

延续本篇过往手动安裝方式来部署Kubernetes v1.11.x版本的高可用集群,而此次教学将直接通过裸机进行部署Kubernetes集群。以手动安装的目标是学习Kubernetes各部件,流程,设定与部署方式。若不想这么累的话,可以参考挑选正确的解决方案来选择自己最喜欢的方式。
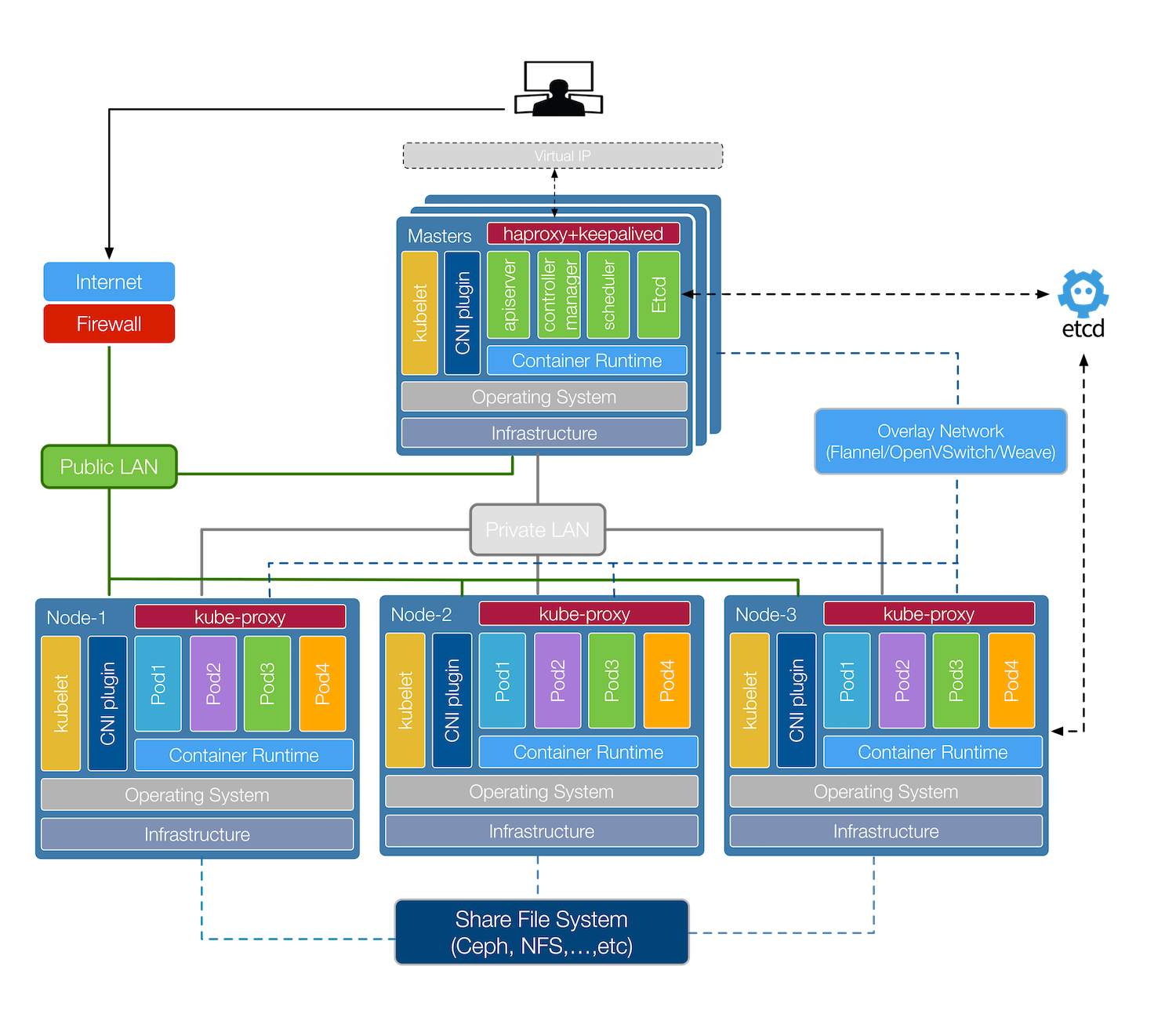
Kubernetes部署信息
Kubernetes部署的版本信息:
- Kubernetes:v1.11.0
- CNI:v0.7.1
- Etcd:v3.3.8
- Docker:v18.05.0-ce
- 印花布:v3.1
Kubernetes部署的网路信息:
- 群集IP CIDR:10.244.0.0/16
- 服务群集IP CIDR:10.96.0.0/12
- 服务DNS IP:10.96.0.10
- DNS DN:cluster.local
- Kubernetes API VIP:172.22.132.9
- Kubernetes Ingress VIP:172.22.132.8
节点信息
本教学采用以下节点数与机器规格进行部署裸机(Bare-metal),操作系统采用Ubuntu 16+(理论上CentOS 7+也行)进行测试:
| IP地址 | 主机名 | 中央处理器 | 记忆 | 额外设备 |
|---|---|---|---|---|
| 172.22.132.10 | K8S-M1 | 4 | 16G | 没有 |
| 172.22.132.11 | K8S-M2 | 4 | 16G | 没有 |
| 172.22.132.12 | K8S-M3 | 4 | 16G | 没有 |
| 172.22.132.13 | K8S-G1 | 4 | 16G | GTX 1060 3G |
| 172.22.132.14 | K8S-G2 | 4 | 16G | GTX 1060 3G |
另外由所有主节点提供一组VIP 172.22.132.9。
- 这边m为主要控制节点,g为GPU工作节点(因为我的环境节点剩两台有显卡的可以用)。
- 操作所有全部用root使用者进行,主要方便部署。
事前准备
开始部署集群前需先确保以下条件已达成:
- 所有节点彼此网路互通,并且k8s-m1SSH 登录其他节点为passwdless,由于过程中很多会在某台节点(k8s-m1)上以SSH复制与操作其他节点。
- 确认所有防火墙与SELinux已关闭。如CentOS:
$ systemctl stop firewalld && systemctl disable firewalld
$ setenforce 0
$ vim /etc/selinux/config
SELINUX=disabled关闭是为了方便安装使用,若有需要防火墙可以参考所需的端口来设定。
- 所有节点设定需要/etc/hosts解析到所有集群中主机。
...
172.22.132.10 k8s-m1
172.22.132.11 k8s-m2
172.22.132.12 k8s-m3
172.22.132.13 k8s-g1
172.22.132.14 k8s-g2- 所有节点需要安装Docker CE版本的容器引擎:
$ curl -fsSL https://get.docker.com/ | sh不管是在Ubuntu或CentOS都只需要执行该指令就会自动安装最新版Docker.CentOS
安装完成后,需要再执行以下指令:$ systemctl enable docker && systemctl start docker
- 所有节点需要设定以下系统参数。
$ cat <<EOF | tee /etc/sysctl.d/k8s.conf
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
$ sysctl -p /etc/sysctl.d/k8s.conf关于bridge-nf-call-iptables的启用取决于是否将容器连接到Linux bridge或使用其他一些机制(如SDN vSwitch)。
- Kubernetes v1.8 +要求关闭系统Swap,请在所有节点利用以下指令关闭:
$ swapoff -a && sysctl -w vm.swappiness=0
# 不同文件会有差异
$ sed '/swap.img/d' -i /etc/fstab记得/etc/fstab也要注解掉SWAP挂载。
- 在所有节点下载Kubernetes二进制执行文件:
$ export KUBE_URL=https://storage.googleapis.com/kubernetes-release/release/v1.11.0/bin/linux/amd64
$ wget ${KUBE_URL}/kubelet -O /usr/local/bin/kubelet
$ chmod +x /usr/local/bin/kubelet
# Node 可忽略下載 kubectl
$ wget ${KUBE_URL}/kubectl -O /usr/local/bin/kubectl
$ chmod +x /usr/local/bin/kubectl- 在所有节点下载Kubernetes CNI二进制执行文件:
$ export CNI_URL=https://github.com/containernetworking/plugins/releases/download
$ mkdir -p /opt/cni/bin && cd /opt/cni/bin
$ wget -qO- --show-progress "${CNI_URL}/v0.7.1/cni-plugins-amd64-v0.7.1.tgz" | tar -zx- 在k8s-m1节点安装cfssl工具,这将会用来建立CA,并产生TLS凭证。
$ export CFSSL_URL=https://pkg.cfssl.org/R1.2
$ wget ${CFSSL_URL}/cfssl_linux-amd64 -O /usr/local/bin/cfssl
$ wget ${CFSSL_URL}/cfssljson_linux-amd64 -O /usr/local/bin/cfssljson
$ chmod +x /usr/local/bin/cfssl /usr/local/bin/cfssljson建立CA与产生TLS凭证
本节将会通过CFSSL工具来产生不同组件的凭证,如Etcd,Kubernetes API服务器等等,其中各组件都会有一个根数位凭证认证机构(Root Certificate Authority)被用在组件之间的认证。
要注意CA JSON档中的CN(Common Name)与O(Organization)等内容是会影响Kubernetes认证的。
首先在k8s-m1通过Git取得部署用文件:
$ git clone https://github.com/kairen/k8s-manual-files.git ~/k8s-manual-files
$ cd ~/k8s-manual-files/pkiETCD
在k8s-m1建立/etc/etcd/ssl资料,并产生Etcd CA:
$ export DIR=/etc/etcd/ssl
$ mkdir -p ${DIR}
$ cfssl gencert -initca etcd-ca-csr.json | cfssljson -bare ${DIR}/etcd-ca接着产生Etcd凭证:
$ cfssl gencert \
-ca=${DIR}/etcd-ca.pem \
-ca-key=${DIR}/etcd-ca-key.pem \
-config=ca-config.json \
-hostname=127.0.0.1,172.22.132.10,172.22.132.11,172.22.132.12 \
-profile=kubernetes \
etcd-csr.json | cfssljson -bare ${DIR}/etcd-hostname需修改成所有masters节点。
删除不必要的文件,检查并/etc/etcd/ssl目录是否成功建立以下文件:
$ rm -rf ${DIR}/*.csr
$ ls /etc/etcd/ssl
etcd-ca-key.pem etcd-ca.pem etcd-key.pem etcd.pem复制文件至其他Etcd节点,这边为所有master节点:
$ for NODE in k8s-m2 k8s-m3; do
echo "--- $NODE ---"
ssh ${NODE} " mkdir -p /etc/etcd/ssl"
for FILE in etcd-ca-key.pem etcd-ca.pem etcd-key.pem etcd.pem; do
scp /etc/etcd/ssl/${FILE} ${NODE}:/etc/etcd/ssl/${FILE}
done
doneKubernetes组件
在k8s-m1建立/etc/kubernetes/pki,并依据下面指令来产生CA:
$ export K8S_DIR=/etc/kubernetes
$ export PKI_DIR=${K8S_DIR}/pki
$ export KUBE_APISERVER=https://172.22.132.9:6443
$ mkdir -p ${PKI_DIR}
$ cfssl gencert -initca ca-csr.json | cfssljson -bare ${PKI_DIR}/ca
$ ls ${PKI_DIR}/ca*.pem
/etc/kubernetes/pki/ca-key.pem /etc/kubernetes/pki/ca.pemKUBE_APISERVER这边设定为VIP位址。
接着依照以下小节来建立TLS凭证。
API服务器
通过以下指令产生Kubernetes API Server凭证:
$ cfssl gencert \
-ca=${PKI_DIR}/ca.pem \
-ca-key=${PKI_DIR}/ca-key.pem \
-config=ca-config.json \
-hostname=10.96.0.1,172.22.132.9,127.0.0.1,kubernetes.default \
-profile=kubernetes \
apiserver-csr.json | cfssljson -bare ${PKI_DIR}/apiserver
$ ls ${PKI_DIR}/apiserver*.pem
/etc/kubernetes/pki/apiserver-key.pem /etc/kubernetes/pki/apiserver.pem这边-hostname的10.96.0.1的英文群集IP的Kubernetes端点; 172.22.132.9为VIP位址; kubernetes.default为Kubernetes系统在默认命名空间自动建立的API服务的域名。
前代理客户端
此凭证将被用于Authenticating Proxy的功能上,而该功能主要是提供API Aggregation的认证。首先通过以下指令产生CA:
$ cfssl gencert -initca front-proxy-ca-csr.json | cfssljson -bare ${PKI_DIR}/front-proxy-ca
$ ls ${PKI_DIR}/front-proxy-ca*.pem
/etc/kubernetes/pki/front-proxy-ca-key.pem /etc/kubernetes/pki/front-proxy-ca.pem接着产生前代理客户端凭证:
$ cfssl gencert \
-ca=${PKI_DIR}/front-proxy-ca.pem \
-ca-key=${PKI_DIR}/front-proxy-ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
front-proxy-client-csr.json | cfssljson -bare ${PKI_DIR}/front-proxy-client
$ ls ${PKI_DIR}/front-proxy-client*.pem
/etc/kubernetes/pki/front-proxy-client-key.pem /etc/kubernetes/pki/front-proxy-client.pem控制器
凭证会建立system:kube-controller-manager的使用者(凭证CN),并且绑定在RBAC集群角色中的system:kube-controller-manager来让控制器管理器能够存取需要的API对象。这边通过以下指令产生Controller Manager凭证:
$ cfssl gencert \
-ca=${PKI_DIR}/ca.pem \
-ca-key=${PKI_DIR}/ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
manager-csr.json | cfssljson -bare ${PKI_DIR}/controller-manager
$ ls ${PKI_DIR}/controller-manager*.pem
/etc/kubernetes/pki/controller-manager-key.pem /etc/kubernetes/pki/controller-manager.pem接着利用kubectl来产生Controller Manager的kubeconfig档:
$ kubectl config set-cluster kubernetes \
--certificate-authority=${PKI_DIR}/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${K8S_DIR}/controller-manager.conf
$ kubectl config set-credentials system:kube-controller-manager \
--client-certificate=${PKI_DIR}/controller-manager.pem \
--client-key=${PKI_DIR}/controller-manager-key.pem \
--embed-certs=true \
--kubeconfig=${K8S_DIR}/controller-manager.conf
$ kubectl config set-context system:kube-controller-manager@kubernetes \
--cluster=kubernetes \
--user=system:kube-controller-manager \
--kubeconfig=${K8S_DIR}/controller-manager.conf
$ kubectl config use-context system:kube-controller-manager@kubernetes \
--kubeconfig=${K8S_DIR}/controller-manager.conf调度
凭证会建立system:kube-scheduler的使用者(凭证CN),并且绑定在RBAC集群角色中的system:kube-scheduler来让调度程序能够存取需要的API对象。这边通过以下指令产生调度程序凭证:
$ cfssl gencert \
-ca=${PKI_DIR}/ca.pem \
-ca-key=${PKI_DIR}/ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
scheduler-csr.json | cfssljson -bare ${PKI_DIR}/scheduler
$ ls ${PKI_DIR}/scheduler*.pem
/etc/kubernetes/pki/scheduler-key.pem /etc/kubernetes/pki/scheduler.pem接着利用kubectl来产生Scheduler的kubeconfig文件:
$ kubectl config set-cluster kubernetes \
--certificate-authority=${PKI_DIR}/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${K8S_DIR}/scheduler.conf
$ kubectl config set-credentials system:kube-scheduler \
--client-certificate=${PKI_DIR}/scheduler.pem \
--client-key=${PKI_DIR}/scheduler-key.pem \
--embed-certs=true \
--kubeconfig=${K8S_DIR}/scheduler.conf
$ kubectl config set-context system:kube-scheduler@kubernetes \
--cluster=kubernetes \
--user=system:kube-scheduler \
--kubeconfig=${K8S_DIR}/scheduler.conf
$ kubectl config use-context system:kube-scheduler@kubernetes \
--kubeconfig=${K8S_DIR}/scheduler.conf管理员
管理员用来绑定RBAC集群角色集群管理员,当想要操作所有Kubernetes集群功能时,就必须利用这边产生的kubeconfig文件。这边通过以下指令产生Kubernetes管理凭证:
$ cfssl gencert \
-ca=${PKI_DIR}/ca.pem \
-ca-key=${PKI_DIR}/ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
admin-csr.json | cfssljson -bare ${PKI_DIR}/admin
$ ls ${PKI_DIR}/admin*.pem
/etc/kubernetes/pki/admin-key.pem /etc/kubernetes/pki/admin.pem接着利用kubectl来产生Admin的kubeconfig文件:
$ kubectl config set-cluster kubernetes \
--certificate-authority=${PKI_DIR}/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${K8S_DIR}/admin.conf
$ kubectl config set-credentials kubernetes-admin \
--client-certificate=${PKI_DIR}/admin.pem \
--client-key=${PKI_DIR}/admin-key.pem \
--embed-certs=true \
--kubeconfig=${K8S_DIR}/admin.conf
$ kubectl config set-context kubernetes-admin@kubernetes \
--cluster=kubernetes \
--user=kubernetes-admin \
--kubeconfig=${K8S_DIR}/admin.conf
$ kubectl config use-context kubernetes-admin@kubernetes \
--kubeconfig=${K8S_DIR}/admin.confKubelet
这边使用节点授权者来让节点的kubelet能够存取服务,端点等API,而使用节点授权者需定义system:nodes群组(凭证的组织),并且包含system:node:<nodeName>的使用者名称(凭证的公用名)。
首先在k8s-m1节点产生所有master节点的kubelet凭证,这边通过下面脚本来产生:
$ for NODE in k8s-m1 k8s-m2 k8s-m3; do
echo "--- $NODE ---"
cp kubelet-csr.json kubelet-$NODE-csr.json;
sed -i "s/\$NODE/$NODE/g" kubelet-$NODE-csr.json;
cfssl gencert \
-ca=${PKI_DIR}/ca.pem \
-ca-key=${PKI_DIR}/ca-key.pem \
-config=ca-config.json \
-hostname=$NODE \
-profile=kubernetes \
kubelet-$NODE-csr.json | cfssljson -bare ${PKI_DIR}/kubelet-$NODE;
rm kubelet-$NODE-csr.json
done
$ ls ${PKI_DIR}/kubelet*.pem
/etc/kubernetes/pki/kubelet-k8s-m1-key.pem /etc/kubernetes/pki/kubelet-k8s-m2.pem
/etc/kubernetes/pki/kubelet-k8s-m1.pem /etc/kubernetes/pki/kubelet-k8s-m3-key.pem
/etc/kubernetes/pki/kubelet-k8s-m2-key.pem /etc/kubernetes/pki/kubelet-k8s-m3.pem产生完成后,将kubelet凭证复制到所有master节点上:
$ for NODE in k8s-m1 k8s-m2 k8s-m3; do
echo "--- $NODE ---"
ssh ${NODE} "mkdir -p ${PKI_DIR}"
scp ${PKI_DIR}/ca.pem ${NODE}:${PKI_DIR}/ca.pem
scp ${PKI_DIR}/kubelet-$NODE-key.pem ${NODE}:${PKI_DIR}/kubelet-key.pem
scp ${PKI_DIR}/kubelet-$NODE.pem ${NODE}:${PKI_DIR}/kubelet.pem
rm ${PKI_DIR}/kubelet-$NODE-key.pem ${PKI_DIR}/kubelet-$NODE.pem
done接着利用kubectl来产生kubelet的kubeconfig文件,这边通过脚本来产生所有master节点的文件:
$ for NODE in k8s-m1 k8s-m2 k8s-m3; do
echo "--- $NODE ---"
ssh ${NODE} "cd ${PKI_DIR} && \
kubectl config set-cluster kubernetes \
--certificate-authority=${PKI_DIR}/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${K8S_DIR}/kubelet.conf && \
kubectl config set-credentials system:node:${NODE} \
--client-certificate=${PKI_DIR}/kubelet.pem \
--client-key=${PKI_DIR}/kubelet-key.pem \
--embed-certs=true \
--kubeconfig=${K8S_DIR}/kubelet.conf && \
kubectl config set-context system:node:${NODE}@kubernetes \
--cluster=kubernetes \
--user=system:node:${NODE} \
--kubeconfig=${K8S_DIR}/kubelet.conf && \
kubectl config use-context system:node:${NODE}@kubernetes \
--kubeconfig=${K8S_DIR}/kubelet.conf"
done服务帐户密钥
Kubernetes控制管理器利用密钥对来产生与签署服务帐户的令牌,而这边不通过CA做认证,而是建立一组公私来源让API服务器与控制器理器使用:
$ openssl genrsa -out ${PKI_DIR}/sa.key 2048
$ openssl rsa -in ${PKI_DIR}/sa.key -pubout -out ${PKI_DIR}/sa.pub
$ ls ${PKI_DIR}/sa.*
/etc/kubernetes/pki/sa.key /etc/kubernetes/pki/sa.pub删除不必要文件
当所有文件建立与产生完成后,将一些不必要文件删除:
$ rm -rf ${PKI_DIR}/*.csr \
${PKI_DIR}/scheduler*.pem \
${PKI_DIR}/controller-manager*.pem \
${PKI_DIR}/admin*.pem \
${PKI_DIR}/kubelet*.pem复制文件至其他节点
凭证将复制到其他master节点:
$ for NODE in k8s-m2 k8s-m3; do
echo "--- $NODE ---"
for FILE in $(ls ${PKI_DIR}); do
scp ${PKI_DIR}/${FILE} ${NODE}:${PKI_DIR}/${FILE}
done
done复制kubeconfig文件至其他master节点:
$ for NODE in k8s-m2 k8s-m3; do
echo "--- $NODE ---"
for FILE in admin.conf controller-manager.conf scheduler.conf; do
scp ${K8S_DIR}/${FILE} ${NODE}:${K8S_DIR}/${FILE}
done
doneKubernetes大师赛
本节将说明如何部署与设定Kubernetes Master角色中的各组件,在开始前先简单了解一下各组件功能:
- kubelet:负责管理容器的生命周期,定期从API服务器取得节点上的预期状态(如网路,储存等等配置)资源,并呼叫对应的容器介面(CRI,CNI等)来达成这个状态。任何Kubernetes节点都会拥有该组件。
- kube-apiserver:以REST API提供Kubernetes资源的CRUD,如授权,认证,存取控制与API注册等机制。
- kube-controller-manager:通过核心控制循环(Core Control Loop)监听Kubernetes API的资源来维护集群的状态,这些资源会被不同的控制器所管理,如复制控制器,命名空间控制器等等。而这些控制器会处理着自动扩展,滚动更新等等功能。
- kube-scheduler:负责将一个(或多个)容器依据排程策略分配到对应节点上让容器引擎(如Docker)执行。而排程受到QoS要求,软硬体约束,亲和性(Affinity)等等规范影响。
- Etcd:用来保存集群所有状态的Key / Value储存系统,所有Kubernetes组件会通过API Server来跟Etcd进行沟通来保存或取得资源状态。
- HAProxy:提供多个API服务器的负载平衡(负载平衡)。
- Keepalived:建立一个虚拟IP(VIP)来作为API Server统一存取端点。
而上述组件除了kubelet外,其他将通过kubelet以静态Pod方式进行部署,这种方式可以减少管理Systemd的服务,并且能通过kubectl来观察启动的容器状况。
部署与设定
在首先k8s-m1节点展示进入k8s-manual-files目录,并依序执行下述指令来完成部署:
$ cd ~/k8s-manual-files首先利用./hack/gen-configs.sh脚本在每台master节点产生组态文件:
$ export NODES="k8s-m1 k8s-m2 k8s-m3"
$ ./hack/gen-configs.sh
k8s-m1 config generated...
k8s-m2 config generated...
k8s-m3 config generated...后完成检查记得/etc/etcd/config.yml与/etc/haproxy/haproxy.cfg是否设定正确。
主要这边文件确认中的${xxx}字串是否有被更改,并且符合环境。详细内容可以查看k8s-manual-files。
接着利用脚本./hack/gen-manifests.sh在每台master节点产生静态pod YAML文件,以及其他相关设定档(如EncryptionConfig):
$ export NODES="k8s-m1 k8s-m2 k8s-m3"
$ ./hack/gen-manifests.sh
k8s-m1 manifests generated...
k8s-m2 manifests generated...
k8s-m3 manifests generated...完成后记得检查/etc/kubernetes/manifests,/etc/kubernetes/encryption与/etc/kubernetes/audit目录中的文件是否的英文定正确。
主要这边文件确认中的${xxx}字串是否有被更改,并且符合环境需求。详细内容可以查看k8s-manual-files。
确认上述两个产生文件步骤完成后,即可设定所有master节点的kubelet systemd来启动Kubernetes组件。首先复制下列文件到指定路径:
$ for NODE in k8s-m1 k8s-m2 k8s-m3; do
echo "--- $NODE ---"
ssh ${NODE} "mkdir -p /var/lib/kubelet /var/log/kubernetes /var/lib/etcd /etc/systemd/system/kubelet.service.d"
scp master/var/lib/kubelet/config.yml ${NODE}:/var/lib/kubelet/config.yml
scp master/systemd/kubelet.service ${NODE}:/lib/systemd/system/kubelet.service
scp master/systemd/10-kubelet.conf ${NODE}:/etc/systemd/system/kubelet.service.d/10-kubelet.conf
done接着在k8s-m1通过SSH启动所有master节点的kubelet:
$ for NODE in k8s-m1 k8s-m2 k8s-m3; do
ssh ${NODE} "systemctl enable kubelet.service && systemctl start kubelet.service"
done完成后会需要一段时间来下载映像档与启动组件,可以利用该指令来监看:
$ watch netstat -ntlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.1:10251 0.0.0.0:* LISTEN 9407/kube-scheduler
tcp 0 0 127.0.0.1:10252 0.0.0.0:* LISTEN 9338/kube-controlle
tcp 0 0 127.0.0.1:38420 0.0.0.0:* LISTEN 8676/kubelet
tcp 0 0 0.0.0.0:8443 0.0.0.0:* LISTEN 9602/haproxy
tcp 0 0 0.0.0.0:9090 0.0.0.0:* LISTEN 9602/haproxy
tcp6 0 0 :::10250 :::* LISTEN 8676/kubelet
tcp6 0 0 :::2379 :::* LISTEN 9487/etcd
tcp6 0 0 :::6443 :::* LISTEN 9133/kube-apiserver
tcp6 0 0 :::2380 :::* LISTEN 9487/etcd
...若看到以上资讯表示服务正常启动,发生若问题可以用docker指令来查看。
接下来将建立TLS Bootstrapping来让Node签证并授权注册到集群。
建立TLS Bootstrapping
由于本教学采用TLS认证来确保Kubernetes集群的安全性,因此每个节点的kubelet都需要通过API Server的CA进行身份验证后,才能与API服务器进行沟通,而这过程过去都是采用手动方式针对每台节点(master与node)单独签署凭证,再设定给kubelet使用,然而这种方式是一件繁琐的事情,因为当节点扩展到一定程度时,将会非常费时,甚至延伸初管理不易问题。
而由于上述问题,Kubernetes实现了TLS Bootstrapping来解决此问题,这种做法是先让kubelet以一个低权限使用者(一个能存取CSR API的令牌)存取API服务器,接着对API服务器提出申请凭证签署请求,并在受理后由API Server动态签署kubelet凭证提供给对应的node节点使用。具体作法请参考TLS Bootstrapping与 使用Bootstrap令牌进行身份验证。
在k8s-m1建立bootstrap使用者的kubeconfig档:
$ export TOKEN_ID=$(openssl rand 3 -hex)
$ export TOKEN_SECRET=$(openssl rand 8 -hex)
$ export BOOTSTRAP_TOKEN=${TOKEN_ID}.${TOKEN_SECRET}
$ export KUBE_APISERVER="https://172.22.132.9:6443"
$ kubectl config set-cluster kubernetes \
--certificate-authority=/etc/kubernetes/pki/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf
$ kubectl config set-credentials tls-bootstrap-token-user \
--token=${BOOTSTRAP_TOKEN} \
--kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf
$ kubectl config set-context tls-bootstrap-token-user@kubernetes \
--cluster=kubernetes \
--user=tls-bootstrap-token-user \
--kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf
$ kubectl config use-context tls-bootstrap-token-user@kubernetes \
--kubeconfig=/etc/kubernetes/bootstrap-kubelet.confKUBE_APISERVER这边设定为VIP位址。若想要用手动签署凭证来进行授权的话,可以参考证书。
接着在k8s-m1建立TLS Bootstrap Secret来提供自动签证使用:
$ cat <<EOF | kubectl create -f -
apiVersion: v1
kind: Secret
metadata:
name: bootstrap-token-${TOKEN_ID}
namespace: kube-system
type: bootstrap.kubernetes.io/token
stringData:
token-id: "${TOKEN_ID}"
token-secret: "${TOKEN_SECRET}"
usage-bootstrap-authentication: "true"
usage-bootstrap-signing: "true"
auth-extra-groups: system:bootstrappers:default-node-token
EOF
secret "bootstrap-token-65a3a9" created然后建立TLS Bootstrap Autoapprove RBAC来提供自动受理CSR:
$ kubectl apply -f master/resources/kubelet-bootstrap-rbac.yml
clusterrolebinding.rbac.authorization.k8s.io/kubelet-bootstrap created
clusterrolebinding.rbac.authorization.k8s.io/node-autoapprove-bootstrap created
clusterrolebinding.rbac.authorization.k8s.io/node-autoapprove-certificate-rotation created验证Master节点
完成后,在任意一台master节点复制Admin kubeconfig文件,并通过简单指令验证:
$ cp /etc/kubernetes/admin.conf ~/.kube/config
$ kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true"}
etcd-1 Healthy {"health":"true"}
etcd-2 Healthy {"health":"true"}
$ kubectl -n kube-system get po
NAME READY STATUS RESTARTS AGE
etcd-k8s-m1 1/1 Running 0 1h
etcd-k8s-m2 1/1 Running 0 1h
etcd-k8s-m3 1/1 Running 0 1h
kube-apiserver-k8s-m1 1/1 Running 0 1h
kube-apiserver-k8s-m2 1/1 Running 0 1h
kube-apiserver-k8s-m3 1/1 Running 0 1h
...
$ kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-m1 NotReady master 38s v1.11.0
k8s-m2 NotReady master 37s v1.11.0
k8s-m3 NotReady master 36s v1.11.0这在阶段状态处于NotReady的英文正常,往下进行就会了解为何。
通过kubectl logs来查看容器的日志:
$ kubectl -n kube-system logs -f kube-apiserver-k8s-m1
Error from server (Forbidden): Forbidden (user=kube-apiserver, verb=get, resource=nodes, subresource=proxy) ( pods/log kube-apiserver-k8s-m1)这边会发现出现403 Forbidden problem题,这是因为kube-apiserver用户并没有节点的资源存取权限,属于正常。
为了方便管理集群,因此需要通过kubectl logs来查看,但由于API权限问题,故需要建立一个RBAC角色来获取存取权限,这边在k8s-m1节点执行以下指令建立:
$ kubectl apply -f master/resources/apiserver-to-kubelet-rbac.yml
clusterrole.rbac.authorization.k8s.io/system:kube-apiserver-to-kubelet created
clusterrolebinding.rbac.authorization.k8s.io/system:kube-apiserver created完成后,再次通过kubectl logs查看Pod:
$ kubectl -n kube-system logs -f kube-apiserver-k8s-m1
I0708 15:22:33.906269 1 get.go:245] Starting watch for /api/v1/services, rv=2494 labels= fields= timeout=8m29s
I0708 15:22:40.919638 1 get.go:245] Starting watch for /apis/certificates.k8s.io/v1beta1/certificatesigningrequests, rv=11084 labels= fields= timeout=7m29s
...接着设定Taints and Tolerations来让一些特定Pod能够排程到所有master节点上:
$ kubectl taint nodes node-role.kubernetes.io/master="":NoSchedule --all
node "k8s-m1" tainted
node "k8s-m2" tainted
node "k8s-m3" tainted这边截至已完成master节点部署,将接下来针对node的部署进行说明。
Kubernetes节点
本节将说明如何建立与设定Kubernetes Node节点,节点是主要执行容器实例(Pod)的工作节点。这过程只需要将PKI,Bootstrap conf等文件复制到机器上,再用kubelet启动即可。
在开始部署前,在k8-m1将需要用到的文件复制到所有node节点上:
$ for NODE in k8s-g1 k8s-g2; do
echo "--- $NODE ---"
ssh ${NODE} "mkdir -p /etc/kubernetes/pki/"
for FILE in pki/ca.pem pki/ca-key.pem bootstrap-kubelet.conf; do
scp /etc/kubernetes/${FILE} ${NODE}:/etc/kubernetes/${FILE}
done
done部署与设定
确认文件都复制后,即可设定所有node节点的kubelet systemd来启动Kubernetes组件。首先在k8s-m1复制下列文件到指定路径:
$ cd ~/k8s-manual-files
$ for NODE in k8s-g1 k8s-g2; do
echo "--- $NODE ---"
ssh ${NODE} "mkdir -p /var/lib/kubelet /var/log/kubernetes /var/lib/etcd /etc/systemd/system/kubelet.service.d /etc/kubernetes/manifests"
scp node/var/lib/kubelet/config.yml ${NODE}:/var/lib/kubelet/config.yml
scp node/systemd/kubelet.service ${NODE}:/lib/systemd/system/kubelet.service
scp node/systemd/10-kubelet.conf ${NODE}:/etc/systemd/system/kubelet.service.d/10-kubelet.conf
done接着在k8s-m1通过SSH启动所有node节点的kubelet:
$ for NODE in k8s-g1 k8s-g2; do
ssh ${NODE} "systemctl enable kubelet.service && systemctl start kubelet.service"
done验证节点节点
完成后,在任意一台master节点复制Admin kubeconfig文件,并通过简单指令验证:
$ kubectl get csr
NAME AGE REQUESTOR CONDITION
csr-99n76 1h system:node:k8s-m2 Approved,Issued
csr-9n88h 1h system:node:k8s-m1 Approved,Issued
csr-vdtqr 1h system:node:k8s-m3 Approved,Issued
node-csr-5VkCjWvb8tGVtO-d2gXiQrnst-G1xe_iA0AtQuYNEMI 2m system:bootstrap:872255 Approved,Issued
node-csr-Uwpss9OhJrAgOB18P4OIEH02VHJwpFrSoMOWkkrK-lo 2m system:bootstrap:872255 Approved,Issued
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-g1 NotReady <none> 8m v1.11.0
k8s-g2 NotReady <none> 8m v1.11.0
k8s-m1 NotReady master 20m v1.11.0
k8s-m2 NotReady master 20m v1.11.0
k8s-m3 NotReady master 20m v1.11.0这在阶段状态处于NotReady的英文正常,往下进行就会了解为何。
到这边就表示node节点部署已完成了,接下来章节将针对Kubernetes Addons安装进行说明。
Kubernetes Core Addons部署
当完成master与node节点的部署,并组合成一个可运作集群后,就可以开始通过kubectl部署Addons,Kubernetes官方提供了多种Addons来加强Kubernetes的各种功能,如集群DNS解析的kube-dns(or CoreDNS),外部存取服务的kube-proxy与Web dashboard-based 管理介面的等等。而其中有些Addons是被Kubernetes认定为必要的,因此本节将说明如何部署这些Addons。
在首先k8s-m1节点展示进入k8s-manual-files目录,并依序执行下述指令来完成部署:
$ cd ~/k8s-manual-filesKubernetes代理
kube-proxy是实现Kubernetes服务资源功能的关键组件,这个组件会通过DaemonSet在每台节点上执行,然后监听API服务器的服务与端点资源物件的事件,并依据资源预期状态通过iptables或ipvs来实现网路转发,而本次安装采用ipvs。
在k8s-m1通过kubeclt执行下面指令来建立,并检查是否部署成功:
$ export KUBE_APISERVER=https://172.22.132.9:6443
$ sed -i "s/\${KUBE_APISERVER}/${KUBE_APISERVER}/g"
$ kubectl -f addons/kube-proxy/
$ kubectl -n kube-system get po -l k8s-app=kube-proxy
NAME READY STATUS RESTARTS AGE
kube-proxy-dd2m7 1/1 Running 0 8m
kube-proxy-fwgx8 1/1 Running 0 8m
kube-proxy-kjn57 1/1 Running 0 8m
kube-proxy-vp47w 1/1 Running 0 8m
kube-proxy-xsncw 1/1 Running 0 8m
# 检查 log 是否使用 ipvs
$ kubectl -n kube-system logs -f kube-proxy-fwgx8
I0709 08:41:48.220815 1 feature_gate.go:230] feature gates: &{map[SupportIPVSProxyMode:true]}
I0709 08:41:48.231009 1 server_others.go:183] Using ipvs Proxier.
...若有安装ipvsadm的话,可以通过以下指令查看代理规则:
$ ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.96.0.1:443 rr
-> 172.22.132.9:5443 Masq 1 0 0CoreDNS
本节将通过CoreDNS取代Kube DNS作为集群服务发现组件,由于Kubernetes需要让Pod与Pod之间能够互相沟通,然而要能够沟通需要知道彼此的IP才行,而这种做法通常是通过Kubernetes API来取得达到,但是Pod IP会因为生命周期变化而改变,因此这种做法无法弹性使用,且还会增加API服务器负担,基于此问题Kubernetes提供了DNS服务来作为查询,让Pod能够以服务名称作为域名来查询IP位址,因此使用者就再不需要关切实际Pod IP,而DNS也会根据Pod变化更新资源纪录(记录资源)。
CoreDNS是由CNCF维护的开源DNS专案,该专案前身是SkyDNS,其采用了Caddy的一部分来开发伺服器框架,使其能够建构一套快速灵活的DNS,而CoreDNS每个功能都可以被实作成一个插件的中介软体,如Log,Cache,Kubernetes等功能,甚至能够将源纪录储存至Redis,Etcd中。
在k8s-m1通过kubeclt执行下面指令来建立,并检查是否部署成功:
$ kubectl create -f coredns/
$ kubectl -n kube-system get po -l k8s-app=kube-dns
NAME READY STATUS RESTARTS AGE
coredns-589dd74cb6-5mv5c 0/1 Pending 0 3m
coredns-589dd74cb6-d42ft 0/1 Pending 0 3m这边会发现Pod处于Pending状态,这是由于Kubernetes的集群网路没有建立,因此所有节点会处于NotReady状态,而这也导致Kubernetes Scheduler无法替Pod找到适合节点而处于Pending,为了解决这个问题,下节将说明与建立Kubernetes集群网路。
若Pod是被DaemonSet管理的话,则不会待定,不过若没有设定hostNetwork则会出问题。
Kubernetes集群网路
Kubernetes在预设情况下与Docker的网路有所不同。在Kubernetes中有四个问题是需要被解决的,分别为:
- 高耦合的容器到容器沟通:通过Pods与Localhost的沟通来解决。
- Pod到Pod的沟通:通过实现网路模型来解决。
- Pod到服务沟通:由服务对象结合kube-proxy解决。
- 外部到服务沟通:一样由服务对象结合kube-proxy解决。
而Kubernetes对于任何网路的实现都需要满足以下基本要求(除非是有意调整的网路分段策略):
- 所有容器能够在没有NAT的情况下与其他容器沟通。
- 所有节点能够在没有NAT情况下与所有容器沟通(反之亦然)。
- 容器看到的IP与其他人看到的IP是一样的。
庆幸的是Kubernetes已经有非常多种的网路模型以网路插件(网络插件)方式被实现,因此可以选用满足自己需求的网路功能来使用。另外Kubernetes中的网路插件有以下两种形式:
- CNI插件:以appc / CNI标准规范所实现的网路,详细可以阅读CNI规范。
- Kubenet插件:使用CNI插件的桥与主机本地来实现基本的cbr0。这通常被用在公有云服务上的Kubernetes集群网路。
如果了解如何选择可以阅读Chris Love的为Kubernetes文章选择CNI网络提供商。
网路部署与设定
从上述了解Kubernetes有多种网路能够选择,而本教学选择了Calico作为集群网路的使用.Calico是一款纯Layer 3的网路,其他处是它整合了各种云原生平台(Docker,Mesos与OpenStack等),Calico不采用vSwitch,而是在每个Kubernetes节点使用vRouter功能,并通过Linux Kernel既有L3转发功能,而当时资料中心复杂度增加时,Calico也可以利用BGP route reflector来达成。
想了解Calico与传统覆盖网络的差异,可以阅读传统覆盖网络的困难文章。
由于Calico提供了Kubernetes资源YAML档来快速以容器方式部署网路插件至所有节点上,因此只需要在k8s-m1通过kubeclt执行下面指令来建立:
$ cd ~/k8s-manual-files
$ sed -i 's/192.168.0.0\/16/10.244.0.0\/16/g' cni/calico/v3.1/calico.yaml
$ kubectl -f cni/calico/v3.1/
- 这边要记得将CALICO_IPV4POOL_CIDR的网路修改群集IP CIDR。
- 另外当节点超过50台,可以使用Calico的Typha模式来减少通过Kubernetes datastore造成API Server的负担。
部署后通过kubectl检查是否有启动:
$ kubectl -n kube-system get po -l k8s-app=calico-node
NAME READY STATUS RESTARTS AGE
calico-node-27jwl 2/2 Running 0 59s
calico-node-4fgv6 2/2 Running 0 59s
calico-node-mvrt7 2/2 Running 0 59s
calico-node-p2q9g 2/2 Running 0 59s
calico-node-zchsz 2/2 Running 0 59s确认calico-node都正常运作后,通过kubectl exec进入calicoctl pod来检查功能是否正常:
$ kubectl exec -ti -n kube-system calicoctl -- calicoctl get profiles -o wide
NAME LABELS
kns.default map[]
kns.kube-public map[]
kns.kube-system map[]
$ kubectl exec -ti -n kube-system calicoctl -- calicoctl get node -o wide
NAME ASN IPV4 IPV6
k8s-g1 (unknown) 172.22.132.13/24
k8s-g2 (unknown) 172.22.132.14/24
k8s-m1 (unknown) 172.22.132.10/24
k8s-m2 (unknown) 172.22.132.11/24
k8s-m3 (unknown) 172.22.132.12/24若没问题,就可以将kube-system下的calicoctl pod删除。
完成后,通过检查节点是否不再是NotReady,以及Pod是否不再处于Pending:
$ kubectl get no
NAME STATUS ROLES AGE VERSION
k8s-g1 Ready <none> 35m v1.11.0
k8s-g2 Ready <none> 35m v1.11.0
k8s-m1 Ready master 35m v1.11.0
k8s-m2 Ready master 35m v1.11.0
k8s-m3 Ready master 35m v1.11.0
$ kubectl -n kube-system get po -l k8s-app=kube-dns -o wide
NAME READY STATUS RESTARTS AGE IP NODE
coredns-589dd74cb6-5mv5c 1/1 Running 0 10m 10.244.4.2 k8s-g2
coredns-589dd74cb6-d42ft 1/1 Running 0 10m 10.244.3.2 k8s-g1当成功到这边时,一个能运作的Kubernetes集群基本上就完成了,接下来将介绍一些好用的Addons来帮助使用与管理Kubernetes。
Kubernetes Extra Addons部署
本节说明如何部署一些官方常用的额外Addons,如Dashboard,Metrics Server与Ingress Controller等等。
所有Addons部署文件均存已放至k8s-manual-files中,因此在k8s-m1进入该目录,并依序下小节建立:
$ cd ~/k8s-manual-files入口控制器
Ingress是Kubernetes中的一个抽象资源,其功能是通过Web Server的虚拟主机概念以域名(域名)方式转发到内部服务,这避免了使用服务中的NodePort与LoadBalancer类型所带来的限制(如Port数量上限),而实现Ingress功能则是通过Ingress Controller来达成,它会负责监听Kubernetes API中的Ingress与服务资源物件,并在发生资源变化时,依据资源预期的结果来设定Web服务器。另外Ingress Controller有许多实现可以选择:
- Ingress NGINX:Kubernetes官方维护的专案,也是本次安装使用的控制器。
- F5 BIG-IP控制器:F5所开发的控制器,它能够让管理员通过CLI或API从Kubernetes与OpenShift管理F5 BIG-IP设备。
- Ingress Kong:着名的开源API网关专案所维护的Kubernetes Ingress Controller。
- Træfik:是一套开源的HTTP反向代理与负载平衡器,而它也支援了Ingress。
- Voyager:一套以HAProxy为底的Ingress Controller。
而Ingress Controller的实现不只这些专案,还有很多可以在网路上找到,未来自己也会写一篇Ingress Controller的实作方式文章。
首先在k8s-m1执行下述指令来建立Ingress Controller,并检查是否部署正常:
$ export INGRESS_VIP=172.22.132.8
$ sed -i "s/\${INGRESS_VIP}/${INGRESS_VIP}/g" addons/ingress-controller/ingress-controller-svc.yml
$ kubectl create ns ingress-nginx
$ kubectl apply -f addons/ingress-controller
$ kubectl -n ingress-nginx get po,svc
NAME READY STATUS RESTARTS AGE
pod/default-http-backend-846b65fb5f-l5hrc 1/1 Running 0 2m
pod/nginx-ingress-controller-5db8d65fb-z2lf9 1/1 Running 0 2m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/default-http-backend ClusterIP 10.99.105.112 <none> 80/TCP 2m
service/ingress-nginx LoadBalancer 10.106.18.106 172.22.132.8 80:31197/TCP 2m后完成浏览通过器存取http://172.22.132.8:80来查看是否能连线,若可以会如下图结果。

当确认上面步骤都没问题后,就可以通过kubeclt建立简单NGINX来测试功能:
$ kubectl apply -f apps/nginx/
deployment.extensions/nginx created
ingress.extensions/nginx-ingress created
service/nginx created
$ kubectl get po,svc,ing
NAME READY STATUS RESTARTS AGE
pod/nginx-966857787-78kth 1/1 Running 0 32s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d
service/nginx ClusterIP 10.104.180.119 <none> 80/TCP 32s
NAME HOSTS ADDRESS PORTS AGE
ingress.extensions/nginx-ingress nginx.k8s.local 172.22.132.8 80 33sPS Ingress规则也支援不同路径的服务转发,可以参考上面提供的官方文件来设定。
完成后通过cURL工具来测试功能是否正常:
$ curl 172.22.132.8 -H 'Host: nginx.k8s.local'
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...
# 测试其他 domain name 是是否回应 404
$ curl 172.22.132.8 -H 'Host: nginx1.k8s.local'
default backend - 404虽然Ingress能够让我们通过域名方式存取Kubernetes内部服务,但是若域名于法被测试机器解析的话,将会显示default backend – 404结果,而这经常发生在内部自建环境上,虽然可以通过修改主机/etc/hosts来描述,但并不弹性,因此下节将说明如何建立一个外部DNS与DNS伺服器来提供自动解析Ingress域名。
外部DNS
外部DNS是Kubernetes社区的孵化专案,被用于定期同步Kubernetes服务与Ingress资源,并依据资源内容来自动设定公有云DNS服务的资源纪录(记录资源)。而由于部署不是公有云环境,因此需要通过CoreDNS提供一个内部DNS服务器,再由ExternalDNS与这个CoreDNS做串接。
首先在k8s-m1执行下述指令来建立CoreDNS Server,并检查是否部署正常:
$ export DNS_VIP=172.22.132.8
$ sed -i "s/\${DNS_VIP}/${DNS_VIP}/g" addons/external-dns/coredns/coredns-svc-tcp.yml
$ sed -i "s/\${DNS_VIP}/${DNS_VIP}/g" addons/external-dns/coredns/coredns-svc-udp.yml
$ kubectl create -f addons/external-dns/coredns/
$ kubectl -n external-dns get po,svc
NAME READY STATUS RESTARTS AGE
pod/coredns-54bcfcbd5b-5grb5 1/1 Running 0 2m
pod/coredns-etcd-6c9c68fd76-n8rhj 1/1 Running 0 2m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/coredns-etcd ClusterIP 10.110.186.83 <none> 2379/TCP,2380/TCP 2m
service/coredns-tcp LoadBalancer 10.109.105.166 172.22.132.8 53:32169/TCP,9153:32150/TCP 2m
service/coredns-udp LoadBalancer 10.110.242.185 172.22.132.8 53:31210/UDP这边域名为k8s.local,修改可以文件中的coredns-cm.yml来改变。
完成后,通过挖工具来检查是否DNS是否正常:
$ dig @172.22.132.8 SOA nginx.k8s.local +noall +answer +time=2 +tries=1
...
; (1 server found)
;; global options: +cmd
k8s.local. 300 IN SOA ns.dns.k8s.local. hostmaster.k8s.local. 1531299150 7200 1800 86400 30接着部署ExternalDNS来与CoreDNS同步资源纪录:
$ kubectl apply -f addons/external-dns/external-dns/
$ kubectl -n external-dns get po -l k8s-app=external-dns
NAME READY STATUS RESTARTS AGE
external-dns-86f67f6df8-ljnhj 1/1 Running 0 1m完成后,通过挖与nslookup工具检查上节测试Ingress的NGINX服务:
$ dig @172.22.132.8 A nginx.k8s.local +noall +answer +time=2 +tries=1
...
; (1 server found)
;; global options: +cmd
nginx.k8s.local. 300 IN A 172.22.132.8
$ nslookup nginx.k8s.local
Server: 172.22.132.8
Address: 172.22.132.8#53
** server can't find nginx.k8s.local: NXDOMAIN这时会无法通过nslookup解析域名,这是因为测试机器并没有使用这个DNS伺服器,可以通过修改/etc/resolv.conf来加入,或者类似下图方式(不同OS有差异,不过都在网路设定中改)。

再次通过nslookup检查,会发现可以解析了,这时也就能通过cURL来测试结果:
$ nslookup nginx.k8s.local
Server: 172.22.132.8
Address: 172.22.132.8#53
Name: nginx.k8s.local
Address: 172.22.132.8
$ curl nginx.k8s.local
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...仪表板
Dashboard是Kubernetes官方开发的基于Web的仪表板,目的是提升管理Kubernetes集群资源便利性,并以资源视觉化方式,来让人更直觉的看到整个集群资源状态,
在k8s-m1通过kubeclt执行下面指令来建立Dashboard至Kubernetes,并检查是否正确部署:
$ cd ~/k8s-manual-files
$ kubectl apply -f addons/dashboard/
$ kubectl -n kube-system get po,svc -l k8s-app=kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
pod/kubernetes-dashboard-6948bdb78-w26qc 1/1 Running 0 2m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes-dashboard ClusterIP 10.109.31.80 <none> 443/TCP 2m在这边会额外建立名称为anonymous-dashboard-proxy的群集角色(Binding)来让system:anonymous这个匿名使用者能够通过API Server来代理到Kubernetes Dashboard,而这个RBAC规则仅能够存取services/proxy资源,以及https:kubernetes-dashboard:资源名称。
因此我们能够在完成后,通过以下连结来进入Kubernetes Dashboard:
由于Kubernetes Dashboard v1.7版本以后不再提供管理权限,因此需要通过kubeconfig或者服务帐户来进行登入才能取得资源来呈现,这边建立一个服务帐户来绑定cluster-admin以测试功能:
$ kubectl -n kube-system create sa dashboard
$ kubectl create clusterrolebinding dashboard --clusterrole cluster-admin --serviceaccount=kube-system:dashboard
$ SECRET=$(kubectl -n kube-system get sa dashboard -o yaml | awk '/dashboard-token/ {print $3}')
$ kubectl -n kube-system describe secrets ${SECRET} | awk '/token:/{print $2}'
eyJhbGciOiJSUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtdG9rZW4tdzVocmgiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGFzaGJvYXJkIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiYWJmMTFjYzMtZjRlYi0xMWU3LTgzYWUtMDgwMDI3NjdkOWI5Iiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmUtc3lzdGVtOmRhc2hib2FyZCJ9.Xuyq34ci7Mk8bI97o4IldDyKySOOqRXRsxVWIJkPNiVUxKT4wpQZtikNJe2mfUBBD-JvoXTzwqyeSSTsAy2CiKQhekW8QgPLYelkBPBibySjBhJpiCD38J1u7yru4P0Pww2ZQJDjIxY4vqT46ywBklReGVqY3ogtUQg-eXueBmz-o7lJYMjw8L14692OJuhBjzTRSaKW8U2MPluBVnD7M2SOekDff7KpSxgOwXHsLVQoMrVNbspUCvtIiEI1EiXkyCNRGwfnd2my3uzUABIHFhm0_RZSmGwExPbxflr8Fc6bxmuz-_jSdOtUidYkFIzvEWw2vRovPgs3MXTv59RwUw复制token然后贴到Kubernetes dashboard。注意这边一般来说要针对不同用户开启特定存取权限。
普罗米修斯
由于Heapster将要被移弃,因此这边选用Prometheus作为第三方的集群监控方案。而本次安装采用CoreOS开发的Prometheus操作员用于管理在Kubernetes上的Prometheus集群与资源,更多关于Prometheus Operator的资讯可以参考小弟的Prometheus Operator介绍与安装文章。
首先在k8s-m1执行下述指令来部署所有Prometheus需要的组件:
$ kubectl apply -f addons/prometheus/
$ kubectl apply -f addons/prometheus/operator/
$ kubectl apply -f addons/prometheus/alertmanater/
$ kubectl apply -f addons/prometheus/node-exporter/
$ kubectl apply -f addons/prometheus/kube-state-metrics/
$ kubectl apply -f addons/prometheus/grafana/
$ kubectl apply -f addons/prometheus/kube-service-discovery/
$ kubectl apply -f addons/prometheus/prometheus/
$ kubectl apply -f addons/prometheus/servicemonitor/完成后,通过kubectl检查服务是否正常运行:
$ kubectl -n monitoring get po,svc,ing
NAME READY STATUS RESTARTS AGE
pod/alertmanager-main-0 1/2 Running 0 1m
pod/grafana-6d495c46d5-jpf6r 1/1 Running 0 43s
pod/kube-state-metrics-b84cfb86-4b8qg 4/4 Running 0 37s
pod/node-exporter-2f4lh 2/2 Running 0 59s
pod/node-exporter-7cz5s 2/2 Running 0 59s
pod/node-exporter-djdtk 2/2 Running 0 59s
pod/node-exporter-kfpzt 2/2 Running 0 59s
pod/node-exporter-qp2jf 2/2 Running 0 59s
pod/prometheus-k8s-0 3/3 Running 0 28s
pod/prometheus-k8s-1 3/3 Running 0 15s
pod/prometheus-operator-9ffd6bdd9-rvqsz 1/1 Running 0 1m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-main ClusterIP 10.110.188.2 <none> 9093/TCP 1m
service/alertmanager-operated ClusterIP None <none> 9093/TCP,6783/TCP 1m
service/grafana ClusterIP 10.104.147.154 <none> 3000/TCP 43s
service/kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 51s
service/node-exporter ClusterIP None <none> 9100/TCP 1m
service/prometheus-k8s ClusterIP 10.96.78.58 <none> 9090/TCP 28s
service/prometheus-operated ClusterIP None <none> 9090/TCP 33s
service/prometheus-operator ClusterIP 10.99.251.16 <none> 8080/TCP 1m
NAME HOSTS ADDRESS PORTS AGE
ingress.extensions/grafana-ing grafana.monitoring.k8s.local 172.22.132.8 80 45s
ingress.extensions/prometheus-ing prometheus.monitoring.k8s.local 172.22.132.8 80 34s确认没问题后,通过浏览器查看prometheus.monitoring.k8s.local与grafana.monitoring.k8s.local是否正常,若没问题就可以看到如下图所示结果。
另外这边也推荐用Weave Scope来监控容器的网路Flow拓朴图。
度量服务器
Metrics Server是实现了资源Metrics API的组件,其目标是取代Heapster作为Pod与节点提供资源的使用指标,该组件会从上每个Kubernetes节点上的Kubelet所公开的摘要API中收集指标。
首先在k8s-m1测试一下kubectl top指令:
$ kubectl top node
error: metrics not available yet发现top指令无法取得Metrics,这表示Kubernetes集群没有安装Heapster或是Metrics Server来提供Metrics API给top指令取得资源使用量。
由于上述问题,我们要在k8s-m1节点通过kubectl部署Metrics Server组件来解决:
$ kubectl create -f addons/metric-server/
$ kubectl -n kube-system get po -l k8s-app=metrics-server
NAME READY STATUS RESTARTS AGE
pod/metrics-server-86bd9d7667-5hbn6 1/1 Running 0 1m完成后,等待一点时间(约30s – 1m)收集指标,再次执行kubectl top指令查看:
$ kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-g1 106m 2% 1037Mi 6%
k8s-g2 212m 5% 1043Mi 8%
k8s-m1 386m 9% 2125Mi 13%
k8s-m2 320m 8% 1834Mi 11%
k8s-m3 457m 11% 1818Mi 11%而这时若有使用HPA的话,就能够正确抓到Pod的CPU与Memory使用量了。
若想让HPA使用Prometheus的Metrics的话,可以阅读Custom Metrics Server来了解。
头盔分蘖服务器
Helm是Kubernetes Chart的管理工具,Kubernetes Chart是一套预先组态的Kubernetes资源。其中Tiller Server主要负责接收来至客户的指令,并通过kube-apiserver与Kubernetes集群做沟通,根据图定义的内容,来产生与管理各种对应API物件的Kubernetes部署文件(又称为Release)。
首先在k8s-m1安装Helm工具:
$ wget -qO- https://kubernetes-helm.storage.googleapis.com/helm-v2.9.1-linux-amd64.tar.gz | tar -zx
$ sudo mv linux-amd64/helm /usr/local/bin/另外在所有node节点安装socat:
$ sudo apt-get install -y socat接着初始化Helm(这边会安装Tiller Server):
$ kubectl -n kube-system create sa tiller
$ kubectl create clusterrolebinding tiller --clusterrole cluster-admin --serviceaccount=kube-system:tiller
$ helm init --service-account tiller
...
Tiller (the Helm server-side component) has been installed into your Kubernetes Cluster.
Happy Helming!
$ kubectl -n kube-system get po -l app=helm
NAME READY STATUS RESTARTS AGE
tiller-deploy-759cb9df9-rfhqw 1/1 Running 0 19s
$ helm version
Client: &version.Version{SemVer:"v2.9.1", GitCommit:"20adb27c7c5868466912eebdf6664e7390ebe710", GitTreeState:"clean"}
Server: &version.Version{SemVer:"v2.9.1", GitCommit:"20adb27c7c5868466912eebdf6664e7390ebe710", GitTreeState:"clean"}测试Helm功能
这边部署简单Jenkins来进行功能测试:
$ helm install --name demo --set Persistence.Enabled=false stable/jenkins
$ kubectl get po,svc -l app=demo-jenkins
NAME READY STATUS RESTARTS AGE
demo-jenkins-7bf4bfcff-q74nt 1/1 Running 0 2m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
demo-jenkins LoadBalancer 10.103.15.129 <pending> 8080:31161/TCP 2m
demo-jenkins-agent ClusterIP 10.103.160.126 <none> 50000/TCP 2m
# 取得 admin 账号的密码
$ printf $(kubectl get secret --namespace default demo-jenkins -o jsonpath="{.data.jenkins-admin-password}" | base64 --decode);echo
r6y9FMuF2u当服务都正常运作时,就可以通过浏览器查看HTTP:// node_ip:31161页面。
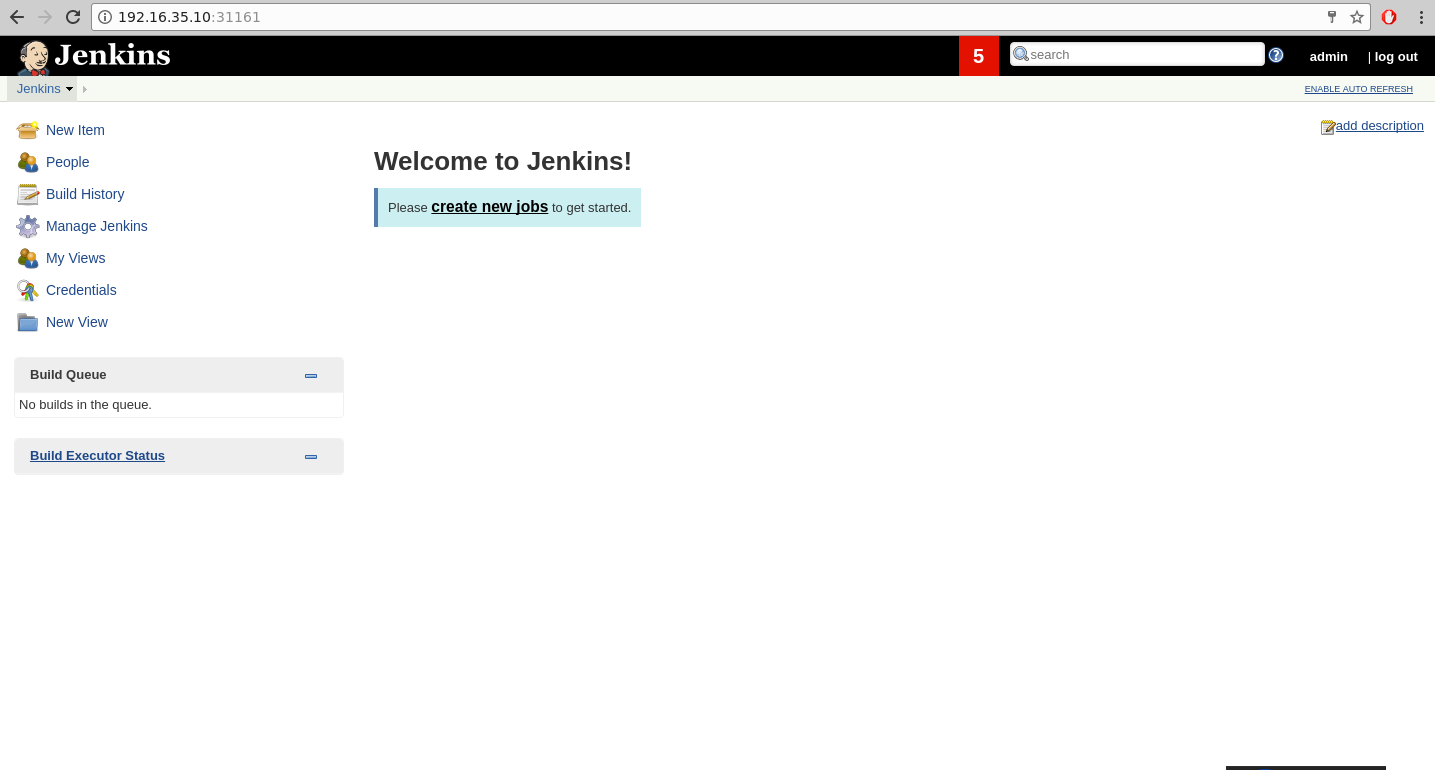
测试完成后,就可以通过以下指令来删除
$ helm ls
NAME REVISION UPDATED STATUS CHART NAMESPACE
demo 1 Tue Apr 10 07:29:51 2018 DEPLOYED jenkins-0.14.4 default
$ helm delete demo --purge
release "demo" deleted想要了解更多Helm Apps的话,可以到Kubeapps Hub网站寻找。
测试集群HA功能
展示进入首先k8s-m1节点,然后关闭该节点:
$ sudo poweroff接着进入到k8s-m2节点,通过kubectl来检查集群是否能够正常执行:
# 先检查 etcd 状态,可以发现 etcd-0 因為關機而中斷
$ kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-1 Healthy {"health": "true"}
etcd-2 Healthy {"health": "true"}
etcd-0 Unhealthy Get https://172.22.132.10:2379/health: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
# 测试是否可以建立 Pod
$ kubectl run nginx --image nginx --restart=Never --port 80
$ kubectl get po
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 22s作者:Kyle.Bai
原文:https://kairen.github.io/2018/07/09/kubernetes/deploy/manual-v1.11/
