作者 :糖甜甜甜,文科女生一枚,不定期分享数据分析文章,以最简单的视角理解数据。 知乎专栏:经管人学数据分析
隐马尔可夫模型差不多是学习中遇到的最难的模型了,本节通过对《统计学习方法》进行学习并结合网上笔记, 用Python代码实现了隐马模型观测序列的生成、前向后向算法、Baum-Welch无监督训练、维特比算法。比较清晰的了解了 隐马尔可夫模型,其实在实际运用中我们只需要调用库就一行代码解决问题。
在调用分词函数时就采用的隐马尔可夫模型HMM原理来进行切词。
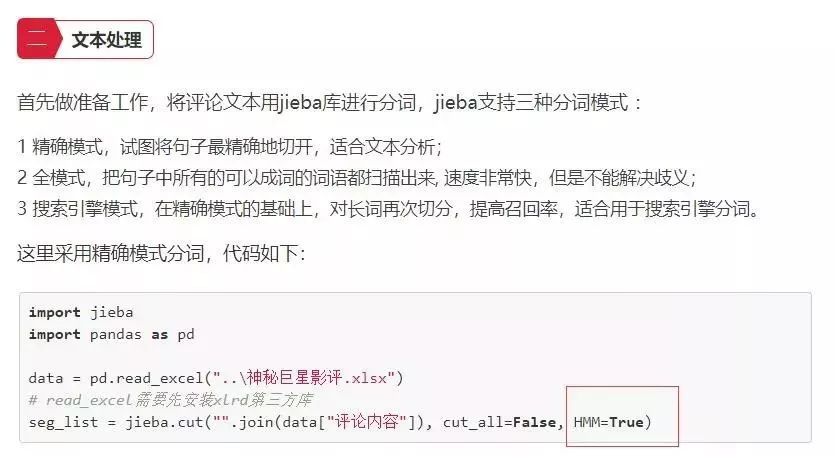
具体原理解释介绍如下:
1 隐马尔可夫模型定义
隐马尔可夫模型是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观测随机序列的过程。隐藏的马尔可夫链随机生成的状态的序列,称为状态序列(state sequence);每个状态生成一个观测,而由此产生的观测的随机序列,称为观测序列(observation sequence)。序列的每一个位置又可以看作是一个时刻。
什么叫隐马尔科夫链呢?简单说来,就是把时间线看做一条链,每个节点只取决于前N个节点。就好比你打开朋友圈通过你朋友的最近几条状态就可以判断他接下来要干嘛。
接下来引入一些符号来表述定义:
设Q是所有可能的状态的集合,V是所有可能的观测的集合。
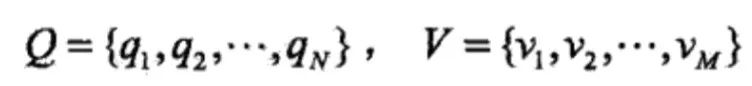
其中,N是可能的状态数,M是可能的观测数。
状态q不可见,观测v可见。应用到词性标注系统,词就是v,词性就是q。
I是长度为T的状态序列,O是对应的观测序列。
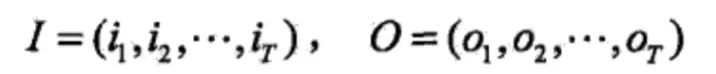
这可以理解为相当于给定了一个词(O)+词性(I)的训练集或者说是中文分词系统里的词典。
定义A为状态转移概率矩阵:
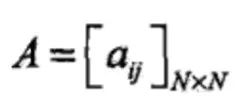
其中,
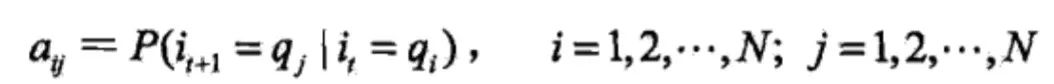
是在时刻t处于状态qi的条件下在时刻t+1转移到状态qj的概率。
这实际在表述一个一阶的HMM,所作的假设是每个状态只跟前一个状态有关。
B是观测概率矩阵:
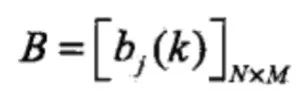
其中,
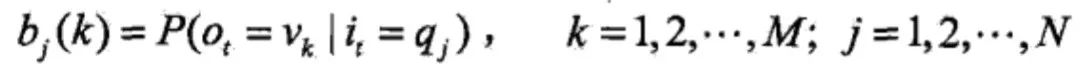
是在时刻t处于状态qj的条件下生成观测vk的概率。
π是初始状态概率向量:
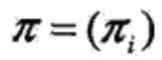
其中,
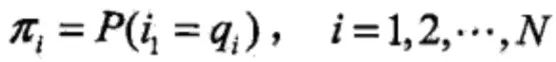
是时刻t=1处于状态qj的概率。
隐马尔可夫模型由初始状态概率向量π、状态转移概率矩阵A和观测概率矩阵B决定。π和A决定状态序列,B决定观测序列。因此,隐马尔可夫模型可以用三元符号表示,即
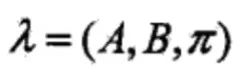
括号里的三个变量称为隐马尔可夫模型的三要素。加上一个具体的状态集合Q和观测序列V,则构成了HMM的五元组。
状态转移概率矩阵A与初始状态概率向量π确定了隐藏的马尔可夫链,生成不可观测的状态序列。观测概率矩阵B确定了如何从状态生成观测,与状态序列综合确定了如何产生观测序列。
从定义可知,隐马尔可夫模型作了两个基本假设:
(1)齐次马尔可夫性假设,即假设隐藏的马尔可夫链在任意时刻t的状态只依赖于其前一时刻的状态,与其他时刻的状态及观测无关。
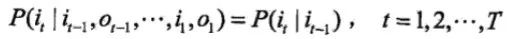
(2)观测独立性假设,即假设任意时刻的观测只依赖于该时刻的马尔可夫链的状态,与其他观测及状态无关。
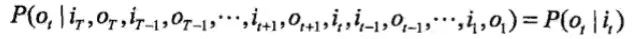
2 观测序列的生成过程
根据隐马尔可夫模型定义,将一个长度为T的观测序列O的生成过程描述如下:
观测序列的生成算法:
输入:隐马尔可夫模型,观测序列长度
输出:观测序列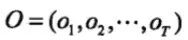
(1)按照初始状态分布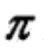 产生状态
产生状态
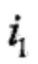
(2)令t=1
(3)按照状态的观测概率分布
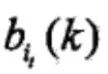 生成
生成
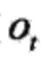
(4)按照状态的状态转移概率分布
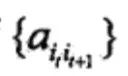 产生状态
产生状态
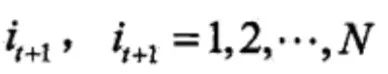
令t=t+1;如果t<T,则转步(3);否则,终止。
2.1 观测序列生成Python实现
算法首先初始化两个长度为T的向量,接着按照初始状态分布pi生成第一个状态,取出状态对应的观测的概率分布,生成一个观测。
接下来都是按前一个状态取出状态转移概率分布生成状态,再取出状态对应的观测的概率分布生成一个观测。重复该步骤就得到长度为T的观测和状态向量。
代码如下:
import numpy as npclass HMM(): def __init__(self, A, B, pi): self.A = A self.B = B self.pi = pi def simulate(self, T): # draw_from接受一个概率分布,然后生成该分布下的一个样本。 def draw_from(probs): return np.where(np.random.multinomial(1, probs) == 1)[0][0] observations = np.zeros(T, dtype=int) states = np.zeros(T, dtype=int) states[0] = draw_from(self.pi) observations[0] = draw_from(self.B[states[0], :]) for t in range(1, T): states[t] = draw_from(self.A[states[t-1], :]) observations[t] = draw_from(self.B[states[t], :]) return states, observations3 隐马尔可夫模型的3个基本问题
(1) 概率计算问题。给定模型 和观测序列
和观测序列
 ,计算在模型
,计算在模型
 下观测序列O出现的概率
下观测序列O出现的概率
 。
。
(2) 学习问题。己知观测序列,估计模型
参数,使得在该模型下观测序列概率
 最大。即用极大似然估计的方法估计参数。
最大。即用极大似然估计的方法估计参数。
(3) 预测问题,也称为解码(decoding)问题。已知模型和观测序列 ,求对给定观测序列条件概率 最大的状态序列
最大的状态序列  。即给定观测序列,求最有可能的对应的状态序列。
。即给定观测序列,求最有可能的对应的状态序列。
下面各节将逐一介绍这些基本问题的解法。
4 概率计算算法
这节介绍计算观测序列概率的前向(forward)与后向(backward)算法,前向后向算法就是求第一个状态的前向概率或最后一个状态的后向概率,然后向后或向前递推即可。
4.1 前向算法
前向概率给定隐马尔可夫模型 ,定义到时刻t为止的观测序列为
,定义到时刻t为止的观测序列为
 且状态为
且状态为
 的概率为前向概率,记作
的概率为前向概率,记作

可以递推地求得前向概率 及观测序列概率
及观测序列概率
 。
。
观测序列概率的前向算法:
输入:隐马尔可夫模型,观测序列
 ;
;
输出:观测序列概率。
(1)初值

前向概率的定义中一共限定了两个条件,一是到当前为止的观测序列,另一个是当前的状态。所以初值的计算也有两项(观测和状态),一项是初始状态概率,另一项是发生到当前观测的概率。
(2)递推对

每次递推同样由两部分构成,大括号中是当前状态为i且观测序列的前t个符合要求的概率,括号外的是状态i发生观测t+1的概率。
(3)终止

由于到了时间T,一共有N种状态发生了最后那个观测,所以最终的结果要将这些概率加起来。
4.2 前向算法Python实现
代码如下:
1def forward(self, obs_seq): 2 """前向算法""" 3 N = self.A.shape[0] 4 T = len(obs_seq) 5 F = np.zeros((N, T)) 6 F[:, 0] = self.pi * self.B[:, obs_seq[0]] 7 for t in range(1, T): 8 for n in range(N): 9 F[n, t] = np.dot(F[:, t-1], (self.A[:, n])) * self.B[n, obs_seq[t]]10 return F4.3 后向算法
后向算法相当于前向算法的反向递推,具体可查看书178页。
4.4 后向算法Python实现
代码如下:
1def backward(self, obs_seq): 2 """后向算法""" 3 N = self.A.shape[0] 4 T = len(obs_seq) 5 M = np.zeros((N, T)) 6 M[:, T-1] = 1 7 # 或者M[:, -1:] = 1,列上表示最后一行 8 for t in reversed(range(T-1)): 9 for n in range(N):10 M[n, t] = np.dot(self.A[n, :], M[:, t+1]) * self.B[n, obs_seq[t+1]]11 return M5 学习问题
Baum-Welch算法也就是EM算法,己知观测序列 ,估计模型 参数,使得在该模型下观测序列概率 最大。即用极大似然估计的方法估计参数。而如何解决这个估计问题这里采用Baum-Welch算法。
关于算法的详细解释可参考:https://blog.csdn.net/u014688145/article/details/53046765?locationNum=7&fps=1
5.1 Baum-Welch算法Python实现
代码如下:
1def EM(self, observation, criterion=0.05): 2 """EM算法进行参数学习""" 3 n_state = self.A.shape[0] 4 n_sample = len(observation) 5 done = 1 6 while done: 7 Alpha = self.forward(observation) 8 Beta = self.backward(observation) 9 xi = np.zeros((n_state, n_state, n_sample-1))10 gamma = np.zeros((n_state, n_sample))11 for t in range(n_sample-1):12 denom = np.sum(np.dot(Alpha[:, t].T, self.A) * self.B[:, observation[t+1]].T * Beta[:, t+1].T)13 sum_gamma1 = np.sum(Alpha[:, t] * Beta[:, t])14 for i in range(n_state):15 numer = Alpha[i, t] * self.A[i, :] * self.B[:, observation[t+1]].T * Beta[:, t+1].T16 xi[i, :, t] = numer/denom17 gamma[i, t] = Alpha[i, t] * Beta[i, t] / sum_gamma118 last_col = Alpha[:, n_sample-1].T * Beta[:, n_sample-1]19 gamma[:, n_sample-1] = last_col / np.sum(last_col)20 # 更新参数21 n_pi = gamma[:, 0]22 n_A = np.sum(xi, 2) / np.sum(gamma[:, :-1], 1)23 n_B = np.copy(self.B)24 num_level = self.B.shape[1]25 sum_gamma = 026 a = 027 for lev in range(num_level):28 for h in range(n_state):29 for t in range(n_sample):30 sum_gamma = sum_gamma + gamma[h, t]31 if observation[t] == lev:32 a = a + gamma[h, t]33 n_B[h, lev] = a / sum_gamma34 a = 035 # 检查阈值36 if np.max(np.abs(self.pi-n_pi)) < criterion and np.max(np.abs(self.B-n_B)) < criterion \37 and np.max(np.abs(self.A-n_A)) < criterion:38 done = 039 self.A, self.B, self.pi = n_A, n_B, n_pi40 return self.A, self.B, self.pi
6 预测算法
6.1 维特比算法
输入:模型 和观测
和观测
 ;
;
输出:最优路径 。
。
⑴初始化

(2)递推。对 

(3)终止

(4)最优路径回溯。对 

求得最优路径。
6.2 维特比算法Python实现
维特比算法是一种动态规划算法用于寻找最有可能产生观测事件序列的-维特比路径-隐含状态序列。维特比算法其实就是多步骤每步多选择模型的最优选择问题,其在每一步的所有选择都保存了前续所有步骤到当前步骤当前选择的最小总代价(或者最大价值)以及当前代价的情况下前继步骤的选择。依次计算完所有步骤后,通过回溯的方法找到最优选择路径。
代码如下:
1def viterbi(self, obs_seq): 2 """viterbi算法预测状态序列""" 3 N = self.A.shape[0] 4 T = len(obs_seq) 5 P = np.zeros((N, T)) 6 prev_point = np.zeros((N, T)) 7 prev_point[:, 0] = 0 8 P[:, 0] = self.pi * self.B[:, obs_seq[0]] 9 for t in range(1, T):10 for n in range(N):11 P[n, t] = np.max(P[:, t - 1] * self.A[:, n]) * self.B[n, obs_seq[t]]12 prev_point[n, t] = np.argmax(P[:, t - 1] * self.A[:, n] * self.B[n, obs_seq[t]])13 return P, prev_point6.3 最优路径生成Python实现
最优路径其实也是维特比算法的一部分,当已经确定了T时刻的最优状态i,接下来通过回溯的方式找到最优路径。
代码如下:
1def build_path(self, obs_seq): 2 """return the optimal path""" 3 P, prev_point = self.viterbi(obs_seq) 4 T = len(obs_seq) 5 opt_path = np.zeros(T) 6 last_state = np.argmax(P[:, T-1]) 7 opt_path[T-1] = last_state 8 for t in reversed(range(T-1)): 9 opt_path[t] = prev_point[int(opt_path[t+1]), t+1]10 last_path = reversed(opt_path)11 return last_path6.4 实践
用《统计学习方法》中的案例数据进行测试,代码如下:
1if __name__ == '__main__': 2 # 用《统计学习方法》中的案例进行测试 3 A = np.array([[0.5, 0.2, 0.3], [0.3, 0.5, 0.2], [0.2, 0.3, 0.5]]) 4 B = np.array([[0.5, 0.5], [0.4, 0.6], [0.7, 0.3]]) 5 pi = np.array([0.2, 0.4, 0.4]) 6 test1 = HMM(A, B, pi) 7 obs_seq = [0, 1, 0] 8 print(test1.forward(obs_seq)) 9 print(test1.backward(obs_seq))10 print(test1.viterbi(obs_seq))11 print(test1.build_path(obs_seq))12 print(test1.EM(obs_seq))参考:
-
李航. 统计学习方法[M]. 北京:清华大学出版社,2012
码农场.隐马尔可夫模型:http://www.hankcs.com/ml/hidden-markov-model.html