

前言
采用 数据驱动迁移反模式 主要发生在当你从一个 单体应用 向 微服务架构 做迁移的时候。之所以称之为反模式主要原因是,刚开始我们觉得创建微服务是一个不错的主意,服务和相应的数据 都独立成 微服务,但这可能会将你带向一个错误的道路上,导致高风险、过剩成本和额外的迁移工作。
正文
数据驱动的迁移反模式
微服务会创建 大量小的、分布式的、单一用途 的服务,每个服务拥有自己的数据。这种 服务和数据耦合 支持一个 有界的上下文 和 一个无共享数据 的架构。其中,每个服务及其对应的数据是独立一块,完全独立于所有其他服务。服务只暴露了一个明确的接口(服务契约)。有界的上下文可以允许开发者以最小的依赖快速轻松地开发,测试和部署。
采用 数据驱动迁移反模式 主要发生在当你从一个 单体应用 向 微服务架构 做迁移的时候。我们之所以称之为反模式主要原因是,刚开始我们觉得创建微服务是一个不错的主意,服务和相应的数据 都独立成 微服务,但这可能会将你带向一个错误的道路上,导致高风险、过剩成本和额外的迁移工作。
单体应用迁移到微服务架构有两个主要目标:
-
第一个目标是单体应用程序的 功能 分割成 小的,单一用途 的服务。
-
第二个目标是单体应用的 数据 迁移到每个服务自己 独占的小数据库(或独立的服务)。
下图展示了一个典型的迁移,看起来像服务代码和相应的数据同时进行迁移。
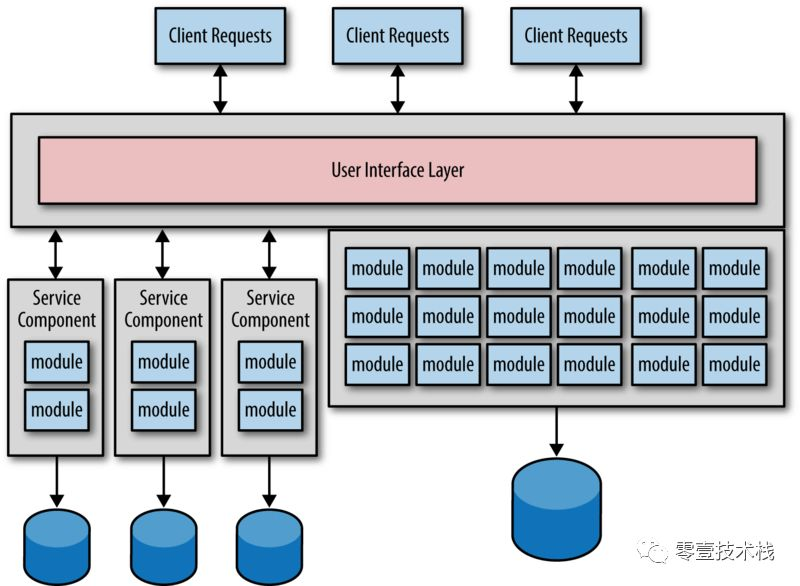
上图中有三个服务是从单体应用中划分而来,并且还划分独立的三个数据库,这是一个自然演变的过程,因为在每个 服务 和 数据库 之间都使用了最为关键的 限界上下文,然而我们遇到的问题也正是基于这一过程将带领我们进入 数据迁移的反模式。
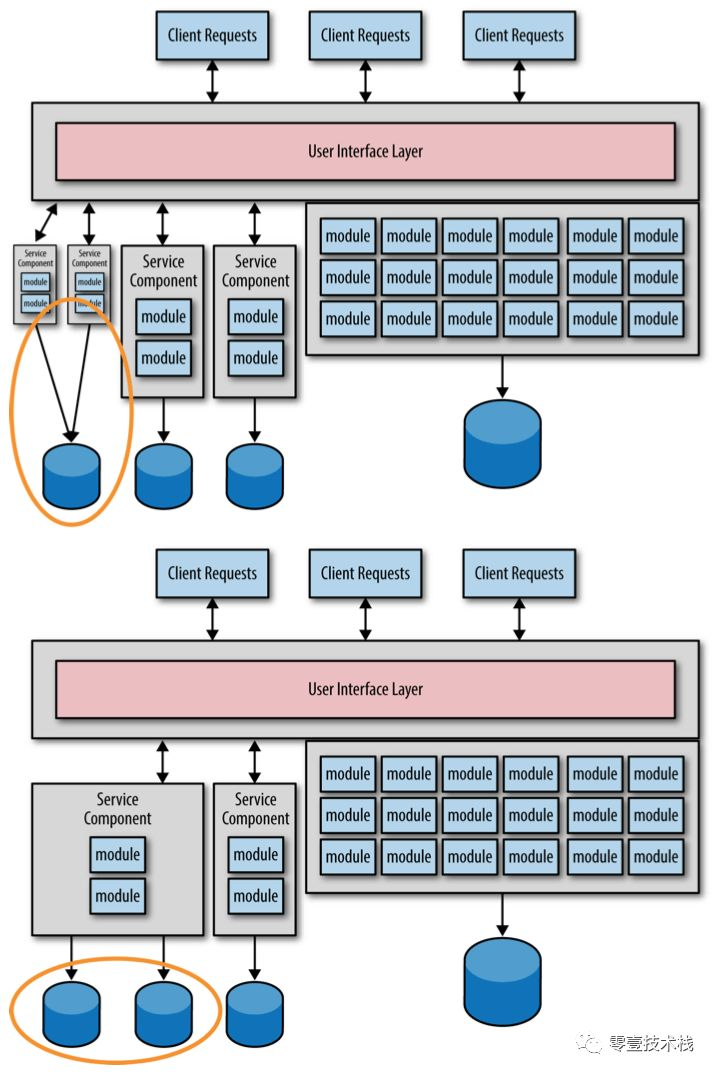
1. 太多的数据迁移
这种迁移路径的主要问题是,我们很难在一次就能够划分清楚每个服务的粒度。从一个 更粗粒度 的服务开始着手,一步步的进行 细化工作,并且要多了解相关业务知识,不断的 对服务的粒度进行调整。
我们来看图 1-1 发现最左边的 服务粒度太粗,需要再 拆分 成二个小的服务,或者你发现左边的二个 服务粒度划分的太细,需要进行 合并。而 数据迁移 要比 源代码迁移 更复杂,更容易出错,我们最好只为数据进行一次迁移工作,因为数据迁移是一个 高风险 的工作。
我们的微服务划分也就是应用代码的迁移和数据的迁移。如图 1-2 所示。
2. 功能分割优先,数据迁移最后
此模式主要采用的是一种避免的手段,以 迁移服务的功能 为第一,同时也需要注意服务和数据之间的 限界上下文。我们可以通过 合并 与 拆分 的手段对服务进行调整直到满意为止,这时候就可以进行 数据迁移。
如图 1-3 所示,左边所有三个服务都已经进行了 迁移 和 拆分,但是所有服务仍然使用的是 同一个数据库。如果这是一个临时中间方案还可以作为一个选择,这时候我们就需要更多的了解服务如何使用,以及接受什么类型的请求数据等。
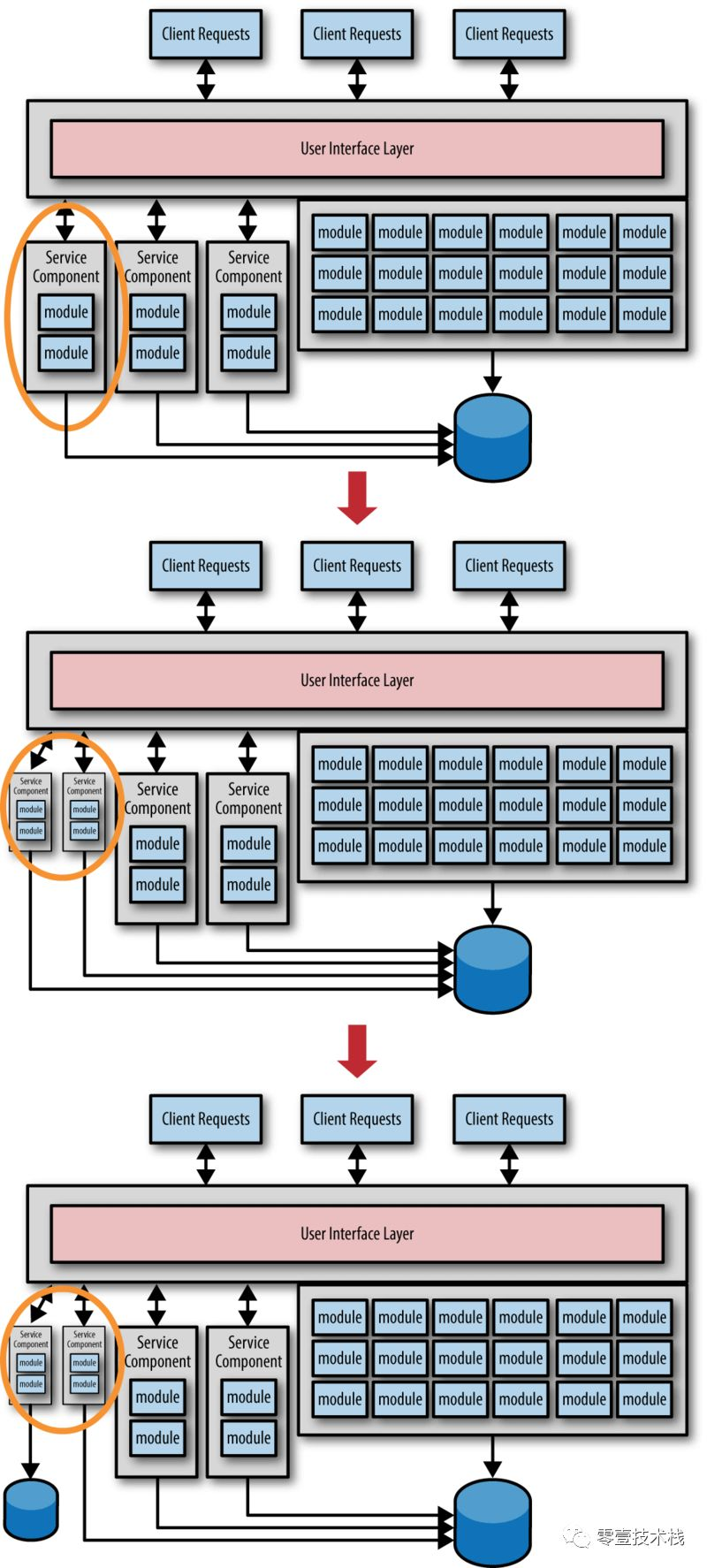
在图 1-3 中,我们要注意最左边的服务是如何发现 粒度太粗 而 拆分 成两个服务的。服务粒度最终确定完成之后,下一步就开始 迁移数据 了,采用这种方式可以避免重复的数据迁移。
后续
-
微服务的反模式和陷阱(一) - 数据驱动的迁移反模式
-
微服务的反模式和陷阱(二) - 超时反模式
-
微服务的反模式和陷阱(三) - 共享反模式
-
微服务的反模式和陷阱(四) - 到达报告反模式
-
微服务的反模式和陷阱(五) - 沙粒陷阱
-
微服务的反模式和陷阱(六) - 无因的开发者陷阱
-
微服务的反模式和陷阱(七) - 随大流陷阱
-
微服务的反模式和陷阱(八) - 其它架构模式
-
微服务的反模式和陷阱(九) - 静态契约陷阱
-
微服务的反模式和陷阱(十) - 通信协议使用的陷阱
欢迎关注公众号: 零壹技术栈

本帐号将持续分享后端技术干货,包括虚拟机基础,多线程编程,高性能框架,异步、缓存和消息中间件,分布式和微服务,架构学习和进阶等学习资料和文章。
