

文: 张丽斌
本文原创,转载请注明作者及出处
背景
随着沪江业务的高速发展,越来越多的产品运营开始关注数据驱动的精细化运营方法,期望通过精细化运营在一片红海中持续获得确定的用户增长、订单转化与收益,而 A/B 测试就是一种有效的精细化运营手段。
设计思路
要认识实验平台,首先要了解实验两个要素:
-
流量:流量即用户的访问,也是实验的样本来源。
-
参数:或者称作实验变量,一个实验可能有多种策略或者模型需要在线上进行比较,这些策略或者模型就称作实验参数。
为了更快的迭代产品,通常产品或运营会要求同一时间做N个实验,想要同一份流量不同实验之间互不干扰,每个实验都能得到100%流量。针对此,我们设计的实验平台分层模型借鉴了Google的论文《重叠实验:更多,更好,更快》,Overlapping Experiment Infrastructure:More, Better, Faster Experimentation。
-
更多:我们需要能同时进行多个实验的可扩展性。但也需要考虑灵活性:不同的实验需要不同的配置和不同的流量来衡量实验的统计意义上的效果显著性。有些实验只需要修改流量的一个子集,比如只是日语的流量,并需要取一个合理的流量规模。
-
更好:不合理的实验是不应该让它在线上流量进行的。指标数据不好的实验应该能很快的被捕获并且停止它的进行。
-
更快:能够很容易并且很快地建立一个实验。容易到非工程师不需要写代码就可以创建一个实验。评价指标应该很快的被统计出来,以便决策。另外,实验系统不仅支持实验,并且可以快速缩量和扩量。更快同时也体现在实验结果的显著性能更快的呈现,这时候我们就需要充分的样本。
为了实现同时做更多的实验以及实现流量复用,我们经过考量,采用如下的分层模型:

关于分层模型有三个关键的概念:
-
域(domain)是指流量的一个划分,流量进来首先是划分域。
-
层(layer)是指系统参数的一个子集。
-
实验(experiment)是由多个策略参数构成的,最终用户只会命中其中之一的过程。
上述分层模型先将流量分为两个域,一个域只有一个单一层(非重叠域),和一个有三个层的重叠域,在这种情况下,每个请求会分到非重叠域或是重叠域。请求只能在非重叠域或重叠域其中之一。
如果请求在重叠域,那么请求最多在一个实验中(这个实验可以改变参数集合中的任意参数的值),如果请求在重叠域,那么请求最多在三个实验中,每层一个实验。流量在每一层都会被重新打散。并且对于每个实验,只能使用对应层的参数。
该分层模型的主要思想为:
-
同一实验的策略参数位于同一层;
-
相互独立的策略参数分属于不同的实验层;
-
不同实验层间进行独立的流量划分和独立的实验,互不影响。
上述重叠域是一个三层实验,第一层UI Layer有三个实验参数,Red、Blue、Green。当在实验平台配置配置好参数及其流量后,我们会按总计100桶分配给三个参数各自的bucket区间,比如 Red、Blue、Green 分别流量配置为 80%,10%,10%,那么各自对应的是bucket区间分别是 0-79, 80-89, 90-99。后面的 Search Results Layer、 Ads Results Layer依次类推。
当流量进来后,实验分流服务会根据不同终端采用不同的用户标识id来hash分流,web端采用 cookieId ,app端采用设备id,小程序端采用 openID 作为唯一标识符。具体进行流量划分时,为了实现实验层之间流量划分的正交性,会将流量标识信息和实验层标识一起进行实验流量 bucket 划分, 实验层标识 salt 称为离散因子。如基于用户标识(uid)的流量划分:
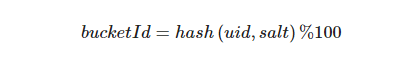
当然,为了便于内测等,我们也实现了白名单功能,运营或者产品可以通过后台配置某用户命中某个特定的实验参数。
在实际线上运行ab测试的时候,我们经常需要针对某个实验参数做流量的扩量或者缩量,比如三个实验参数A、B、C,线上数据发现A的指标相对最好,我们会逐步的针对C扩量,其他做相应的缩量。
假设有三个实验参数A、B、C,假设总 bucket size 为100,A、B、C初始流量为:80%,10%,10%。假设 C 扩张 10% 的流量至 20%,有一种可能,切换之后流量分布如下表:
| 实验变量 | A | B | C |
|---|---|---|---|
| 切换前bucket区间 | 0-79 | 80-89 | 90-99 |
| 切换后bucket区间 | 0-74 | 75-79 | 80-99 |
切换之后实际上A,B和C覆盖的用户人群都发生了变化,A、B分别减少了 5%,其实更佳的扩缩量方案是:B流量不变,C从A切换 10% 流量过去,这样可以尽量减少对覆盖用户人群参与实验的变化,从而保证实验数据更加科学。针对此,我们设计一套算法在调整流量时可以做到尽量保证更小的变动,尽可能挪动更小的用户群体。
实验平台架构
目前沪江实验平台主要包括以下 4 个功能模块:
-
实验管理:允许用户对实验进行配置和管理。
-
流量管理:对实验参数分配流量配置。
-
数据收集:客户端上报数据,最终落到BI部门Hadoop集群
-
数据分析:对上报的数据进行分析以及计算置信区间等,最后通过报表的形式进行展示。
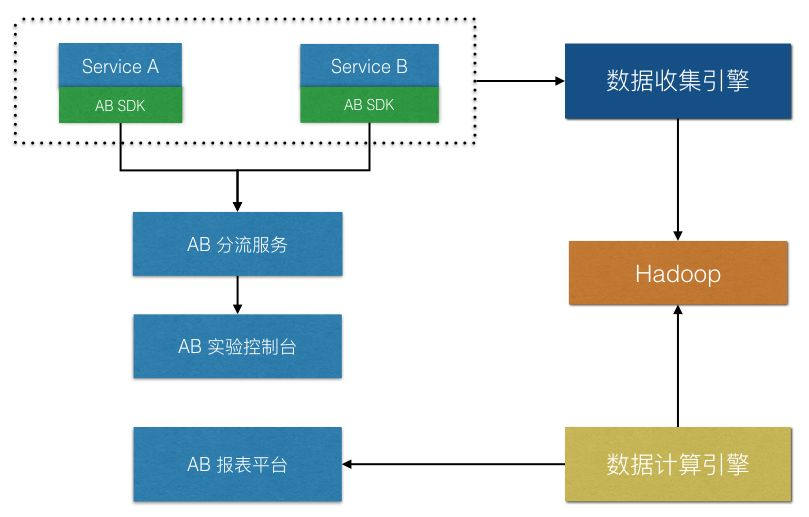
整体架构大致如下:
-
产品或者开发通过AB实验控制台配置实验方案及流量分配,配置同时入库
-
AB分流服务启动时初始化从DB拉取实验配置加载入内存,如实验配置发生变更,AB分流服务将定时拉取DB中配置信息
-
业务方请求AB分流服务获取分流策略
-
业务方上报打点数据给BI
-
AB报表平台读取BI离线或者实时统计的数据指标并做P值检验和置信区间计算
实验指标
我们现在已经覆盖沪江常用的指标,订单转化、留存(次日留存、三日留存、七日留存等)、点击转化率等核心指标。这些指标只需要在实验平台后台配置一下(如下图所示),T+1日就会自动生成指标报告。
实验指标配置示例如下:
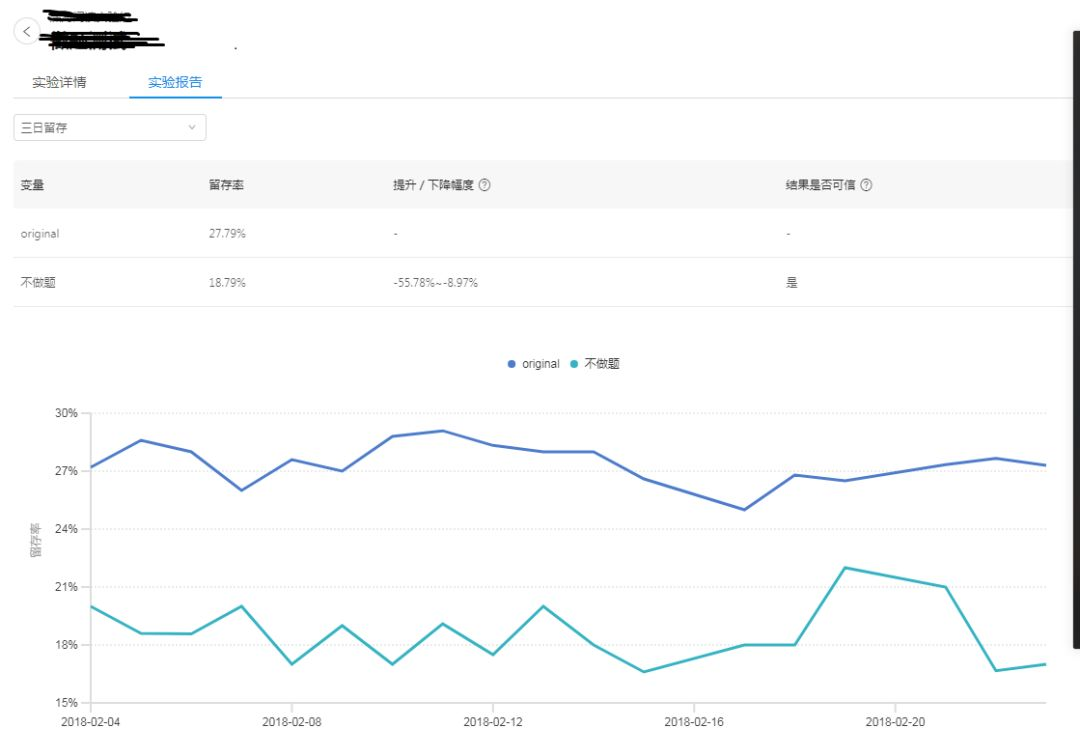
某业务留存数据示例如下:
实验指标我们不仅给出了均值与每日走势,针对两个版本或者多个版本,我们也给出了与对照版本的置信区间和置信度。那么到底什么是置信区间呢?这其实关系到实验数据的科学性。
实验科学性
假设某业务算法优化的 AB Test 的点击数据如下:
| 实验变量 | 点击率 | UV |
|---|---|---|
| algo1 | 0.35 | 230111 |
| algo2 | 0.34 | 229136 |
纯粹从数字上看,algo1算法的点击率是0.35,algo2的点击率是0.34。是不是就意味着algo1的效果就好于algo2呢,这并不一定,实验是抽样进行的,样本量大小和某些偶然因素,比如某天的数据algo1远高于algo2,导致均值比algo2略高。所以我们需要一套科学的统计手段来比较两个版本孰优孰劣。我们现在采用的是P值检验和置信区间来判断方案的优劣。
P-value(P值检验)
首先要了解P 值检验,我们首先需要了解下假设实验,在实验验过程中存在2个假设。
-
原假设:我们希望通过实验结果推翻的假设,如两个版本没有明显差异
-
备择假设:我们希望通过实验结果验证的假设,如两个版本有明显差异
P 值检验就是在零假设成立的条件下,获得和观察到的数据一致,或者更加极端情况的概率。p值越小,说明原假设越不成立,因为概率太小了。假设 P 值 0.04, 那么意味着如果原假设为真,我们通过抽样得到观察到的样本数据的可能性只有 4%,这时我们有理由推翻原假设,选择备择假设。
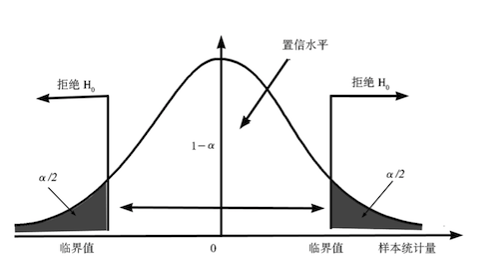
通常情况下,在统计学上有一个概率值 α ,也称为显著性水平,当 P 值小于 α ,即可以推翻原假设,选择备择假设。α 可以选择为 0.05,0.1等。我们选择的是比较常用的 0.05 。
根据中心极限定理,在样本量达到一定量时,大量相互独立随机变量的均值经适当标准化后分布收敛于正态分布:
由于样本量大,我们可以采用Z检验。另外,对于较小的样本集合,我们可以依赖于T检验。通常我们通过Z值推导P值,AB测试计算Z值的计算公式为:

计算出Z值我们可以根据正态分布Z值表查询到对应的P值。
置信区间
置信区间概念
置信区间(Confidence Interval)是用来对一个概率样本的总体参数进行区间估计的样本均值范围,它展现了这个均值范围包含总体参数的概率,这个概率称为置信水平。
置信水平代表了估计的可靠度,一般而言,我们采用 95% 的置信水平进行区间估计。
置信区间在A/B测试中的意义
在实验运行一段时间之后,如果置信区间的上下限同为正,说明实验结果是统计显著的,并且实验版本优于对照版本;如果同为负,实验结果也是统计显著的,但是实验版本劣于对照版本;如果置信区间为一正一负,则说明版本间差异不大。
在上图中,从我们针对公司某款小程序产品做关于做题对用户留存率影响的ab数据指标看,不做题的置信区间是【-55.78%,-8.97%】。这个数据说明: 不做题版本不如做题版本,并且有95%的可能性是差了55.78%到8.97%之间。
置信区间的计算方法
由前面计算得出的Z 值,再根据两个总体的均值、标准差和样本大小,利用以下公式即可求出两个总体均值差的95%置信区间。
由前面计算得出的Z值,再根据两个总体的均值、标准差和样本大小,利用以下公式即可求出两个总体均值差的95%置信区间。

从公式看,如果要缩小置信区间的范围,可以通过加大样本量来做AB Test。
总结
-
ABTest 重在比对不同方案的指标数据,在不同方案的设计上也需要有明确的产品思路差异。
-
在指标跟踪上,也需要设计核心明确的指标来跟踪。
-
在数据采集上尽量针对每个环节设计好完善的埋点机制,便于后续分析新老版本的差异。
参考资料
-
分层实验平台基石 Google论文:https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/36500.pdf
-
在线AB置信区间计算:https://abtestguide.com/calc/
-
置信区间:https://onlinecourses.science.psu.edu/statprogram/reviewofbasic_statistics/
-
P值检验:https://www.statsdirect.com/help/basics/p_values.htm

推荐阅读
从 SQL Server 到 MySQL(二):在线迁移,空中换发动机


