

大数据时代,每个公司都会遇到一些共性的挑战,比如大数据的采集、整合、存储、计算。Airbnb 在大数据平台架构构建的过程中,也收获了很多宝贵的经验。

2017 年 12 月 1 日-2 日,由 51CTO 主办的 WOTD 全球软件开发技术峰会在深圳中州万豪酒店隆重举行。Airbnb Sr Software Engineer 王宇在大数据系统架构设计专场与来宾分享了“Airbnb 的跨洋大数据架构”主题演讲。
他为大家揭秘了 Airbnb 是如何解决大数据的存储应用以及跨洋的数据平台的搭建和支持,详析 Airbnb 大数据挑战和解决方案,分享如何解决大数据高效存储和计算的过程,并了解如何进行大数据平台的跨洋支持。
本次分享分为三大部分:
-
Airbnb 的大数据需求,它是整个数据架构的基础。
-
Airbnb 的大数据架构,包括 Superset 等部件。
-
Airbnb 大数据架构对中国的支持,虽然公司位于美国加州,但是对于中国市场业务也提供着数据方面的支持。
Airbnb 的大数据需求
先介绍一下 Airbnb 对大数据的需求和数据的驱动。
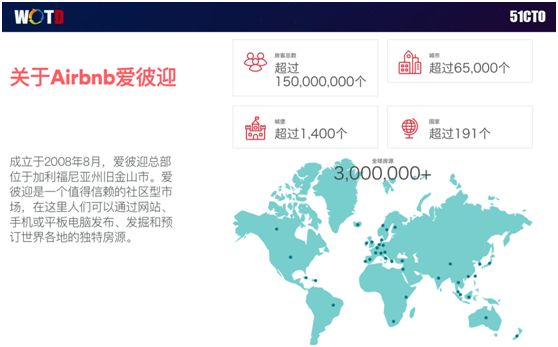
Airbnb 于 2008 年 8 月成立,人们可以通过网站、手机或平板电脑,发布、发掘和预订各地的独特房源。上图所列数据虽不是最新,但是可见数据的体量是非常庞大的。

Airbnb 服务对象的多样性决定了:我们必须通过定制化的数据产品,为用户提供最佳的旅行体验。同时我们的平台也会基于各种数据做出正确的决策。
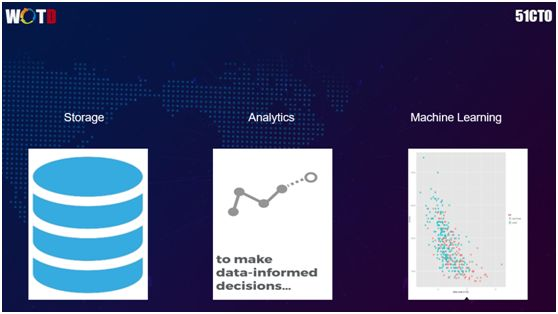
我们对于数据的使用流程分为:
-
最底层是数据的存储(Storage),一般具有高配置的计算能力和容量。
-
中间层是基于数据的挖掘与分析,我们根据不同的场景,通过 Data Mining和 Analytics,来实现用户管理、定价和风险控制,从而为运营(Operating)团队提供可参考的模型矩阵(Matrix)。
-
最上层是我们根据不同的产品结构所开展的基于数据的机器学习、人工智能、决策预判等。

我们在企业中比较推崇 Data Informed Culture,我们通过检查各种试验性的假设、和深度挖掘各种商业数据,从而构建出机器学习的模型。
同时,我们通过持续监控与跟踪,将数据作为决策的重要依据,保证平台上的任何推荐都能够严格基于数据的指标。
Airbnb 的大数据架构
下面我们从 Airbnb 大数据架构的构建理念、整体的架构特点和对部分系统的 Deep Dive 来深入探讨。
Airbnb 大数据架构理念
虽然经历了几代数据架构的升级,但是我们的理念一直保持如下五个特点:
-
开源软件的使用,在开源社区里有着非常多的优秀产品可为我们提供帮助。
-
使用标准的组件和方法,可以提高通用性和重用性。
-
关注可扩展性,在设计的最初就要考虑到系统的 scale up(扩容),从而使得整体架构既简单易懂,有灵活伸缩。
-
解决数据用户的实际问题,真正满足数据使用者的需求,给他们提供所需的环境。
-
留有余量,为了提高产品效率,公司产品线的增加往往相对于现有的数据架构的压力并非是线性上升的,因此我们要在设计之初就留有足够的余量。
Airbnb 大数据架构实战

上图所列的数据虽不是最新,但与当前的实际体量也差不多。我们日志消息的容量大概有 10B,数据仓库的容量大概是 50PB 以上,机器的数量大约有几千台,而数据的年增长率则是每年 5 倍的增长速度。
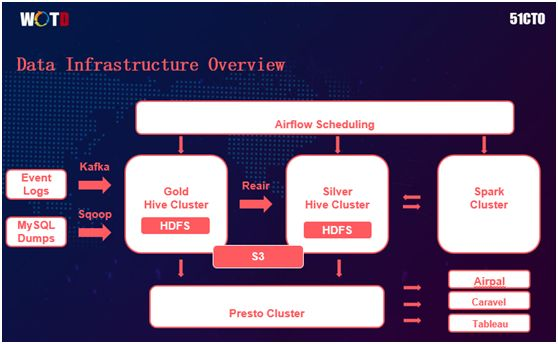
上图展示的是我们数据架构的一个概览。从左向右,首先是两种输入:
-
Event Logs,一般是由用户行为所触发,它连接的是改进版 Kafka,即:底层是 Kafka 的 Jenkins,而我们在上层做了许多优化。
-
MySQL Dumps,来自传统关系型数据库的在线数据流被 Sqoop 传递到 Hadoop 的 HDFS 中。
而中间则由 Gold Hive Cluster 和 Silver Hive Cluster 两个部分组成,所有的 Raw Data 和 Log 在被处理之前,全都被送入 Gold Cluster 进行各种应用、分类和特征的提取。
在产生相应的 table 之后,再被放入 Server 中。那么如果所有的变化都是批量产生的话,我们就能够很容易地实现同步。
但是如果出现 Interfering Change(干扰变更)时,为了保持一致性,我们自己写了一个 Re-air 的工具,去同步两个单独的 Data Clusters。
最上面是 Airflow Scheduling,Airflow 是我们公司内部自行开发的一个系统,我们用它去做 schedule job。
通过良好的 UI,它能够实现数据流的分配管理,控制任务间依赖关系和时间调度。同时它还能够调度上图右边的 Spark Cluster。
最下方是 Presto Cluster,它是 Facebook 研发出的一套开源的分布式 SQL 查询引擎,适用于交互式分析查询。
其右边对应的分别是:负责界面显示的 Airpal、简易的数据搜索分析工具Caravel、和 Tableau 公司的可视化数据分析产品。
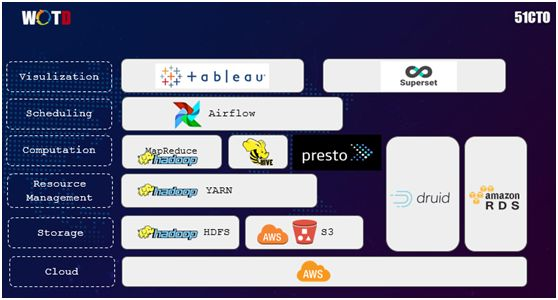
如上图所示,我们的 Data Cluster 云是架构在亚马逊的 AWS 上,其中全球部分被放置在美国东部,而中国部分则被放置在新加坡:
-
在存储方面,我们使用的是 Hadoop 的 HDFS 和 AWS 的 S3。
-
在资源管理上,我们用到了 YARN。同时我们通过 Druid 和亚马逊的 RDS,实现了对数据库连接的监控,以及操作与扩展。
-
在计算上,我们采用的是 MapReduce、HIVE 和 Presto。
-
在调度上,我们使用的是自己开发的 Airflow。
-
在可视化上,我们用到了现成的 Tableau 和 Superset。
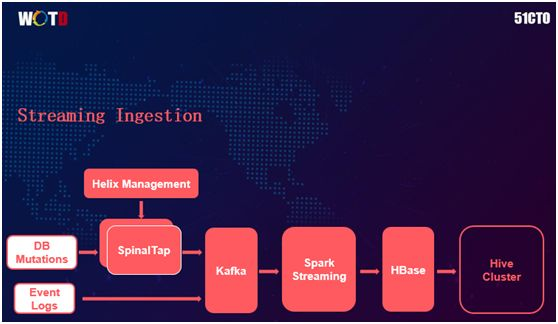
我们来具体看看 Streaming Ingestion(数据流摄取)的流程。首先,我们主要获取的是两种输入:
-
Event Logs
-
DB Mutations
为了记录数据库的变化(mutations),我们自行开发了一个叫做 SpinalTap 的系统,用来捕获每个表(table)的变化。
该系统是由通用分布式集群管理与调度框架 Helix 来进行管理的。Helix 不但开源,而且我个人觉得比 Zookeeper 更好用。
然后数据顺次进入 Kafka 的 Jenkins,Spark Streaming,之后到达 Hbase 的数据仓库。
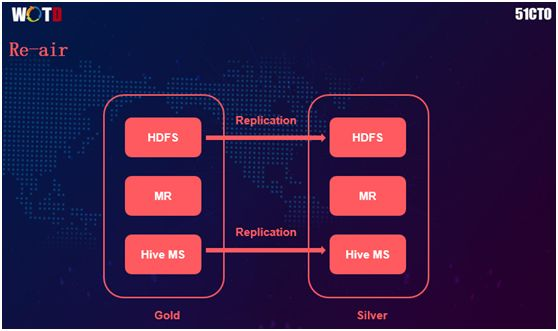
上图是 Re-air 的抽象逻辑图,其中最重要的就是实现在 Gold、Cluster 和 Silver Cluster 之间 HDFS 的实时同步。另外在它对所有数据同步的过程中,也能具有去重的效果。
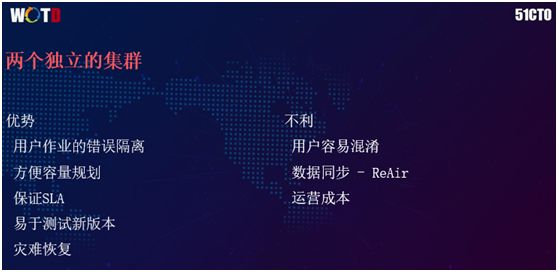
说到两个独立的集群,现在许多公司都在尝试这样的架构,我们也是力推 Gold+Silver 的集群模式。
它的优势在于:
-
用户作业的错误能够被完全隔离。
-
容量规划更为方便。我们可以对两个集群的容量及各种参数进行预估,在管理角度上更为清晰。
-
保证 SLA。您一旦形成了独立集群的概念和能力,就能快速地升级或部署新的函数与应用。
-
具有更为可靠性的灾难恢复能力。
当然,该架构也会存在着如下的缺点:
-
用户容易混淆,据官方数据声称,用户容易混淆两个集群。
-
数据同步,这是两个集群的最大挑战,不过我们用 Re-air 解决了此问题。
-
运营成本可能会有所增加。

前面我们提到过两个数据仓库之间的同步策略,具体说来一般分为两种方式:
-
批量同步。优点是:扫描 HDFS、Metastore,拷贝相关的数据,简单粗暴、也不需要维护状态; 缺点是:当您的存储容量变得很大时,延时会比较高。
-
增量同步。优点是:更为智能化,它可以记录数据源的变化,通过拷贝到目标集群,执行相关操作。其延时非常低,我们在两边的同步延迟可以达到秒级; 缺点是:复杂,需要维护和处理好许多状态。

如今业界许多公司都在使用 Airflow,来实现统一的调度管理系统(Schedule System)。我们公司内部也开发出了一套自己的工作流系统。
它有着独特的 UI,能提供许多内置的 Operators。我们可以通过自定义各种 Job(作业),来支持 Hive、Presto、MySQL、S3 等系统。
当然,相类似的系统也有:Apache 的 Oozie、Azkaban、AWS 的 SWF 等,但是 Airflow 更好用一些。
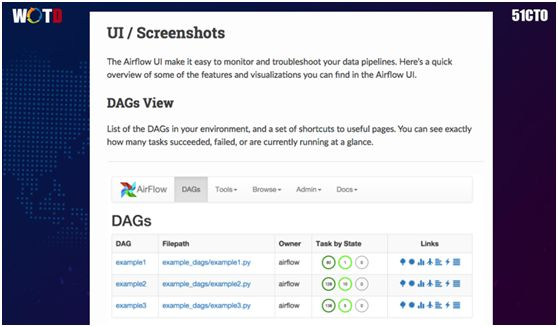
简单来说,如果您要做一套 Flow,那么首先需要定义不同流程的特征(feature)。
通过收集,我们便可罗列出自己环境中的 DAG,其中包括各种成功或失败的任务(tasks)。
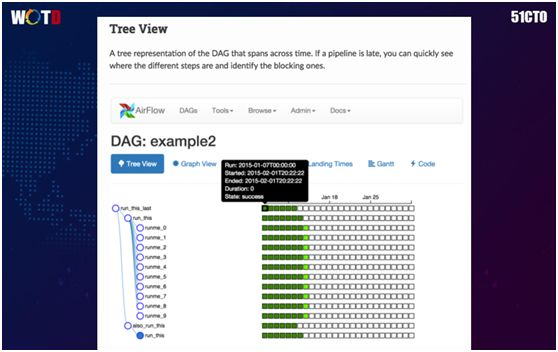
通过如图所示的树形视图(Tree View),您可以迅速地通过时间状态来找到被阻止的地方。
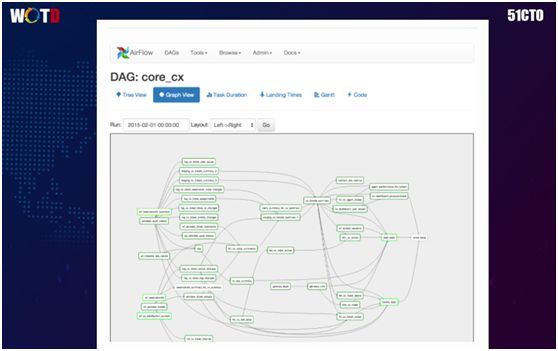
您还能够获知关键组件间的逻辑关系,如上图所示。
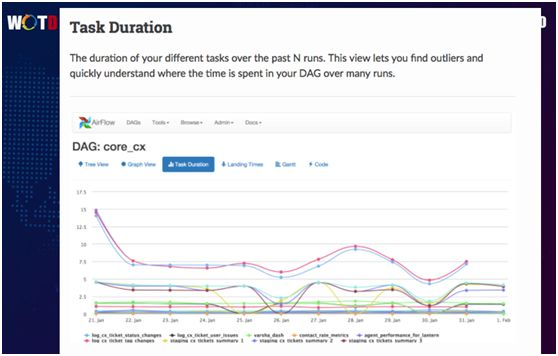
而通过任务耗时曲线图,您可以了解到在过去的屡次运行中,不同任务的具体耗时情况,出现过的异常值,以及最耗时的环节。

我们再来看看 Superset,它是由 Apache 提供的一种开源的大数据可视化工具,我们对其也进行了自行开发。
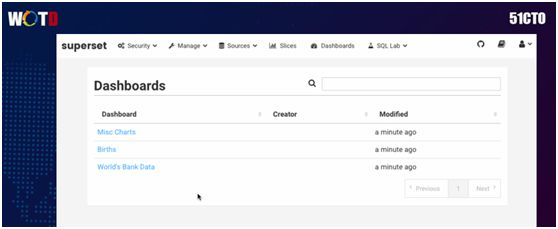
Superset 的功能比较强大,您可以自行建立不同的 Dashboard(仪表盘),它支持各种应用数据的查询,并能以曲线、饼图或表的形式展示出来,还能定制化显示页面。
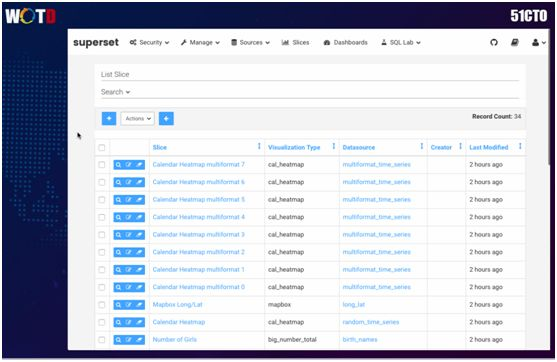
通过简单的页面点击,数据能够立即呈现出来。同时它还能提供各式各样的 Matrix(模型矩阵),以供进一步做细粒度的分析。
Airbnb 大数据架构对中国的支持
最后我介绍一下大数据架构对中国的支持。对于 Airbnb 这样的海外公司在进入中国市场的过程中,鉴于中国对于数据安全性的合规要求等方面的挑战,我们找到了一些相应的解决方案。
大数据架构在中国的挑战
由于 Airbnb 是一个旅游的平台,所以我们会存储一些和个人相关的信息。例如:我们会要求用户上传身份证的相关信息。
如果是房东的话,我们还要求他注册家里的各种数据。因此,我们不能将数据简单放到谷歌上。
同时,中国的研发团队不仅需要最大程度地使用中国本地的数据,还要用到位于美国数据中心的全球数据。
因此,保证数据的安全性和使用时的高效性,是我们所面临的两大挑战。
解决方案
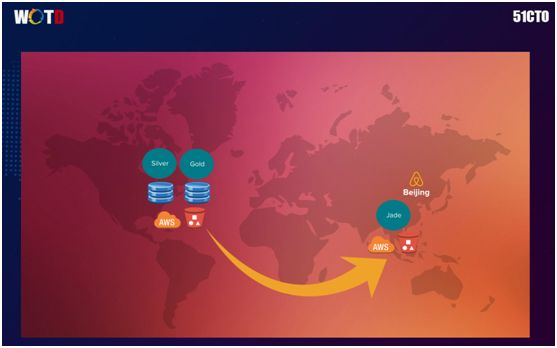
我们在亚洲的新加坡有个 Gold 和 Silver Cluster 区域中心,而在中国北京我们用的是 Jade,其结构一模一样,只是在业务上有细微的差别。
如前面所提到的,我们在存储上用到了 HDFS 和 S3。而实际上,我们在全球绝大多数地区都使用的是 HDFS,只是在 Jade Cluster 里我们用的是 S3。
数据支持
首先来看看 Universal Export(统一导出)对数据的支持。我们无时无刻地在向中国这边输送着全球的信息数据。
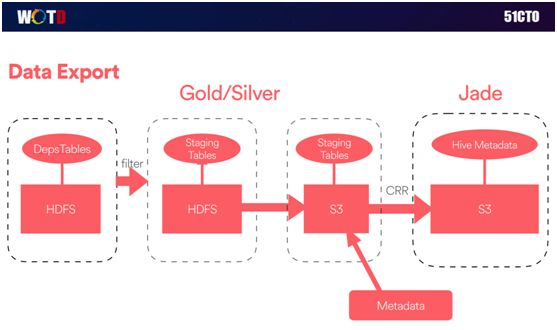
上图是数据输出的简要逻辑图。最左边是全球的数据表输入,由于安全性的原因,我们通过 Filter 进行过滤,并且在生产环境中建立了一个基于 HDFS 的 Staging Table。
而其右边则是另一个基于 S3 的 Staging Table,因此这些数据在跨区域到达亚洲的时候,我们这边会有相应的 Job(作业)去进行评估和过滤。
另外,我们通过两套数据的方式,大幅提高了对于数据的访问使用速度,以及系统之间的复制效率。
服务监控
下面简单介绍一下我们端对端的服务级别监控,如下图:
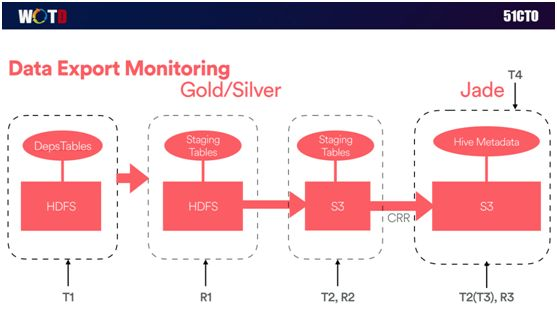
由于系统对于实时性要求比较高,我们需要通过良好的监控,以获知在什么时候、在何处出现了什么问题。
因此我们在整个过程中都“打上”了各种时间标记,从而能够无时无刻地监控到不同交易之间的时间差,同时也包括每一步之间数据的差异性。
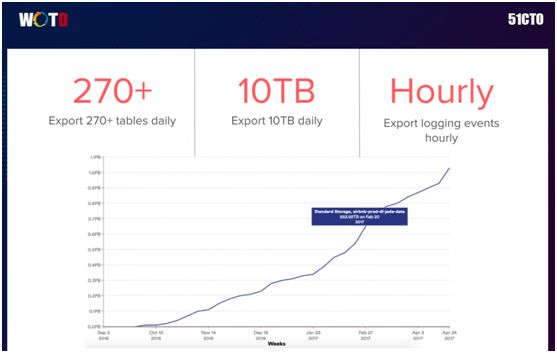
如上图所示,我们实现了按小时输出日志事件、按天输出近 300 张表、10TB 的数据量,这些都归功于我们在全球和中国范围内的大数据整体架构。
作者:王宇
编辑:陈峻、陶家龙、孙淑娟
投稿:有投稿、寻求报道意向技术人请联络 editor@51cto.com

王宇,于华中科技大学和石溪大学(Stony Book University)获得本科与硕士学位。曾就职 Quantcast 和 Qualcomm。在 Quantcast 主要负责广告的实时竞价和精准投放;在 Qualcomm 负责搭建芯片数据的云存储和分析系统。现加入 Airbnb 中国基础构架组(China Infrastructure),任职高级软件工程师,负责 Airbnb 中国产品相关的基础构架(Data Infrastructure) 和反欺诈服务(Anti-Fraud)。

精彩文章推荐:
