


背景
甜橙金融目前有众多的金融及相关衍生产品,且业务的范围和体量也在不断增加,相应的各类应用系统以及微服务的规模也在高速的扩张,这对于后端的运维平台的支撑能力提出了很高的要求。
那么,如何能快速、合理地将现有资源分配给生产的各个服务,并能同时保证分布式、高并发、高可用、高性能等成为整个运维技术团队一直在尝试和探索的方向。
跟大部分互联网公司的发展路线很相似,也是经历了以下几个阶段:
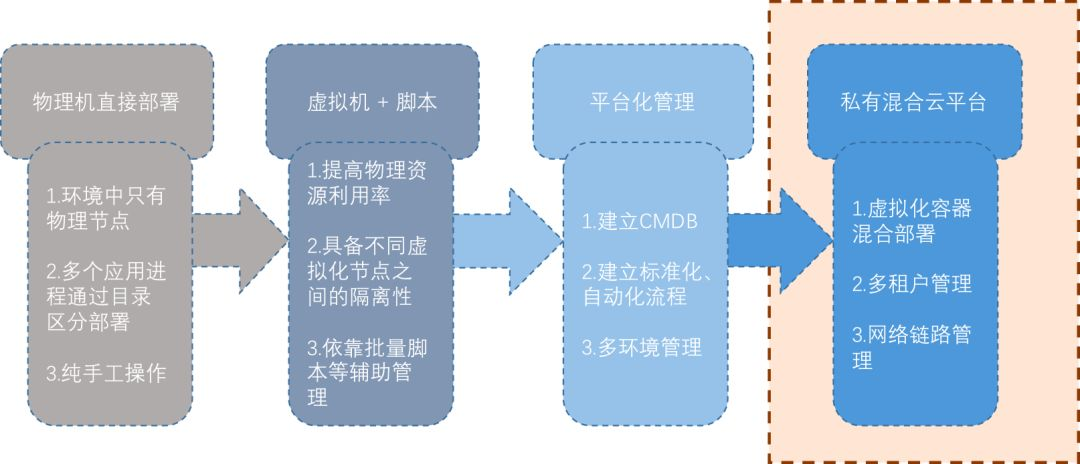
本次主要会针对目前私有云当中容器与虚拟机混部这块的探索和实践做一个分享
简介
我们基于探索性业务系统的一些特征(生命周期不稳定、业务量级增长规模难预估、具有周期性业务高峰等)。
考虑使用容器技术更好更快的支撑业务发展,但同时由于之前基于虚拟机的运维体系架构已较为成熟,所以一定是要在基础设施、系统、网络等层面做很多的适配和尝试,才能在用户几乎无感知的情况下,最终达到虚拟机和容器之间平滑的迁移和切换。
思考及方案
网络层面
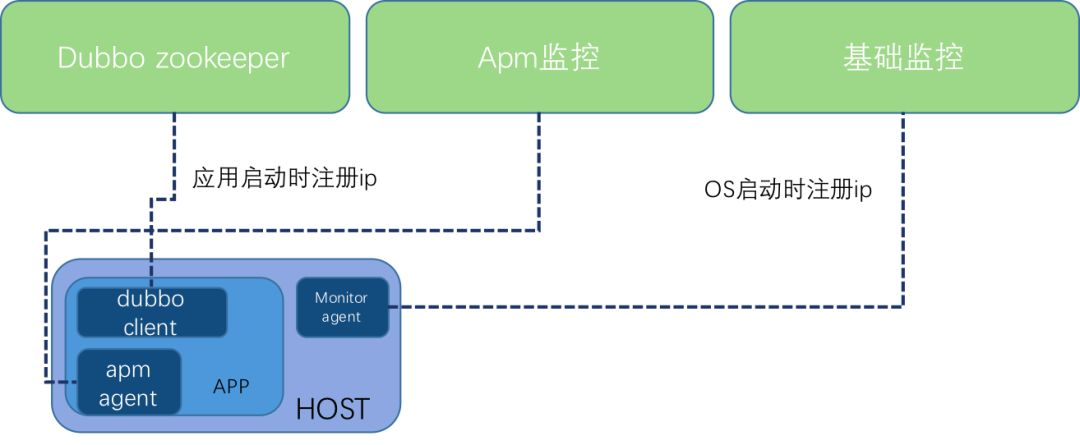
为了兼容现有的应用服务框架以及配套的运维架构,所以必须要具体以下几个条件:
1)独立的ip地址目前应用系统使用 dubbo 做为微服务框架,用过dubbo的人都知道应用在启动的时候会将当前的服务及 ip 地址注册到 zookeeper 上,如果我们使用容器技术,那么势必就要求每个容器起来之后要有自己的ip地址;
2)重启之后ip保持不变在用基础监控系统、apm 性能监控、日志收集和分析系统等都是以应用+ ip的维度进行相关数据的分析和展示,使用容器技术的话需要尽可能的保证容器重启之后的 ip 不变,系统的数据连续性能得到保证;
3)容器网络与现有物理网络直连相通已有的网络是基于 cisco 的商用产品做的 sdn 方案,容器的网络必须要兼容现有 sdn 方案,另外,因为是混部所以还要确保容器内的ip能和原来各个区域的虚拟机、物理机直连通信。
1) 尝试 contiv 方案
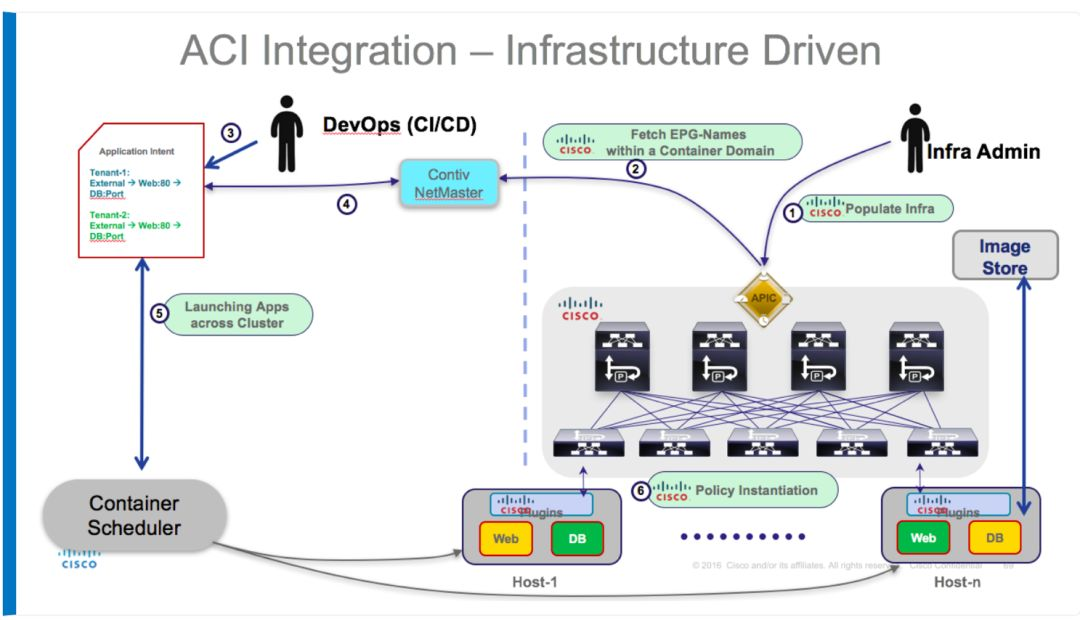
我们首先考虑了同样是 cisco 出品的 doker 网络插件 contiv,前期在跟 cisco 的交流中对方也表示 contiv 可以像 aci 一样做到 ip 级别的管控,contiv + aci的相关架构如下:
针对 contiv 我们也在自己的一套专门的容器环境下进行了相关的测试,也的确可以做到跟 aci 一样,但还是有一些顾虑,主要体现在:
-
contiv 的 sdn 配置管理体系相对独立、跟原来的 aci 配置上并不能完美的契合,要在同一个内网环境部署的话,需要同时配置两个地方。
-
contiv 当时的版本还是 beta 阶段,本并不稳定,测试过程中偶尔会出现带宽不稳定的情况。
2)尝试macvlan方案macvlan 的介绍网上也有不少,主要有以下特点:
-
通过 macvlan,可以在不同的子接口打上不同的 vlantag,实现一台主机上的跑多个 vlan 的容器,每个容器是有自己独立的ip,并且可以跟原物理网络相互通信;
-
允许在主机的一个物理口上配置多个虚拟网络接口,每个接口拥有自己的mac 地址,从 arp 层面进行了隔离;
-
macvlan 是 linux 内核级别的特性,相对比较稳定。
架构图如下:
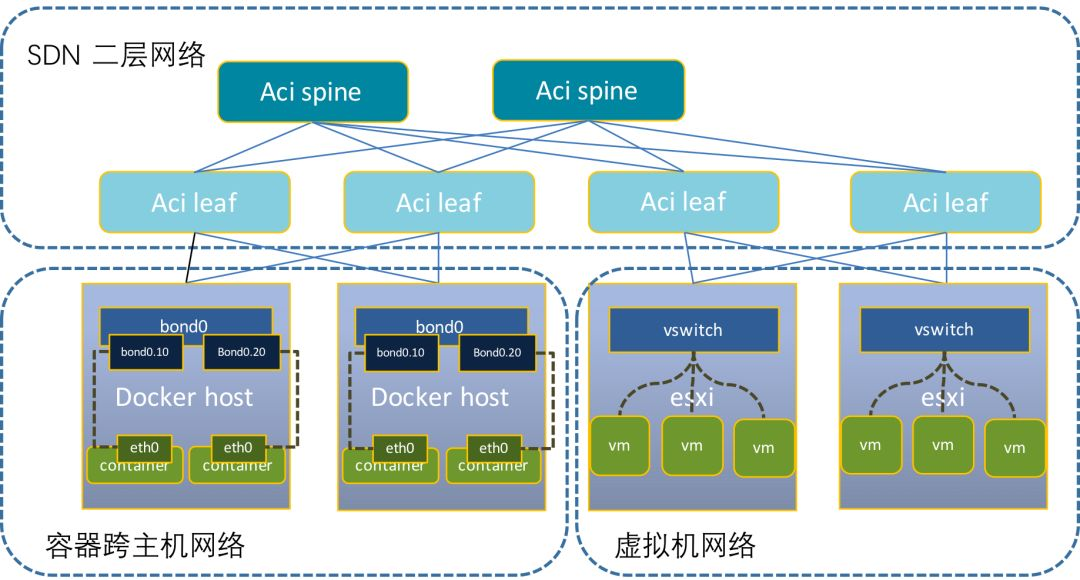
使用 macvlan 可以让容器与虚拟机在同一个二层网络中相互通信,同时也发现有一定的弊端,适用macvlan的 bridge 模式,及时在统一台主机上两个同属一个vlan的容器之间要进行通信,他们之间的数据包并不能直接传输,流量也必须经过上层的交换机。
3)方案选取
-
contiv 的稳定性问题一直得不到有效的解决;
-
contiv 的部署和维护相对复杂,需要有一定的 cisco aci 产品运维经验作为基础;
-
macvlan 在测试过程中的稳定性非常好,使用上也几乎没有门槛
因此综合稳定性、可维护性等方面考虑了以上两种方案的优缺点之后,我们最终决定使用maclvan来组建跨主机容器网络。
容器层面
1)镜像标准docker 是崇尚单容器单进程的,所以很多官方镜像都非常的简洁。我们在制作镜像时一开始也考虑使用简单的 jetty/tomcat 镜像。
但是考虑到这跟 vmwre 虚拟机在使用和维护上的差异太大,可能会对开发人员、运维人员造成不小的困扰,所以在使用上我们想尽量做跟虚拟机类似,整个镜像也是在 redhat 的发行版的基础上修改,包括 ssh 登陆的支持,各类 agent 进程,各类常用排查命令的支持。
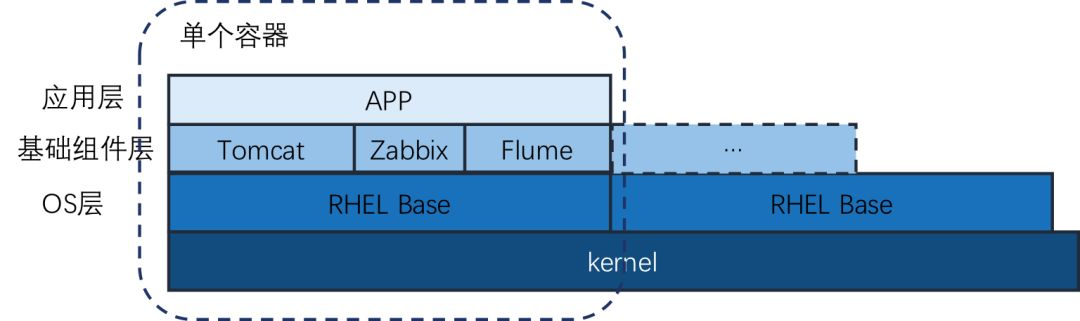
2)进程管理容器启动之后只能运行一个命令,所以一般要在容器内跑多个进程的话,大部分的做法是把一些列的启动命令写在脚本里,然后容器启动的时候跑一次脚本来启动多个进程。
我们的做法类似,但并不是采用脚本的方式,而是在容器起来的时候拉起supervisord,进而管理一些列需要启动的进程。这么做的优势:
-
supervisord 都是基于成熟的配置文件管理,不必再写脚本考虑守护进程、自动拉起推出进程这类问题;
-
使用supervisord再维护成本上很低,只需要确保配置文件正确即可。
3)资源隔离容器在资源隔离方面确实做的没有 vmwre 这么好,但目前使用下来也基本满足需求:
1.内存资源:使用 cgroup 限制,目前网站基本都是 java 应用,正常情况下内存限制的比 jvm堆内存大确保 jvm 启动正常,swappiness 设置的尽可能小避免虚拟内存的使用即可。对于 numa 等特性,不打算压榨服务器性能时,暂时不开启。
2.cpu计算资源:使用 cgroup限制,对cpu的限制只需要保留 1~2core 给宿主机使用,其他容器共享剩余 cpu 即可。这样可以避免某些 core 繁忙、某些空闲的情况,最大限度的利用 cpu 资源。
3.磁盘资源:之前 docker 使用 devicemapper 可以调整单个容器的大小,但这个文件系统的性能不佳,在新版本的docker中默认使用 overlayfs 文件系统,并不支持控制单容器的大小。因此我们在容器内和宿主机上部署监控脚本,用以控制单容器的大小。
调度层面
1)兼容多种调度框架
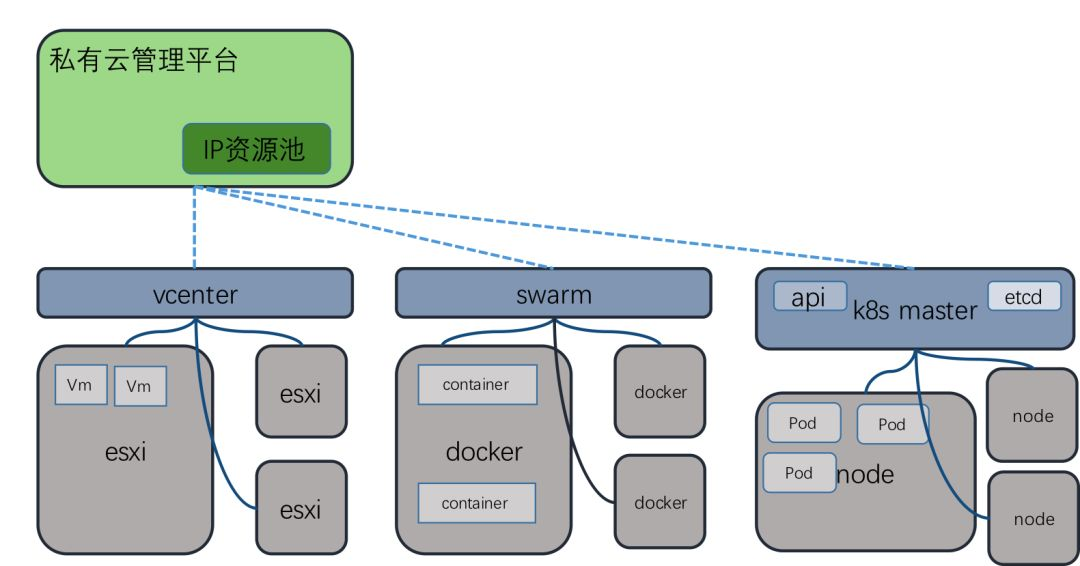
考虑到无论底层是使用 vmware 或者 docker,对于私有云管理平台来说他们都只是作为应用的实例运行节点,确保一个应用的实例运行数可以支撑当前业务量即可,因此我们在这块对不同 api 做了不同的适配:
-
用户在选择给一个应用新增运行节点的时候,不指定后端实例生成方式,平台会根据资源使用情况自动计算挑选空闲物理节点部署应用节点实例
-
考虑到k8s的部署成本问题,我们在多个测试、性能等对稳定性要求不高的环境均使用swarm来管理docker,云平台也会根据用户选择的节点所属环境判断连接方式。
2)ip地址管理在同一个私网环境中,ip 地址作为全局唯一资源,我们只在云平台上记录并分配给应用实例节点。之前的管理平台已经实现了跟 aci 对接并分配 ip 地址的功能,因此在使用 docker 的时候并不能直接使用随机 ip。
3)实例节点故障迁移在出现单个节点异常的时候,通常我们的做法就是将异常节点下线并同时上线一个新的应用节点,并保持 ip 地址不变。
基于 macvlan 的网络方案,我们做到的是可以从一个 vm 节点迁移到容器节点、也可以从容器节点迁移到 vm 节点。
展望
1)轻量级探索:目前的我们所使用的容器还是属于胖容器,今后我们会尝试在使用容器技术过程中让容器变得更加单一,更符合传统一个容器一个进程的思想。
但如何让研发和运维人员能接受这样的转变,可能还会经历一个比较长的过程。
2)数据层产品探索:另外现在只是在应用部署层面使用了容器技术,但是在持久化技术这块的尝试还没有成熟的方案,例如redis、mongoDB、mysql等。
如何解决数据存储在多节点之间的一致性问题,如何确保数据库高可用方案在容器环境下可行这些都是待解决的问题。
想借鉴更多企业级私有云混合部署技术选型的实践方案?不妨看看携程的容器云运维实践之路,还有《深度实践KVM》作者肖力老师带来 国家级私有云运维实践哦,你想看的,都在 9 月 GOPS 全球运维大会上海站,约上三五好友,组团来参加!
 ↓↓精彩还在继续,第10 届 GOPS 高清视频
↓↓精彩还在继续,第10 届 GOPS 高清视频
更多详情,点击阅读原文访问大会官网