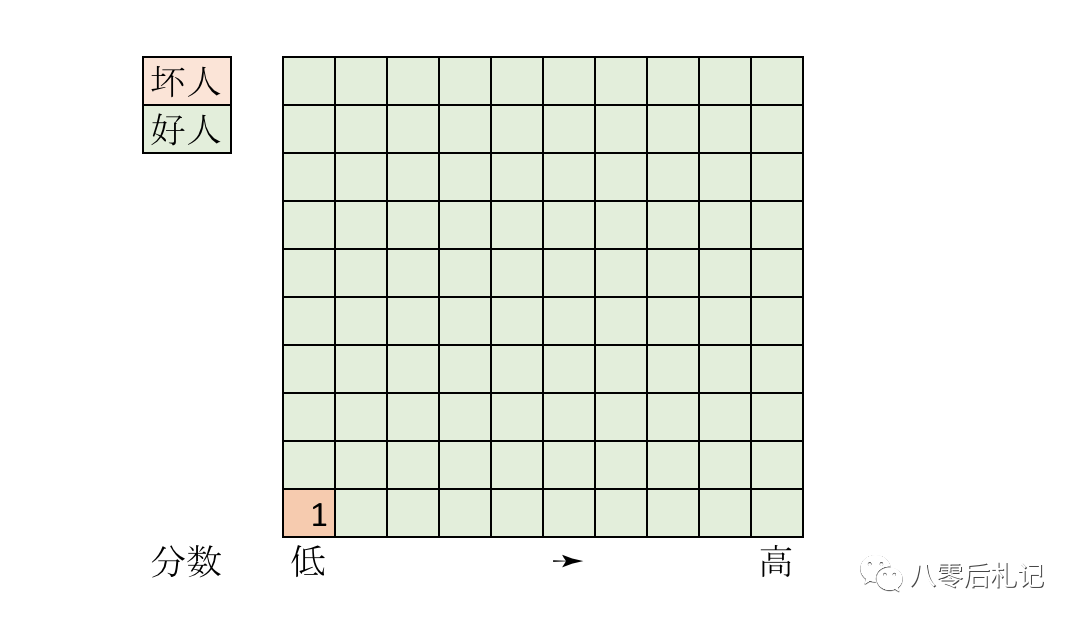
在上图的极端情况下,KS 高达 82%,在分值设为 1 分的时候。你应该可以口算出来吧?(KS 并不是越高越好,当我们说KS越高越好的时候,一定是有一些前提的)
而且,跟抓人困境一样,KS 对决策几乎没有什么实质性的帮助。只是一种参考而已。显然,我们在真实抓人的时候,不一定可以设置能取到 KS 的分值(例如 第一个例子里的 5 分),你要考虑监狱的床位够不够,对吧?
说好的三张图,其实用了五张。就当我把你骗了,怎么的吧?
嘻嘻,希望你学会了,什么是 KS。
完。
PS. 课本上说,对一个风控模型来说,经验上,KS 统计量至少要 40% 才反应一个较好的判别能力。(课本知识,你懂的,自己判断咯)
再PS. KS 是一个统计量,是两个战斗民族(俄罗斯人)的名字(Kolmogorov-Smirnov)缩写。
最后,门外汉知道这些就够了。
真的。
完了。

